
智能音箱中的一种快速回声消除算法
2020-06-01 10:58王冬霞
计算机应用 2020年4期
张 伟,王冬霞,于 玲
(辽宁工业大学电子与信息工程学院,辽宁锦州121001)
(∗通信作者电子邮箱1019247780@qq.com)
0 引言
近年来,随着人工智能技术的不断发展,语音交互成为最方便快捷的人机交互方式,其中智能音箱是人们日常主要应用对象。当智能音箱中扬声器播放音乐时,会经房间传播后被智能音箱中麦克风采集,即为智能音箱中的回声,该回声与使用者发出的目标语音信号叠加在一起,严重影响目标语音信号质量和唤醒与识别结果,从而不能继续对智能音箱进行有效的语音控制。在通信中,传统的单通道声学回声消除(Acoustic Echo Cancellation,AEC)主要采用自适应滤波技术[1],即首先估计扬声器和麦克风之间的声学冲击响应(Acoustic Impulse Response,AIR),然后利用估计的AIR 对扬声器播放信号进行滤波,计算出回声并从麦克风信号中减去。现有的自适应滤波回声消除算法包括归一化最小均方(Normalized Least Mean Square,NLMS)算法[2]、分块频域自适应 算 法[3]、开 源Speex 算 法[4]和WebRTC(Web Real-Time Communications)算法[5]等,还可以利用卡尔曼滤波技术[6]、盲源分离技术[7],以及神经网络技术[8]等进行回声消除。其中NLMS 算法由于其相对强大的性能和低复杂度而得到最广泛的应用。这些算法在一定程度上改善了目标语音的质量,但由于大多基于自适应滤波技术,若直接应用到多通道情况中,会大幅度增加计算量,不利于工程上的实现。
然而,智能音箱设备多由一个扬声器和一个麦克风阵列组成。在多通道情况下,回声消除最直接的解决方案是在每个麦克风的输出端分别放置一个回声消除器,然而多通道回声消除MM-AEC(Multi Microphone Acoustic Echo Cancellation)算法的复杂度与麦克风的数量成正比。对于较长的自适应滤波器,MM-AEC 算法的复杂性既与麦克风数量成正比,又与回声消除器长度成正比,因此它很容易超过可用的计算资源。针对计算复杂度问题,文献[9]提出相对回声传递函数-AEC(Relative Echo Transfer Function-AEC,RETF-AEC)低复杂度算法,首先用扬声器播放信号当作参考信号,在短时傅里叶变换(Short Time Fourier Transform,STFT)域,利用单通道自适应滤波算法更新声学回声传递函数(Acoustic Echo Transfer Function,AETF),估计出第一通道回声,然后利用估计的第一通道回声当作其他通道的参考信号,来不断更新麦克风阵列之间的相对回声传递函数(RETF),最后计算出其他通道回声。因RETF 的长度比AETF 长度短,从而使MM-AEC 的总计算量降低。声学回声传递函数在立体声回声消除中也有广泛应用[10]。
当麦克风接收的信号不仅包含回声和目标语音信号,还包含背景噪声时,AEC 的最终目标是完全去除回声和背景噪声,使其只有目标语音信号。但在大混响、低回噪比条件下,自适应滤波收敛后,仍会有残留回声存在,学者普遍认为单独的AEC 无法抑制背景噪声和残留回声。单通道AEC 通常应用后处理技术[11-12]来抑制存在于回声消除输出后的背景噪声和残余回声。而MM-AEC 可以结合波束形成(Beam Former,BF)技术抑制背景噪声和残余回声[13-14]:可以在AEC后先应用BF 减少背景噪声,再通过后处理技术去掉残留回声;或者先在每通道AEC后应用后处理技术去掉残留回声,再应用BF技术减少背景噪声。该类算法残留回声和背景噪声需分开抑制。最近,文献[9]又提出了利用BF 技术联合去除残留回声和背景噪声的算法。该算法首先利用提出的RETF-AEC 算法去掉回声,再估计出残留回声和背景噪声,最后利用多通道维纳滤波(Multi-Channel Wiener Filter,MCWF)波束技术联合去除残留回声和背景噪声(简记为MCWF-AEC 算法)。由于RETF-AEC 算法还需要利用自适应滤波不断更新RETF,计算量并没有大幅度降低。且在低回噪比条件下,由于残留回声估计得过高,MCWF会使目标语音信号有一定的失真,影响语音可懂度。
针对上述两点问题,本文借鉴麦克风阵列语音去噪[15]的思想,在文献[9]的基础上,首先提出了一种改进的相对回声传递函数的多通道回声估计算法——ERETF-AEC(Estimate Relative Echo Transfer Function-AEC),该算法不需要自适应更新RETF,降低了算法的复杂度。随后,鉴于广义旁瓣抵消器(Generalized Sidelobe Canceller,GSC)算法在不同信噪比下的稳定性,又提出了ERETF-GSAEC(Estimate Relative Echo Transfer Function Generalized Sidelobe Canceller Acoustic Echo Cancellation)麦克风阵列快速回声消除算法。该算法利用改进的ERETF-AEC 回声估计算法替代传统GSC 算法的阻塞矩阵模块,能有效地避免阻塞矩阵构造不合适而造成的阻塞剩余和目标语音信号抵消等缺点;并且该算法不再需要残留回声估计,有效避免残留回声估计过高引起的问题,进一步减少在低回噪比(Echo Noise Ratio,ENR)下MCWF 算法对语音失真的现象,较好地保留目标语音信号的频域信息,提高语音可懂度。
1 智能音箱环境下的声学模型
如图1 所示,假设智能音箱设备由一个扬声器和一个麦克风阵列组成,回声路径为线性系统。
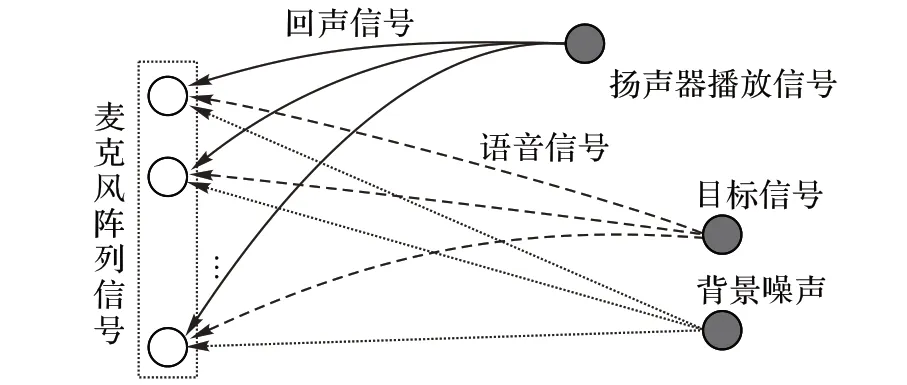
图1 智能音箱环境下的声学模型Fig. 1 Acoustic model in smart speaker environment
在STFT 域,令Sn(l,k)表示语音信号,Dn(l,k)表示回声信号,Vn(l,k)表示背景噪声,则第n个麦克风接收信号表示为:
Yn(l,k) = Dn(l,k) + Sn(l,k) + Vn(l,k) (1)其中:l、k、n 分别表示帧索引、域带索引、麦克风索引,n ∈{1,2,…,N}。当房间混响较大时,回声信号可以使用卷积传递函数(Convolutive Transfer Function,CTF)[16]近似表示为:

其中:
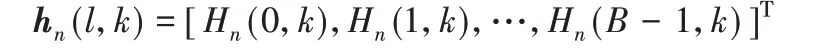
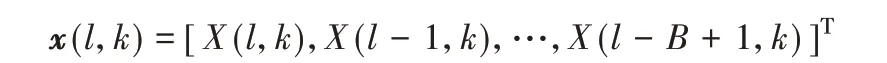
上脚标(·)Τ和(·)Η表示转置和共轭转置;hn(l,k)是扬声器和麦克风之间的第n 个AETF 向量;B 为hn(l,k)的长度;X(l,k)是扬声器播放的信号,鉴于AEC的特殊应用,X(l,k)是可以采集到的,通常在AEC中当作参考信号。
根据麦克风阵列的空间结构,类比相对传递函数(Relative Transfer Function,RTF)[17],第一通道与其他通道间的声学回声传递函数比或RETF表示为:
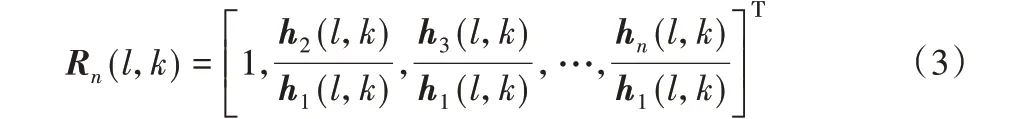
这里仅使用一个CTF[16]长度来近似表示RTF、RETF。则第n个麦克风接收信号可以改写为:
Yn(l,k) = Rn(l,k)D1(l,k) + Vn(l,k) + Cn(l,k)S1(l,k) (4)其中:Cn(l,k)为每通道目标语音信号的RTF。
2 ERETF-GSAEC回声消除算法
本文的ERETF-GSAEC 麦克风阵列快速回声消除算法框图如图2 所示,主要包括三部分:固定波束形成、噪声参考信号估计和自适应波束形成。
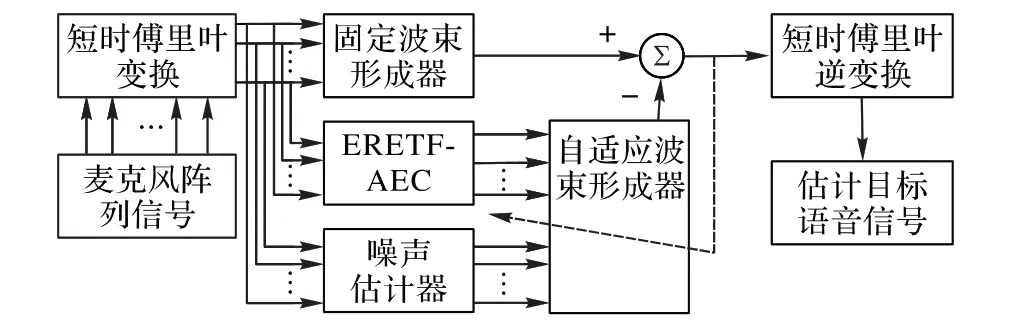
图2 ERETF-GSAEC回声消除算法框图Fig. 2 Block diagram of ERETF-GSAEC echo cancellation algorithm
2.1 固定波束形成
固定波束形成器是利用声源信号空间方位信息,最大限度输出期望方向内信号。本文算法采用文献[18]中的固定波束形成器,使得波束指向目标语音信号方向。
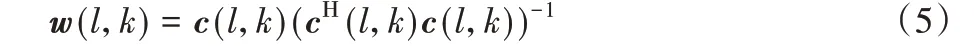
其中:

c(l,k)表示目标语音信号RTF向量;w(l,k)表示固定波束形成器权系数。则固定波束形成的输出为:

其中:y(l,k) =[Y1(l,k),Y2(l,k),…,YN(l,k)]Τ是麦克风阵列接收信号。YFBF(l,k)作为上支路语音参考信号。
2.2 噪声参考信号估计
如图3 所示,利用回声估计算法替代传统GSC 算法的阻塞矩阵模块,能有效地避免阻塞矩阵构造不合适而造成的阻塞剩余和目标语音信号抵消等缺点。
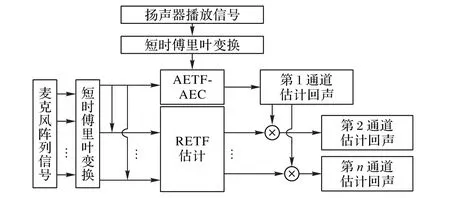
图3 ERETF-AEC回声估计算法框图Fig. 3 Block diagram of ERETF-AEC echo estimation algorithm
2.2.1 AETF-AEC算法
AETF-AEC 算法在STFT 域中采用自适应滤波技术,在没有语音信号存在时(即回声帧),不断更新扬声器和麦克风之间的AETF,利用估计的AETF 对扬声器播放信号进行滤波得到回声信号:

其中:“^”表示估计。当有语音信号存在时,停止更新,计算出回声,随后从麦克风信号中减去,从而使回声减少。则第一通道误差信号表示为:

该算法利用最小均方误差作为代价函数,使用梯度下降自适应算法进行更新,则更新等式表示为:
M1(l,k)是一个B × B的自适应步长矩阵,表达式为:

φx(l,k)表示相关矩阵,采用平滑方式得到,表达式为:
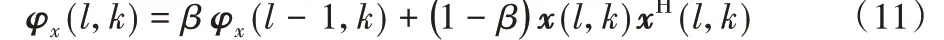
其中:μ 为固定步长;β 为遗忘因子。所以AETF-AEC 算法的复杂度与CTF长度即滤波器长度B成正比。
2.2.2 RETF估计
RETF-AEC 算法[9]利用自适应滤波算法来不断更新RETF。更新等式表示为:

其中:
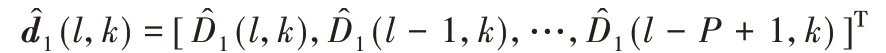
n ∈{2,3,…,N},P <B;Qn(l,k)是一个P × P 的自适应步长矩阵,与M1(l,k)计算相同。所以RETF-AEC 算法[9]计算量与滤波器长度P 成正比。由于自适应滤波算法较为复杂,并没有大幅度提高计算量。
RETF 由阵列的空间结构决定,当回声路径为线性系统时,RETF不随时间的变化而变化,并不需要时时更新,所以可以取出前1 s的语音,只需估计一次阵列间的RETF,之后便不再更新,作为定值,当作整段信号的RETF。本文RETF 估计算法在回声帧先估计出噪声信号,从麦克风信号中减去,再以第一通道为基准,得到估计的Rn(l,k),表达式为:
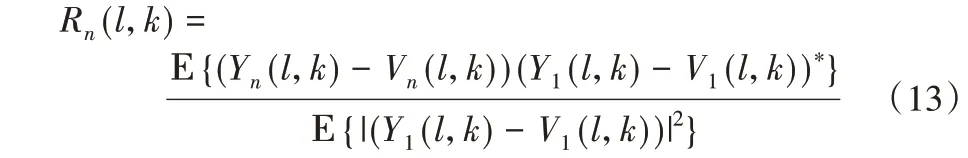
所以,当n ∈{2,3,…,N}时,回声估计可以表示为:
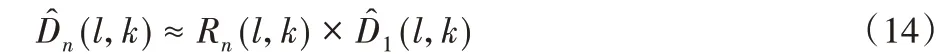
2.3 自适应波束形成
采用文献[18]中的自适应波束形成器,根据由固定波束形成得到的语音参考信号YFBF(l,k)和自适应波束形成噪声参YANC(l,k)之间的最小均方误差值来构建代价函数:

使用NLMS算法对波束形成器系数进行更新迭代:
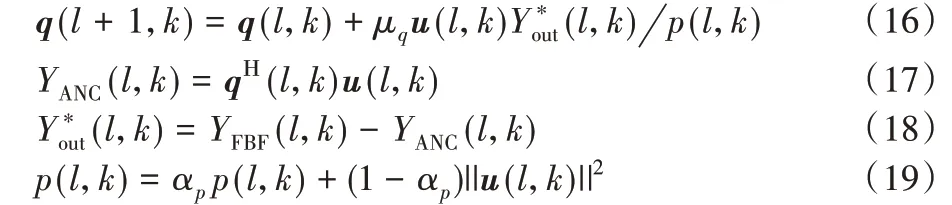
其中:
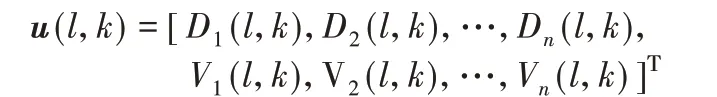
是噪声参考信号,由估计回声和估计噪声向量串联组成。
与RETF-AEC 算法[9]相比,本文ERETF-AEC 算法由于不需要自适应一直更新每通道的RETF 来估计回声,只需要利用每通道前1 s 的语音估计出RETF 作为定值,所以使估计回声的计算量降低。与MCWF-AEC 算法[9]相比,本文ERETFGSAEC 算法选择GSC 波束形成技术,将估计的每通道回声信号不直接从麦克风信号中减去,而是通过GSC 中自适应波束形成器去除回声和噪声。所以该算法不需要自适应估计每通道的残留回声,从而使波束形成计算量减少,同时避免了由于残留回声估计过高,而使目标语音失真的现象。
3 实验结果与分析
3.1 实验参数设定
按照实际设备的运行环境,设置本次实验仿真,模拟一个智能音箱设备,它由一个扬声器和一个麦克风阵列组成。麦克风阵列是由四个麦克风组成的均匀线性阵列,麦克风的间距是1.5 cm;扬声器与阵列中心之间的距离为10 cm;扬声器播放信号的到达方向设定为12°;此外,将所需的远场目标信号用另一个扬声器模拟,放置在距离阵列中心2.5 m,71°处;选择与扬声器最接近的麦克风作为主麦克风,即n=1。
实验使用文献[19]中的房间脉冲发生器,用镜像法对一个尺寸为(3× 5× 2.5)m3的房间产生两组AIR,每一组为有4个AIR。房间的混响时间设定为0.35 s。采样率为fs=16 kHz,避免由于AETF的模型不足造成的残留回声,截断AIR的长度L=1 536 个样本,选定的长度可确保截断的AIR 覆盖早期反射。
图4 为各语音时域信号波形。从酷狗音乐中下载音乐“最美的太阳”,截选12.5 s当作智能音箱扬声器播放信号,如图4(a)所示;通过将截断的第一组AIR 与扬声器播放信号进行卷积生成回声信号,第一通道回声信号如图4(b)所示;将互不相关的白噪声信号添加到麦克风信号以模拟不同的ENR;从标准TIMIT 语音库选取2.5 s 语音作为目标信号,如图4(c)所示,通过将目标信号与第二组AIR 进行卷积来生成语音信号,以第一通道的语音信号当作目标语音信号,如图4(d)所示。在第10 s 后,以回信比(Echo Signal Ratio,ESR)的方式将语音信号加到麦克风信号中。即0~10 s 属于回声帧。

图4 各语音时域信号波形Fig. 4 Each speech time-domain signal waveform
STFT 的长度K = 512,窗选择汉明窗,帧移R = 128,AETF滤波器长度B如下:其中:“「·」”表示取整。自适应滤波器固定步长为μ = 0.1,遗忘因子β如下:


3.2 回声估计实验结果与分析
将本文改进的回声估计算法ERETF-AEC 与RETF-AEC算法[9]进行性能比较。回声估计的性能采用回声返回损耗增益(Echo Return Loss Enhancement,ERLE)表示回声信号与残留回声的比值,值越高性能越好。

表1为ENR为-5 dB、0 dB、5 dB与10 dB的回声估计情况。表1 中数值为总时间段ERLE 的平均值,第一通道均使用AETF 算法来估计回声,总体来讲,在不同ENR 情况下,RETF-AEC 算法比第一通道AETF 算法值都略高,本文算法与第一通道AETF 算法值略低。本文算法和RETF-AEC 算法[9]性能相差不大。因此,本文算法能够在具有较好性能同时又能减少算法计算量,保证算法实用性。
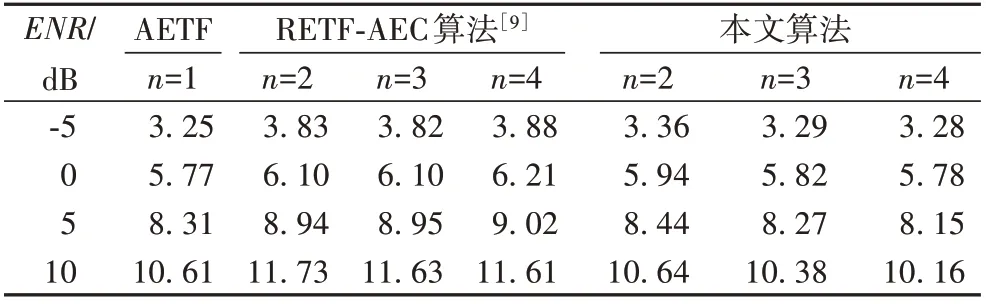
表1 不同回噪比下各算法平均ERLE比较Tab. 1 Average ERLE comparison of different algorithms under different ENR
如图5 所示,给出了ENR 为0 dB 时不同算法在有目标语音出现帧的回声估计时域信号波形。从图5 可知,三种算法均取得了较好的回声估计效果。
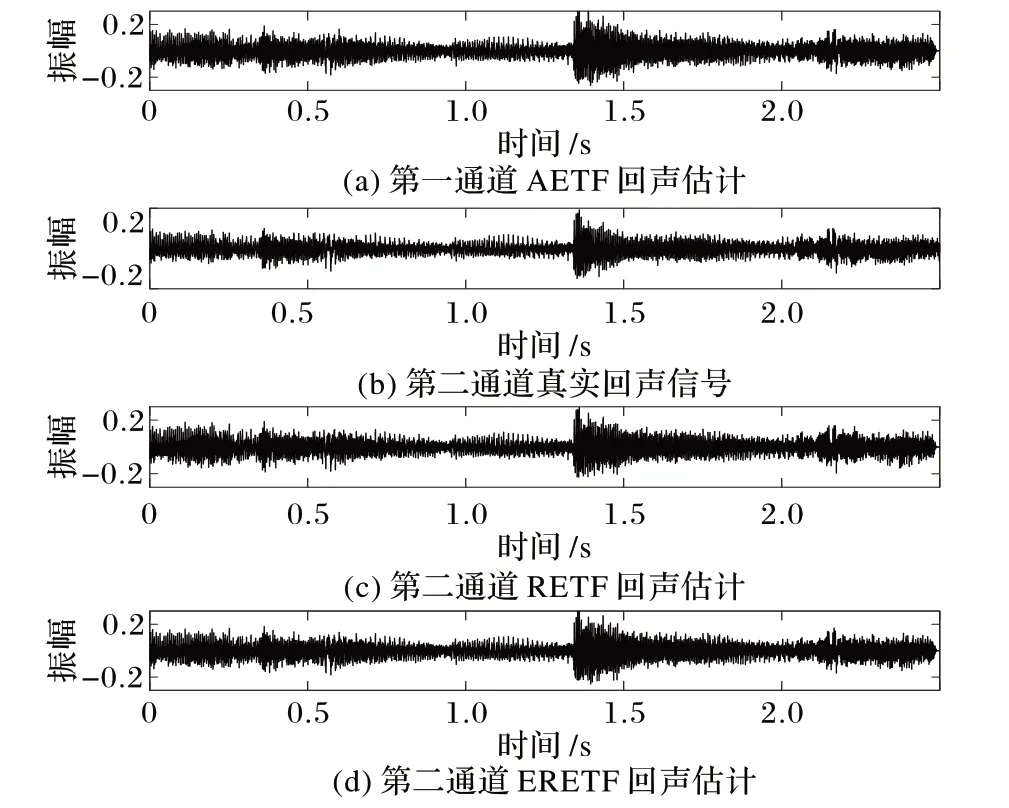
图5 回噪比为0 dB时不同算法的回声估计时域信号波形Fig. 5 Echo estimation time-domain signal waveform of different algorithms with ENR=0 dB
3.3 回声消除实验结果与分析
本文采用信源失真率(Signal Distortion Ratio,SDR)、语音短时客观可懂度(Short Time Objective Intelligibility,STOI)作为目标语音信号回声消除算法性能客观评估标准,对MCWFAEC 算法[9]和本文算法的性能在可懂度和失真方面进行评估,评估值越高算法的性能越好。
由于噪声估计算法并不在本文研究之内,所以采用真实噪声信号进行实验。目标语音信号的RTF在线下进行计算。
如图6 所示,给出了在ENR 为0 dB 和ESR 为0 dB 时两种算法波束形成后的时域波形图。从图6(c)中可以看出:MCWF-AEC算法[9]在能量较大的语音帧,有明显的语音失真;本文算法能较好地保证重构语音质量,实现回声消除和去噪。
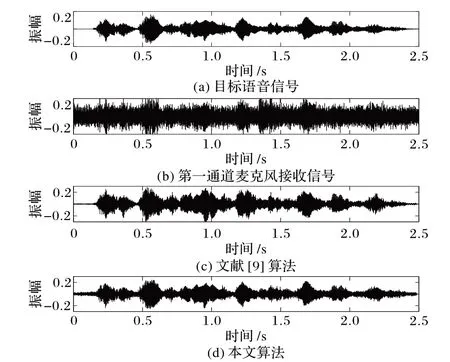
图6 回噪比和回信比均为0 dB时不同算法的目标语音时域信号波形Fig. 6 Target speech time-domain signal waveform of different algorithms with ENR=0 dB and ESR=0 dB
如表2 所示,给出ESR 分别为-5 dB、0 dB、5 dB,ENR为-5 dB、0 dB、5 dB 与10 dB 时回声消除情况。ESR 小于0 dB时,表示回声能量比语音信号能量低,这时回声消除性能最高。正常情况下,回声信号与语音信号能量相差不大,即ESR为0 dB 一旦回声信号比语音信号能量大,即ESR 大于0 dB时,回声消除性能会下降。总体上看,本文算法SDR 与STOI评估指标存在着明显优势。这说明对于噪声环境与回信比的变化,ERETF-GSAEC 模型能够更好地消除回声和抑制噪声,能更好地提高目标语音可懂度,减少语音失真。
信号语谱图颜色的深浅和清晰度能够反映语音信号能量的大小和语音的质量。如图7 所示,给出了MCWF-AEC 算法[9]和 本 文 算 法 在ENR 和ESR 均 为0 dB 时 的 语 谱 图。从图7(d)可以发现,在该条件下回声和噪声分布在整个频段,语音受到严重干扰,目标语音信号几乎被淹没。图7(e)显示MCWF-AEC 算法虽然能够很好地减少回声和噪声的影响,但在低回噪比情况下,由于MCWF-AEC 算法残留回声估计过高,会过度地去除回声和噪声,使一些频点丢失,导致语音失真。本文ERETF-GSAEC 算法通过自适应波束形成去除回声和噪声,在保证去噪的情况下,频点不丢失,这是由于采用GSC 波束形成算法在不同信噪比下具有较强的稳定性。因此,本文算法能够有效地减少目标语音失真,提高回声和噪声抑制的能力。

表2 不同回信比和回噪比下各算法SDR与STOI得分Tab. 2 SDR and STOI scores of different algorithms under different ESR and ENR

图7 回噪比和回信比均为0 dB时不同算法的语谱图Fig. 7 Spectorgrams of different algorithms with ENR=0 dB and ESR=0 dB
4 结语
考虑到多通道回声消除的复杂性,本文提出了相对回声传递函数的多通道回声估计算法——ERETF-AEC,能使计算量减少;然后结合ERETF-AEC算法又提出了一种麦克风阵列快速回声消除算法——ERETF-GSAEC,以有效地避免阻塞矩阵构造不合适和残留回声估计过高而引起目标语音信号失真的现象,获得更好的目标语音信号。实验结果表明,在不同回噪比和回信比下从回声估计和目标语音信号信源失真率和可懂度三方面,客观评测参数显示本文算法有效地抑制了回声和噪声,减小了语音的失真度。未来可以在立体声加麦克风阵列回声消除方向进行研究。
猜你喜欢
家庭影院技术(2021年7期)2021-08-14
家庭影院技术(2021年3期)2021-05-21
成都信息工程大学学报(2021年6期)2021-02-12
数字海洋与水下攻防(2020年6期)2020-12-25
移动通信(2020年9期)2020-11-06
现代电子技术(2020年3期)2020-08-04
科技与创新(2020年8期)2020-05-08
演艺科技(2019年11期)2019-03-30
小学科学(2016年12期)2017-01-06
电脑爱好者(2016年24期)2017-01-05
