
基于本体特征的影评细粒度情感分类
2020-06-01 10:55侯艳辉董慧芳崔雪莲
计算机应用 2020年4期
侯艳辉,董慧芳,郝 敏,崔雪莲
(山东科技大学经济管理学院,山东青岛266590)
(∗通信作者电子邮箱Coolhyh@126.com)
0 引言
随着国民经济水平的提高,电影已经成为一种大众化的休闲娱乐方式。网络媒体的发展进一步扩大了电影的影响范围,繁荣的前景也加剧了电影行业的竞争。如何把握消费者偏好,创作出高质量、受欢迎的影视作品是制片方始终要考虑的重大问题。
与搜索型产品不同,电影属于体验型产品,需要体验过之后才有具体的效用感知。影评作为一种重要的信息载体,传达了评价者的情感态度,影响着潜在消费者的购买决策。已有研究说明了在线电影短评的研究价值[1-4],这为影评的情感分析奠定了理论基础。海量的在线影评也为研究分析提供了丰富的数据资源。对影评进行情感分析能够了解消费者偏好,进而为制片方制片和宣传提供参考依据,为消费者购票决策提供意见支持。
本文针对影评情感分析中对电影特征关注度不足,对文本粒度和情感强度划分粗糙的现状,从特征-观点对视角,在文本粒度和情感强度两个方面对中文影评进行情感细粒度分析。
1 相关工作
文本粒度、情感强度、分类算法这三个方面的确定是完成情感分类任务的三个渐进子任务。鉴于此,本文将针对这三个方面的现有研究成果进行述评。
1.1 情感分析中文本粒度
情感分析中文本粒度的研究现状主要分为两个层次,分别为基于文档级、句子级的粗粒度分析和基于评价对象及其属性的细粒度分析。由于搜索型产品有产品说明书作为属性参考,所以基于评价对象及其属性的细粒度分析主要针对搜索型产品的在线评论。在属性细粒度文本分析的基础上,尹裴等[5-6]又针对搜索型产品提出了基于本体的特征观点对的情感分析方法。相对而言,对于体验型产品在线评论的文本研究粒度远不如搜索型产品。聂卉等[7]以书评为研究对象借助情感词典与主题模型LDA(Latent Dirichlet Allocation)方法识别了正负情感倾向;樊振等[8]利用影评数据实现了评论文本的自动标注并提高了情感分类的准确性。但两者的研究都未涉及属性特征层面的分析。侯银秀等[9]利用图书评论语料实现了用户对图书属性情感偏好的个性化推荐,但研究文本为英文,由于中英文之间的差异,研究成果较难直接应用于中文评论。目前还没有利用基于本体的特征观点对的方法对体验型产品的在线评论进行情感分析的研究。
1.2 情感分析中情感强度划分
情感分析的另一重要任务是对情感强度的界定,国内外学者已经对情感强度分类进行了深入的研究。这里的情感强度不仅指一种情感上的程度量化(如:开心、比较开心、很开心等),而且指各种情感的分类(如快乐、愤怒、焦虑、悲伤等)。鉴于人类情绪的多维性、多变性,研究通常将情感强度进行离散化,但是并没有统一的分类标准[10]。在情感强度划分方面,目前比较有代表性的研究成果如表1所示。

表1 代表性的情感强度划分对比Tab.1 Comparison of representative emotional intensity classifications
对于搜索型产品评论的情感强度划分为二分类(正负)和三分类(积极、消极、中性)即可满足消费者肯定或否定的态度识别;但对于体验型产品评论而言,此种划分方式不足以描述消费者丰富的体验情感。已有学者将更细腻的情感强度与产品评论相结合进行研究,如:刘丽娜等[11]研究了满意、失望、赞美、谴责、喜爱、讨厌6 种离散情感在评论星级中的分布;聂卉等[7]研究了乐、好、怒、哀、惧、恶、惊7 种情感在图书评论中的分布。因此,对于影评的情感强度划分也应考虑多分类的情感强度。
1.3 情感分析中分类算法
分类算法的准确性是情感分类任务能否完成的关键。对于影评的情感分类问题现有研究方法主要有:基于情感词典、基于机器学习、基于神经网络以及算法融合四类研究方法[16]。基于情感词典的研究方法主要通过扩展情感词典对影评进行情感分析。如Mishra 等[17]扩展了电影和酒店词汇资源,提高了分类准确性。基于机器学习用到的方法主要有朴素贝叶斯、决策树、支持向量机等。如:Anand 等[18]基于聚类方法实现了影评属性的情感分类;Tripathy等[19]验证了在影评数据集中支持向量机比朴素贝叶斯算法分类准确度更高;García-Díaz 等[20]在影评数据集上训练了朴素贝叶斯分类器,提高了情绪分析的准确性。基于神经网络的方法提升了模型的推广能力。如:Lee 等[21]基于卷积神经网络计算了影评中句子整体的情感倾向。基于算法融合的方法相对于单一的算法能够在一定程度上提高模型的准确率。如:Khan 等[22]融合了机器学习与基于词汇的方法提高了影评情感分类的准确性;Araque等[23]结合词嵌入模型和线性机器学习算法实现了基于神经网络的影评情感分类。由于情感分析具有领域依赖性,不同的模型在不同的任务上有不同的表现,对于方法的优劣不能一概而论。
2 基于本体特征的影评细粒度情感分类方法
2.1 电影本体概念模型构建
本体被人工智能领域引入特指概念化的规格说明。已有国内外学者对电影本体进行了探索。如Peñalver-Martinze等[24]提出了电影本体概念模型,属性层面包括电影、导演、演员、影片类型。姜霖等[25]构建了内容、形式、价值的本体模型。但存在如下不足:前者“电影”属性包含范围大、概念模糊;后者“内容”属性符合非专业人士观影人群的评价认知体系,但部分“形式”属性、“价值”属性在短评中较少体现,直接应用现有模型会造成特征混淆和特征稀疏。故本文在前人研究的基础上,重新构建属性特征,并验证特征的有效性。
借鉴尹裴等[5]的研究并加以改进。构建电影本体四元组,即S ={Cid,Cterm,Csynanym,Chyponym}。其中:Cid表示特征唯一标识符;Cterm表示特征;Csynanym为同义词集;Chyponym为下位词集。由于影评的特殊性,对于某一个特征词如“演技”只用来形容人物,“彩蛋”只用来形容剧情,其标识性唯一。因此,去掉隶属度概念只基于特征构建本体概念模型。电影本体概念模型示例如表2所示。

表2 电影本体概念模型示例Tab.2 Examples of movie ontology conceptual model
利用TF-IDF 算法、TextRank 算法对预处理后的文本提取关键词。为了提高特征的代表性,取关键词的交集作为候选特征词。再考虑与电影特征有关的其他关键词进行人工筛选,构建电影本体概念模型。电影本体概念模型的特征描述如表3所示。

表3 电影本体概念模型的特征描述Tab.3 Feature description of film ontology conceptual model
利用构建的电影本体概念模型,分析观影人重点关注的电影特征。由于中性评论难以说明偏好,分析时不考虑中性情感的评论。观影人对电影特征的关注度如图1所示。
从图1 可看出,观影人对故事(story)属性关注度最高,其次 是 题 材(theme)、人 物(character)、场 景(scene)、导 演(director)等特征。这说明电影制作、影片宣传要依次考虑故事、题材、人物、场景、导演五个方面的特征;若资源有限应优先考虑影片故事、题材、人物三个方面的特性,抓住观影人的眼球。
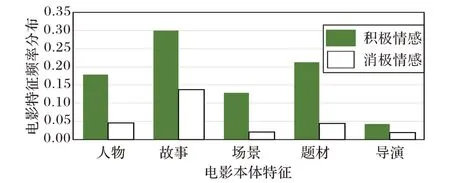
图1 观影人对电影特征的关注度Fig. 1 Viewer's attention to movie's features
至此,本文融合了前人在电影领域的本体概念模型和在搜索型产品领域的本体建模方法,构建了电影本体概念模型。为下一步在电影特征层面识别观影人电影属性偏好做好基础工作。
2.2 情感强度划分
为细化当前三分类(积极、消极、中性)为主的情感强度划分现状,本文借鉴了普鲁契克多维度情绪模型,首次将其引入到电影影评的情感偏好研究,以实现情感强度上更细粒度的划分。
Plutchik被认为是情感研究领域的思想领袖,提出了情绪心理进化理论和一种多维度情绪模型,即著名的“普鲁契克情感之轮”[5,15]。本文在考虑情感词典情感值的基础上,选取该模型作为情感强度划分的标准。根据Plutchik 提出的多维度情绪模型,将情感强度(1:积极,0:中性,-1:消极)三分类拓展为(-4~4)八分类,其中(+4:狂喜,-4:悲痛)、(+3:钦佩,-3:厌恶)、(+2:令人惊异,-2:警惕)、(+1:恐怖,-1:愤怒),0代表中性,来进行更细粒度的情感分类。影评的情感态度不同于普通产品评论的情感态度,如:“恐怖”在一般产品评论中为负向情感,而在影评评论中该词反映了电影的情节吸引力或令人印象深刻的视听效果,对于一部电影的制作是一种肯定的评价,所以情感值为+1。
2.3 情感分类方法设计
为实现在特征粒度层面和多维度情感强度下的细粒度情感分类模型,本文提出了一个将电影特征属性和普鲁契克多维度情绪模型与双向长短时记忆网络融合的算法。具体思路为:利用电影本体概念模型,在情感词典中匹配特征观点对,得到电影特征属性偏好;利用普鲁契克多维度情绪模型按2.2 节的划分标准,将情感值细化为八分类;再利用Bi-LSTM神经网络进行情感分类。
在此基础上,为验证该模型的有效性,文章还设计了单纯基于情感词典、机器学习、Bi-LSTM网络的3种算法,在整体粒度和三分类情感强度下的分类模型。具体阐述如下:
1)基于情感词典的方法:采用BosonNLP 情感词典(玻森情感词典)匹配特征观点对。该词典是从微博、新闻、论坛等数据来源的上百万篇情感标注数据中自动构建的情感极性词典,共包括114 767个词语,满足日常评论的常用语覆盖。
2)基于机器学习的方法:本文采用了5 种特征提取算法构建文本特征。其中:①利用词频(Term Frequency,TF)计算某一个给定的词语在该文档中出现的次数;②利用潜在语义分析(Latent Semantic Analysis,LSA)通过分析文章来挖掘文章的潜在语义;③利用词频逆文档频率词频-逆文档频度(TFInverse Document Frequency,TF-IDF)计算一个词对于文档集中某个文档的重要程度;④利用主题模型LDA 计算文档集中每篇文档的主题概率分布;⑤利用Doc2Vec 计算句子向量表达,通过计算向量之间的距离来找句子之间的相似性。
3)基于Bi-LSTM 网络的方法:引入基于人民日报预训练的词向量,利用双向长短时记忆网络模型进行训练。Bi-LSTM是长短时记忆网络的一种改进,能更好地对序列数据进行表达,尤其是有语言顺序的文本数据。通过Bi-LSTM 可以更好地捕捉双向的语义依赖。
3 实验与评价
3.1 实验步骤设计
首先,对文本进行预处理;接着,提取电影特征,构建电影本体概念模型;然后,分别从文本粒度和情感强度两个方面进行粒度细化。其中,文本粒度指影评句子整体和影评特征属性的不同划分。实验基本流程如图2所示。

图2 实验基本流程Fig.2 Basic flowchart of the experiment
3.2 实验数据与预处理
1)数据获取:选取国内影响力较大的电影网站——豆瓣电影,以最近热门电影作为实验对象。通过网络爬虫爬取了201 部电影影评,去掉只有数字和词数小于2 的评论,最终得到32 762条在线短评数据。
2)标签标注:以星级评分作为标注信息,将其分为三种情感强度:1、2 星级标注为-1,4、5 星级标注为+1,3 星级标注为0。随机对其中的6 070 条评论进行人工标注,标注时基于前文构建的本体模型进行情感打分(消极:-1,积极:1,中性:0),以属性值的线性加和作为本条评论的总体情感倾向。并通过了Kappa 统计量的一致性检验,说明了标注信息的无偏性。对标注比例进行统计,其中,中性情感占34.78%,积极情感占44.12%,消极情感占21.10%,说明标注类别基本平衡。
3)预处理过程:分词(jieba,结巴分词)→去停用词(利用自己构建的停用词表)→词性标注。
4)实验环境:Python3.6、Pycharm。
3.3 实验方法与结果
实验将数据划分为75%的训练集和25%的验证集,模型评估指标为F1值。下文报告的准确率均为10 折交叉验证后模型在验证集上的F1值。
3.3.1 基于影评整体层级的情感分类
实验1(dic) 利用情感词典的方法。将预处理后的评论与BosonNLP 情感词典匹配,以标记信息作为标签,计算影评整体的情感倾向。
实验2(ml) 利用机器学习的方法。通过2.3 节中提及的特征工程对预处理后的文本提取电影特征。具体思路如下:提取词频特征(TF),利用LDA 主题模型降维为LDA 特征;提取词频逆文档频率特征(TF-IDF),利用截断奇异值分解(Truncated Singular Value Decomposition,TSVD)降维为LSA特征;利用Doc2vec 算法将原始数据数字化为Doc2vec 特征。最后,将LDA、LSA、Doc2vec 三种特征进行融合,并将得到的特征转换为稀疏矩阵,合并到TF-IDF 特征中,完成特征组合。最后,使用LinearSVC(Linear Support Vector Classifier)算法进行分类。
实验3(nn) 利用神经网络的方法。引入人民日报预训练的词向量,基于kashgari 开源框架,利用Bi-LSTM 模型进行数据训练。
实验结果分析:实验1(dic)的准确率为48.7%。通过实验发现,仅用情感词典对影评进行整体粗粒度分析结果很不理想。实验2(ml)的准确率为55.1%。与实验1(dic)相比,模型分类的准确率有6.4 个百分点的提升,说明基于机器学习的方法能学习到更多的数据特征,但模型准确率仍不理想。实验3(nn)的准确率为93.7%;与实验2(ml)相比,模型分类的准确率有38.6 个百分点的提升,实验结果较理想,但基于整体层级的影评分析,不能满足当前市场分析的需求。
3.3.2 基于影评特征层级的情感分类及情感强度细分
由于需要特征属性情感值的标签,以下实验以人工标注的数据集作为实验数据。
实验4(dic+tz) 利用情感词典的方法。在实验1(dic)的基础上,利用电影本体概念模型匹配特征观点对,计算特征层面的情感倾向。
实验5(nn+tz) 融合情感词典的神经网络模型。在整体层级分类表现最好的模型(即实验3(nn))的基础上,结合实验4(dic+tz)匹配到的特征观点对进行特征层面的情感分析,并设置情感强度为积极、消极、中性三个等级。
实验6(nn+tz+ei) 情感强度细分实验。在实验5(nn+tz)构建的Bi-LSTM 模型的基础上,根据Plutchik 提出的多维度情绪模型,利用情感词原有的分值进行情感强度细分,分值所代表的情感按2.2 节的说明进行划分,情感强度范围为-4~4,在情感强度层面进行研究。
实验结果分析:实验4(dic+tz)的平均准确率为78.5%,与同利用情感词典方法的实验1(dic)对比可知,基于特征层级的情感分类比基于整体层级的情感分类准确率提高了29.8个百分点。这不仅验证了本文构建的本体概念模型的有效性,而且也说明了基于特征层面的细粒度情感分类更容易识别评论人的情感倾向。实验5(nn+tz)的平均准确率为90.2%,模型准确率虽略小于整体层级的最优结果,但比基于特征层级的情感词典方法(即实验4(dic+tz))的准确率提高了11.7 个百分点且分类效果也较理想。基于特征层面的情感分析有利于了解消费者在电影各个特征层级的情感偏好,更有助于市场分析。实验6(nn+tz+ei)的平均准确率为93.0%。其中,情感强度高的情感词能被完全识别,相对于情感强度三分类的融合算法(即实验5(nn+tz))准确率提高了2.8 个百分点。这说明对情感强度细化分类准确率仍有提升空间,即多维情感强度细粒度有利于实现更准确的情感分类。
实验4(dic+tz)匹配到的特征观点对的举例说明如表4 所示,为了便于阅读,对语序稍作一些调整。实验4 在特征层级的准确率如表5所示。
从表6所示的实验结果可看出:
1)实验3(nn)基于神经网络对影评整体层级进行情感分类的模型表现最好,但它无法区别电影特征层面的情感倾向。实验6(nn+tz+ei)分类效果也较理想,并实现了基于影评特征和情感强度的情感细粒度划分,验证了研究的理论价值和实践意义。
2)在相同文本粒度和情感强度水平上,基于情感词典、机器学习、神经网络算法的分类准确率逐步提升,如实验1(dic)、实验2(ml)、实验3(nn)的模型分类结果对比,实验4(dic+tz)和实验5(nn+tz)的模型分类结果对比。这说明随着模型复杂度增大,学习到的数据特征越多,分类越准确。
3)在不同文本粒度和情感强度水平上,即使用同一种算法进行处理,其分类准确度也会随粒度细化得到一定幅度提升,例如:实验1(dic)和实验4(dic+tz)的对比,同用情感词典的方法对不同文本粒度进行分析,结果从48.7%提升到78.5%,准确率提升29.8 个百分点。实验5(nn+tz)和实验6(nn+tz+ei)的比对,同用词典与神经网络融合的算法对不同情感强度划分水平进行分析,结果从90.2%提升到93.0%,准确率提升2.8 个百分点。以上两点再次说明了情感分析任务从文本粒度和情感强度两个角度对文本进行细化研究的科学性。
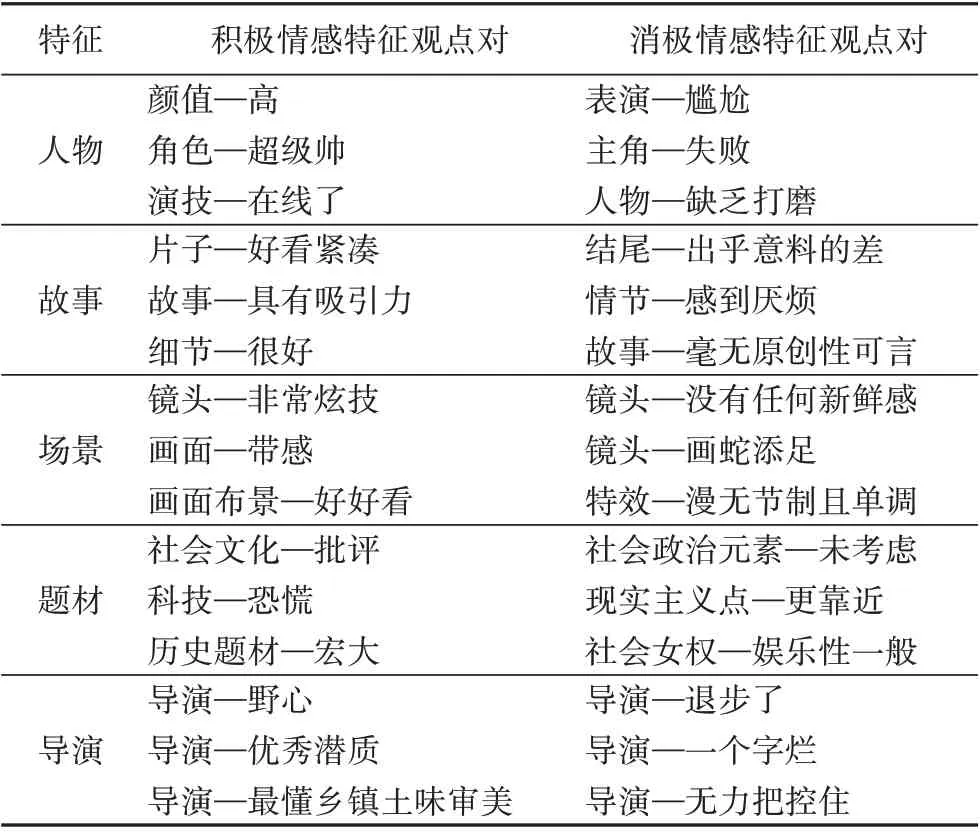
表4 特征观点对(举例)Tab.4 Feature view pairs(examples)
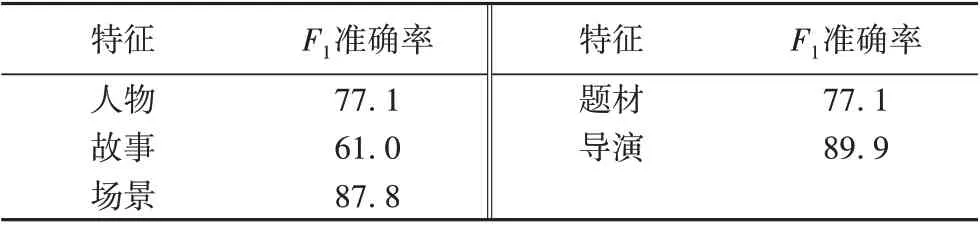
表5 实验4特征层级的准确率 单位:%Tab.5 Accuracy in the experiment 4 on feature level unit:%

表6 模型实验结果汇总表Tab.6 Summary of model experiment results
4 结语
本文以在线电影短评为研究对象,利用基于本体的特征观点对的研究方法,在不同文本粒度和不同情感强度上进行细粒度情感分类研究,细化了影评情感分类的粒度,有利于制片方电影制作和宣传,同时为消费者购票决策提供意见参考。本文研究结论如下:
首先,通过构建电影本体概念模型,分析得出:观影人对电影本体特征的关注度依次为故事(story)、题材(theme)、人物(character)、场景(scene)、导演(director)特征。其次,本文提出了一种针对影评本体特征和融合普鲁契克多维度情绪模型的情感分类模型。同时,对比分析了不同文本粒度、不同情感强度、不同实验方法对分类准确率的影响。实验结果表明,本文提出的分类模型,不仅具有较高准确率,而且还能提供观影人对电影本体特征和情感强度的偏好,实现了影评更细粒度的情感分类。
由于时间和人力限制,实验所用数据集较小,实验所用方法有限。其次,电影特征中“人物(character)”特征的划分没有将表演人员和电影中塑造的人物相区别,希望在未来的研究中能够加以完善。
猜你喜欢
齐鲁艺苑(2022年1期)2022-04-19
建材发展导向(2021年7期)2021-07-16
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
哈哈画报(2021年10期)2021-02-28
健康体检与管理(2021年10期)2021-01-03
新高考·高一物理(2016年7期)2017-01-23
新高考·高一物理(2016年7期)2017-01-23
新高考·高一物理(2016年7期)2017-01-23
