
面向移动应用识别的结构化特征提取方法
2020-06-01 10:58陈曙晖
计算机应用 2020年4期
沈 亮,王 鑫,陈曙晖
(国防科技大学计算机学院,长沙410073)
(∗通信作者电子邮箱shchen@nudt.edu.cn)
0 引言
随着移动互联网基础设施建设不断优化升级以及智能手机的快速普及,我国形成了全球最大的移动互联网应用市场。中国互联网络信息中心(China Internet Network Information Center,CNNIC)发布的第43 次《中国互联网络发展状况统计报告》显示,截至2018年12月,我国市场上监测到的移动应用程序在架数量为449万款[1]。面对数量庞大的移动应用,如何高效、准确地识别这些应用的流量,对于网络运营和管理机构具有重要的意义,这是研究差异性服务、流量控制、恶意应用识别以及用户行为分析的前提和基础。
网络流量识别是指通过对网络流量的分析,确定网络流量对应的应用协议,并基于此对网络流量进行分类。在传统的互联网平台上,主要通过端口识别[2]、深度包检测(Deep Packet Inspection,DPI)[3-4]、基于主机行为或流量行为的识别技术[5-6]、协议逆向[7]和机器学习[8-10]等技术来实现。传统网络识别大多只能进行粗粒度的流量识别,如网络流对应的应用层协议、恶意流量识别、异常流量检测等。
在传统网络流量识别技术的基础上,很多研究工作专门针对移动应用的特点提出了相应的识别方法。当前的主要研究方向是对应用超文本传输协议(Hyper Text Transfer Protocol,HTTP)流的识别。这是因为绝大部分移动应用都是通过HTTP 和超文本传输安全协议(Hyper Text Transfer Protocol over Secure socket layer,HTTPS)与服务器进行通信[11],而这两种协议的实现机制不同,需要分开研究。Xu等[12]通过提取移动应用网络流量中的应用标识符(唯一标识应用的数字或字符串,如Youku、taobao_android 等)来识别应用流量。他们根据互联网服务提供商提供的网络流量,对移动应用特征进行了大规模研究,提出使用HTTP 报文中的User-Agent字段来识别应用程序。但是,Tongaonkar 等[13]在对超过10 万个Android 和iOS 应用程序研究后发现,iOS 系统的许多应用程序都遵循在User-Agent 字段放置应用标识符的规则,但Android系统的应用程序并没有强制遵循这一规则。因此,该方法并不适用于识别Android应用。
Dai 等[11]构建了一个应用特征生成系统NetworkProfiler。应用特征有两个组成部分:第一部分由主机名Host 组成;第二个部分是将HTTP请求行中的请求方法(Get/Post/Head 等)、请求路径名和查询关键字及其值域中的固定不变内容转换为状态机。NetworkProfiler 只是获取HTTP报文请求行中的固定字符串和Host 作为应用的特征,存在以下两个问题:1)当前主流应用朝着体系化、平台化方向发展,应用相互集成,如手机QQ 中集成了QQ 空间、微视、QQ 音乐、京东购物等。当多个关联应用从同一个服务器获取数据时,产生的报文在Host、请求行等位置可能完全一致,NetworkProfiler 忽略了其他位置可能存在的有用信息,难以有效识别关联应用的流量。2)为了对抗网络监听和爬虫,应用开发人员引入可变路径技术,对请求行中的关键路径段和参数值进行编码或加密,NetworkProfiler难以有效识别这类流量。
Ranjan 等[14]将应用安装包进行反编译,从配置文件中获取指定HTTP 消息报头的值作为特征。这种方法不需要采集应用流量,直接从应用市场下载应用安装包即可获得研究数据。但是也存在两个比较突出的问题:1)不同应用在开发时所遵循的规范不统一,面对数量庞大的应用,难以形成有效的自动化方法将应用配置文件中的全部有用信息结合起来;2)需要人工设计应用特征的构成,可能会忽略应用自定义的HTTP报头及其内容,而这些信息是识别应用流量的关键。
也有研究者[15-16]尝试利用卷积神经网络(Convolutional Neural Network,CNN)进行准确的移动应用流量识别。将数据包转换为固定长度的向量,利用CNN 提取HTTP 中的抽象统计特征,并为每个应用程序建立了一个检测模型。这种做法的好处是实现了应用HTTP 特征无关化,存在的主要问题有:1)需要较大的样本集才能实现较好的效果;2)模型比较复杂,难以在网络上进行在线实时检测,更适合做离线处理;3)背景流量对分类器的性能影响较大。
移动应用流量识别存在比较突出的难点,就是没有可用的移动应用网络流量集。有研究者[17]使用移动平台上的虚拟专用网络(Virtual Private Network,VPN)应用程序编程接口(Application Programming Interface,API)来获取应用程序生成的网络流量。这种方法能够将应用程序与网络流相关联,可用于构建移动应用的流量数据集。
从以上研究可以看出,对移动应用流量识别主要采用两种技术:DPI 和机器学习。以上研究都能够解决一定的问题,但是都存在局限性:1)DPI 和传统的机器学习算法如支持向量机、随机森林等,都需要预先设计特征,这样会丢失应用流量中广泛存在的个性化信息,可能导致识别效果不理想;2)深度学习虽然实现了特征无关化,但是模型复杂,难以进行在线实时检测,用于处理加密的HTTPS流量可能更加合适。
由于HTTP 流中的字符可见,其中有足够多的可用信息,关键是如何获取这些信息来构建有效的应用流量特征。本文针对移动应用HTTP流量,提出了一种基于传统DPI技术的移动应用HTTP 流结构化特征提取方法。与现有工作的不同之处在于:1)不需要预先设计特征,对数据不作特殊处理,可以保留报文中的全部特征片段,直接采用HTTP 报文结构作为聚类标签,适用于所有HTTP 流;2)在提取应用特征前先进行一次聚类,避免了对毫无关联的流进行操作,既便于保留报文中的共同点,也便于发现不同点;3)实验数据全部来自现实环境,结果更加可靠,通过开发一款基于Android 的流量采集工具,在设备端捕获流量的同时精确地为每条数据流产生标签,此标签可以确定每一条流的归属,避免了其他流量获取方法带来的不确定性。
1 结构化特征提取系统框架
本文构建了一个基于DPI 的移动应用特征提取系统,由流量采集、预处理、特征提取、特征筛选4 个模块组成,如图1所示。

图1 移动应用特征提取系统基本框架Fig.1 Basic framework of mobile application signature extraction system
1)采集流量。从流量入手开展移动应用特征提取研究,首先要获取移动应用的网络流量。由于没有标准的移动应用流量数据集可供使用,研究者要独立采集移动应用的流量。采集流量必须要解决网络流的实际归属问题,即采用一定的技术手段来准确判定每条网络流是由哪个应用的产生的;否者,从不纯净的应用流量中提取的特征将存在很大的误差。本文将在2.1节介绍标签化的流量采集方法。
2)预处理阶段。根据报文的五元组信息将采集的混合网络流量进行重组,形成独立的网络流。在完成流重组后剔除非正常流以及利用HTTP 报文进行DNS 查询的数据流。正常的HTTP 流必须具有完整的TCP 连接建立过程,且服务器返回的状态码为“2XX”系列。最后获取HTTP 请求报文的载荷信息,存入对应的应用程序流量库中,每条载荷信息代表一条网络流。
3)特征提取阶段。将每个应用的流聚类成具有相同结构的集合,并分别提取每个集合内所有流的最长公共子序列(Longest Common Sequence,LCS),最后替换掉LCS 中的可变字段和无关信息,就形成了每一类流的字符串特征。
4)特征筛选阶段。将多个关联应用的相同特征进行筛选,根据该特征代表的网络流在不同应用中出现的频率来判定特征最后的归属。
2 关键技术实现
2.1 标签化流量采集
标签化流量采集就是通过一定的技术手段确定每一条网络流的归属。由于不同的手机操作系统原理不同,目前我们开发了一款基于Android的免Root流量采集工具NetLog,通过Android4.0+提供的VPN Service 模块监听设备上所有应用的接口。NetLog 在开启后会自动记录设备产生的网络流量,每隔一定时间生成一个pcap 文件及相应的网络流标签文本,并压缩上传至服务器。流量标签如图2 所示,包括开始的时间、应用名称、协议类型(TCP/UDP)、源IP地址、源端口号、目的IP地址、目的端口号。通过该标签,可以在后续的预处理阶段对pcap 文件中的混合流量进行精确的区分,从而得到纯净的应用流量。

图2 Netlog流量标签Fig.2 Traffic labels of Netlog
2.2 结构化特征提取
移动应用操作界面很多,功能十分丰富,为了实现每一个界面的每一种功能,应用需要向对应的服务器请求数据。针对这些功能,开发人员会在应用中制定对应的数据获取计划,在应用运行过程中触发时就形成了不同类型的网络流。网络数据获取计划的内容包括采取的数据传输协议(HTTP、HTTPS等)、请求路径、各种参数名及参数值、各个字段的先后顺序、不同字段之间的分隔符等。网络数据获取计划相当于构建了一个流量框架,当触发时各个字段填充上相应的数据就构成了现实中的网络流量。由于不同公司的应用开发规范不同、不同开发人员的个人习惯不同,应用每一种功能所对应的网络数据获取计划可能存在差异,这些差异最终会体现在报文中,而这正是流量特征。
本节将介绍如何提取应用HTTP流的结构化特征。
2.2.1 流聚类
在对应用流量进行分析后发现,应用在获取不同的数据时产生的HTTP 请求报文存在较大的差异。当请求方法、报文结构、服务器域名有任意一处不同时,报文可能完全不同。本文期望在提取应用流量特征时保留报文的结构,为此,需要将每个应用的HTTP 流进行聚类,使每一类流趋向于相同的数据获取行为。在进行多次聚类实验及效果评估后,制定了流聚类标签,聚类标签由HTTP 请求报文的请求方法、消息报头及其先后顺序、Host或路径中的域名组成,这个标签适用于任何移动应用HTTP 流,当两条流的标签一致时则认为是同一类流,具体流程如图3所示。
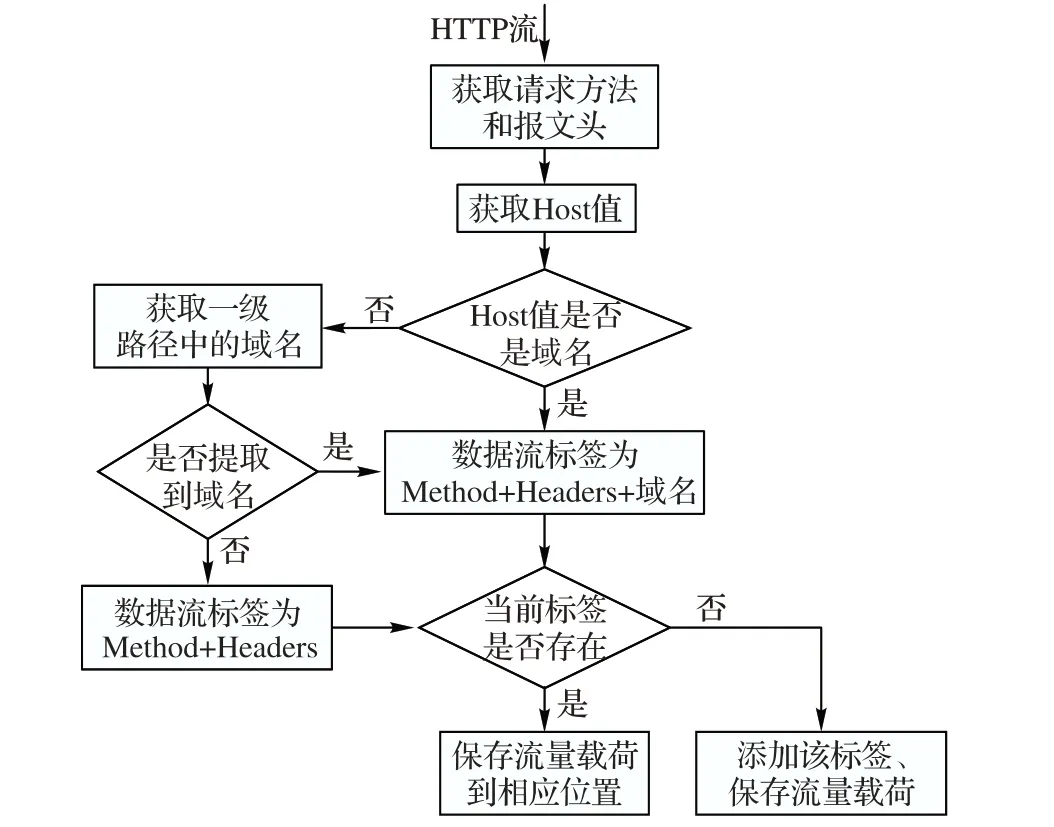
图3 流聚类流程Fig.3 Traffic clustering process
经过聚类,每一类的数据流已经高度相似。图4 为两台不同设备上的爱奇艺产生的HTTP 请求报文,根据本文的聚类原则,这两条数据流属于一类。从图4 可以观察到这两条请求报文的结构完全一致,只有部分字段的值不同,可以在后续处理中提取出其中的报文结构和固定字符串作为特征。
2.2.2 特征生成
应用产生的HTTP 流经过聚类后,得到了多个高度相似的集合。在提取特征时,要将每一类流中的固定不变信息保留下来。本文提出的特征生成算法是:在应用流聚类的基础上,使用LCS 算法分别提取应用的每一类HTTP 流的LCS。由于每一类HTTP 流具有相同的结构,为了减少不必要的计算,将HTTP 报文分成不同的行,即请求行、报文头行、报文体行,再分别提取每一行的子LCS后并组合成最终的结果。

图4 爱奇艺HTTP流Fig.4 HTTP traffic of iQiYi
LCS 算法实现简单,但存在结果碎片化的问题。为此,本文引入阈值Length_min 来解决碎片化问题。具体思路为:在生成两个字符串的LCS状态矩阵时,当前位置字符相同,且其前后共Length_min 个字符也相同时才计入结果。由于HTTP报文有明显的结构,不同意义的字段由一定的间隔符分隔,最短的关键字可以是1 个字符,如“pt=0&t=6&tl=7&”中的关键字“t”加上前后两个分隔符“&”“=”,所以Length_min取值最小应为3。Length_min值越大,最后的结果越精简。详细描述如算法1所示。

根据本文的特征生成算法,提取图4 中两条爱奇艺HTTP流的LCS,其结果如图5 所示。可以看出,结果保留了图4 两条HTTP 请求报文中符合本文要求的公共字符串序列,且保留了报文的结构,由于非连续处插入了特殊间隔符,可以在后续处理中剔除可变化的字段。

图5 图4的LCS结果示例Fig.5 Result example of LCS for Fig.4
2.2.3 字符替换
将应用的每一特征中存在的可变字段和无关项进行替换,最后添加转义符将特征转化为正则表达式形式,可直接用正则匹配来识别应用流量。
1)替换可变字段。如前所述,在提取了每一组数据流的LCS 后,会在每一个不连续处插入特殊间隔符,而HTTP 报文具有明显的结构,可依据常用间隔符如空格、换行,以及“/”“,”“=”“&”“;”等划分成不同的字段,如果某一字段中存在特殊间隔符,则将当前字段替换为“(.*)”。
2)替换无关项。应用程序的流中通常具有某些与应用程序无关的字段,如“WIFI”“4G”“G4”“LTE”“NONE”“NULL”等,将这些字段替换为“(.*)”。
3)转义字符替换。最后保留“(.*)”不变,将各个转义字符前添加转义符“”,需要转义的字符包括“.”“*”“?”“(”“)”等。
图6为图5所示的LCS经过字符替换后的结果,其中存在变化的字段和无关项已替换为正则表达式中代表任意字符的“(.*)”。当网络流量来源比较广泛时,就可以排除出所有的可变换字段,剩下的固定不变字段即为该类网络流的特征。
2.3 特征筛选
由于移动应用的开放性,不同应用可以从相同的服务器获取数据,所以可能存在不同应用产生完全相同的HTTP 请求报文,即提取的特征无法有效识别数据流的源头。这类完全相同的流,主要涉及一些系统功能相关的数据,包括获取服务器时间、网络测试、上传日志等。如图7 所示,飞猪、闲鱼、手机淘宝、手机天猫和优酷视频都能提取到这样一条特征。对于这种不能明确地区分数据流归属的特征,依据其在应用数据流中出现的频率来判定,如果在某一应用中出现的频率明显高于其他应用,则将此特征归为出现频率较高的应用;如果在各个应用中出现的频率没有明显的差异,则将此特征删除。
本文设置临界频率倍数阈值P,P代表了对提取的应用特征误报率的容忍度。P=0 表明完全接受应用特征产生的误识别;P 值越大,则本文方法提取的特征在实际流量识别中的误报率越低。本文将P设置为5,现实意义为如果特征A代表的流在应用1中所占比率高于其他应用5倍,则特征A归属于应用1,其他应用中的特征A 删除。5 是一个经验值,在实验中已经可以达到较好的效果。

图6 爱奇艺特征示例Fig.6 Signature example of iQiYi
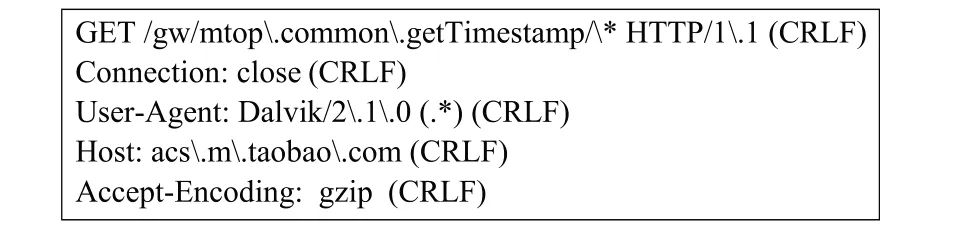
图7 多种应用的共同特征Fig.7 Common signature of multiple applications
3 实验及结果分析
3.1 实验数据采集
为了评估本文的特征提取方法,在多台设备上安装采集工具NetLog,并收集2019 年5 月20 日—6 月30 日产生的流量。其中6 月15 日前的流量作为样本集,用于提取应用的特征;6月16日—30日的数据作为测试集,用于测试实验提取的特征的识别效果。为了排除设备型号对应用特征的影响,挑选出其中至少出现在两台不同设备上的42 种应用所产生的HTTP流作为实验数据。样本集共含有117 772条HTTP流,其详细分布见表1;测试集共含有50 387 条HTTP 流,其详细分布见表2。

表1 样本集应用及HTTP流分布Tab. 1 Applications and HTTP traffic distribution in sample dataset
3.2 评价标准



表2 测试集应用及HTTP流分布Tab. 2 Applications and HTTP traffic distribution in test dataset
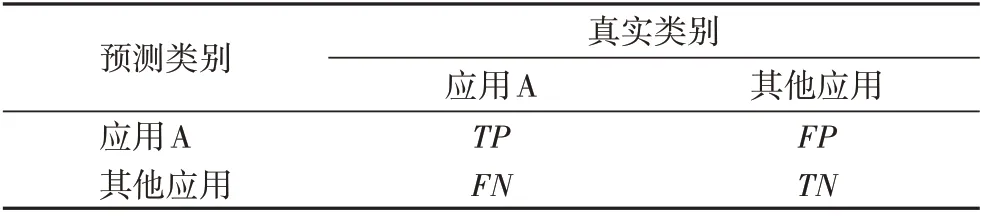
表3 混淆矩阵Tab. 3 Confusion matrix
3.3 实验结果
为验证本文提出的应用特征提取方法的有效性,使用该方法提取样本集中42 种应用的HTTP 流特征,并使用这些特征去识别测试集中的应用流量,得出每个应用特征的TP、FP、FN、TN 值,并计算每个应用的特征在测试集上的查全率、准确率和误报率。由于提取的特征是正则表达式形式的字符串,识别时直接使用正则匹配的方法将每一个特征同应用的HTTP 请求报文进行匹配即可。评估结果见表4。由表4 可见,本文提出的应用特征提取方法具有良好的识别效果,其中平均准确率ACC 达99%以上,单个应用最大误报率为QQ 空间的0.52%,查全率最低为71%、最高为99%,平均查全率为90.63%。
由表4 也可得出,本文方法可以有效区分具有关联性的同一体系的应用。如腾讯公司的QQ 空间、QQ 浏览器、手机QQ、企鹅电竞、腾讯视频、微视、微信,阿里巴巴旗下的淘宝、天猫、淘票票、口碑、飞猪、饿了么、聚划算、闲鱼,字节跳动公司的今日头条、抖音短视频、火山小视频、西瓜视频等。同一公司开发的应用具有明显的关联性,功能相互集成,本文方法可以以极低的误报率取得较高的查全率。

表4 应用特征在测试集上的评估Tab. 4 Evaluation of application signatures on test dataset
3.4 对比实验
本节进行两组对比实验:第一组,通过改变特征筛选阶段的阈值P,观察它对识别结果的影响;第二组,选取其他已发表文献的应用特征提取技术与本文方法进行对比。
3.4.1 对比实验1
本文在特征筛选阶段设置了阈值P=5,即将多个应用出现的相同特征归属于流占比高于其他应用5 倍的应用,该阈值可以较低的误报率获得较高的查全率。在对比实验1 中,将阈值P设置为无穷大,其现实意义为:如果多个应用具有一个相同的特征,则排除此特征,从而使得在样本集上获取的特征可以唯一指向某一个应用。对比实验同样使用样本集提取特征,用测试集来验证识别效果,对比结果见表5。从表5 可见,能够容忍一定程度误报率的P 取值为5,与完全不容忍误报率的P 取值为无穷大相比,平均查全率由88.21%提高到90.63%,但平均误报率仅由0.01%提高为0.05%。表6 列出了三种结果差异较大的应用,查全率有较大幅度的提升,但误报率最高仅为0.52%。由此可见,在容忍一定误报率的前提下,可以大幅提高部分应用流量的查全率。

表5 对比实验1结果 单位:%Tab. 5 Result of comparative experiment 1 unit:%

表6 对比实验1详细结果 单位:%Tab. 6 Details of comparative experiment 1 unit:%
3.4.2 对比实验2
本节选取其他三种特征提取技术来评估本文方法:1)基于HTTP 头 字 段 中 的 显 式 应 用 标 识 符[12];2)基 于NetworkProfiler 方法[11]的URL 状态机及Host 组合;3)应用逆向的方法[14]。前两种方法与本文方法都是从应用流量入手,根据原文的思路进行复现,从样本集中提取特征,并测试所提取的特征在测试集中的识别效果;第三种应用逆向的方法,由于不具备复现的能力,本文根据文献[14]的实现机制和实验数据进行对比分析。
由表7 可见,本文方法与应用标识符的方法相比,平均查全率提高了47%,平均误报率仅为0.05%。与NetworkProfiler的方法相比,平均查全率提高了22%,平均误报率不足NetworkProfiler 方法的1/25。由此可见,本文方法与其他从应用流量入手的方法相比,具有较高的查全率和较低的误报率。
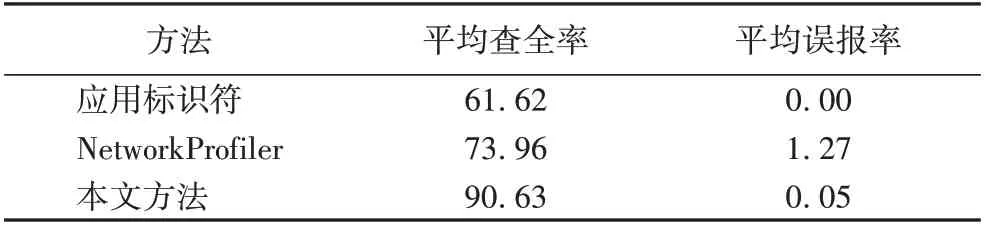
表7 对比实验2结果 单位:%Tab. 7 Result of comparative experiment 2 unit:%
最后,对应用逆向的方法进行对比分析。文献[14]对应用安装包进行反编译,从配置文件中获取特定的字符串(例如服务器域名、User-Agent 等)填充到统一构建的特征框架中,从而形成应用流量特征。此方法无须采集应用流量,直接利用应用安装包构建应用流量特征,其优势是便于开展大规模的应用特征提取,缺点是统一的特征框架难以充分利用配置文件中的关键信息,造成特征不够精细,难以有效区分同体系的应用流量。文献[14]的实验结果表明,安卓应用的整体流覆盖率为40.76%,引入“Application Families”概念(将具有一定关联性的应用作为一个整体)后整体流覆盖率提升为81%。由此可见,本文提出的方法对于识别具有关联性的应用流量具有明显的优势。
4 结语
本文提出了一种提取移动应用HTTP 流结构化特征的方法,避免了预先设计特征带来的识别精度底、适用性差的问题,能够有效识别存在数据关联性的应用的流量。本文方法不需要对数据做特殊处理,适合开展大规模、高吞吐量的实时在线检测。
本文方法存在两点不足:1)采集流量需要人工运行应用程序完成;2)流聚类还不够精细,造成聚类后的类别较多。下一步的主要工作包括:1)优化聚类算法,在不影响特征精度的前提下,尽可能减少特征的数量;2)与应用自动化运行工具相结合,构建一个全自动的移动应用HTTP特征提取系统。
猜你喜欢
汽车电器(2022年9期)2022-11-07
电子技术与软件工程(2022年11期)2022-09-09
舰船科学技术(2022年10期)2022-06-17
计算机应用与软件(2022年2期)2022-02-19
电脑爱好者(2021年23期)2021-12-08
科学家(2021年24期)2021-04-25
中国外汇(2019年11期)2019-08-27
办公室业务(2019年13期)2019-08-01
现代电子技术(2016年24期)2017-01-19
新世纪图书馆(2014年7期)2014-09-19
