
基于响应模糊化的抗附加块攻击云数据安全去重方法
2020-06-01 10:54周琳娜
计算机应用 2020年4期
唐 鑫,周琳娜
(国际关系学院信息科技学院,北京100091)
(∗通信作者电子邮箱xtang@uir.edu.cn)
0 引言
随着大数据时代的到来,云存储平台面临海量用户数据的存储挑战,为了提高大数据的存储和管理效率,越来越多的云服务商,诸如Dropbox、Mozy、Mega、Bitcasa 等[1-2],采用云数据去重技术来避免存储冗余数据,只保存用户数据的一个副本。尤其是跨用户去重技术,将去重范围延伸到云存储平台的所有用户,一个用户上传数据之前,首先上传对应标签信息,由云服务商在本地查找所有用户存储的数据,一旦发现相同副本,则阻断数据上传,并通过数据所有权验证机制验证用户的所有权。如果验证通过,则云服务商允许此后用户对该数据的下载和使用。由于这种方式进一步提高了云存储平台的存储效率,因此被广泛采用。
然而,跨用户去重技术在节约存储开销的同时却使得云端数据的隐私面临被边信道攻击窃取的安全风险[3]。考虑一种模板化的用户文件存放在云端,该文件只含部分敏感数据,其余部分均为公开数据。例如某公司员工的电子工资单,包含员工姓名、工号、部门等公开信息以及工资收入这个敏感信息。如果存在内部员工在未经许可的情况下想要获知别人的工资信息,他只需按照模板格式生成目标员工的公开信息,同时按猜测附加上工资信息,随后上传生成的电子工资单并观察去重系统的响应。一旦云服务商在本地发现相同的工资单副本,则会阻断该员工的上传,此时该员工就可确认猜测的工资信息即为对应员工的真实工资。为了应对这种攻击,实现安全的跨用户去重,当前许多工作分别对明文云数据[2,4-6]和密文云数据[7-11]作了大量研究。为了抵抗明文云数据跨用户去重过程中的边信道攻击,现有解决方法大多在去重响应中附加随机信息,使得检测者无法根据云服务商返回的响应来判断检测文件的真实存在性。例如,如果将云端的去重响应设定为检测文件在云端未命中的数据块信息,则为了混淆检测者,可在响应中附加部分命中块信息,使得无论对命中文件还是未命中文件,去重响应中包含的数据块个数均相等。简单假定检测文件的敏感信息均包含在一个数据块之中,其余块中均为公开信息。那么,在文件检测时,如果检测文件存在,当次检测出的未命中块数应为0;如果不存在,则未命中块数应为1。为了混淆检测者,前一种情况下可在响应中要求用户上传1 个随机选定的命中块;而在后一种情况下,则自然地要求用户上传未命中的敏感块。因此,在两种情况下,检测者接收到的响应中均包含1 个数据块信息,无法通过响应判断所检测文件的存在性。对密文云数据而言,当前工作通常在密文生成过程中添加随机信息来实现对边信道攻击的抵抗。然而,攻击者往往可以通过女巫攻击[12]等方式伪造身份,获取该随机信息,因此这类方法仍然面临安全风险。为了实现密文云数据的安全去重,可行的方法应类似明文去重,在响应中引入不确定性。尽管这类方法能够奏效,但它们均要求云服务商首先能够正确地判断出所检测文件的存在性,这在附加块攻击[5]的场景下是难以实现的。在附加块攻击中,检测者首先对检测文件附加上随机数量的非命中块,然后将各块标签信息一起上传到云端检测文件的存在性。显然,无论文件的存在性如何,云服务商检测出的未命中块数均大于0,因此难以判断文件的真实存在性,从而也无法在未命中文件的响应中附加随机块信息,实现混淆检测者的目的。
因此,本文拟解决附加块攻击下的云数据去重安全性问题,在附加块攻击场景下,提出一种轻量级的抗边信道隐私泄露安全去重方法。本文方法首次将附加块数量作为考虑因素,对于待检测文件,提取附加块数量,与该文件未命中块数比较,根据比较结果确定响应中要求用户上传的块数,从而不需要基于检测文件的存在性生成响应。本文方法不仅实现了附加块攻击场景下文件存在性隐私的绝对安全性,而且所需开销远远低于现有的抗附加块攻击去重方法。
本文的工作主要有以下几点:
1)针对附加块攻击场景下去重过程中云数据存在性隐私泄露的问题,提出一种安全的轻量级去重检测框架。该框架使云服务商不仅能够在未知所检测文件真实存在性的情况下生成响应,混淆检测者,而且能使响应中附加的冗余信息量实现最小化,将开销控制在最低水平。
2)在本文设计的框架下,提出了一种基于响应模糊化的轻量级去重方法。该方法基于检测到的附加块数量、未命中块数量,计算要求用户上传的数据块并生成响应,使得无论对命中文件还是未命中文件,响应中包含的数据块数量保持一致。从而,检测者无法通过分析响应信息判断所检测文件的真实存在性,实现了附加块攻击场景下的安全去重。
3)通过安全分析说明了本文方法的安全性,并开展实验验证了性能。实验结果表明,本文方法在实现附加块攻击场景下去重过程中云文件存在性隐私绝对安全性的前提下,所需开销显著小于当前最新方法;且与经典成果相比,在开销相当或少量增加的情况下,安全性显著提高。
1 相关工作
跨用户云数据去重技术被广泛用来消除云端冗余数据,提高存储效率。然而,攻击者却能够通过去重结果,创建边信道以窃取云端数据的存在性隐私。为了抵抗边信道攻击,Harnik 等[4]提出了一种基于随机阈值的方法——RTS(Randomized Threshold Solution),首先为每个文件在云端分别设置一个存储阈值,该值对云用户保密且只有当云端存放的文件数高于该阈值时才对该文件执行去重。这样,即使检测者接收到的去重结果表明云端要求上传所检测文件,也不能说明该文件在云端不存在,从而实现了对云端数据不存在隐私的保护。然而,一旦云服务商在检测标签信息后阻断了用户对检测文件的上传,就说明云端存储的该文件数量达到了阈值,文件的存在性隐私就会暴露。作为改进工作,Zuo 等[5]提出了一种基于响应模糊化的抗边信道攻击去重方法——RRCS(Randomized Redundant Chunk Scheme),该方法首先要求云端正确地判断出所检测文件的真实存在性,再为命中文件和未命中文件分别在原响应中附加随机数量的命中块信息,以确保响应中包含的数据块数量在相同的范围内,从而使得攻击者难以通过响应判断所检测文件的真实存在性。为了实现这一目的,两种情况下附加的随机块数在不同的范围内选定。具体来看,该方法假设待检测文件的所有敏感信息均包含在一个数据块之中,其余块为公开块。对于一个检测文件而言,云端检测出的未命中块数量只能是0 或1,分别对应检测命中和未命中两种情况。显然对于未命中文件而言,云端响应必须包含检测出的未命中块,则响应中附加的命中块数量在[0,λN]中随机选取,λ是用来平衡安全性和效率的比例因子,N 是检测文件的块数。而对命中文件,响应中附加的随机块数在[1,λN+1]中随机选取。所以两种情况下,去重响应包含的数据块数量均在[1,λN+1]范围中,攻击者无法通过响应判断文件存在性。然而,一旦攻击者为检测文件附加上随机数量的非命中块,无论对命中文件还是非命中文件,云端检测出的未命中块数量都将大于1,此时云服务商无法确认在响应中附加的数据块数量是在[0,λN]中还是在[1,λN+1]中选取。按照无附加块攻击场景下的定义,Zuo 等[5]规定,两种情况下均在[1,λN+1]中随机选取附加的数据块数量,因此命中文件和非命中文件的响应中包含的数据块数量将不可避免地存在于不同的区间范围之中,该方法在附加块攻击场景下存在泄漏文件存在性隐私的风险。此后,Yu 等[2]从数据块检测的角度研究了一种双数据块同时检测方法,采用异或技术模糊化云端的去重响应,实现对边信道攻击的抵抗。然而,他们的方法仍然没有在附加块攻击场景下实现文件存在性隐私的安全性。Pooranian 等[6]改进了这一方法,但是本质上仍然存在这一缺陷。
针对密文云数据,现有的工作大多基于CE(Convergent Encryption)加密技术[13]生成密文,该技术将明文的哈希值作为密钥,因此同一文件的多个所有者可以生成相同密文。而云服务商只存储密文,却无法获知明文哈希值,因而难以解密出明文。基于该技术,Bellare 等[9]采用第三方可信服务器生成随机数,并基于交互式盲签名技术将之引入密钥生成过程以抵抗边信道攻击。然而,该技术无法避免攻击者通过伪造身份获取该随机信息,即:攻击者可以伪造成正常用户执行协议,从而产生包含随机信息的密文再上传去重。在Bellare 工作[9]的基础上,Kwon 等[8]引入双线性对技术进一步提高了安全性。Dang 等[11]提出了一种基于硬件的随机数和密钥生成方法。然而,这些后续工作均继承了Bellare 工作[9]的局限性,在此范畴下,密文云数据去重过程中面临的边信道攻击等同于明文,如采用如上所述的明文云数据抵抗边信道攻击的方法,同样无法在附加块攻击场景下取得足够的安全性。
2 抗附加块攻击的云数据安全去重方法
2.1 方法框架
本文所提抗附加块攻击的云数据安全去重方法的设计包含安全性和效率两方面的考虑。其中,安全性是指本文方法需在附加块攻击场景下有效防止攻击者通过建立边信道窃取云端数据的存在性隐私,即:考虑攻击者对待检测文件附加了随机数量的非命中块后上传至云端,云服务商按照本文方法生成响应,在响应中包含一定数量的冗余块信息以实现模糊化,从而达到混淆攻击者的目的。既谈安全性,就要考虑实现安全性的代价。由于本文方法是通过在响应中附加冗余块信息的方法来混淆攻击者,而响应中包含的数据块均为要求用户上传的块,所以本文考虑的开销主要为流量开销。本文方法在效率上的目标是将流量开销控制在最低水平。在此设计目标下,本文方法的框图如图1所示。
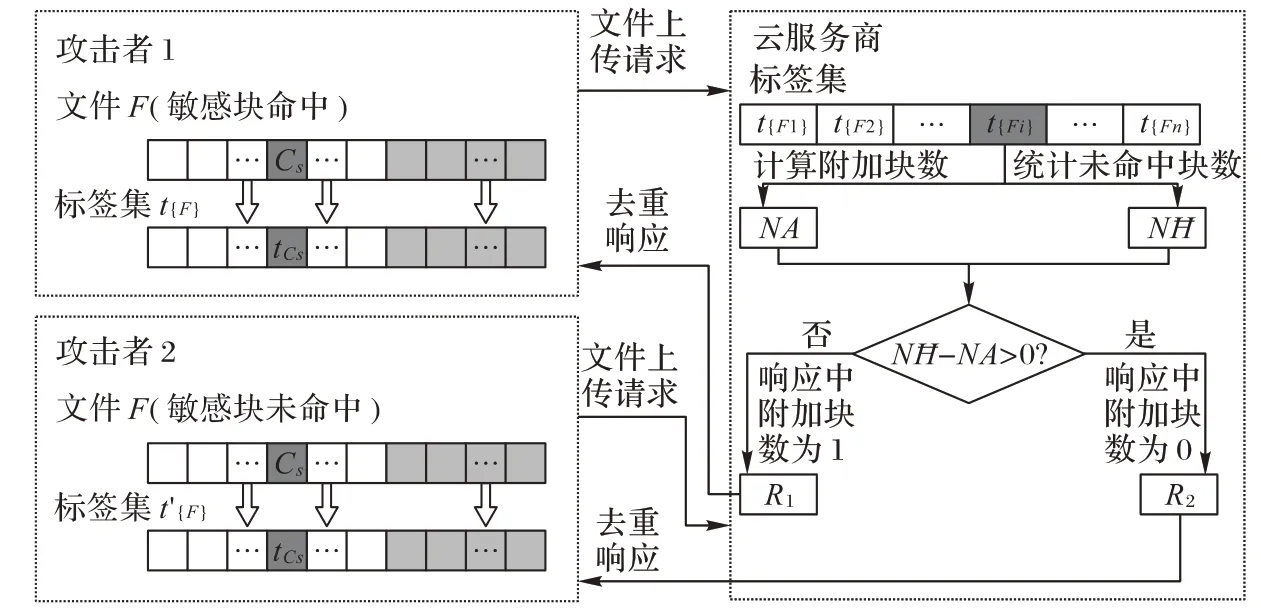
图1 抗附加块攻击的云数据安全去重方法框图Fig. 1 Framework of appending chunk attack resistant secure deduplication method for cloud data
如图1 所示,本文方法以文件为检测单元,每次检测分块后的一个完整数据文件。出于简单性考虑,假定云用户和云服务商已经协商好分块大小,云端将一个文件的所有块标签存放在一起。在图1 中,考虑两个攻击者检测同一文件,所检测文件的公开块及附加块均相等,只有敏感块不同。接收到二者的文件上传请求后,云服务商在本地数据块标签集中查找请求中包含的文件块标签,查找到匹配所有公开块的标签集后,统计标签集中总命中块数,并根据标签集中元素个数,计算附加块的数量,比较二者,根据结果生成响应。值得注意的是,所有的附加块均不命中,而如果未命中块的数量等于附加块的数量,说明检测文件中敏感块命中,此时在响应中随机附加一个命中块信息;否则,一旦未命中块的数量大于附加块的数量,说明检测文件中的敏感块未命中,此时响应不需模糊化。如此一来,攻击者1和攻击者2接收到的响应中包含的块数相同,而响应模糊化的开销只有1 个冗余块,即实现了开销最小化。上述相关技术已申请专利[14]。
2.2 方法详细构造
考虑云数据检测者已经对待检测文件分块生成标识信息,并作为文件上传请求上传到云端,等待云端的去重响应以确定需要上传哪些数据块。其中,标识可为数据块的哈希值。假定去重查询请求对应的文件为F,请求包含F的N个数据块C1,C2,…,CN及N′个附加块A1,A2,…,AN′。其中,在N 个数据块中有1 个块包含敏感信息,可能为命中块,也可能为非命中块,其余N - 1 个数据块均包含公开信息,为命中块;所有的附加块均为随机生成的非命中块。
云服务商接收到去重查询请求以后,按照以下步骤来查找未命中块的数量、检测附加块数量并生成响应。
1)首先在云存储中查询这N + N′个数据块的标识信息,显然,以文件为单位查询,如果请求中的敏感块命中,则云服务商可查询到对应的N 个命中块;否则,只能查询到N - 1 个命中块,记命中块数量为H。非命中块数量NĦ 可按式(1)计算:

根据以上分析可知,在没有附加块攻击的情况下,N′=0,NĦ=N-H 的取值为1或者0;当N′≠0时,由于附加块均为非命中块,NĦ的取值至少为N′。
2)云服务商观察查询到的H 个命中块对应的文件块标签集,记其包含的数据块数量为L,则附加块数量NA 可按式(2)计算:

式(2)表明,附加块数量等于检测文件的长度减去云端存储的该文件长度。在正常情况下,云用户上传的文件块标识对应的完整文件没有附加非命中块,即N′=0。如果该文件在云端存在,则请求中的文件长度N 等于云端存储的文件长度L;而在附加块攻击的情况下,N′≠0,通过式(2)可计算出N′的真实值。
3)比较统计出的非命中块数量NĦ 和计算出的附加块数量NA,按照表1 确定响应中包含的数据块数量。
根据上文分析不难发现,非命中块数量NĦ 的取值为N′或N′+1,附加块数量NA的实际值为N′,所以表1 中NĦ - NA 的值为0 或者1。当NĦ - NA = 0 时,说明在检测文件中,只有附加的块未命中,其余的N 个块均命中,即检测文件对应的原文件在云端存在。此时,云服务商生成的响应需包含NĦ个非命中块,额外要求的1个块用来实现响应模糊化,从而达到混淆攻击者的目的。当NĦ-NA=1 时,说明在检测文件中,除了N′个附加块,原文件的1 个敏感块也未命中,即检测文件对应的原文件在云端不存在。此时,云服务商生成的响应只需包含所有NĦ 个非命中块。值得注意的是,这里的非命中块数量NĦ等于上一种情况文件命中时对应的非命中块数量加1。所以两种情况下的响应中包含的数据块数量相同,攻击者无法通过响应来判断所检测文件的存在性。

表1 去重响应生成方法Tab. 1 Generation method of deduplication response
抗附加块攻击的云数据安全去重方法的流程伪代码如下所示。

3 安全性分析及性能验证
本章将分析本文方法的安全性并通过实验验证其性能。其中安全性分析部分首先从理论上分析本文方法在附加块攻击场景下实现去重的过程中,云数据存在性隐私泄露的风险,从而表明本文方法能够实现该场景下的边信道攻击抵抗。接下来,将本文方法与该领域当前最新工作进行比较,评估各自在无附加块攻击场景下和附加块攻击场景下存在性隐私泄露的风险,从而证明本文方法在安全性上的优势。实验验证是通过开展实验,评价本文方法的性能,并与该领域目前最新的工作进行比较,表明本文方法的性能优势。为了开展实验,本文采用亚马逊EC2(Elastic Computing Cloud)来部署云数据跨用户去重系统,并在系统上构建所提的去重响应机制。同时,选取一组配置为Intel Core i5-4590 CPU @ 3.3 GHz,8 GB RAM 和7 200 转1 TB 容量硬盘的服务器作为云用户客户端,来实现云数据检测。
3.1 安全性分析
如图1 所示,在本文方法考虑的场景中,云端将同一个文件的数据块标签集中存储。如果文件已经存放在云端,则云端存放的该文件标签集合中包含的标签个数即为文件块个数。对于静态文件来说,文件长度属于固有属性,不会改变。因此,本文方法按照式(2)来检测附加块的数量,在该场景下是可行的。另由附加块攻击的特性可知,攻击者为了混淆云服务商,在检测文件上附加的文件块均为非命中块,因此,本文方法在检测步骤中,在云端检测得到的未命中块中已包含附加的文件块,其余部分为可能的未命中敏感块。由于本文假定一个文件只有一个敏感块,因此,未命中敏感块的个数只能是1 或0。综上所述可知,对于一个检测文件,未命中块的个数NĦ 与附加块个数NA 的差值只能是1 或0。当差值为1时,说明检测文件的敏感块未命中,而差值为0 时,说明敏感块命中。在这两种情况下,云服务商给出相同数量数据块的响应,因而攻击者无法根据响应判断所检测文件的真实存在性。
选取抗边信道攻击安全去重领域的最新成果RRCS[5]和经典成果RTS[4]作为比较对象,比较本文方法和RRCS、RTS在无附加块攻击和附加块攻击场景下的安全性,用文件存在性隐私泄露的概率来测量安全风险。在无附加块攻击场景下,本文方法对命中文件和非命中文件所需的上传数据块数量都为1,存在性隐私泄露的概率为0。RRCS 为非命中文件和命中文件在不同的区间内计算冗余块的个数,确保云端响应中要求用户上传的文件块数量均在相同区间[1,λN+1]中随机产生,符合均匀分布。其中λ∈(0,1),用来平衡方法的开销和安全性。因此,攻击者根据响应难以判断所检测文件的存在性,在此场景下文件存在性隐私泄露的概率同样为0。而RTS随机产生阈值T,当云端副本数量少于T 时,攻击者无法判断文件存在性,一旦云端副本数达到T,存在性隐私立即泄露。
在附加块攻击情况下,由于本文方法构建在不需云端检测出待检文件真实存在性的基础上,所以无论对命中文件还是非命中文件,所需上传的数据块数均为N′+1,攻击者无法通过响应来区分,所以文件存在性隐私泄露的概率仍然为0。RRCS 对命中文件和非命中文件所需上传的数据块数量分别在[N′,λ(N+N′)+ N′]和[N′+1,λ(N+N′)+ N′+1]随机选取,假设一个文件的敏感块有m 种不同的可能,则检测所有m 个版本的文件,如果有一个文件响应中包含的需上传块数量为N′,则存在性隐私泄露。同样的,如果m - 1 个文件的需上传块数量均为λ(N+N′)+ N′+1,存在性隐私同样泄露。而对RTS 而言,当云端敏感块及附加块副本数量少于T 时,敏感块存在性隐私泄露风险为0,一旦数量达到T,存在性隐私立即泄露。3种方法的安全性比较结果如表2所示。
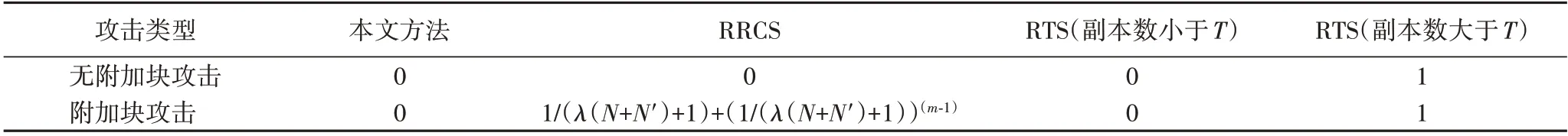
表2 本文方法和RRCS的存在性隐私泄露风险比较Tab. 2 Comparison of existence privacy disclosure risk between the proposed method and RRCS
3.2 性能验证
为了验证本文方法的性能,本节在公开数据集Fslhomes[15]、MacOS[15]和Onefull[16]上实现本文方法、RRCS 和RTS,并评价各自在无附加块攻击情况下和有附加块攻击情况下的性能开销。其中:前两种方法均采用响应模糊化的方法来混淆攻击者,所需开销均为用户额外上传冗余块的通信开销;RTS采用设置随机阈值的方法,所需开销为与阈值相关的文件冗余上传开销。因此本节将通信流量开销作为比较对象来衡量3种方法的性能,即比较3种方法在确保各自安全性的基础上,在云用户和云服务商之间产生的通信流量开销。Fslhomes 数据集是由纽约州立大学石溪分校的文件系统和存储实验室建立的,其中数据包含虚拟机图片、word 文档、程序源代码等;MacOS 数据集收集了1 台MacOS X 企业级服务器上的数据内容,该服务器可对247 名用户同时提供电子邮件、数据库等服务;Onefull数据集收集了国内一个实验室15台学生计算机上的数据信息。据统计,这3 个数据集平均文件大小分别为1 530 KB、683 KB 和622 KB,数据跨用户冗余率分别为39%、48%和25%[5]。
3.2.1 无附加块攻击场景
本节将该数据集存放在已部署跨用户去重系统的云平台上,在开销评估部分,首先考虑无附加块攻击场景下,对单个文件多次检测,在云用户和云存储系统之间所产生的实际通信流量大小。为了比较的统一,假定目标文件在云端存在。用户请求的待检测文件公开信息均相同且与目标文件一致,只有敏感信息可能不同,即非命中块数量为1或0。对命中文件和非命中文件,RRCS要求用户上传的数据块在相同范围内产生,而本文方法两种情况要求用户上传的块数相同,所以这里并不对文件的命中与否作区分。为了比较的一致性,将RTS 机制稍加修改,使其由文件级阈值去重变为数据块级阈值去重。在Fslhomes、MacOS 和Onefull 这3 个数据集上分别随机选取100个文件,计算3种方法在无附加块攻击场景下单文件检测的平均流量开销。
从如图2所示的实验结果可看出:对所选的3个数据集而言,RRCS 方法无论检测文件是否命中,要求用户上传的数据块均在[1,λN+1]中随机产生,符合均匀分布,而本文方法要求用户上传的块数始终为1,所以,在单文件100 次检测中,RRCS方法的流量开销波动变化,明显高于本文方法。而RTS方法在文件检测次数少于阈值T时,流量开销为1个敏感块的大小,与本文方法相同,这是因为此时无论对什么文件,云均要求用户上传1 个敏感块。而当文件检测次数大于等于阈值时,RTS方法的流量开销与所检测文件敏感块的存在性有关。对一个非命中文件而言,云端仍然要求用户上传1 个敏感块,而对命中文件而言,后续流量开销为0。故RTS 达到阈值后的流量开销可体现为期望值。由于3 个数据集数据冗余率分别为39%、48%和25%,故明显可看到RTS 达到阈值后的流量开销比本文方法略低,它在MacOS 数据集上达到最小,约为0.025 9 MB,在Onefull数据集上最大,约为0.037 4 MB。
接下来验证不同数量文件上传请求下,云用户和云存储系统之间所产生的实际通信流量大小。本实验中,考虑请求检测的文件数量控制在1~100,每一次请求的文件均随机选取,对RRCS 而言,响应均随机产生。用户上传响应中指定的数据块。在Fslhomes、MacOS 和Onefull 这3 个数据集上分别随机选取100个文件,计算3种方法在无附加块攻击场景下不同数量文件检测的流量开销,实验结果如图3所示。
由图3 可知,由于本文方法所需上传的数据块数对命中文件和非命中文件均为1,所以产生的流量开销随着请求检测的文件数量增加而线性增加。作为比较,RTS 的流量开销近似线性增加,且略低于本文方法的开销。与图2 的结果一致,由于MacOS数据集的冗余度最大,RTS方法对该数据集流量开销最低;反之,对Onefull 数据集流量开销最大。由于RRCS 方法所需的块数对两种情况均在[1,λN+1]中随机取值,所以其流量开销在所测数据集中始终大于等于本文方法和RTS。随着请求检测的文件数量增大,多个文件对应的上传块累加起来,差别更加明显。
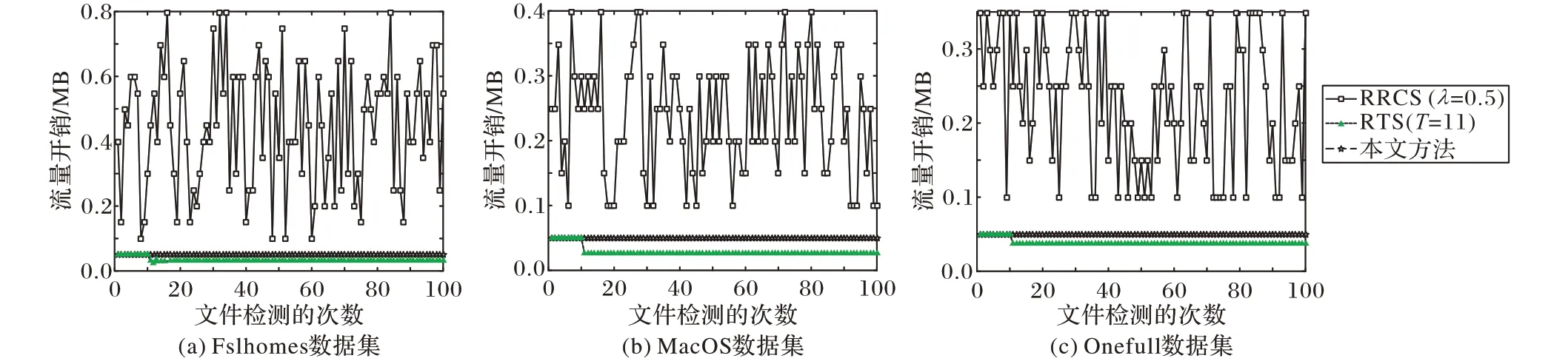
图2 无附加块攻击场景下单个文件检测的流量开销Fig.2 Traffic overhead of single file detection without appending chunk attack
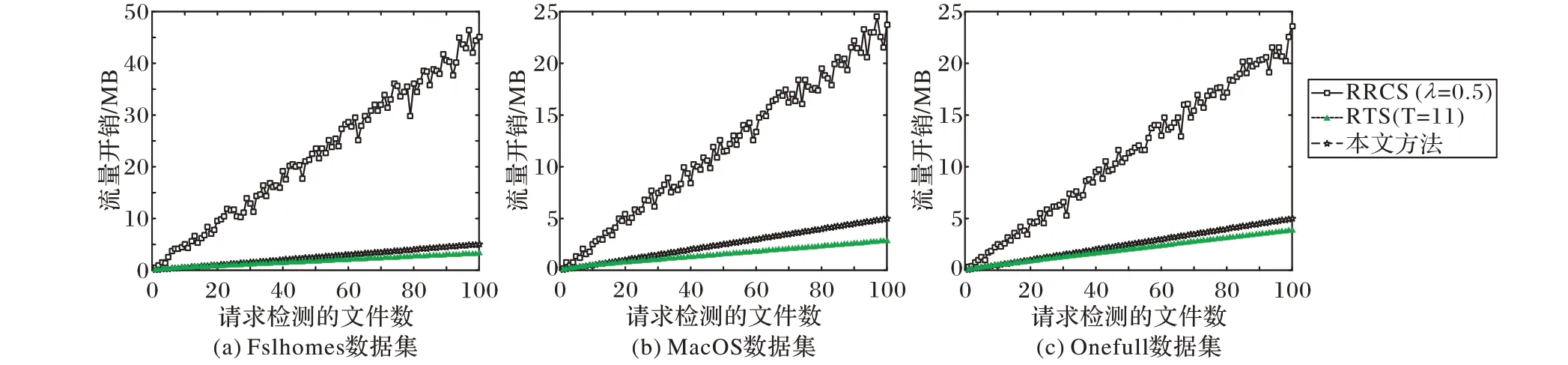
图3 无附加块攻击场景下不同数量文件检测的流量开销Fig.3 Traffic overhead of detection of different number of files without appending chunk attack
3.2.2 附加块攻击场景
接下来,考虑检测文件均被附加了N′个非命中块的情况,在此情景下,对于命中文件,RRCS需要上传的文件块数在[N′,λ(N+N′)+N′]中随机选取,符合均匀分布。对于非命中文件,RRCS 需要上传的文件块数在[N′+1,λ(N+N′)+N′+1]中随机选取,符合均匀分布;而在本文方法中,两种情况下需要上传的文件块数均为N′+1。选取附加块个数N′为5,首先比较单个文件检测下的流量开销,实验结果如图4 所示。由图4可知,单个文件检测场景下RRCS方法对命中文件和未命中文件实际产生的流量开销范围不同。对未命中文件,下限约为0.35 MB,显著高于本文方法和RTS 方法。而对于命中文件,RRCS方法的流量开销下限和本文方法相当且达到下限的次数很少。在3个数据集里分别检测100次目标文件,命中情况下,RRCS 分别只有5、13、10 次达到下限,其余情况均高于本文方法的流量开销。与前文无附加块攻击场景一致的是,RTS 方法在附加块攻击场景下流量开销也略低于本文方法。
接下来验证附加块攻击场景下,不同数量文件检测的流量开销。实验场景设定类似无附加块攻击的情况。图4 已表明无论检测文件是否命中,RRCS的单个检测流量开销均大于本文方法或与本文方法相当,所以这里仅随机选定命中文件和非命中文件,实验结果如图5 所示。由图5 可知,由于本文方法在附加块攻击情况下,对命中文件和非命中文件,所需上传的数据块数均为N′+1,所以产生的流量开销随着请求检测的文件数量增加而线性增加;随着请求文件数量的增多,流量开销与RTS的差距逐渐缩小。而对于RRCS,其所需块数在两种情况下分别为[N′,λ(N+N′)+N′]和[N′+1,λ(N+N′)+N′+1],均大于等于本文方法;随着请求检测的文件数量增加,多个文件对应的上传块累加起来,差别更加明显。
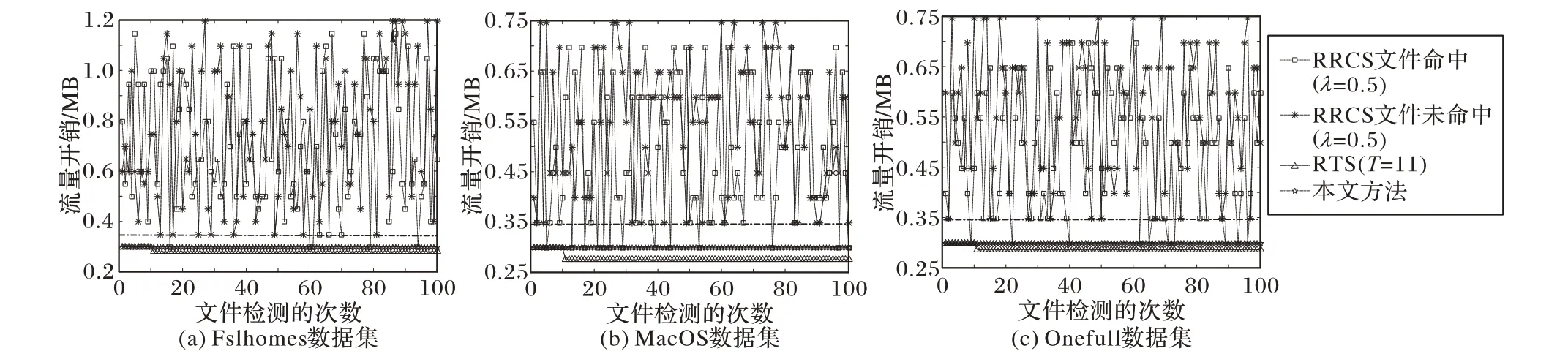
图4 附加块攻击场景下单个文件检测的流量开销Fig.4 Traffic overhead of single file detection under appending chunk attack
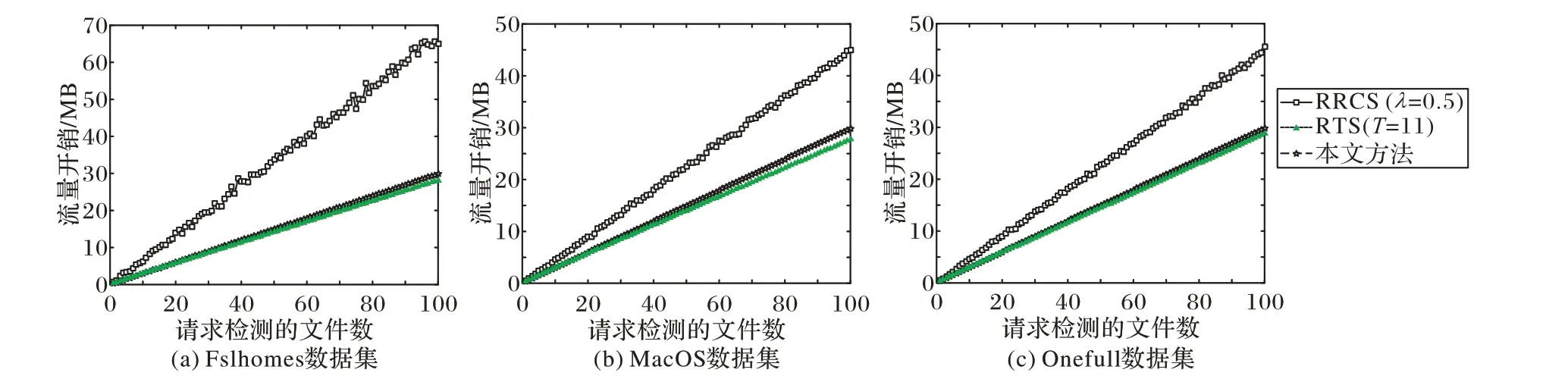
图5 附加块攻击场景下不同数量文件检测的流量开销Fig.5 Traffic overhead of detection of different number of files detection under appending chunk attack
4 结语
本文提出了一种基于响应模糊化的抗附加块攻击云数据安全去重方法的设计原理和详细构造,并开展了安全性分析和性能验证。同当前该领域的前沿成果RRCS 和经典成果RTS比较结果来看,本文方法在确保安全性的前提下,所需的流量开销显著小于RRCS 方法;而且与RTS 相比,在流量开销相当或少量增加的情况下,安全性显著提高;性能优势随着检测文件数量的增加而愈加明显。
猜你喜欢
现代电子技术(2022年11期)2022-06-14
华人时刊(2022年5期)2022-06-05
奥秘(2020年6期)2020-06-30
小学生学习指导(低年级)(2019年3期)2019-04-22
爱你·心灵读本(2018年6期)2018-09-10
爱你(2018年16期)2018-06-21
初中生世界·七年级(2017年2期)2017-01-20
小猕猴智力画刊(2016年6期)2016-05-14
人力资源(2015年7期)2015-08-06
小说月刊(2014年9期)2014-11-18
