
基于层级注意力机制与双向长短期记忆神经网络的智能合约自动分类模型
2020-06-01 10:55吴雨芯张大斌
计算机应用 2020年4期
吴雨芯,蔡 婷,张大斌
(1. 广东白云学院大数据与计算机学院,广州510450; 2. 中山大学数据科学与计算机学院,广州510006;3. 重庆邮电大学移通学院大数据与软件学院,重庆401520)
(∗通信作者电子邮箱ct_dolphin@163.com)
0 引言
随着区块链技术的不断发展与应用,部署在区块链平台上的智能合约数量已呈指数型增长[1]。自智能合约白皮书正式发布之后,标志着未来几年时间内智能合约将在数字身份、资产记录、金融贸易、抵押贷款、数据共享、物联网供应链等领域得到广泛应用。目前Ethereum 平台上已有超过200种智能合约应用,平均每月发布的智能合约数量接近10 万个[2]。对区块链用户而言,如何在海量的智能合约应用中快速准确地选择合适的应用服务,是目前亟待解决的重要问题。因此,设计有效的分类模型对智能合约实现自动分类是很有必要的。
智能合约自动分类可以为区块链用户提供应用服务的智能推荐,避免了人工筛选海量智能合约的巨大时间成本,还能够对智能合约源代码进行有效的组织和管理,有利于智能合约的分门别类与安全漏洞检测[3]。智能合约分类本质上是合约源代码文本分类,以下展示了一个Ethereum 平台上的智能合约源代码。

该合约代码使用Solidity 编程语言实现,在满足预设条件时,它会在相互不信任的区块链参与者之间强制执行。要将智能合约自动分类到对应的预定义类别中,主要面临以下几个问题:
1)智能合约源代码不同于普通文本,传统的文本特征表示会忽略源代码中的语法规律和上下文行为信息;
2)由于智能合约源代码中的关键词可能出现在文本中的任意位置,如何捕获对分类结果有重要意义的单词顺序、句法和语义规律是一个不小的挑战;
3)区块链平台中的每个智能合约都对应一个账户,合约账户信息包含了相关的合约地址、余额、代码、相关交易、数据存储等信息,在建立分类模型时只对合约源代码进行特征提取将丢失关于智能合约的部分重要信息,影响模型的分类效果。
鉴于以上问题,本文提出一种基于层级注意力机制与双向长短期记忆(Bidirectional Long Short-Term Memory,Bi-LSTM)神经网络的智能合约自动分类模型HANN-SCA(Hierarchical Attention Neural Network with Source Code and Account)。在学习词特征表示时,从合约源代码和账户信息两个角度出发,利用双向长短期记忆网络最大限度地捕获上下文信息和非连续词之间的关联,更好地学习双向的语义依赖;在词层面和句层面同时引入注意力机制,区别不同单词和句子的注意力权重以构建智能合约文档级特征表示。
1 相关工作
智能合约自动分类可以建模为一个文本分类问题,目前对于智能合约自动分类问题的研究相对较少,其中,黄步添等[4]首次结合智能合约源代码与交易信息,基于词嵌入模型提取文本特征,利用长短期记忆(Long Short-Term Memory,LSTM)网络生成全局向量表示,将向量输入到前馈神经网络中,由Softmax 层输出分类结果。LSTM 可以很好地捕获较长距离的依赖关系,通过训练可以选择性地记忆或遗忘部分不重要信息;但它不能捕获从后到前的语义信息,这将对分类的准确度产生较大影响。根据句子输入形式的不同,分布式句子表示模型主要分为基于词序列和树结构两种类型:基于词序列的模型考虑连续词之间的关系,从单词序列构造句子表示[5];基于树结构的模型将每个单词标记为语法解析树中的一个节点,并以递归的方式从叶子到根学习句子表示[6]。因为深度学习中神经网络模型在自然语言处理任务中的优异表现,基于神经网络模型学习分布式句子表示成为文本分类任务中的一种主流实现方法。
卷积神经网络(Convolutional Neural Network,CNN)由于具备捕获空间和时间的局部相关性以及通过汇聚提取更高层次关联的能力,使得CNN 可以从连续的上下文窗口中对句子进行建模。Kim[7]在预先训练的词向量基础上,利用卷积神经网络进行句子级分类。该模型基于超参调节和静态向量作为双通道输入,在卷积层使用多个具有不同窗口大小的过滤器进行特征提取,池化层将不同长度的句子表示成定长的向量表示。Dos 等[8]提出一种深度卷积神经网络CharSCNN,联合使用字符级、词级和句子级表示对短文本进行情感分析。Zhang 等[9-10]将文本作为一种字符级的原始信号,直接使用简单的卷积和池化操作处理不同长度的文本分类;但他们提出的卷积神经网络模型深度较大,需要大量的训练数据集。Johnson 等[11]比较了较浅的单词级卷积神经网络与较深的字符级卷积神经网络在文本分类中的性能。Wang 等[12]使用大型分类知识库将文本表示为一组向量,并将字符级特性合并到卷积网络模型中,以捕获细粒度的子单词信息。
循环神经网络(Recurrent Neural Network,RNN)在学习有序数据中的语义关系时具有天然优势,但RNN 遇到长句或文档分类时,句子中位置靠后的单词对句子中靠前单词的感知能力逐渐下降。虽然LSTM 网络[13-14]改进了这一问题,但它对于较长单词序列的记忆能力仍然比较有限。Zhou 等[15]结合RNN 和CNN 的优点,利用CNN 提取较高层次的短语特征表示,并将其输入到LSTM 中得到句子向量表示。Tang 等[16]利用门控递归神经网络自适应地将句子语义及其关系编码到文档表示中。针对LSTM 无法从后向前学习语义信息的问题,Zhou 等[17]提出一种双向长短期记忆网络(Bi-LSTM),利用二维卷积和二维池化操作进行特征采样和文本表示。
针对句子编码成固定长度向量后会成为模型整体性能提升的瓶颈问题,Bahdanau 等[18]首次在利用双向循环神经网络(Bidirectional Recurrent Neural Network,Bi-RNN)获取语义特征过程中加入了注意力机制,提高了对长句子的翻译效率和准确度。紧接着,Zhao 等[19]提出一种基于注意力机制的卷积神经网络ATT-CNN,在没有任何外部特征的情况下,利用注意机制自动捕获长句子上下文信息和非连续词之间的关联,从而提高句子分类性能。Yang 等[20]提出一种基于层级注意力机制的文档分类网络,使用词层面和句层面两级的注意力机制,在构造文件表示时区别不同单词和句子的注意力权重。针对RNN 及其衍生网络模型中前后隐藏状态存在依赖性,无法实现并行计算的问题,Vaswani等[21]提出一种完全依赖于注意力机制的网络模型Transformer,结合自注意力和点积注意力机制计算不同位置权重。在多语言文档分类任务中,Pappas 等[22]利用多任务学习和对齐的语义空间作为输入,使用跨语言的共享编码器和共享注意力机制,提出了一种单一多语言模型。Du 等[23]结合注意力机制,利用Bi-LSTM 捕获句子中的关键单词。
不同于上述工作,本文针对智能合约自动分类问题,利用Bi-LSTM 神经网络从源代码和账户信息两个角度对智能合约建模,在层级注意力机制的作用下结合代码特征与账户特征,作为神经网络的输入实现分类任务。基于不同区块链平台上智能合约数据集的实验验证了所提模型的有效性。
2 智能合约自动分类模型
本文模型HANN-SCA 的整体框架如图1 所示。模型网络结构主要由词嵌入层、Bi-LSTM 层、句表示层、文档表示层、连接层和Softmax 层组成。为了最大限度地提取智能合约的特征信息,提高神经网络分类性能,本文同时从智能合约源代码和账户信息两个角度建模:源代码角度关注智能合约中代码语义特征,账户信息角度关注智能合约账户特征;并且,在特征学习过程中分别在词层面和句层面引入注意力机制,重点捕获对智能合约有重要意义的单词或句子。最后,连接代码特征和账户特征生成智能合约文档级特征表示,通过Softmax层完成分类任务。
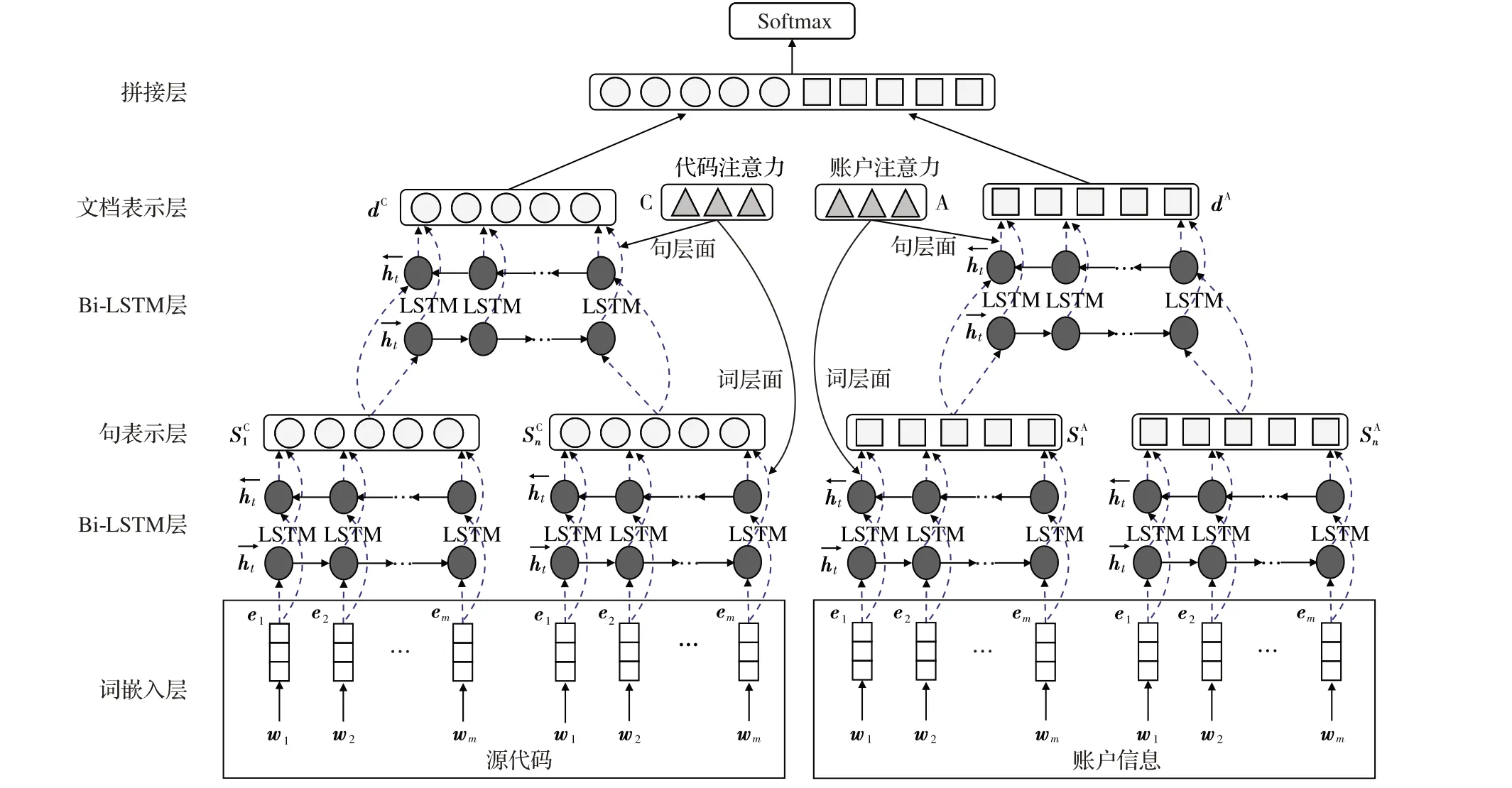
图1 HANN-SCA模型网络框架Fig. 1 Network structure of HANN-SCA model
2.1 词嵌入层

2.2 Bi-LSTM层
LSTM网络可以处理任意长度的单词序列,以递归的方式将一个转换函数f 应用到内部隐藏状态向量ht。隐藏状态ht在t 时刻与当前输入向量et以及前一隐藏状态ht-1之间的关系如式(2)所示:
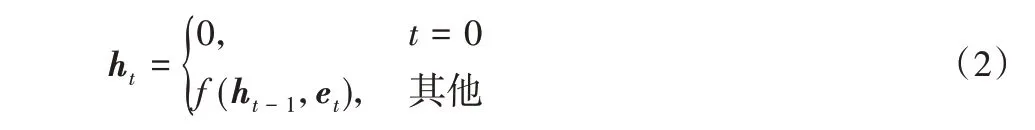
Bi-LSTM网络层中包含多个LSTM单元,如图2所示。
每个LSTM 单元中包含一个记忆单元ct和三个门控制器,分别是输入门it,输出门ot和遗忘门ft。对给定的输入向量et、上一单元的隐藏状态ht-1、上一单元的记忆状态ct-1,当前单元的隐藏状态输出ht可计算如下:
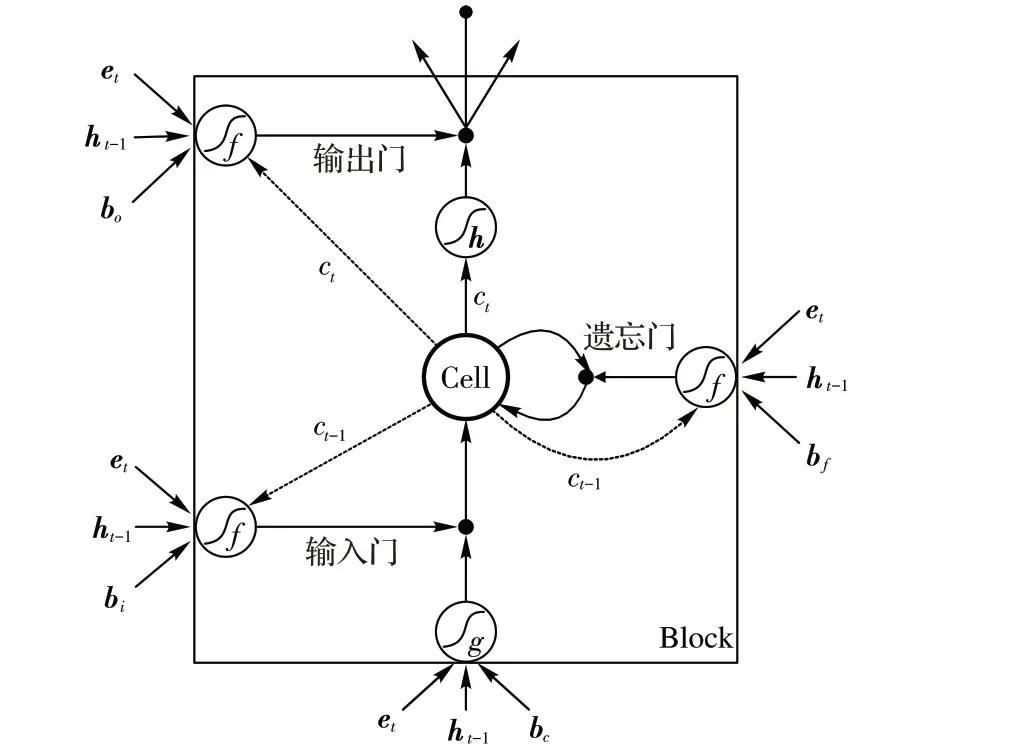
图2 LSTM单元结构Fig. 2 LSTM cell structure
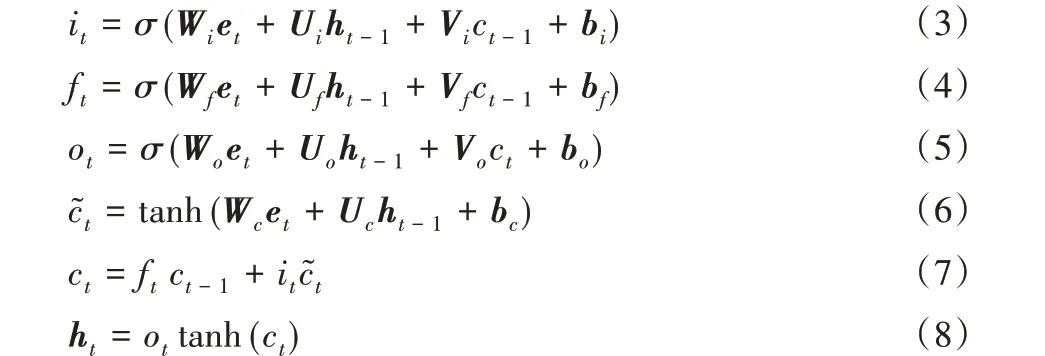
其中:需要学习的参数包括权重矩阵W、U、V 和偏置向量bt、

2.3 层级注意力机制
在智能合约源代码和账户信息中,句子里不同单词对合约分类的结果贡献度是不一样的。例如,在一个娱乐类智能合约中,取名为“Player”的函数或变量相比其他单词,对该合约所属类别的预测能起到更加重要的作用。因此,本文在智能合约特征学习过程中从源代码和账户信息两个角度出发,分别在词层面和句层面引入注意力机制,进而提取对智能合约分类有重要意义的特征单词和句子。
2.3.1 代码注意力

2.3.2 账户注意力


2.4 Softmax层
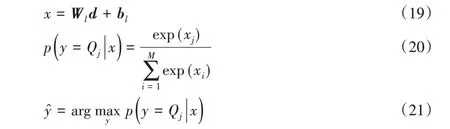
在得到智能合约全局特征表示后,将d 作为最终输入到Softmax 分类器的分类特征。首先将d 反馈到线性层中,从而将其投影到目标分类Q中。投影过程如式(19)~(21)所示:其中:Wl为权值矩阵;bl为偏置;M 为目标分类标签数;示d在分类标签Q 中的最大概率值。为了训练分类模型中的参数,本文选择交叉熵函数作为损失函数。损失函数如式(22)所示:
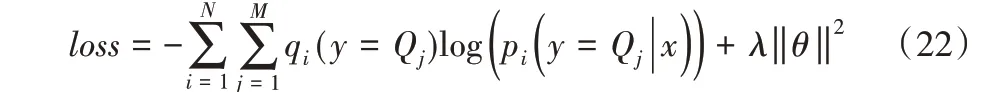
其中:pi(⋅)表示预测概率分布;qi()表示指标函数;N 为训练数据集中的句子数;M 为目标分类标签数;λ 为引入的L2正则化参数;θ表示Bi-LSTM 网络层和线性层的一组训练参数。本文选择ADADELTA[25]随机梯度下降更新规则来学习模型的参数。同时,为了避免过拟合问题,使用Dropout[26]随机丢弃LSTM 单元的部分输入,通过最小化损失函数来优化训练模型。
3 实验设置
3.1 数据集
本文分别从3 个不同的区块链平台收集了总共35 101 个经过验证的智能合约,并利用网站提供的API 获取相关智能合约账户信息。数据集统计信息如表1所示。
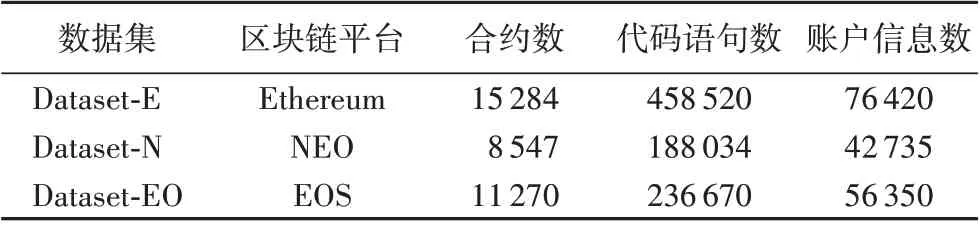
表1 数据集统计信息Tab. 1 Dataset statistical information
根据文献[4]对智能合约的分类,本文将智能合约应用分为娱乐(音乐、视频、游戏和社交),工具,信息管理,金融(保险、融资、投资和货币等),彩票,物联网,其他共7个类别。为了验证HANN-SCA 的有效性,本文首先使用Dataset-E 数据集对模型进行训练和测试,通过人工标记得到Dataset-E 数据集中智能合约各类别统计信息,如表2 所示。同时,为了体现HANN-SCA 模型在准确度和稳定性上的优势,本文将HANNSCA与已有的7种模型在上述3个数据集上进行对比实验。
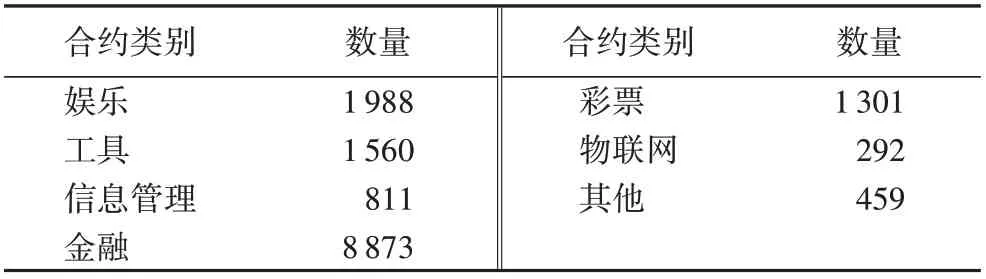
表2 Dataset-E数据集中的智能合约类别统计Tab. 2 Smart contract category statistics in Dataset-E
3.2 评价指标
与分类问题中常用的指标类似,本文使用正确率(Precision)、召回率(Recall)和F 值(F-score)三个度量指标来评价模型的性能。指标计算如下:

其中:out_tp 表示测试数据集中预测分类为阳性、实际也为阳性的智能合约个数;out_fp 表示预测为阳性、实际为阴性的个数;out_fn表示预测为阴性、实际为阳性的个数。
4 实验结果与分析
4.1 有效性分析
实验选取Dataset-E 数据集的80%作为模型训练集,20%作为测试集。表3显示了7种智能合约类别的分类结果。
从表3 可以看出,整体93.1%的分类准确率验证了HANN-SCA 模型的有效性。其中,物联网和其他类别的智能合约相比金融、彩票、工具类等分类效果较差。这是因为:一方面,在Dataset-E 数据集中物联网和其他类别的智能合约数量偏少,分类标签数量不均衡;并且其他类别包含的隐含种类较多,有可能导致模型无法很好地学习到分类边界。另一方面,金融类、彩票类、工具类的智能合约特征相对比较突出,更容易被模型所学习。
4.2 对比实验
接下来,将模型HANN-SCA 与以下7 种基准模型在表1所示3个数据集上进行对比实验。
1)W2V-SVM(Word to Vector-Support Vector Machine):使用Word2Vec方法对词向量进行训练,采用支持非线性分类的高斯核支持向量机作为分类器,结合One vs All策略进行多类分类。
2)CNN[7]:借助词向量将句子编码成二维矩阵,使用多个不同窗口大小的卷积过滤器提取特征,并将不同长度的句子表示成固定长度的向量表示。
3)C-LSTM(Convolutional-Long Short-Term Memory)[15]:一种CNN+LSTM 的方法。使用CNN 提取高层次特征表示,利用LSTM 学习长期依赖关系,生成句子向量表示。C-LSTM 模型既能捕获短语的局部特征,又能捕获句子的全局语义和时态语义。
4)W2V-LSTM(Word to Vector-Long Short-Term Memory)[4]:先将智能合约源代码通过Word2Vec方法映射为词向量表示,再将词向量顺序输入LSTM 网络得到全局代码向量。同时,结合智能合约关联交易信息,通过一个前馈神经网络以及Softmax输出分类标签概率。
5)ATT-CNN(Attention-Convolutional Neural Network)[19]:该模型将句子中的每个单词替换为它的向量表示,并创建句子矩阵。结合注意力机制,通过卷积和最大池化操作将句子向量映射到隐层特征空间表示,利用全连接层输出标签概率分布。
6)AT-LSTM(Attention-Long Short-Term Memory)[14]:通过LSTM 模型对句子进行建模,将LSTM 隐藏层与方面词向量相结合,在注意力机制的作用下以加权和的方式生成句子最终表示。
7)ATT-BiLSTM(Attention-Bidirectional Long Short-Term Memory)[23]:结 合 注 意 力 机 制,使 用 双 向LSTM 学 习 文 本特征。
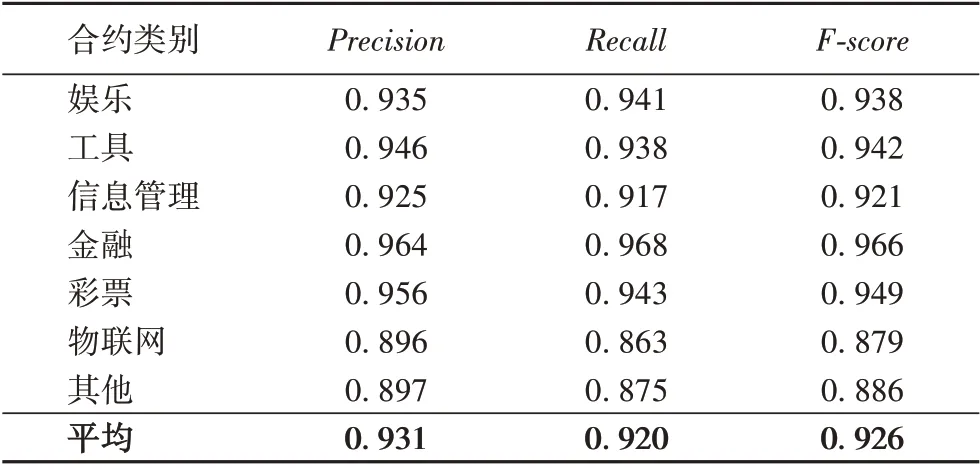
表3 Dataset-E数据集的分类结果Tab. 3 Classification results on Dataset-E
4.3 结果分析
基于Dataset-E、Dataset-N 和Dataset-EO 数据集,表4 给出了不同模型的实验结果。
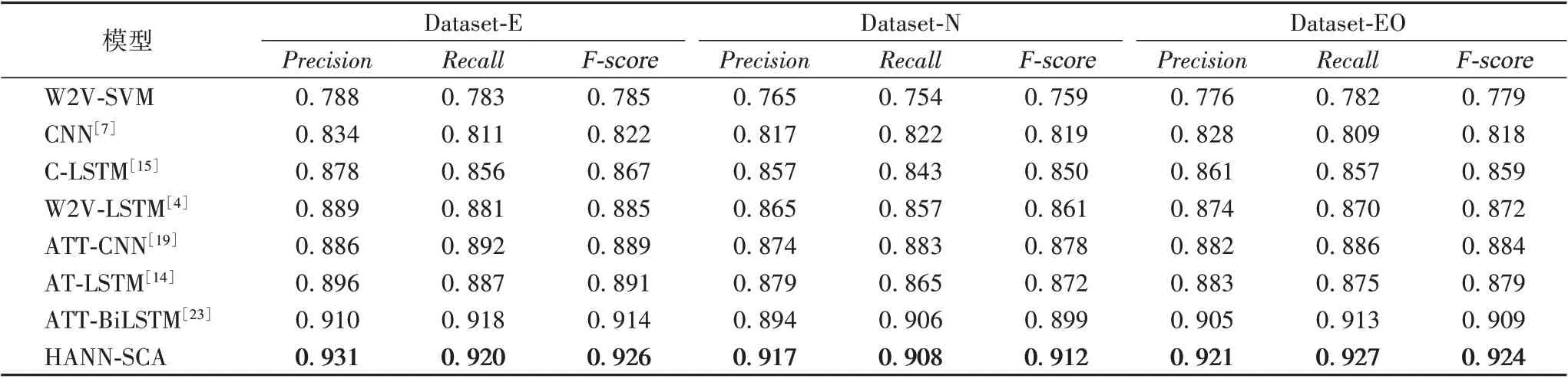
表4 HANN-SCA与不同模型实验结果对比Tab. 4 Experimental results comparison of HANN-SCA with different models
实验结果表明,HANN-SCA 模型在3 个数据集上均取得了不错的分类效果,其中在Dataset-E 数据集上的分类效果最佳,达到93.1%的正确率,比ATT-BiLSTM 模型和文献[2]提出的W2V-LSTM模型提高了2.1个百分点和4.2个百分点,显示出较好的性能。总体来看,各模型在Dataset-N 数据集上的分类效果不如其他两种数据集效果好,原因在于Dataset-N 数据集中训练数据偏少,NEO 区块链平台中智能合约的账户信息描述相对Ethereum 和EOS 平台来说不够详细,从而直接影响到各模型对智能合约所属类别的预测。从表4 还可以看出,利用CNN 进行智能合约分类的效果略差于LSTM,这进一步验证了LSTM 在具有上下文长期依赖关系的文本分类任务中的优势。
在没有加入注意力机制的情况下,CNN 和LSTM 模型在Dataset-E 数据集上分别达到83.4%和87.8%的正确率,而加入注意力机制的ATT-CNN 和AT-LSTM 模型正确率达到了88.6%和89.6%,分别提高了5.2 个百分点和1.8 个百分点。这是因为在神经网络模型中加入注意力机制后,模型在学习智能合约代码特征和账户信息时会重点关注合约的关键特征,从而有效提高模型的分类正确率。
本文模型在3 个数据集上的分类效果均优于ATTBiLSTM 模型,正确率分别提高了2.1 个百分点、2.3 个百分点和1.6 个百分点。这是由于HANN-SCA 模型从单词和句子层面分别建模,使用两层注意力机制对单词特征和句子特征进行向量转换。图3 展示了Dataset-E 数据集中一个娱乐类(游戏)智能合约注意力可视化,其中颜色越深代表注意力权重越大。
另外,本文对比了HANN-SCA 与各模型在不同数据集上的稳定性与运行时间效率。从图4 可知,HANN-SCA 模型在训练样本达到50%左右时基本达到了稳定;而其他几种模型几乎需要在训练样本达到70%以上才能趋于稳定,说明了HANN-SCA模型在稳定性上的优势。这是因为本文所提模型在对智能合约进行分类时,使用了两层注意力机制获取智能合约源代码特征和账户信息特征,考虑了更全面的上下文语义关系依赖。
图5 给出了HANN-SCA 与各模型训练时间和测试时间对比,训练与测试过程均在Intel Core i7-8550U CPU 上完成,将数据集的80%作为训练集,20%作为测试集。从图5(a)可以看出,W2V-SVM 训练时间相比其他模型较短,原因是基于Word2Vec方法的SVM可以直接对词向量进行训练,支持非线性分类的高斯核能快速地完成分类。随着CNN 中卷积层或LSTM 中隐藏层数量的增加,神经网络训练时间会相应增加,但注意力机制的引入会加快模型的收敛。
由图5(b)可知,引入了注意力机制的模型在训练完成后,测试时间会更短。原因在于注意力机制能更快速地提取文本中的关键特征,加速合约分类。从图5(b)还可以看出,HANN-SCA 相比AT-LSTM 和ATT-BiLSTM 模型在数据集上的测试时间更短,这是因为Softmax 分类器在训练和测试过程中降低了分类计算复杂度,从而有效地缩短了分类时间。

图3 源代码单词级注意力可视化Fig.3 Word-level attention visualization of source code
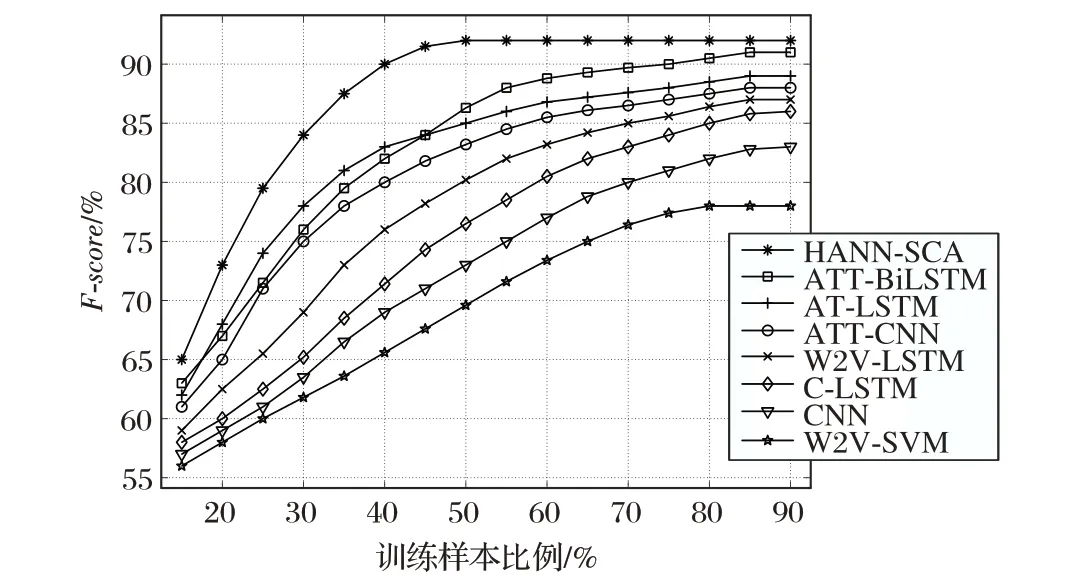
图4 HANN-SCA与不同模型稳定性对比Fig.4 Stability comparison of HANN-SCA with different models
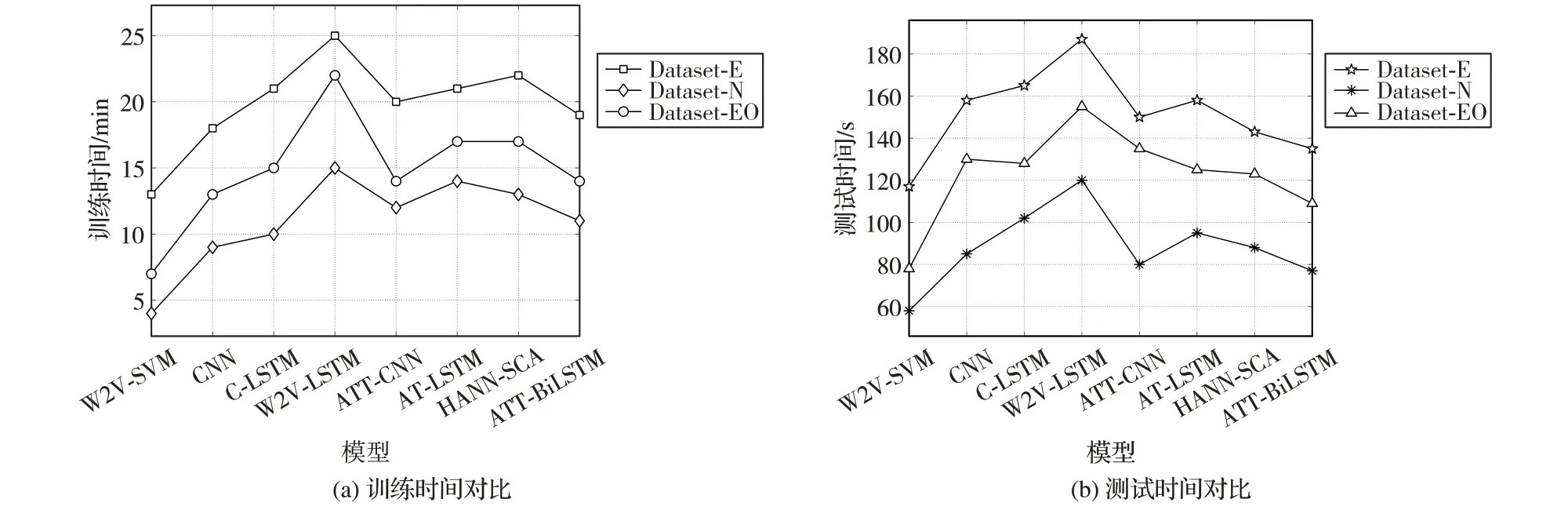
图5 不同模型运行时间对比Fig.5 Comparison of running time of different model
5 结语
针对智能合约自动分类任务,本文提出的HANN-SCA 模型结合层级注意力机制,利用Bi-LSTM 神经网络从源代码和账户信息两个角度分别学习智能合约的特征表示,更全面地捕获智能合约中双向的上下文语义依赖。最后,整合两个特征表示作为智能合约的最终表示,用于智能合约分类。基于Dataset-E、Dataset-N 和Dataset-EO 数据集的实验结果表明,本文所提模型分类性能超过了传统的SVM 模型和神经网络基准模型,且具有更好的稳定性。在未来的工作中,将进一步扩展智能合约数据集,使用层次化的分类标签结构,处理更复杂、更完整的分类标签信息。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
现代信息科技(2021年21期)2021-05-07
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
农家书屋(2016年11期)2016-12-23
世界汽车(2016年9期)2016-09-29
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
