
云计算在Web数据挖掘技术中的应用*
2020-05-29 08:25王琦超李广辉
九江学院学报(自然科学版) 2020年1期
王琦超 李广辉
(郑州工业应用技术学院 河南新郑 451100)
互联网技术使人们的生活更加方便和快捷。在大数据库中,Web数据挖掘技术有一定的提炼有用信息的功能,能够挖掘信息之间存在的关联性。目前在一台计算机上很难进行大量数据的处理和分析工作,云计算的出现是必然,它具有较强的信息存储能力,安全性较高,处理分析数据的水平较高,因此受到了各行各业的关注和重视。
1 云计算技术的发展情况与技术特征
1.1 云计算技术的发展概况
互联网企业的信息需求分析能力已经成为了其竞争和发展的重要内容,构建更加科学和更符合客户需求的网站非常重要。云计算技术可有效解决目前网络技术发展过程中存在的一些问题,云计算的概念模型图见图1。
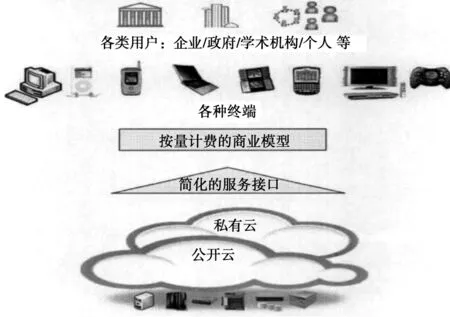
图1 云计算的概念模型图
由图1可知,将虚拟化的资源作为云的形式,利用服务接口,采用计费方式为网络用户提供服务,而用户不受时间和空间限制,随时随地都能享受服务。
1.2 云计算技术的特征
(1)广泛性。在云计算技术中存储技术非常重要,它可提高存储容量,保证存储的安全性,主要采用分布式的存储模式,具有较强的实用性和较高的性价比。
(2)具有较强的数据管理能力。云计算能够对大数据进行实时监控、实时处理和分析数据,也能根据用户需求筛选出更具有价值的信息,效率较高。
(3)先进的编程技术。技术的先进性能够衡量网站运行的先进性,也是推动云计算系统正常运行的重要因素,因此,编程技术非常重要。目前,使用比较广泛的编程技术是Map-Redduce技术,初期主要呈现树状结构,分支后还需要使用其他的编程技术对其进行维护。
(4)虚拟技术。在云计算使用过程中虚拟技术的应用相对较多,这主要是因为虚拟技术能够将网络资源进行有效配置,保证其能独立存在。在各项分支系统独立存在时,包含的数据信息也具有一定的独立性,这样使云计算系统弹性更大,并能将动态的虚拟资源灵活应用,进一步降低成本,不断提高网络资源管理的安全性。
2 Web数据挖掘技术概述
2.1 Web数据挖掘技术的含义
Web数据挖掘技术是将Web技术、信息技术以及网络技术进行有效结合,全面分析和处理挖掘的数据信息。Web数据挖掘技术可分为以内容为基础、以架构为基础以及以应用为基础的几类挖掘技术。以内容为基础就是在Web的环境中,使用人工模式提炼出相关文件夹中的有用信息;以架构为基础是使用人工将不同的数据结构挖掘出来,再采用有效的措施手段将有用的信息提炼出来;以应用为基础是在日志文件中存储好挖掘的主体,再将出站点的用户信息挖掘出来。因此,数据挖掘技术主要采用技术将Web文档当中含有的有用信息提取出来,并对未来的发展趋势进行分析和预测。
2.2 Web数据挖掘技术的分类
一般地,对Web数据挖掘技术进行分类主要按照内容、架构、使用记录三个因素进行分类。从内容角度看, Web的内容非常丰富,不仅包括整个页面内容的数据交易记录,还包括文本、图片等多媒体数据,一般将其细化为文本挖掘和多媒体挖掘。文本挖掘是指文本信息没有结构,也被称为非结构化信息;多媒体挖掘是以图片以及多媒体信息为基础的挖掘,处理多媒体信息需要使用更加复杂的理论,是目前研究的重点和热点。
从结构角度看,主要的对象类别就是数据架构,可对数据架构区分和组织,并能细分数据链,帮助Web数据挖掘技术,提升效率和准确性。Web的结构挖掘主要就是挖掘Web页面之间的链接结构,因为网络中各种文档之间存在联系性,可将这些信息利用起来,排序页面,发现更加有价值的页面。因为Web网页的结构更加丰富,它不仅包含了文本信息,还能表示其与网页关系链接存在的联系。有研究表明,Web的结构挖掘的主要目的就是将文档中存在的超链接结构利用起来对数据进行分析,Web超链接信息非常大量,其提供了与Web页面内容相关的信息,能将文档中存在的引用或者包含关系等反映出来,更具有准确性、客观性和概括性。
从记录角度看,具体分析和处理Web文档中的数据信息,可详分用户类型,进一步挖掘潜在客户,为企业创造出更多的经济价值。Web数据挖掘技术的具体分类如图2所示。
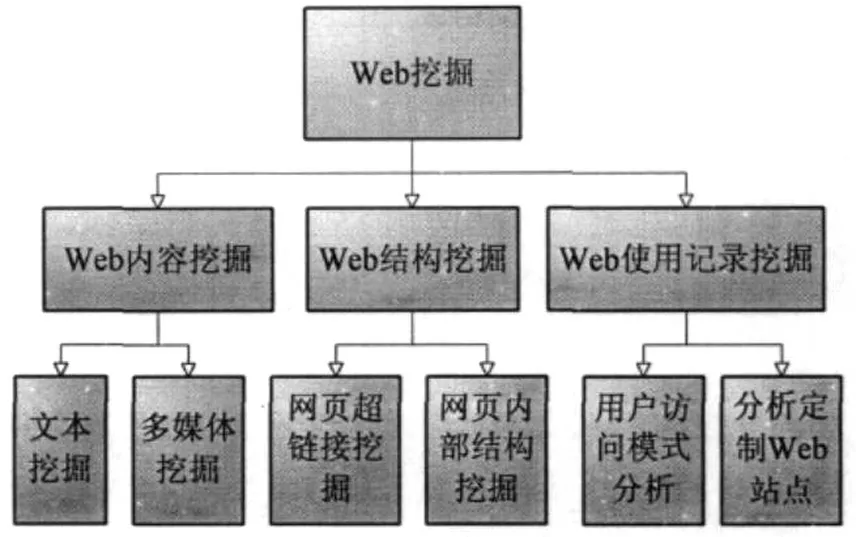
图2 Web数据挖掘技术的具体分类
2.3 应用Web数据挖掘技术的相关流程
一般使用Web数据挖掘技术,会受到较多影响因素的作用,Web数据挖掘技术与传统数据挖掘技术相比,变化了其对象和手段,其流程也随之发生了一定的变化。目前有效融合数据挖掘技术和Web技术是研究的难点和发展的难题。使用Web数据挖掘技术并不是简单应用一类挖掘技术,而是使用一个系统的流程,其中包括检索信息、选择信息以及对信息进行分析等过程。信息检索是查询和分析Web文档中数据信息或者网站上已有的日志或者新闻等内容;信息选择主要是筛选和辨别上一个环节中查询到的相关信息,将其中存在的一些无用信息去除,并初步分析有用信息;对信息进行分析主要是深入筛选和辨别有待处理的数据信息,将有价值的数据信息提炼出来。Web数据挖掘技术的整个流程,还需要使用自动化技术对其进行辅助,有效结合人工辨别,能进一步提高Web数据挖掘技术的准确性。
3 在Web数据挖掘技术中云计算的应用研究
3.1 构建基于云计算的Web数据挖掘系统
几个节点相互关联能够形成Web数据挖掘系统架构,而云计算在Web数据挖掘系统架构中的作用就是能让节点之间相互作用,使Web数据挖掘系统更加完善和可靠,其主要结构如图3所示。
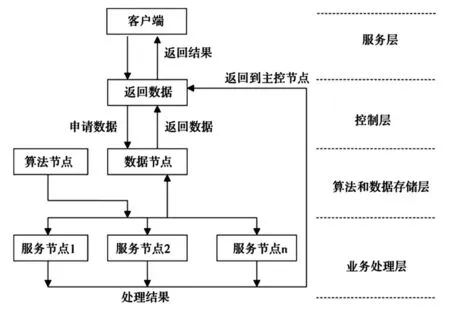
图3 Web数据挖掘系统主要结构图
由图3可知,Web数据挖掘系统的主要控制节点是由主控节点、算法节点、数据节点以及服务节点构成,其中主控节点是将用户和其他节点联系起来的纽带;算法节点主要是为数据分析提供一定的算法依据,拥有一个算法数据库;数据节点是存储数据的仓库;服务节点的作用主要是对任务的进程仅从控制,并将分析结果反馈出来。
将Web数据挖掘系统的功能作用有效结合起来,还可以知道系统结构可以划分为服务层、控制层、存储层以及业务处理层。①服务层将用户的需求结合起来,使用Web数据挖掘技术分析相关数据,并及时反馈给用户;②控制层是通过主控节点,深入分析用户具体的需求,使选择的算法程序更加科学、合理,让算法程序与信息数据之间的契合度得到保证;③存储层是将使用的算法程序、用户需求以及最终结果存储起来,可保证信息存储的安全性,进一步降低了可能会丢失原始数据或算法的现象出现,即使系统出现故障,也可以在数据和算法的存储层中找到并恢复;④业务处理层主要是通过主控节点将数据库中的原信息数据进行初步分配,并在分析、处理完后,将结果传回主控节点。
3.2 基于云计算的Web数据挖掘算法程序研究
随着互联网技术的不断更新和发展,大数据时代已经到来,要想将网页链接的关系保存并计算,需使用大型的并行系统才能实现,Pagerank算法比较常用,其实现并行化也是发展的必然趋势。
Mapreduce并行算法的主要计算过程就是存在于Hadoop集群中的Master节点将具有存储关系链接的文件进行划分,并将其分派给各个工作节点,让每个节点都能够进行Map任务。相关研究显示,在进行并行计算任务时,都需要访问HDFS,因此,并行算法每次更迭都会进行一次Mapreduce计算过程。
首先需要准备好算法数据,将链接结构的文件格式进行转换,使让更具针对性,并为每个节点赋值,一般初始的pagerank值为1-d,d的具体值为0.85,作为计算的输入数据。对数据进行预处理是由海量的信息网页节点组成,整个节点也需要并行化,则为Maperduce阶段。链接结构的文件格式如表1所示。

表1 链接结构的文件格式
输出节点链接序列保存得到HDFS当中,这是实现算法数据准备阶段的重要内容。使用Mapreduce框架将Map方法的输出进行归类并收集,并将生成的结果与生成链接合并,让其能够在作为下一次的迭代输入,进行并行Pagerank算法的原理如图4所示。
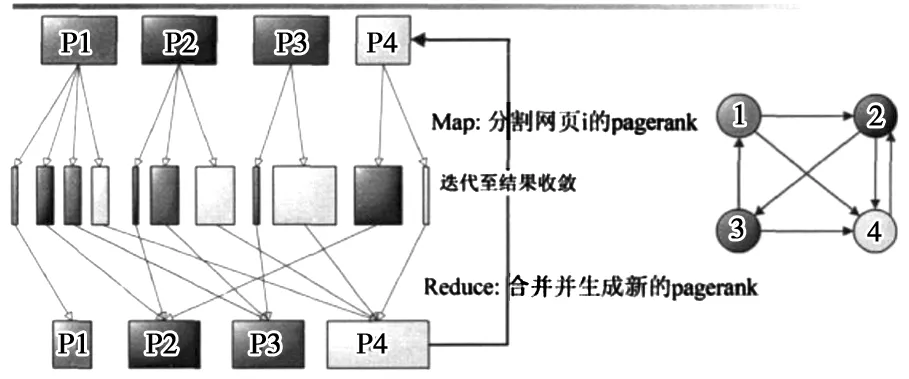
图4 Pagerank算法的原理图
如图4所示,首先要将用户的需求结合起来,明确其可信度,使用Web网页客户端向主控节点发出指令,传递原始数据给主控节点,并在主控节点中反馈服务节点分析的相关结果;主控节点再进行数据传递,从算法数据库中选择最优传递给算法节点,并对各个服务节点进行分配;各服务节点会具有针对性地筛选数据,整理和分类数据信息,获取到数据库的频集;在主控节点中反馈分析结果,了解数据库的整个频集,分别传送至各个服务点,进一步提高节点的频集准确性,再将反馈给用户。
检验算法程序主要依靠实验数据,根据相关研究可知,算法的效率与信息量之间存在正相关关系,因其传递的时间不同,一般情况下算法程序传递的时间比数据传输的时间少。Web数据挖掘算法与一般算法相比,差距非常大,可将其他算法进行改变以获得更新更加科学的算法程序。以云计算为基础的Web数据挖掘算法比较整体,各节点之间具有较强的联系,在一定程度上避免出现遗漏有效规则的情况,具有较大的应用价值和应用前景。
4 结语
综上所述,Web数据挖掘技术主要是利用Web文档进一步加工处理提炼的信息,将人们的生活习惯和模式结合起来,满足人们的需求。目前互联网正呈现爆炸式的发展,对信息的存储能力和数据分析能力的要求也越来越高,不断创新技术、挖掘出更多有效的信息是目前研究的重点。云计算较强的信息存储能力、数据计算和分析能力,在互联网行业中得到了比较广泛的应用,在Web数据挖掘技术中应用云计算技术也是互联网发展的重大突破,能将互联网信息资源的利用效率进一步提升,应用前景广阔。
猜你喜欢
机械工业标准化与质量(2022年6期)2022-08-12
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
大众投资指南(2021年35期)2021-02-16
装备制造技术(2020年2期)2020-12-14
中国交通信息化(2020年1期)2020-07-27
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
电脑爱好者(2017年7期)2017-05-06
中国卫生(2015年12期)2015-11-10
