
基于强化学习的DASH自适应码率决策算法研究
2020-05-27 12:55冯苏柳姜秀华
中国传媒大学学报(自然科学版) 2020年2期
冯苏柳,姜秀华
(中国传媒大学信息与通信工程学院,北京100024)
1 引言
随着无线通信技术的飞速发展和智能手机、平板电脑、移动电视等视频观看设备的多样化,内容提供商和用户对可变网络环境下提供高QoE(用户体验质量)视频流服务的需求不断增加。在这样的背景下,能够根据网络环境动态调节请求码率以最大化QoE的自适应流媒体传输应运而生。目前基于HTTP的动态自适应流媒体传输(MPEG-DASH)标准具有覆盖广泛、兼容性良好、部署较简便等特性,成为自适应流媒体传输的研究重点。在DASH中,一个视频流被切割成固定时长的分片,每个分片存储有多种码率,客户端的播放器根据当前网络状况以及播放信息,采用码率自适应(ABR)决策算法,选择下个分片请求的最优码率。DASH标准中并没有指定ABR算法,所以存在很大的研究空间。ABR算法的总体目标是:1)避免由缓冲区下溢引起的播放中断,即重缓冲;2)最大化视频质量;3)最小化视频质量切换次数及幅度以保证视频播放平滑度。而实现最优的ABR算法存在着以下挑战:1)动态网络环境下实现精确的吞吐量预测难度较大;2)ABR算法必须平衡各种QoE指标,但这些指标存在着内在冲突,例如高码率和重缓冲;3)当前的码率决策会对后续的决策产生级联效应;4)ABR算法可用的决策码率是粗粒度的,仅限于给定视频的可用码率。所以对ABR算法的研究一直在不断提升中。
目前基于客户端的ABR算法主要有基于吞吐量、基于缓冲和基于混合/控制理论这三类,但这些算法都存在局限性,即它们都使用基于特定环境的低准确性的建模来实现固定的控制算法,这使它们很难捕获和反映真实网络环境中动态网络的变化情况,并且很难在不同的网络环境下和不同的QoE目标上实现最佳决策。强化学习(RL)作为新兴的机器学习方法,通过学习环境的动态特性,反复试验并通过反馈的回报不断调整执行策略,逐渐收敛到最优策略,目前已广泛应用于无人驾驶、智能控制机器人等领域。近几年开始有研究将强化学习应用于ABR算法并取得了比启发式算法更好的效果。所以,采用强化学习来研究自适应流媒体传输中的ABR算法,为用户提供更加智能化的视频流服务,对提升用户体验质量,具有重大的意义。
本文采用了强化学习和深度神经网络相结合的深度强化学习算法,对动态网络环境下的DASH客户端码率决策算法进行优化。
本文第二章介绍目前的基于客户端的码率自适应算法研究现状,第三章介绍本文所采用的的基于深度强化学习的码率决策算法,第四章为实验部分,新算法和现有算法进行比较并分析,最后一章为结论。
2 研究现状
目前基于客户端的ABR算法主要有基于吞吐量、基于缓冲和基于混合/控制理论这三类。
文献[1]提出了一种基于TCP的AIMD算法,使用平滑的吞吐量测量来探测空闲网络容量并检测拥塞,渐进向上切换码率,检测到网络拥塞时乘性减小码率。文献[2]提出了一种多个商业DASH播放器共享瓶颈链路,基于公平性、效率和稳定性三个评估指标的码率自适应算法,采用历史吞吐量的调和均值估计当前带宽,并且采用有状态和延迟的码率更新以及随机下载块调度。文献[3]提出了一种基于缓冲区的码率自适应算法,构建了基于重缓冲、分片质量和质量切换的QoE模型,并表示为非线性随机最优控制问题,设计了基于动态缓冲区的PID控制器,该控制器可以确定每个分片的比特率并稳定缓冲区级别。文献[4]提出了基于缓冲区的Lyapunov 算法(BOLA),将码率自适应表示为效用最大化问题,并使用Lyapunov优化技术来求解最优策略。BOLA现在是dash.js中实验算法的一部分。文献[5]提出了一种基于模型预测控制(MPC)的算法,该算法结合吞吐量和缓冲区占用反馈信号,使用过去5个块的吞吐量调和均值进行吞吐量预测,并采用CPLEX等现有技术来解决QoE优化问题。他们还提出了robust-MPC[6],其控制器等效于吞吐量取下限估计值输入的MPC。
近年来开始出现了基于马尔可夫决策过程(MDP)的码率自适应算法,将码率决策模型化为有限状态的MDP,在波动的网络环境下做出决策。文献[7]提出了基于Q-learning算法的控制算法,客户端通过学习网络环境的动态特性,根据每个状态下不同动作的Q值选择当前的最佳动作,并更新状态-动作值Q表。与现有的启发式算法相比,QoE增加了9.7%。文献[8]将状态空间减少为两个变量:缓冲区级别和可用带宽,并简化了回报函数。文献[9][10]也提出了一种基于Q-learning的控制模型,改进之处主要在于对回报函数的调整。但由于Q-learing算法要求状态空间必须是离散的以及维度灾难问题,因此出现了使用神经网络来逼近价值函数的深度Q-learning算法(DQN)。文献[11]采用double-DQN,其主网络输出不同动作的近似Q值,目标网络输出目标Q值。D-DASH[12]根据分片大小来估计SSIM代替码率来作为分片质量度量标准[13],还使用混合神经网络框架,包括前馈神经网络和循环神经网络。Pensieve[14]采用A3C算法,该算法结合了策略梯度和基于值函数的方法,用值函数来指导策略更新,取得了更高的QoE值。
本文同样采用了深度强化学习的方法,通过学习环境的动态特性做出决策,并根据回报来调整策略,强化学习算法本文采用了OpenAI推出的将值迭代和策略梯度算法相结合的近似策略优化算法(PPO)[15]。
3 基于并行PPO的ABR算法研究
3.1 PPO算法简介
强化学习采用近端策略优化算法(PPO),PPO是2017年OpenAI推出的一种新的基于Actor-Critic算法。本文选用该算法的原因是PPO结合了策略梯度算法和值函数的优势,但是之前的策略梯度算法存在着学习步长难以确定的问题,在训练过程中新旧策略的的变化差异如果过大,相当于用了一个较大的学习率,不利于学习。而PPO提出了新的目标函数,经过理论推导得出只要策略参数朝着增大目标函数的方向更新,就可以保证策略的期望回报是单调递增的,解决了策略梯度算法中步长难以确定的问题。
原始的AC算法的策略网络的损失函数如式(1)所示。
(1)
其中pθ(st,at)为状态s下采取动作a的概率,优势函数Aθ(st,at)的含义是在状态s下采取动作a所获得的价值相比于平均价值有多好,损失函数的含义是增大获得较大回报价值的动作发生的概率。
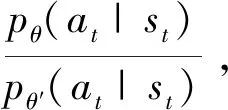
(2)
为了保证策略的回报期望是单调递增,PPO限制新旧策略不能相差过大。PPO有两种算法,第一种是PPO-penalty,目标函数如式(3)所示,增加了两个策略的KL散度惩罚项。
KL散度的系数β随KL散度而变化,若大于设定目标值,则增大惩罚系数使得参数朝着减小KL散度的方向更新,反之亦然。
(3)
第二种是PPO-clip,它不在损失函数中加KL散度惩罚项,而是直接对式(3)的第一部分进行裁剪,限制在预设范围(1-ε,1+ε)内,损失函数如式(4)所示。
(4)
为了增加模型探索性,在目标函数中加入了概率熵,熵权值随着训练次数增加而减小。
本文将实现PPO-penalty和PPO-clip这两种算法。
3.2 算法实现
3.2.1 强化学习元素
状态选用六种特征,包括过去k个视频块的吞吐量测量矢量;过去k个视频块的下载时间矢量,代表了吞吐量测量的时间间隔;下一个视频块的可下载大小的矢量,矢量长度为可选码率数量;当前缓冲水平;视频还存留的块数;上一个块下载的码率。
回报函数选用了ABR算法中常用的线性Qoe模型,包括三个部分:媒体分片质量、重缓冲事件、码率切换事件,如式(5)所示。码率切换部分需要先判断当前缓冲是否小于预设最低阈值,若小于预设阈值,则奖励减小决策码率的行为,惩罚增大码率的行为;若大于预设阈值,则惩罚减小决策码率的行为,奖励增大码率的行为。
(5)
3.2.2 网络框架
本文采用PPO结合神经网络的算法,包括actor策略网络和critic值网络,网络框架图如图1所示。
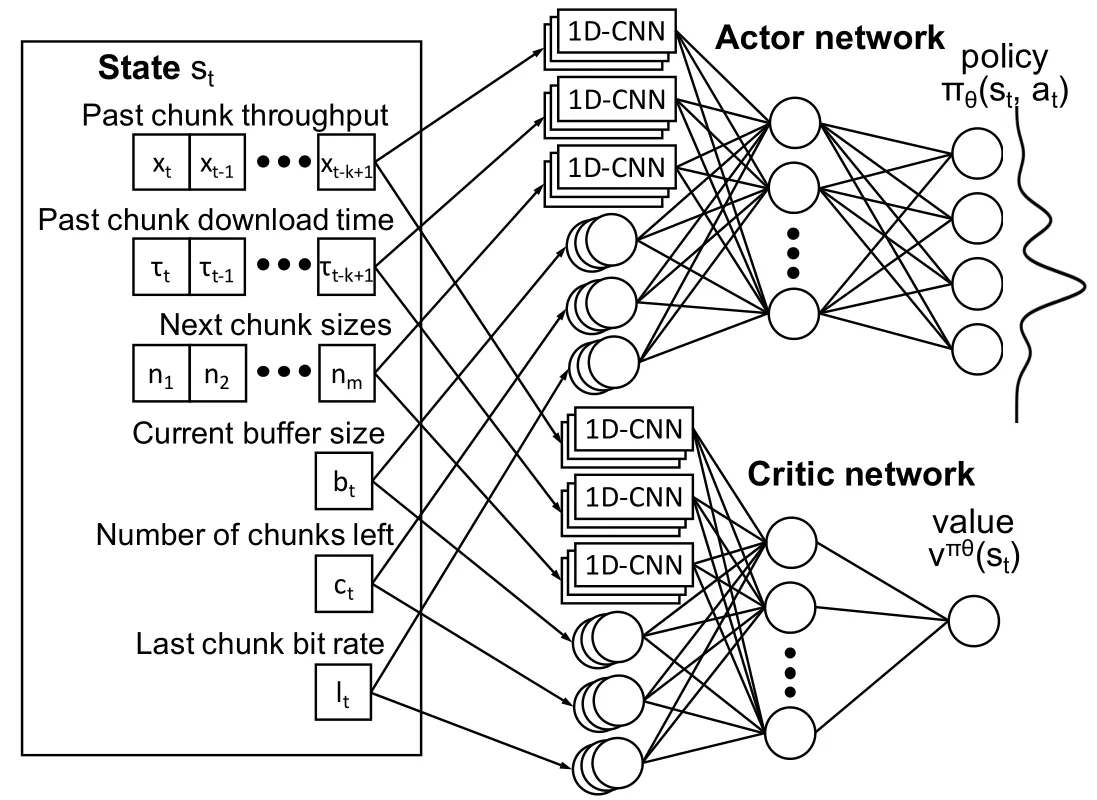
图1 PPO算法框架
Actor网络和Critic网络的输入层和隐藏层设置相同。输入层为6个状态特征,输入的状态中的三个序列,包括吞吐量、分片下载完成时间、当前分片大小列表,经过一个一维卷积层,卷积层的size为4,滤波器个数设置为128。输入状态的其他单值特征则输入一层全连接层,节点数设为128,然后第一层隐藏层的所有输出合在一起输入一层全连接层,最后接输出层。
Actor网络的输出层为softmax层,输出节点数为动作数量,对应输入状态s下不同动作a对应的概率分布p(a|s),Critic网络的输出层为全连接层,输出节点为1,对应为输入状态s的状态价值V(s)。
3.2.3 算法训练
本文采用并行训练的方法训练PPO算法,即采用多个不同训练环境采集样本,可以提升训练速度,并且样本分布更加均匀,更利于网络的训练。相比于值函数方法中用经验池来存储历史样本,再随机抽取样本训练,并行训练可以大大地节省存储空间。并行训练的框架如图2所示。
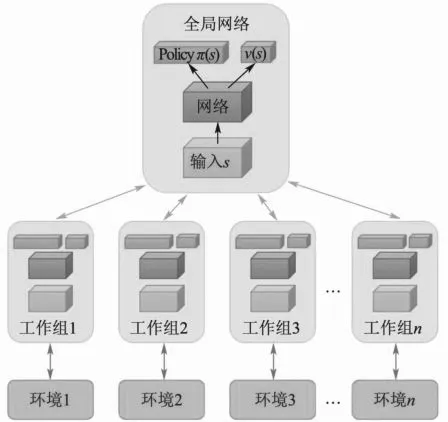
图2 并行训练框架
各个agent在各自的环境下进行不断决策,获取到决策轨迹(s,a,r,s_next),然后积累到一定样本时送到central_agent,对网络参数进行更新,更新完之后把参数复制给agent网络。
本文采用了两种并行训练的方式,一种是同步并行,即等所有agent采集完足够的样本,把所有agent的(s,a,r,s_next)送入到central_agent,计算梯度然后更新网络参数,更新完后把参数分发给各个agent。另一种是异步并行,即只要有一个agent采集完足够的样本,就把该agent的(s,a,r,s_next)送入到central_agent,计算梯度然后更新网络参数,更新完后把参数分发给该agent。本文将同时采用这两种训练方式。
4 实验结果
4.1 实验准备
测试视频选用DASH-246 JavaScript参考客户端的“Envivio-Dash3”序列,该视频采用H.264/MPEG-4编码,总时长为193秒,被分割成48个分片,每个分片的可用码率包括{300,750,1200,1850,2850,4300}六种,分片时长为4秒。训练和测试的网络轨迹选用挪威收集的3G / HSDPA移动数据集,由传输过程中(如通过公交、火车等)流媒体视频的移动设备生成。训练集包含了127个轨迹文件,每个文件包括300-1500个时刻的吞吐量测量值;测试集包含了147个轨迹文件,每个文件只有50-250个时刻的吞吐量测量值。吞吐量范围在0.2~6Mbps。本实验是在ubuntu16.04的Pycharm中下进行仿真,模拟码率决策和分片下载过程。
4.2 实验结果
采用PPO-clip的算法,且同步并行训练。输出本课题算法及现有算法在测试轨迹集上的总回报均值,如表1所示。

表1 不同算法在各个测试轨迹的总回报均值
可以看出,本文的算法在相同的测试轨迹下获得的总回报均值要高于现有算法。绘制不同算法在测试轨迹集上的总回报的累积分布曲线,如图3所示。
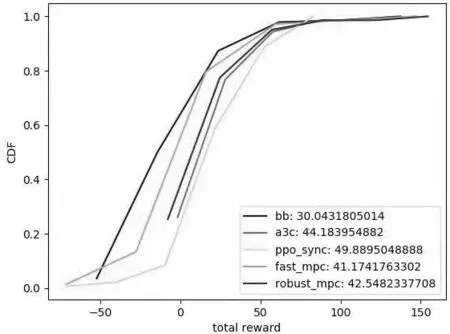
图3 不同算法在测试轨迹上的总回报累积分布曲线
可以看出,在横轴相同的区间范围内,本文算法在纵轴的比例较大,说明PPO算法落在较高回报值区间的比例最大。
随机选取一个轨迹,输出各个算法在测试轨迹下的码率选择,缓存区余量,带宽随时间变化曲线,如图4所示。
可以看出,PPO算法能够保证选择较高码率并且较稳定,码率切换频率较小,并且能够充分利用缓冲,在吞吐量即使较小时,如果缓冲区较充足,仍然选择较大码率,同时在缓存区低于门限值时能够立即减小码率。
选用ppo-pen、ppo-clip和同步并行、异步并行组合训练,输出四种方法下在测试轨迹集上的总回报均值,如表2所示。

表2 ppo-pen、ppo-clip及同步并行、异步并行组合训练在测试轨迹上的总回报均值
从ppo算法上看,ppo-clip总回报值要略高于ppo-pen,从并行训练方式上看,同步并行总回报值较高于异步并行。
从ppo算法分析,从式(3)和式(4)可以看出,ppo-clip是直接对新旧策略的比值进行一定程度的裁剪,可以保证两次更新之间的分布差距不大。从并行训练方式分析,异步并行会导致过期梯度情况,即cenral_agent在更新当前网络参数时使用的从agent传来的梯度可能是多次更新之前的参数,这样会导致梯度下降的过程变得不稳定,而实验中输出agent使用的参数,小于当前central_agent的参数版本在10-16,充分说明过期梯度的问题。对于这个问题,目前有研究提出给梯度增加延时补偿,利用梯度函数的泰勒展开来有效逼近损耗函数的Hessian矩阵。
输入状态的时间序列长度slen分别设置为1,4,8,16,采用ppo-clip及同步并行训练,输出这四种设置在测试轨迹上的总回报均值,如表3所示。

表3 四种不同的时间序列长度在测试轨迹上的总回报均值
可以看出,时间序列由1增大到4、由4增大到8时,总回报均值均有较大提升,但是由8增大到16时,总回报均值没有增大,反而有略微减小。
结果说明一定程度的增大历史吞吐量的数量可以提升码率决策性能,因为一定的历史吞吐量信息有利于较为准确地预测当前带宽,但是历史吞吐量数量增大到一定程度性能不再提升,因为当前动作对未来回报的影响是逐渐衰减的,越久之前的信息对当前影响越小。
5 结论
本文采用了强化学习和深度神经网络相结合的DRL算法,实现了DASH客户端的自适应码率决策算法。在真实网络轨迹数据集上进行多种算法的测试,实验结果表明:本文所采用的算法能够获得比现有算法更高质量的用户体验,并且具有较少的重缓冲事件和质量切换事件。
猜你喜欢
词学(2022年1期)2022-10-27
计算机应用(2022年9期)2022-09-25
计算机系统应用(2022年5期)2022-06-27
通信电源技术(2022年1期)2022-06-16
电子科技大学学报(2022年3期)2022-05-28
电子测试(2022年4期)2022-03-17
西安交通大学学报(2021年3期)2021-03-08
火控雷达技术(2018年4期)2019-01-15
集装箱化(2017年4期)2017-05-17
集装箱化(2016年11期)2017-03-29
