
基于深度学习的图像文字识别技术研究与应用
2020-05-25 02:30夏昌新莫浩泓王成鑫王瑶闫仕宇
软件导刊 2020年2期
夏昌新 莫浩泓 王成鑫 王瑶 闫仕宇


摘 要:针对传统图像文字识别技术采用模板匹配法和几何特征抽取法存在识别速度慢、准确率低的缺点,提出一种基于深度学习的图像文字识别技术,使用开源、灵活的Tensor Flow框架以及LeNet-5网络训练数据模型,并将训练好的模型应用于特定场景印刷体文字识别。实验结果表明,识别模型的top 1与top 5准确率分别达到了99.8%和99.9%。该技术不仅可快速有效地处理大量图片文件,而且能综合提高图像文字识别性能,节省大量时间。
关键词:文字识别;TensorFlow;深度学习;LeNet-5;数据模型
DOI:10. 11907/rjdk. 191546 开放科学(资源服务)标识码(OSID):
中图分类号:TP301文献标识码:A 文章编号:1672-7800(2020)002-0127-05
英标:Research and Application of Image Character Recognition Technology Based on Deep Learning
英作:XIA Chang-xin,MO Hao-hong,WANG Cheng-xin,WANG Yao,YAN Shi-yu
英单:(School of Computer Science,University of South China, Hengyang 421001,China)
Abstract: In view of the shortcomings of slow recognition speed and low accuracy in the traditional image and character recognition technology based on template matching method and geometric feature extraction method,an image character recognition technology based on deep learning is proposed. Open source, flexible TensorFlow framework and LeNet-5 network are used to train data model, and the trained model is applied to the recognition of printed characters in specific scenes. The experimental results show that the accuracy of top 1 and top 5 of the recognition model reaches 99.8% and 99.9% respectively. This technology can not only process a large number of image files quickly and effectively, but also improve the performance of optical character recognition and save a lot of time.
Key Words: character recognition;Tensorflow;deep learning;LeNet-5;data model
0 引言
随着信息化水平的不断提升,以图像为主的多媒体信息迅速成为重要的信息传递媒介,图像中的文字数据包含丰富的高层语义信息与分析价值。光学字符识别(Optical Character Recognition,OCR)指利用电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。它是一种针对印刷体字符,采用光学方式将纸质文档中的文字转换为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术,通过该技术可将使用摄像机、扫描仪等光学输入仪器得到的报刊、书籍、文稿、表格等印刷品图像信息转化为可供计算机识别和处理的文本信息[1]。目前,OCR技术广泛应用于多个领域,比如文档识别、车牌识别、名片识别、票据识别、身份证识别和驾驶证识别等。如何除错或利用辅助信息提高识别准确率和效率,已成为OCR技术研究热门课题。
传统OCR技术基于图像处理(二值化、连通域分析、投影分析等)和统计机器学习(Adaboost、SVM),采用模板匹配和几何特征抽取的方法进行识别,过去20年间我国在印刷体和扫描文档识别上取得了进展,如李俊[2]提出采用基于连通域的方法,通过对不同连通域的特征分析,区分识别有效区域和无效区域,解决了投影法对于图文混排、兼有表格的复杂版面不能正确切分的问题,但是该方法只限于一些简单场景,对于稍微復杂的应用场景,通过版面分析(连通域分析)和行切分(投影分析)生成文本行时,无法处理前背景复杂的随意文字(例如场景文字、菜单、广告文字等),且过度依赖字符切分结果,在字符扭曲、粘连、噪声干扰的情况下,切分的错误传播尤其突出;郑泽鸿等[3]提出将AP聚类算法应用于字符分割,根据类中心对特征点进行归类得到分割结果,该方法具有较高识别准确率,但在识别效率上有待提高,另外,二值化操作本身对图像成像条件和背景要求比较苛刻;田洁等[4]指出,二值化过程容易引入噪声、造成文字笔划信息丢失,传统OCR引擎用于识别叠加文字二值化后的结果可能不够鲁棒。
本文基于深度学习方法,将神经网络LeNet-5应用于字符识别模型训练,以期弥补传统方法对于字符粘连、模糊和形变情况下识别准确度较差的不足。
1 基本原理
1.1 OCR文字识别技术
通常OCR文字识别过程可分为图像输入、图像預处理、对比识别、后期纠正和结果输出等步骤。据此可将整个OCR识别流程划分为5个部分,图1为OCR文字识别系统工作流程。
文字识别常用方法有模板匹配法和几何特征抽取法。
(1)模板匹配法。将输入的文字与给定的各类别标准文字(模板)进行相关匹配,计算输入文字与各模板的相似程度,取相似度最大的类别作为识别结果。该方法适用于识别固定字型的印刷体文字,优点是用整个文字进行相似度计算,对文字缺损、边缘噪声等具有较强的适应能力;缺点是当被识别类别数增加时,标准文字模板的数量也随之增加,增加机器存储容量会降低识别正确率。
(2)几何特征抽取法。抽取文字的一些几何特征,如文字端点、分叉点、凹凸部分及水平、垂直、倾斜等各方向的线段、闭合环路等,根据这些特征的位置和相互关系进行逻辑组合判断,获得识别结果。该识别方式由于利用结构信息,也适用于变形较大的手写体文字。不足之处在于当出现文字粘连扭曲、有噪声干扰时,识别效果不佳。
1.2 基于深度学习的LeNet-5网络
深度学习(Deep Learning)是多层神经网络运用各种机器学习算法解决图像、文本等各种问题的算法集合。深度学习的核心是特征学习,它通过组合低层特征形成更加抽象的高层表示属性类别或特征,从分层网络中获取分层次的特征信息,以发现数据分布式特征表示,从而解决以往需要人工设计特征的难题。
利用深度学习进行文字识别,采用的神经网络是卷积神经网络(Convolutional Neural Networks,CNN),具体选择使用哪一个经典网络需综合考虑,越深的网络训练得到的模型越好,但是相应训练难度会增加,此后线上部署时预测的识别速度也会很慢,所以本文使用经简化改进后的LeNet-5(-5表示具有5个层)网络,如图2所示。它与原始LeNet稍有不同,比如把激活函数改为目前常用的ReLu函数;与现有conv->pool->ReLu不同的是其使用的方式是conv1->pool->conv2->pool2,再接全连接层,但是不变的是卷积层后仍然紧接池化层。
2 基于深度学习的图像文字识别技术
2.1 方法步骤
本文在开源的TensorFlow框架开发环境下,搭建深度学习神经网络LeNet-5和计算图,将样本文件添加到训练队列中喂给网络训练,完成充足的训练量后,对模型进行识别准确率评估,并最终将训练得到的识别模型应用于实际场景中的图像文字识别实验检测,流程如图3所示。
2.1.1 网络搭建
深度学习训练的第一步是搭建网络和计算图。文字识别实质上是一个多分类任务,识别1 000个不同的文字,相当于1 000个类别的分类任务。在搭建的网络中加入batch normalization。另外损失函数选择sparse_softmax_cross_entropy_with_logits,优化器选择Adam,学习率设为0.1,实现代码如下:
#network: conv2d->max_pool2d->conv2d->max_pool2d->conv2d->max_pool2d->conv2d->conv2d->max_pool2d->fully_connected->fully_connected
#给slim.conv2d和slim.fully_connected准备了默认参数:batch_norm
with slim.arg_scope([slim.conv2d, slim.fully_connected],
normalizer_fn=slim.batch_norm,
normalizer_params={'is_training': is_training}):
conv3_1 = slim.conv2d(images, 64, [3, 3], 1, padding='SAME', scope='conv3_1')
max_pool_1 = slim.max_pool2d(conv3_1, [2, 2], [2, 2], padding='SAME', scope='pool1')
conv3_2 = slim.conv2d(max_pool_1, 128, [3, 3], padding='SAME', scope='conv3_2')
max_pool_2 = slim.max_pool2d(conv3_2, [2, 2], [2, 2], padding='SAME', scope='pool2')
conv3_3 = slim.conv2d(max_pool_2, 256, [3, 3], padding='SAME', scope='conv3_3')
max_pool_3 = slim.max_pool2d(conv3_3, [2, 2], [2, 2], padding='SAME', scope='pool3')
conv3_4 = slim.conv2d(max_pool_3, 512, [3, 3], padding='SAME', scope='conv3_4')
conv3_5 = slim.conv2d(conv3_4, 512, [3, 3], padding='SAME', scope=‘conv3_5)
max_pool_4 = slim.max_pool2d(conv3_5, [2, 2], [2, 2], padding='SAME', scope='pool4')
flatten = slim.flatten(max_pool_4)
fc1 = slim.fully_connected(slim.dropout(flatten, keep_prob), 1024,
activation_fn=tf.nn.relu, scope='fc1')
logits = slim.fully_connected(slim.dropout(fc1, keep_prob), FLAGS.charset_size, activation_fn=None,scope='fc2')
# 因为没有做热编码,所以使用sparse_softmax_cross_entropy_with_logits
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=labels))
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(logits, 1), labels), tf.float32))
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
if update_ops:
updates = tf.group(*update_ops)
loss = control_flow_ops.with_dependencies([updates], loss)
global_step = tf.get_variable("step", [], initializer=tf.constant_initializer(0.0), trainable=False)
optimizer = tf.train.AdamOptimizer(learning_rate=0.1)
train_op = slim.learning.create_train_op(loss, optimizer, global_step=global_step)
probabilities = tf.nn.softmax(logits)
2.1.2 模型训练
训练之前需先设计好数据,为高效地进行网络训练作好铺垫。主要步骤如下:
(1)创建数据流图。该图由一些流水线阶段组成,阶段间用队列连接在一起。第一阶段将生成并读取文件名,并将其排到文件名队列中;第二阶段从文件中读取数据(使用Reader),产生样本且把样本放在一个样本队列中。
根据不同的设置,或者拷贝第二阶段的样本,使其相互独立,因此可以从多个文件中并行读取。在第二阶段排队操作,即入队到队列中去,在下一阶段出队。因为将开始运行这些入队操作的线程,所以训练循环会使样本队列中的样本不断出队,如图4所示。
图4 样本队列数据读入流程
样本队列的入队操作在主线程中进行,Session中可以多个线程一起运行。在数据输入的应用场景中,入队操作从硬盘中读取输入进行,再放到内存中,速度较慢。使用QueueRunner可以创建一系列新的线程进行入队操作,让主线程继续使用数据。如果在训练神经网络的场景中,则训练网络和读取数据异步,主线程在训练网络时,另一个线程再将数据从硬盘读入内存。
训练时数据读取模式如上所述,则训练代码设计为:
with tf.Session(config=tf.ConfigProto(gpu_options=gpu_options, allow_soft_placement=True)) as sess:
# batch data 獲取
train_images, train_labels = train_feeder.input_pipeline(batch_size=FLAGS.batch_size, aug=True)
test_images, test_labels = test_feeder.input_pipeline(batch_size=FLAGS.batch_size)
graph = build_graph(top_k=1) # 训练时top k = 1
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
# 设置多线程协调器
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
train_writer = tf.summary.FileWriter(FLAGS.log_dir + '/train', sess.graph)
test_writer = tf.summary.FileWriter(FLAGS.log_dir + '/val')
start_step = 0
(2)指令执行。设置最大迭代步数为16 002,每100步进行一次验证,每500步存储一次模型。
训练过程的损失函数loss和精度函数accuracy变换曲线如图5、图6所示。
损失(loss)和精度(accuracy)是用于衡量模型预测偏离其训练对象期望值的衡量指标,从图5、图6可以看出loss和accuracy最大值分别稳定在0.05、0.9左右,说明模型训练顺利完成,已具备替代训练对象进行文字识别工作的能力。
(3)模型性能评估。在对模型进行训练调试之后,再对模型性能进行评估,计算模型top 1(识别结果的第一个是正确的概率)和top 5(识别结果的前5个中有正确结果的概率)的准确率,使模型应用效果达到最佳。计算模型top 1和top 5准确率的代码为:
i = 0
acc_top_1, acc_top_k = 0.0, 0.0
while not coord.should_stop():
i += 1
start_time = time.time()
test_images_batch, test_labels_batch = sess.run([test_images, test_labels])
feed_dict = {graph[‘images]: test_images_batch,
graph[‘labels]: test_labels_batch,
graph[‘keep_prob]: 1.0,
graph[‘is_training]: False}
batch_labels, probs, indices, acc_1, acc_k = sess.run([graph[‘labels],
graph[‘predicted_val_top_k],
graph[‘predicted_index_top_k],
graph[‘accuracy],
graph[‘accuracy_top_k]],
feed_dict=feed_dict)
final_predict_val += probs.tolist()
final_predict_index += indices.tolist()
groundtruth += batch_labels.tolist()
acc_top_1 += acc_1
acc_top_k += acc_k
end_time = time.time()
logger.info(“the batch {0} takes {1} seconds, accuracy = {2}(top_1) {3}(top_k)”
.format(i, end_time - start_time, acc_1, acc_k))
預测的top 1和top 5准确率如图7所示。
从图中可以看出,识别模型top 1和top 5分别达到了99.8%、99.9%,识别准确率很高。
2.2 实验结果
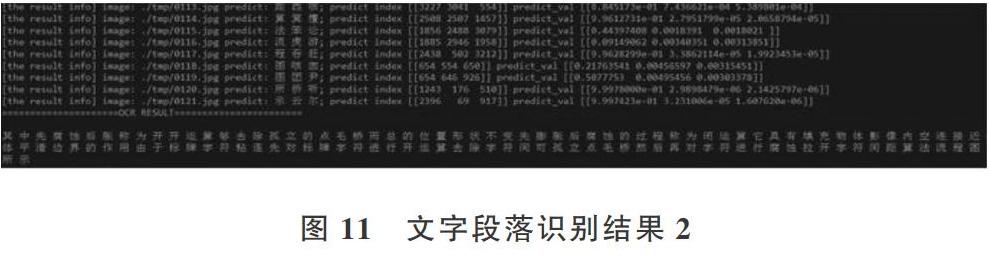
从某文档中截取出一段文字以图片格式保存,再使用文字切割算法把文字段落切割为单字,如图8、图9所示。
对文字段落进行识别,由于使用的是GPU,识别速度非常快,除去系统初始化时间,全部图像识别时耗不超过1s。其中输出的信息分别是:当前识别的图片路径、模型预测出的top 3汉字(置信度由高到低排列)、对应的汉字ID、对应概率。在识别完成之后,将所有识别文字按顺序组合成原始段落排列,如图10、图11所示。
从图中可以看出单字的识别非常准确,在最后显示的文字段落识别结果中可以看到仅个别文字识别出现偏差,整体识别效果佳,说明该模型的识别能力可满足一般实际场景印刷体文字识别要求。
3 结语
经过测试,基于深度学习的图像文字识别模型在模型评估上top 1的正确率达到了99.8%。与传统OCR相比,基于深度学习的OCR技术在识别准确率方面有大幅上升。在一些比较理想的环境下,文字识别效果较好,但是处理复杂场景或一些干扰比较大的文字图像时,识别效果有待提高,后续将对模型作进一步优化。
随着OCR技术的迅猛发展,文本检测和识别技术将拓展更多语言支持。从图像中提取文字对于图像高层次语义理解、索引和检索意义重大。结合深度学习的神经网络和NPL语义分析提升OCR识别纠错能力,帮助个体提升效率、创造价值,是未来重要发展趋势。
参考文献:
[1] 王文华. 浅谈OCR技术的发展和应用[J]. 福建电脑,2012,28(6):56,92.
[2] 李俊. 印刷体文字识别系统的研究与实现[D]. 成都:电子科技大学,2011.
[3] 郑泽鸿,黄成泉,梁毅,等. 基于AP聚类的中文字符分割[J]. 智能计算机与应用,2018,8(1):65-67,71.
[4] 田洁,王伟强,孙翼. 一种免除二值化的视频叠加中文字符识别方法[J]. 中国科学院大学学报,2018,35(3):402-408.
[5] 张桂刚,李超,邢春晓. 大数据背后的核心技术[M]. 北京:电子工业出版社,2017.
[6] 李月洁. 自然场景中特定文字图像优化识别研究与仿真[J]. 计算机仿真,2016, 33(11):357-360.
[7] 王若辰. 基于深度学习的目标检测与分割算法研究[D]. 北京:北京工业大学,2016.
[8] 叶韵. 深度学习与计算机视觉[M]. 北京:机械工业出版社,2017.
[9] 张三友,姜代红. 基于OPENCV的智能车牌识别系统[J]. 软件导刊, 2016,15(5):87-89.
[10] 黄攀. 基于深度学习的自然场景文字识别[D]. 杭州:浙江大学, 2016.
[11] 喻俨,莫瑜. 深度学习原理与TensorFlow实践[M]. 北京:电子工业出版社, 2017.
[12] 丁明宇,牛玉磊,卢志武,等. 基于深度學习的图片中商品参数识别方法[J]. 软件学报, 2018,29(4):1039-1048.
[13] 何树有. 自然场景中文字识别关键技术研究[D]. 大连:大连理工大学, 2017.
[14] 舒跃育,刘红梅. 深度学习推进人工智能变革[N]. 中国社会科学报,2018-02-06(005).
[15] 姚东林. 基于安卓的文字识别系统的设计与实现[D]. 西安:西安电子科技大学,2014.
[16] 张纪绪. 面向移动平台的离线手写文档识别系统[D]. 哈尔滨:哈尔滨工业大学,2017.
[17] MADCOLA. CNN网络架构演进:从LeNet到DenseNet[EB/OL]. https://www.cnblogs.com/skyfsm/p/8451834.html.
[18] BARAT C,DUCOTTET C. String representations and distances in deep convolutional neural networks for image classification[J]. Pattern Recognition,2016(54):104-115.
[19] HLáDEK D,STA? J,ONDá? S, et al. Learning string distance with smoothing for OCR spelling correction[J]. Multimedia Tools and Applications,2017(76):24549-24567.
[20] BALOOCHIAN H,GHAFFARY H R,BALOCHIAN S. Enhancing fingerprint image recognition algorithm using fractional derivative filters[J]. Open Computer Science,2017(2):9-16.
[21] RYAN M,HANAFIAH N. An examination of character recognition on ID card using template matching approach[J]. Procedia Computer Science,2015(59):520-529.
(责任编辑:江 艳)
猜你喜欢
医学食疗与健康(2021年27期)2021-05-13
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
中国交通信息化(2018年5期)2018-08-21
互联网周刊(2009年13期)2009-07-29
