
云环境下结合改进粒子群优化与检查点技术的容错调度算法
2020-05-25 02:30孙默辰邵清
软件导刊 2020年2期
孙默辰 邵清

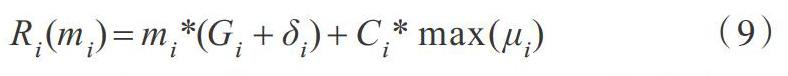
摘 要:云计算环境中任务执行容易受资源故障影响,导致调度效率与成功率降低。针对该问题,提出一种结合改进粒子群优化与检查点技术的容错调度算法。通过改进粒子群优化算法进行全局搜索,寻找粒子群最优解,以保证任务获取最优资源,减少调度复杂度;同时通过设置检查点,使失效任務从检查点继续执行,实现任务动态恢复,提高调度可靠性。仿真实验表明,与传统算法相比,当任务数量不断增加时该算法可提高任务执行成功率,缩短任务执行时间。
关键词:云计算;任务调度;容错;粒子群优化;检查点技术
DOI:10. 11907/rjdk. 191566 开放科学(资源服务)标识码(OSID):
中图分类号:TP312文献标识码:A 文章编号:1672-7800(2020)002-0007-05
英标:Fault-tolerant Scheduling Algorithm Based on Improved Particle Swarm Optimization in Cloud Environment
英作:SUN Mo-chen,SHAO Qing
英单:(School of Optical-Electrical and Computer Engineering,University of Shanghai for Science and Technology,Shanghai 200093,China)
Abstract:Task execution is susceptible to resource failures in cloud computing environment which leads to a reduction in scheduling efficiency and success rate. In order to solve this problem, a fault-tolerant scheduling algorithm based on improved particle swarm optimization and checkpoint technology is proposed. Firstly, the particle swarm optimization algorithm is used for global search to find the optimal solution, and it will ensure that the task gets the optimal resources and reduces the complexity of the task scheduling. At the same time, by setting a checkpoint, the invalid task is continuously executed from the checkpoint to achieve dynamic recovery of the task and improve scheduling reliability. Simulation experiments show that as the number of tasks increases, the algorithm can improve the success rate of task execution and also shorten the task execution time when compared with the traditional algorithm.
Key Words:cloud computing; task scheduling; fault tolerance; particle swarm optimization; checkpoint technology
0 引言
在互联网时代,信息量呈不断增大趋势,目前已进入大数据时代[1]。互联网已融入公众日常生活,但原有的计算机模式已不能满足处理海量数据的需求[2]。为了更好地处理海量数据信息,在计算机和网络技术基础上,云计算作为一种新兴的计算范式[3-6],受到业界和学术界的关注。作为未来重要行业领域的主流IT应用模式,云计算将为重点行业用户信息化建设与IT运维管理工作奠定核心基础,并助力行业迅速发展。
云计算面对的计算任务数量庞大,任务调度和资源分配问题是决定云计算效率的重难点[7],同时在处理数据过程中会产生大量、重要的中间数据,因此数据可靠性也是亟待解决的重点问题,即完善的容错机制对云计算必不可少[8]。从云环境下的任务容错调度需求出发,在确保每个任务被分配到最佳资源上的同时,尽可能减少故障对任务调度产生的影响。检查点技术是一种常用的容错方法,通过设置检查点和回卷恢复机制可使失效任务重新恢复执行,从而提高调度可靠性[9]。
针对云计算任务调度与容错技术,国内外学者进行了相应研究,并提出了很多算法,如文献[10]分别对蚁群算法和粒子群算法(Particle Swarm Optimization,PSO)进行改进,综合两种算法的优势建立一种蚁群粒子群算法,以提高云计算资源调度效率;文献[11]提出一种多种服务质量QoS(Quality of Service)约束离散粒子群优化的任务调度算法,该算法在满足调度截止期的情况下具有较高的可靠性,并且对Makespan性能影响较小,但是以上算法均没有考虑系统容错问题,导致任务调度成功率较低;文献[12]提出一种虚拟化云平台中的容错调度算法,通过主副版本方法实现对物理主机的容错,有效提高了资源利用率,但是时间成本较高;文献[13]提出一种基于任务备份的云计算容错调度算法,根据云计算的安全等级对任务进行备份,重新调度失效任务,具有较好的容错性,但是资源调度效率较低。
上述算法均没有将任务调度与容错机制有效结合。因此本文提出一种基于改进粒子群优化与检查点技术的容错调度算法(FTCM-PSO),在确保每个任务被分配至最佳资源的基础上,同时通过设置检查点,使失效任务从检查点继续执行,实现任务动态恢复,提高调度可靠性。仿真实验表明,与传统算法相比,该算法能够提高任务执行成功率,同时任务执行时间也有一定程度缩短。
1 问题描述
在云计算环境下任务调度指建立任务与资源之间的映射,资源处理能力越高,表明调度到该资源上的任务处理时间越短。
在一次全局分配α中,用户提交的任务t被分配到各个资源VM中,资源负载情况和计算能力将随之变化,仅通过查看资源配置参数无法正确呈现资源性能变化,为了正确展示资源性能变化情况,用公式(1)、公式(2)计算资源负载情况。
其中[vmi]表示资源编号,[Pi]表示资源性能参数,[L(α)i]表示某个任务开始时资源的当前负载,[Tmax(α)i]表示分配到资源[vmi]上所有任务执行完成时间,[lenti]表示分配到资源[vmi]上所有任务长度,本文用任务长度表示任务大小,[Bi]代表资源[vmi]可用带宽,所以每当一个新任务分配到资源[vmi]上后,對应任务执行时间[Tmax(α)i]均随之变化。此外,本文引入检查点技术为任务调度提供容错机制,因此对于任务[tj]在资源[vmi]上的执行时间计算公式为:
其中,[mi]表示任务[ti]的检查点数量,[Gi]表示检查点设置时间开销,[δi]为故障检测时间开销,[Ci]为资源故障发生次数,[μi]为卷回恢复时间开销。在任务到达资源之前,每个资源均有默认的参数,例如处理器速度、当前负载和带宽。这些参数将被用来计算资源处理任务的能力,本文采用改进粒子群优化算法获取适应度高的最优粒子,它代表全局最佳资源,即该资源处理任务能力最高。任务调度是建立任务与资源之间的映射,资源处理任务能力越高,表明任务执行时间越短。算法目标是找到全局最佳资源,并将任务分配到该资源上,从而减少任务执行时间。用[TVij]表示资源[vmi]对任务[tj]的处理能力,MIPSi表示处理器速度,[1-L(α)i]表示当前资源所剩负载大小。因此在云环境任务调度问题中,求最小完成时间的问题可转化为求函数优化问题,目标函数为:
本文针对任务调度模型作出如下假设:
假设1:各任务之间没有依赖关系,资源性能可满足每个任务的要求。
假设2:所有任务可被完全分配。
假设3:资源是被独占而非共享的,一个资源只能被一个任务占用。
2 算法设计
本文设计一种结合改进粒子群优化与检查点技术的容错调度算法。通过寻求粒子群最优解获取最佳资源,减少调度复杂性,并在任务执行过程中设置检查点,通过回卷恢复机制实现容错效果。
2.1 粒子群优化方案
由于任务调度是离散问题,在应用粒子群算法时[14-15],应使用离散的数值对粒子进行编码,将任务调度与粒子位置、速度等结合起来。本文对粒子群算法中的粒子使用间接编码的方式[16]。
2.1.1 速度操作算法设计
假设存在t个任务,将这t个任务分割成m个子任务,资源数量为n个,则粒子可编码为公式(5)所示的m维向量。
其中,i表示种群中第i个个体,j表示个体的第j维,其中1≤j≤m,xij表示[1,n]范围内的自然数。例如设置t=2,m=7,n=4。粒子可编码为(3,4,2,1,4,2,3,1,3,4),如表1所示,每个粒子均代表一种调度方案,通过对粒子解码可知任务分配情况。
为获得子任务在计算资源上的分布情况,对已编码的粒子进行相应解码。由表1中的粒子编码情况,对粒子进行解码,结果如表2所示。
通过表2解码可知,计算资源1用来执行子任务{4},由此可知子任务{3, 6}、{1, 7}、{2, 5},分别分配到计算资源2、3、4。
设种群规模为NP,即为系统随机初始化NP个粒子。xij、vij表示将第j个任务分配到第i个资源上后粒子位置和速度。其中1≤i≤NP,初始化vij的值设置为[-vmax,vmax]之间的随机数。每个粒子在更新自己速度和位置时均根据自己搜索到的历史最佳点和群体内其它粒子搜索的历史最佳点两个值进行迭代更新,粒子根据公式(6)、(7)更新自己的速度和位置。
2.1.2 惯性权重设计
在速度更新公式中引入惯性权重ω[17],通过ω的选取影响全局和局部搜索能力。
在标准粒子群算法中通常使用固定值的惯性权重ω值,但是通过阅读大量文献发现,当使用动态的惯性权重ω值时,改进的粒子群优化算法可以得到更好的收敛结果。在算法初期使用较大的ω值,使搜索步伐加大,随着迭代次数的不断增加,逐渐减小ω值,缩小搜索步伐,防止错过最优解。因此使用一个合适的动态惯性权重值可以平衡算法的全局和局部搜索能力,使算法可以在使用最少迭代次数的同时得到最优结果。
本文对ω进行改进,使搜索过程具有非线性自适应动态调节的特点。具体公式为:
其中,tmax表示最大迭代次数,t表示当前迭代次数,ωmax和ωmin分别表示惯性权重ω的最大值、最小值,由于惯性权重ω常在[0.4, 0.9]之间变化,因此ωmax=0.9,ωmin=0.4。为了测试参数n对惯性权重ω的影响,对n取[0.5, 2.0]之间的数值进行验证。
如图1所示,当n较小时,随着迭代次数的增加,ω减小速度过快,不利于后期局部搜索;当n为1时,ω呈线性变化;而当n过大时,ω较早收敛为0。实验表明当n=1.5时,ω的变化满足迭代后期缓慢减小的要求,因此取参数n=1.5。
2.2 检查点设置与恢复实现
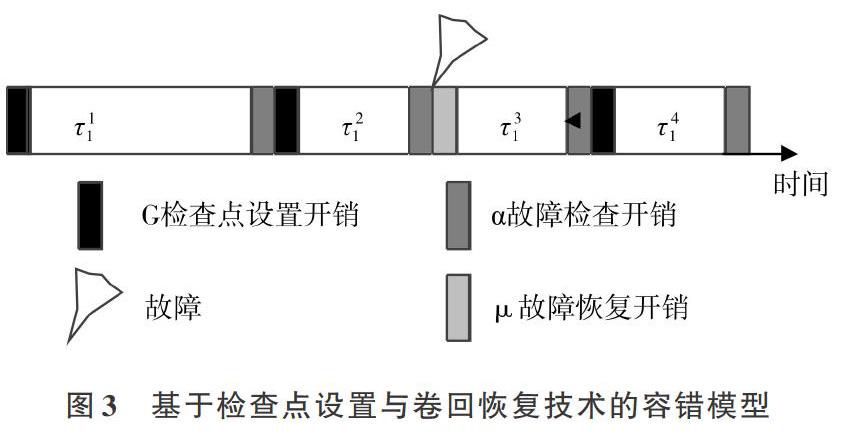
检查点技术可定期保存任务执行状态[18],并在任务执行出错后从检查点位置恢复执行,这是故障恢复的一种重要方法,但需要合理设置检查点,以减少任务执行开销。
2.2.1 检查点设置
在检查点技术中,检查点文件是一个重要的概念,存储和故障后的回滚均依赖检查点文件。为了尽量减少检查点的设置开销,在检查点文件的生成过程中,检查进程哪些部分发生了变化,如果发生了变化,则更新进程。检查点恢复技术原理如图2所示。
在检查点恢复技术中,检查点的设置间隔与任务执行总时间存在如下关系:检查点间隔较短,则设置检查点的代价较大,导致任务执行总时间可能变长;相反,检查点间隔较长,则导致故障发生时从上一检查点重新执行的时间代价较大,因此检查点间隔的设置对任务执行的时间至关重要。本文通过等距检查点设置算法,确保在任务执行过程中,保持检查点间隔不变。如果任务执行时间为T,检查点设置开销为G,故障上限是k,采用固定检查点间隔τ=可使任务在最坏情况下的执行时间最短。
2.2.2 恢复实现
在云计算任务调度下,任务T={t1, t2,…, tn}的配置属性可由7元组〈Ti, Di, Ci, mi, Gi, δi, μi〉表示,其中Ti、Di、Ci分別表示任务ti的到达时间、截止时间、最坏执行时间,且Ci 基于该模型,在任务可能发生多次故障的情况下,同时考虑检查点设置开销、故障检测开销、故障恢复开销,即任务故障响应时间的计算公式Ri(mi)为: 其中[Ri(mi)]为检查点设置时间与故障检测时间及故障恢复时间之和。故障恢复时间是在任务执行时间内,故障发生次数与最大故障恢复开销的乘积。 2.3 算法流程 基于改进粒子群优化与检查点技术的容错调度算法流程如图4所示。 算法步骤描述如下: 步骤1:初始化NP个粒子的位置和速度。 步骤2:通过公式(6)、公式(7),不断更新粒子的位置和速度。 步骤3:判断是否达到了最大迭代次数,如果达到即找到适应度高的最优粒子即最佳资源,将任务分配到该资源上;如果没有达到,则回到步骤2。 步骤4:在最佳资源上执行任务。 步骤5:判断任务是否完成,若任务未完成,判断任务是否执行失败,若任务失败:读取最近一次保存检查点信息,记录资源故障次数,从上次保存的状态重新执行失败任务,然后执行步骤4;若任务成功:保存检测点信息然后继续执行步骤4;若任务完成,记录任务完成总时间。 步骤6:判断所有任务是否执行完成,若未完成,执行步骤2寻找最佳资源执行任务;若完成,则结束任务。 3 实验研究 3.1 实验方案 首先,为验证迭代次数对改进粒子群算法性能的影响,设定迭代次数的范围为100~400,粒子群大小为50,记录执行完成200个任务所需的时间和任务完成率,将两项结果转化成相对值在一个图形中展示。 从图5可知,任务完成时间的减少及任务完成率的提高表示改进粒子群优化算法性能在一定范围内,随迭代次数的增加逐渐提高,但当迭代次数达到300次后,两项性能指标曲线趋于稳定,为确保完整算法性能稳定,本文设定迭代次数为300次。 其次,为了验证本文算法性能,利用云平台CloudSim构建实验环境,设定20个不同执行能力的资源且每个资源下的机器数量从10~20不等。在本次实验中,主要观察不同任务数对算法性能的影响,即规定在一定时间范围内执行50~300个不同大小的任务,为便于计算,假设在任务执行过程中仅发生一次故障。环境和模拟参数如表3所示。 3.2 实验结果与分析 为了验证本文融合检查点技术的容错调度算法(FTCM-PSO)的有效性,将其与基于蚁群优化的容错调度算法(ACOwFT)[19]、基于粒子群优化的多目标任务调度算法(TSPSO)[20]进行对比分析。为了获取更精确的测量结果,进行10次实验后取其平均值。 由图6可知,在任务数量较少时,因为FTCM-PSO算法设置检查点造成的时间开销,导致任务执行时间略高于TSPSO算法,FTCM-PSO算法与ACOwFT算法的表现相当。然而,随着任务数量的增加,本文FTCM-PSO算法可在任务将要执行时对资源作出更好的选择,将任务分配到最佳资源上执行,并且在执行过程中遇到资源故障时,可直接把任务进程恢复到检查点时刻的状态继续运行,从而大幅缩短任务执行时间,且随着任务数量的继续增加,执行时间差距逐渐增大,本文算法优势会愈加明显。 从图7可看出,随着任务数量的增加,3种算法的错失率均在增加,但是相比不具有容错机制的TSPSO算法,其它两种算法的错失率相对较低,本文算法有明显优化效果。 4 结语 为了提高云计算下任务调度算法的容错性能,本文通过引入检查点技术,利用检查点设置和回卷恢复技术,缩短了任务总执行时间,提高了资源利用率。同时,在任务分配期间,通过改进粒子群优化算法的粒子搜索能力,选择最佳资源,不但能缩短任务执行时间,还降低了任务执行错失率。仿真实验表明,该算法在容错性能上优于ACOwFT算法和TSPSO算法,调度可靠性进一步提高。 参考文献: [1] WIN T Y, TIANFIELD H, MAIR Q. Big data based security analytics for protecting virtualized infrastructures in cloud computing[J]. IEEE Transactions on Big Data,2018,4(1):11-25. [2] WU J X. Thoughts on the development of novel network technology[J]. Science China(Information Sciences),2018,61(10):144-154. [3] 张鹏,王桂玲,徐学辉. 云计算环境下适于工作流的数据布局方法[J]. 计算机研究与发展,2013,50(3):636-647. [4] BUYYA R, GARG S K, CALHEIROS R. SLA-oriented resource provisioning for cloud computing: challenges, architecture, and solutions[C]. International Conference on Cloud and Service Computing, 2011:1-10. [5] 刘永.云计算技术研究综述[J]. 软件导刊,2015,14(9):4-6. [6] 胡莹.云计算及其关键技术研究[J]. 软件导刊,2016,15(8):159-161. [7] MAZHAR B, JALIL R, KHALID J, et al. Comparison of task scheduling algorithms in cloud environment[J]. International Journal of Advanced Computer Science and Applications,2018,6(4):384-390. [8] 王勇, 刘美林, 李凯,等. 云环境下基于可靠性的均衡任务调度算法研究[J]. 计算机科学,2015,42(S1):325-331. [9] 杨娜, 刘靖. 融合容错需求和资源约束的云容错服务适配方法[J]. 计算机科学,2017,44(7):61-67. [10] 萨日娜. 基于蚁群粒子群优化算法的云计算资源调度方案[J]. 吉林大学学报:理学版,2017,55(6):1518-1522. [11] WANG Y, LIU Y G, GUO J F, et al. QoS scheduling algorithm in cloud computing based on discrete particle swarm optimization[J]. Computer Engineering,2017,43(6):111-117. [12] 王吉,包卫东,朱晓敏. 虚拟化云平台中实时任务容错调度算法研究[J]. 通信学报,2014,35(10):171-180,191. [13] GULER B, OZKASAP O. Efficient checkpointing mechanisms for primary-backup replication on the cloud[J]. Concurrency and Computation: Practice and Experience,2018,30(21):e4707. [14] ZHANG Y, YANG R. Cloud computing task scheduling based on improved particle swarm optimization algorithm[C]. IECON 2017 - 43RD Annual Conference Of The IEEE Industrial Electronics Society,2017:8768-8772. [15] WANG Q, FU X L, DONG G F. et al. Research on cloud computing task scheduling algorithm based on particle swarm optimization[J]. Journal of Computational Methods in Sciences and Engineering,2018,8(9):1-9. [16] 劉志雄. 求解调度问题的粒子群算法编码方法研究[J]. 武汉科技大学学报,2010,33(1):99-104. [17] LI X G, ZHU E Z, ZHANG Y W. A novel computation method for adaptive inertia weight of task scheduling algorithm[J]. Computer Research and Development,2016,53(9):1990-1999. [18] HE Z Z, MEN C G, LI X. Schedulability of fault-tolerant real-time system based on checkpoint interval optimization[J]. Journal of Jilin University,2014,44(2):433-439. [19] IDRIS H, EZUGWU A E, JUNAIDU S B, et al. An improved ant colony optimization algorithm with fault tolerance for job scheduling in grid computing systems[DB/OL]. http://europepmc.org/backend/ptpmcrender.fcgi?accid=PMC5435234&blobtype=pdf. [20] JENA R K. Multi-objective task scheduling in cloud environment using nested PSO framework[J]. 3RD International Conference on Recent Trends in Computing,2015,57:1219-1227. (责任编辑:江 艳)
猜你喜欢
制造技术与机床(2019年4期)2019-04-04
测控技术(2018年7期)2018-12-09
计算机应用(2016年12期)2017-01-13
大学教育(2016年9期)2016-10-09
信息通信技术(2015年6期)2015-12-26
华东理工大学学报(自然科学版)(2015年4期)2015-12-01
现代电子技术(2015年16期)2015-11-17
现代电子技术(2015年21期)2015-11-09
