
基于SSM 框架和大数据技术的校企协同育人平台设计与实现*
2020-05-25 09:10洪东
广西民族大学学报(自然科学版) 2020年2期
洪 东
(广西交通职业技术学院 信息工程系,广西 南宁 530023)
0 引言
《关于深化产教融合的若干意见》中简述了深化产教融合的原则——统筹协调,共同推进;服务需求,优化结构;校企协同,合作育人.根据《意见》,深化产教融合的主要目标是:逐步完善多元化办学体制,提高行业企业参与办学的程度,全面推进校企合作育人.[1]由此可见,国家层面对校企协同育人非常重视,所以,通过SSM 框架技术搭建Web服务端,结合云计算技术完成Hadoop分布式服务器构建,利用大数据技术对数据资源进行分类、筛选、分析等,为校企双方管理都提供可视化的管理模式.
1 校企协同育人的现状
1.1 校企深度合作未能达成共识
企业需要什么样的人才? 学校培养出对应的人才进行服务.作为高职院校,实践动手能力强是学生的特色.因此,在实践教学环节中,职业院校会让学生走进企业并在一线环境中学习新知识、新技术.但是,职业院校作为育人的主体与企业对接不紧密,而企业因本身的经济发展也忽略对职业院校人才的培养.
1.2 校企协同育人模式单一
校企合作的深度不够,双方未根据学院专业特色,企业用人的特点,对人才的需求进行分类培养.在引企入校,双导师授课,企业入驻课堂等模式,双方只停留于浅表层面,未能深入探究.协同育人过程出现问题双方未能及时解决,制度政策不完善,缺乏双向管理.
1.3 校企合作平台缺乏数据管理
目前,企业与职业院校签订协同育人协议后,大部分都是停留在“一纸协议”的模式,协同育人过程中,企业的积极性不高,职业院校教学质量无法与企业联合,毕业生和企业岗位不能无缝对接.[2]针对上述的问题,缺乏信息平台或大数据技术进行数据记录、跟踪、管理、分析等,导致合作双方对人才培养的过程管理无法掌控.
2 校企协同育人的意义
2.1 提升职业院校产学研水平
职业院校的教育教学要突出“职业特色”,校企合作教育则成为职业教育适应区域经济发展和社会资源共享的必然选择,各职业院校根据自身的办学特点及当地区域经济的发展,探索和实践企业行业特色的校企合作人才培养模式.[3]职业院校从专业设置、课程体系、教学内容、课堂活动、课程开发等方面与企业需求进行对接,在协同育人的过程中,与知名企业合作,提高育人的标准,促进教学质量的提升,教师能力水平和科研能力的提高,服务企业项目的实力增强.
2.2 提高课堂教学质量
采用“企业入驻课堂,双导师授课”等模式,使教学经验丰富的校内专职教师和项目经验丰富的企业工程师共同授课,共同管理.学生在接收理论知识的同时也能接收实践性强、实用性泛的新兴技术.合作企业还承担课程体系中的专业见习,顶岗实习和毕业实习任务,真正融入企业让学生的专业技能得到更高的提升,形成“理论与案例相结合,实践与应用相结合”的课堂教学特色.
2.3 增强学生就业竞争力
企业引入新兴的生产流程和技术,把优秀的企业管理理念和文化引入校园,让学生提前接触和适应社会.通过校企协同育人,学院在创新工作室、实训课堂、校内专业见习等引入企业文化、企业制度、经营理念、企业项目等,使学生零距离接触企业生产、管理的真实环境,提升学生综合素质.
3 校企协同育人平台构建思路
(1)搭平台记录数据.采用SSM 框架搭建校企协同育人平台,记录学生成长轨迹,包含:在校期间每个学期每门课程的成绩,参加各类技能大赛获得成绩,参与科研项目或企业真实项目的记录等.除此之外,记录并跟踪往届学生的成长轨迹,做好完整的育人体系链.
(2)大数据分析改革教学.运用大数据技术,对就业岗位、待遇、职业发展等进行分析,根据学生各维度情况,智能推荐企业及工作岗位.同时,将综合分析出的情况反哺教学,对人才培养方案进行修订,课程体系改革,人才培养模式完善,培育出更多优秀应用型人才.
(3)打造数字资源库.校企共同构建数字资源库,融合虚拟仿真平台、操作视频、UI界面设计素材、原理动画等数字媒体资源.同时,可依托“数字资源平台”形成政府、行业、企业、学校多层管理、监督、监控的网络数据平台,并对数据进行分析,为项目的实施提供改革方向、改进措施等.
根据上述思路,形成基于“创新工作室”的校企协同育人思维框架图,如图1所示.
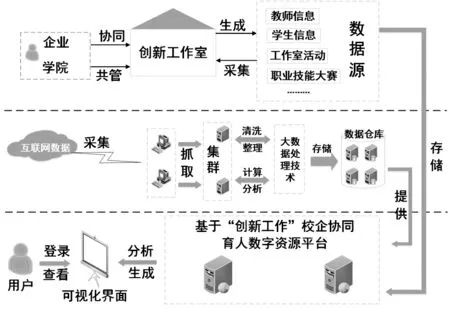
图1 基于“创新工作室”的校企协同育人思维框架图Fig.1 School-enterprise collaborative education framework based on"Innovation Studio"
4 校企协同育人平台相关技术
面向高职院校育人过程,通过数据可视化展示育人的结果、过程.开发框架采用跨平台混合应用开发,结合大数据技术应用对数据进行抓取、清洗、分析、计算等.适应不同的用户,提供全方位的服务及个性化的设置.
该平台采用Seed UI客户端交互界面,MYSQL数据存储容器,SSM+Min UI为Web服务端研发框架.
SSM 框架:Spring+Spring MVC+MyBatis即是(业务逻辑层+表现层+数据处理层)是经典的Java-EE企业级框架.[4]原理:用户通过控制器调用业务层(S)处理逻辑以完成逻辑事务处理,然后逻辑层向持久层(D)发送请求,持久层与数据库(XML)交互,并将结果返回给完成数据的CRUD 之后,业务层,业务层将处理逻辑发送到控制器,控制器调用视图(V)显示数据.
MiniUI前端框架:是快速开发Web界面的前端框架,可以创建Ajax 无刷新、B/S 快速录入数据、CRUD、Master-Detail、菜单工具栏、弹出面板、布局导航、数据验证、分页表格、树、树形表格等,可供.NET、java、php等主流编程语言配合使用.[5]
大数据技术:Hadoop分布式环境,Python语言和Map Reduce技术完成数据计算程序,Hive完成数据清洗和过滤,HBase实现数据存储.
5 校企协同育人平台设计与实现
5.1 权限配置
基于“创新工作室”的校企协同育人平台,根据校企双方的需求,共用一个平台,但用户根据职责、职务、管理等划分为企业(领导、管理者、工程师),学院(领导、教师、在校学生、往届学生).其中企业和学院的领导查看整个育人体系中学生的总体情况,工作室总体的事务量,工程师与教师的工作衔接率,并根据数据进行决策.企业管理者负责企业与学院的事务对接,工程师负责培养学生,与教师共育人才.学院教师负责工作室的日常事务管理,培养学生,对接企业日常活动等,学生(在校、往届)负责记录自己的成长数据,查看项目,参与考核,获取招聘信息.
5.2 成长轨迹
工程师记录参与项目学生的所有数据并对其进行分类,也可查看学生在校的学习情况、参与活动、竞赛获奖等情况.教师将学生在校或毕业后的数据进行记录,按活动类别、比赛项目、企业任务等多维度方面,记录学生的所有数据,通过可视化平台进行数据分析.工程师和教师都可以根据成长轨迹图进行分类专门培养,调整培养的方法.学生可以看自己整个大学的学习情况轨迹,参加活动或竞赛等分析图,调整自己的学习目标和方向.
5.3 项目中心
企业将真实项目发布于平台或引入到项目实训课程里,学生成立团队接收项目,要教师和工程师的指导下完成项目的开题报告、需求调研、框架设计、程序编写、项目测试、成果展示、结题归档,所有的步骤数据都进入平台的项目管理中心.可以查看项目的进度,上传文档,成果演示,数据统计等功能.
5.4 大数据分析
基于Hadoop分布式环境下,通过Python语言和Map Reduce完成抓取数据程序,运行抓取程序将互联网中的热门招聘信息网的数据按规定的数据结构进行数据爬取.[6]利用Hive进行创建数据仓库并对接抓取的数据,同时对数据进行清洗,通过HBase完成数据存储.再运用Echear完成图表可视化分析.
(1)抓取数据,采用爬虫技术(招聘类网站信息).
运用Python语言编写程序,采用Requests请求数据,使用BeautifulSoup 解析数据,运用xlsxwriter框架保存数据到Excel文件中.核心代码如下:
网页下载器:
#设置请求头部参数,模拟浏览器访问
header= {'User-Agent':r'系统版本,浏览器,浏览器内核','Referer':r'访问地址',
'Connection':'keep-alive'
}
网页解析器:
#提取数据
soup= BeautifulSoup(html_content,'html.parser')
all=primary_soup.find('h3',class_="name").a.text
sala=primary_soup.find('h3',class_="name").a.span.text
job=all.replace(sala,"")
job_require=primary_soup.find('p').text
输出Excel:
for i in range(1,row_num+1):
if i==1:
tag_pos='A%s'%i
tmp.write_row(tag_pos,tag_names)
else:
con_pos='A%s'%i
content=results[i-1]
tmp.write_row(con_pos,content)
调度器:
#循环处理抓取数据
for i in range(1,page_count+1):
time.sleep(random.uniform(1,5))
content = self.downloader.get_ page(base URL,i,keyword)
com_results=self.parser.parse(content)
for com in com_results:
all_coms.append(com)
(2)清洗数据,采用正则表达式过滤.
根据数据结构要求,完成“地区”和“薪水”数据清洗过滤,“地区”保留城市,去掉区域;处理“薪水”的最高和高低.核心代码如下:
清洗过滤数据:
#判断待遇是否为空,并计算最低最高待遇
if salary:
result=handle_salary(salary)
low_salary=result[0]
high_salary=result[1]
else:
low_salary=high_salary=""
正则表达式提取数据:
# 针对1万~2万/月或者10万~20万/年的情况,包含“-”符号
low_salary=re.findall(re.compile('(d*.? d+)'),salary)[0]
low_salary=float(low_salary)/12*10
low_salary=float(low_salary)*10
(3)提取和分析,构建数据仓库.
运用Python语言编写程序,利用xlrd读取execl的数据,提取和分析,并创建表;然后将生成的数据通过load到Hive表中.核心代码如下:
构建Hive数据仓库:
#输入的xls文件
book=xlrd.open_workbook(execl的文件路径)
in_file=book.sheets()[0]
title_List=in_file.row_values(0)
title_str=','.join(title_List[i]for i in range(len(title_List)))
title=''.join(lazy_pinyin(title_str))
table_sql=str('hive-e'+'"'+title+'"')
(4)将数据存入HBase数据库.
基于Hadoop分布式环境下,运用shell命令完成操作,将Hive表的数据生成hfile,再通过bulkload导入到hbase数据库.操作步骤如下:
第一步:启动Hive,导入需要的jar包
add jar/lib/hive-hbase-handler-2.3.3.
jar;
add jar/lib/hbase-protocol-1.1.1.jar;
add jar/lib/hbase-common-1.1.1.jar;
add jar/lib/hbase-client-1.1.1.jar;
add jar/lib/hbase-server-1.1.1.jar;
第二步:生成hfile,并存储在HDFS目录
STORED AS
INPUTFORMAT'org.apache.hadoop.mapred.TextInput Format'
OUTPUTFORMAT'org.apache.hadoop.
hive.hbase.Hive HFileOutput Format'
TBLPROPERTIES('hfile.family.path'='/
user/hive-hbase/jobs');
第三步:创建对应的HBase表
create'hive_load','jobs'
第四步:执行bulkhead,将数据导入到HBase中
bin/hbase org.apache.hadoop.hbase.mapreduce.LoadIncremental HFiles hdfs://maste:port/user/hive-hbase/jobs/hive_load
(5)可视化数据显示.
根据数据分析需求,按数据结构,采用java+ECharts+Ajax读取数据并绘制可视化图表.效果如图2、3所示.
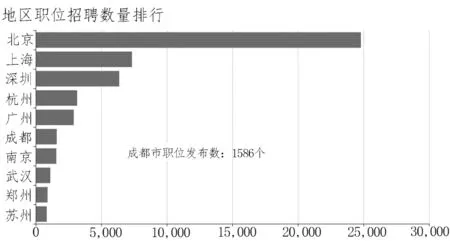
图2 地区职位招聘数量排行Fig.2 Top Jobs by Region
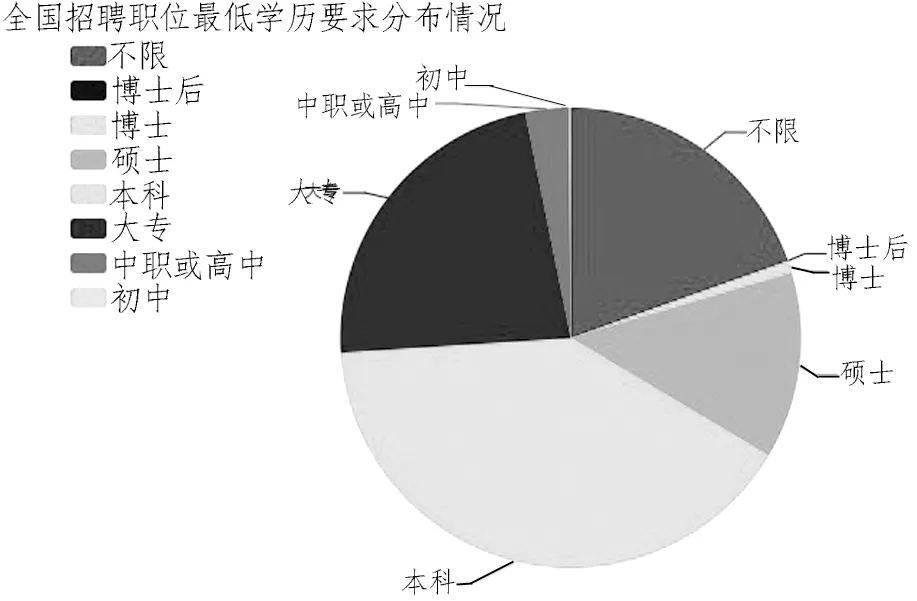
图3 全国招聘职位最低学历要求分布情况Fig.3 Distribution of minimum education requirements for national recruitment positions
5.5 智能推荐
采用“协同过滤算法”完成企业岗位的推荐,推荐过程对学生的各类数据,企业岗位、岗位数量、岗位要求行进行训练,在匹配计算过程中要建立学生到岗位的倒排序,在推荐数据过程中先确定学生对被推荐岗位的匹配程度值,最终推荐匹配度排位最前的岗位.[7]具体的流程如图4所示.
根据“协同过滤算法”数学模型,求解出学生对企业岗位列表中的每个岗位匹配度的值.数学模型如下:
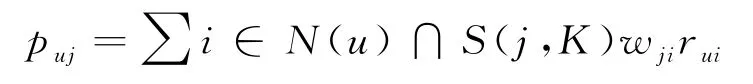
模型中N(u)是一个数据样本集合,代表学生匹配的岗位,S(j,K)是数量为K 的岗位且与j匹配度较高,w ji为j与i的匹配程度值,r ui为u对i的合适值.模型计算出的值,与学生匹配岗位越接近,则该岗位越有可能最合适该学生.
运用Python语言编写程序,实现JobsCF 推荐算法,完成数学模型的训练.代码如下:
#循环完成最优推荐值
for i,wji in sorted(W[user].items(),key=itemgetter(1),reverse= True)[0:K]:
#循环训练
for u,rui in train[i].items():
if u in interacted_items:continue
rank[u]+= wji*rui
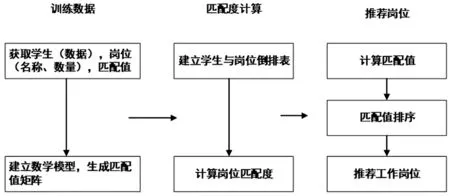
图4 基于“协同过滤算法”工作岗位推荐流程图Fig.4 Flow chart of job recommendation based on"collaborative filtering algorithm"
6 结语
随着大数据、云计算融入平台,人工智能AI的快速成长,数据的可视更加直观,功能也更加人性化、智能化、精准化.本平台基于“创新工作室”平台,融合大数据和流行框架SSM,构建校企协同育人数字资源平台,解决校企合作数据存储,育人过程记录,智能推荐岗位,人才选拔和录用等问题.同时,双方可以根据数据分析做改革和决策,共享、共建、共管理人才培养的资源.校企协同育人数字资源平台目前还处于测试阶段,功能各方面还有待进一步完善.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
新班主任(2022年4期)2022-04-27
科学大众(2020年23期)2021-01-18
活力(2019年15期)2019-09-25
上海包装(2019年2期)2019-05-20
汽车观察(2019年2期)2019-03-15
消费导刊(2017年20期)2018-01-03
新课程研究(2016年1期)2016-12-01
中国卫生(2016年5期)2016-11-12
中国教育技术装备(2015年6期)2015-03-01
