
基于对比注意力机制的跨语言句子摘要系统
2020-05-20 10:22:42殷明明史小静俞鸿飞段湘煜
计算机工程 2020年5期
殷明明,史小静,俞鸿飞,段湘煜
(苏州大学 自然语言处理实验室,江苏 苏州 215006)
0 概述
句子摘要是将源端句子中的主要思想进行抽取和概况,并以摘要短语的形式呈现。句子摘要系统通过快速浏览句子以获取其中的主要信息,再对该信息进行重写生成相对应的摘要短语。在已有研究中,多数学者主要是针对单语进行句子摘要[1-2],即源端句子和目标端摘要短语属于同种语言,但基于单语的形式严重阻碍了人们快速获取不同语言文本中所包含的主要信息。与基于单语的句子摘要任务不同,现实中跨语言的句子摘要缺少大量的平行语料以供使用,属于零样本学习问题。在大规模单语句子摘要系统的平行语料和神经机器翻译系统的跨语言平行语料基础上,可将两个系统相结合以解决该零样本学习问题。
由于单语的句子摘要系统存在大规模的平行语料,因此采用神经网络构建序列到序列(seq2seq)的模型。在平行语料中,源端序列是长句子文本,目标端是与之对应的摘要短语。该系统利用编码器将源端序列编码成固定维度的向量空间,再通过解码器解码出具体的摘要短语。神经网络的广泛使用使得神经机器的翻译性能有了显著提升[3-4]。目前,主流的神经机器翻译方法[5-6]主要包括基于循环神经网络(Recurrent Neural Network,RNN)的神经机器翻译方法[7-8]、基于卷积神经网络(Convolution Neural Network,CNN)的神经机器翻译方法[9]和基于完全注意力机制的神经机器翻译方法(Transformer)[7],其中Transformer在各类数据集上的表现上相比于其他方法具有明显优势。
早期学者对于跨语言摘要任务的研究主要利用抽取和压缩的方法。通过从原文档中抽取关键的句子进行翻译,再采用压缩方法删除翻译译文中最不相关的信息。单纯抽取和压缩得到的摘要短语不能安全包含源句中的主要含义。在近期研究中,文献[8]提出利用神经网络构建序列到序列的跨语言句子摘要系统,将单语平行语料中目标端的摘要短语通过神经机器翻译系统翻译成另外一种语言的摘要短语,与源端长句共同构建跨语言的伪平行语料对。在此基础上借鉴神经机器翻译中的“老师-学生”框架[6],将单语句子生成式摘要模型作为“老师”,跨语言句子生成式摘要模型作为“学生”。
本文借鉴回译思想[10-11],将单语句子摘要平行语料中的源端通过神经机器翻译系统翻译成另外一种语言,与句子摘要平行语料中真实目标端的摘要短语构成跨语言的伪平行语料。另外,句子摘要将从源端长句中抽取出的主要信息以摘要短语的形式进行呈现,然而,源端和目标端句子长度存在较大差异。在序列到序列模型中传统注意力机制主要是使目标端获取与源端最相关的信息,但在句子摘要生成过程中,由于较短目标端摘要短语需从较长的源端获取最相关的信息,因此源端和目标端句子长度的不匹配使得传统注意力机制不再适用于此类情况。为解决该问题,本文提出对比注意力机制,通过该机制使目标端可从源端中获取最不相关的信息。
1 相关工作
1.1 单语的句子摘要
针对单语的句子摘要问题,学者提出一些基于统计模型和神经网络的方法。由于基于统计模型的方法需构建大规模单语句子摘要的平行语料,因此基于神经网络的方法逐渐成为主流方式。文献[12]采用带有注意力机制的循环神经网络构建序列到序列的句子摘要系统,学者们在此基础上进行了深入研究,例如文献[13]融入丰富的语言学信息以扩大词典,文献[14]增强了摘要主题,文献[15]对编码器添加选择门机制。在文档级别的摘要任务中,文献[16]将原始文本转化为相应的抽象语义表示图,再通过语义字典过滤抽象语义表示图中的冗余信息。文献[17]提出融合Doc2Vec模型、K-means算法和TextRank算法的自动提取摘要系统。
1.2 跨语言的句子摘要
早期学者未对跨语言句子摘要进行较多研究,而是主要关注于跨语言文档级别的摘要研究。文献[18]对原文档中句子进行打分,选择最优句子进行翻译形成摘要,并且基于抽取式摘要模型设计两个图,图中包含双语的信息。文献[19]利用翻译和解析信息引入双语概念和特征,生成跨语言多文档摘要。文献[8]利用“老师-学生”框架完成跨语言句子摘要模型的训练过程,而本文摒弃了复杂的“老师-学生”框架,通过对比注意力机制来弥补传统注意力机制的不足,从而加强跨语言的句子摘要能力。
2 跨语言句子摘要系统
2.1 基准模型
在实验中,本文选择标准Transformer模型作为单语句子摘要模型和神经机器翻译模型。Transformer与循环神经网络及卷积神经网络不同,其完全基于注意力机制实现。在该模型中包含编码器-解码器结构,编码器将源端序列信息编码成固定维度隐藏层向量,解码器从源端隐藏层向量中解码出具体的目标端序列,编码器与解码器之间通过注意力机制实现连接。
Transformer中主要采用缩放的点乘注意力机制,具体公式如下:
(1)
其中,Q、K、V分别为问题向量、关键字向量和值向量,dk为向量K的维度,激活函数softmax返回在向量V上的权重概率分布,函数Attention(Q,K,V)生成与当前时刻最相关的上下文信息。
在整个Transformer模型中,缩放的点乘注意力机制主要应用如下:
1)自注意力机制(Self-Attention),在编码器端和解码器端都采用自注意力机制。在编码器端,向量Q是源端序列中当前位置的隐藏层向量,而向量K和向量V为整个源端序列中所有位置隐藏层向量组成的向量矩阵。与编码器端不同,在解码器端的序列是从左向右依次解码,对于当前位置而言后面位置的信息不可见。因此,在解码器端对于向量矩阵K和向量矩阵V当前位置往后的信息需要通过掩码矩阵进行掩码,而向量Q与编码器端相同,为目标端序列当前位置的隐藏层向量。
2)编码器-解码器注意力机制(Encoder-Decoder Attention),与传统序列到序列模型中的注意力机制类似,通过目标端当前位置的信息获取源端序列中最相关的信息。向量Q为解码器端当前位置的隐藏层向量,向量K和向量V为编码器中源端序列中所有位置隐藏层向量组成的向量矩阵。
另外,在上述两种注意力机制中都采用多头的注意力机制。将向量Q、向量K和向量V切分成更小维度的向量,通过不同视角获取多样的注意力信息。切分的维度等于最初向量维度的1/h,其中h为切分的头数目。具体地,将向量Q、向量K和向量V维度设置为512维,分为8个头,即每个向量被分为8份,每一份为64维。在此基础上将每一个头的向量通过式(1)计算注意力信息,最终将各头的注意力信息进行拼接再次映射成512维,具体公式如下:
MultiHead=Concat(head1,head2,…,headh)WO
(2)
(3)
2.2 管道方法
单语句子摘要系统是一个端到端的实现方式,即给定源端输入后通过模型得到具体的摘要短语输出,但是对于跨语言句子摘要任务而言不存在类似的端到端系统。因此,本文通过两步方式实现跨语言句子摘要。首先预训练一个单语摘要系统和一个翻译系统,然后将两个系统结合生成最终的跨语言摘要系统。具体实现过程有如下两种方式:
1)先摘要-后翻译,记作Pipeline-ST。给定具体语言的源端句子,先通过单语摘要系统生成同语言的摘要短语,再使用翻译系统将生成的摘要短语翻译成另一种语言的摘要短语。
2)先翻译-后摘要,记作Pipeline-TS。与上述方法相反,先将具体语言的源端句子使用翻译系统翻译成另一种语言,再对该句子使用单语句子摘要系统生成最终的摘要短语。
2.3 回译方法
由于大规模的单语句子摘要平行语料的存在,使得基于神经网络的单语摘要系统得到广泛应用,但是跨语言句子摘要不存在任何相关的平行语料,因此在实验过程中本文借鉴机器翻译中的回译方法,通过此方法构建伪语料以供使用。
在机器翻译领域,训练模型需要使用大量的平行语料,通常构建平行语料需要花费巨大的人力物力,但是现实中存在大量的单语语料,因此可通过回译方法将单语语料翻译成与平行语料中源端相同语言的文本,构成具备真实目标端的伪平行语料,然后使用该伪语料对原有的平行语料进行数据扩充。
本文采用回译思想,借用机器翻译系统将单语句子摘要的平行语料中的源端翻译成另一种语言,构成具有虚假源端和真实目标端的跨语言句子摘要的伪平行语料。与文献[8]方法不同,本文将单语句子摘要平行语料中的目标端通过机器翻译系统生成另一种语言文本,形成由真实源端和虚假目标端共同构成的跨语言句子摘要的伪平行语料。
本文实现了从中文句子到英文摘要短语的过程,使用预训练的英文到中文的神经机器翻译系统将英文单语句子摘要语料中的源端翻译成中文文本,再与该数据中英文目标端构成跨语言句子摘要的伪平行语料,如图1所示。其中,实线框表示真实数据,虚线框表示伪数据,实线双箭头表示真实平行语料,虚线双箭头表示伪平行语料,NMT表示使用机器翻译模型进行翻译。

图1 回译过程
2.4 对比注意力机制
与机器翻译不同,句子摘要任务中需保留源端序列中的主要信息,并过滤次要信息。文献[15]在编码器中添加选择门机制,通过选择门机制过滤源端序列中的次要信息。本文在Transformer基准系统上添加对比注意力机制来获取源端序列中不重要的信息。
本文将序列到序列结构中的编码器-解码器注意力机制定义为传统注意力机制,用来获取源端序列中的主要信息。如图2所示,标准Transformer结构包含编码器、解码器以及传统编码器-解码器注意力机制,对比注意力机制包含注意力转换(Attention Transfer)、反向注意力(Opponent Attention)和反向概率分布(Opponent Probability)。除此之外,Transformer模型结构中通常采用的是多层叠加结构,前一层的输出作为下一层的输入,其中Nx表示N层相同结构的叠加,但在反向注意力结构中只采用一层结构。本文将αc定义为传统注意力机制的注意力权重,具体公式如下:
(4)


图2 对比注意力机制的模型结构
将αo定义为对比注意力机制的注意力权重,对比注意力机制通过传统注意力机制转换而来,具体公式如下:
αo=softmax(α′c)
(5)
Attentiono(Q,K,V)=αoVL,h
(6)
其中,α′c是将传统注意力权重αc中最大的权重值重新赋值为-inf,使其经过激活函数softmax后使αo对应的权重变为0。将传统注意力机制转换为对比注意力机制的主要目的是将传统注意力机制中与源端最相关信息在对比注意力机制中变为最不相关信息。VL,h和KL,h是相同的向量矩阵,为编码器端最后一层的第h个头对应的源端所有位置的隐藏层向量组成的向量矩阵。在此方法中,传统注意力机制获取源端与目标端最相关的信息,而对比注意力机制则获取目标端与源端序列中最不相关的信息。
具体地,在Transformer基准系统中主要包含6层相同的子结构,并且每一层包含8个头的传统注意力机制。本文通过分析跨语言摘要伪平行语料在基准系统上每一层每一个头的传统注意力对齐情况,发现第5层的第7个头的传统注意力对齐效果最佳。因此,在实验过程中将第5层的第7个头的传统注意力机制转换为对比注意力机制,即将所对应的注意力权重分布中最大的权重重新赋值为-inf。除此之外,Transformer基准系统是6层子结构,但是在对比注意力机制中仅有一层结构。
2.5 训练与解码
Transformer结构中除了注意力机制还需要经过层正则化(Layer Normalization)、残差连接(Residual Connection)、前馈网络(Feed Forward)和激活函数softmax,最终得到候选词的概率分布。具体地,给定一对平行语料,其中,源端X={x1,x2,…,xn},目标端Y={y1,y2,…,ym}。在训练过程中,通过激励传统注意力机制获取源端最相关信息并生成目标端候选词的最大化概率Pc(yi|y[1:(i-1)],X)。
在传统注意力机制中,通过激活函数softmax激励模型获取源端序列中的最相关信息,但是在对比注意力机制中需惩罚最相关信息,从而获得不相关信息。因此,在对比注意力机制中将传统注意力机制中的激活函数softmax替换成softmin,具体公式如下:
z1=LayerNorm(Attentiono)
(7)
z2=FeedForward(z1)
(8)
z3=LayerNorm(z1+z2)
(9)
Po(yi|y[1:(i-1)],X)=softmin(Wz3)
(10)
其中,W是模型训练参数。激活函数softmin和训练目标分别如下:
(11)
L=loga(Pc(yi|y[1:(i-1)]))+
λloga(Po(yi|y[1:(i-1)]))
(12)
其中,λ为平衡因子。在解码时,模型通过束搜索寻找最大化函数L。
3 实验结果与分析
本文实现了一个中文句子到英文摘要短语的系统。训练集主要使用单语句子摘要的平行语料和英中机器翻译的平行语料。由于不存在跨语言句子摘要的测试集,将单语句子摘要的平行语料中的源端英文句子通过人工翻译为中文句子,构成标准的{中文句子,英文摘要短语}测试集。
3.1 数据集
单语句子摘要的平行语料使用的是带有注释的Gigaword[20],对该数据的处理方式与文献[12]一致,将每一篇文章的第一句作为源端句子与该篇文章的标题构成平行语料对。经处理后该数据集中共包含约380万对的训练集,8 000对验证集和1 951对测试集。另外,也使用DUC-2004[21]作为测试集,该数据中包含500篇文档,每一篇文档对应4种人工生成的摘要。
本文还使用英文到中文的机器翻译系统。训练该系统使用的英中平行语料是从LDC中抽取的125万句英中平行语句对,其中包括LDC2002E18、LDC2003E07、LDC2003E14、LDC2004T07、LDC2004T08和LDC2005T06中的议会议事录部分。选择NISTMT02、NISTMT03、NISTMT04、NISTMT05、NISTMT08作为测试集,NISTMT06作为验证集。
在实验过程中,从Gigaword数据的验证集中随机抽取2 000个句对,并将该句对中的源端使用人工翻译成对应的中文作为跨语言句子摘要系统的验证集。同时,将Gigaword数据集中的测试集和DUC-2004数据中的源端翻译成对应中文,作为本文跨语言句子摘要任务的标准测试集。除此之外,为实验公平起见,参照文献[8]方法使用大规模的中文短文本摘要平行语料LCSTS[22],该语料主要从新浪微博上收集整理,其中,训练集包含约240万对平行语料,测试集包含725对平行语料。
3.2 实验参数
本文英中翻译系统和句子摘要系统中都使用Transformer作为基本结构,具体代码实现基于Fairseq。该结构中编码器和解码器都设为6层,其中多头注意力机制使用8个头,词向量及隐藏层维度都设置为512维,Adam优化器,初始学习率为0.000 5,β1=0.9,β2=0.99,ε=10-9,其他参数与文献[7]相同。在单语句子摘要系统中,共享编码器和解码器中的词向量。解码时使用束搜索方法,束搜索宽度设置为12,最大句长设置为50。
在实验过程中,采用BPE[23]技术处理语料中的低频词问题,BPE大小设置为32 000。在单语句子摘要任务中源端和目标端使用联合BPE的方式。另外,对于人工翻译得到的中文文本,首先使用分词工具Jieba进行分词,然后使用BPE进行处理。
3.3 评测标准
本文使用ROUGE[24]作为评测脚本。对于Gigaword测试集,测试其全长度的F值得分,其中包括ROUGE-1(R-1)、ROUGE-2(R-2)和ROUGE-L(R-L)。在DUC-2004测试集上,文献[8]提出使用全长度的F值作为评测标准。因为召回率得分与生成序列的长度相关,所以为公平起见使用全长度的F值得分作为评测标准,本文也采用该评测方法。
3.4 实验结果
3.4.1 超参数确定
在实验过程中的主要超参数是式(12)中的平衡因子λ,其用于平衡传统注意力机制和对比注意力机制,如果λ越大,则系统生成候选词的概率分布越偏向于对比注意力机制。本文分别设置λ为0.2、0.4和0.6,根据其对应模型在验证集上的具体表现选择最终的λ。如表1所示,当λ取0.4时在验证集上的ROUGE得分最高,因此本文系统中λ设定为0.4。

表1 不同平衡因子λ时的ROUGE得分
3.4.2 对比注意力机制中的K值确定
在对比注意力机制中,将传统注意力的权重分布中最大的K个值重新赋值为-inf,使其在对比注意集中经过再次softmax后所对应的权重值变为0,即在传统注意力权重中最相关的信息在对比注意力机制中变为次要信息。在此基础上,分析对比注意力机制选取不同K值在验证集上的ROUGE得分。如表2所示,当K值取1时对比注意力机制在验证集上表现最优。因此,在本文实验中将K值设置为1。
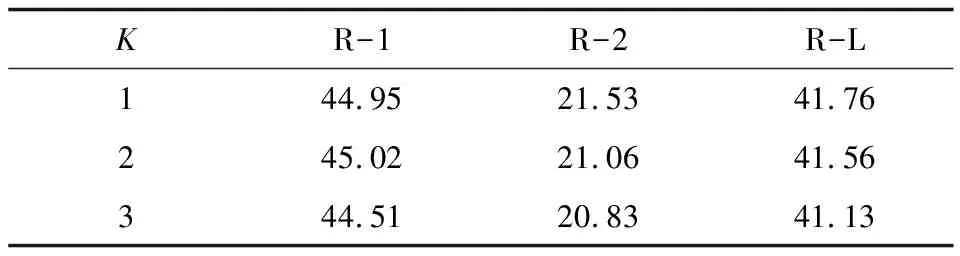
表2 不同K值时的ROUGE得分
3.4.3 单语句子摘要系统实验结果
Transformer模型在神经机器翻译领域取得显著成效,但是其在摘要任务中尚未有深入的研究。本文使用Transformer作为句子摘要基准系统,实验结果表明该系统在单语句子摘要测试集上性能表现较好。
如表3所示,ABS[12]和ABS+[12]使用注意力机制的循环神经网络构建单语句子摘要;SEASS[15]通过在编码端增加选择门机制,对源端信息进行选择性编码;Actor-Critic[14]在序列到序列的模型基础上引入增强学习方法;FactAware[25]利用开放式信息抽取和依存关系来描述源端文本中的信息。本文在Transformer结构的基础上,对训练集采用BPE预处理,定义为Transformer-BPE,其在Gigaword和DUC-2004测试集上均达到较高的水平,并且在跨语言句子摘要中采用相同的处理方法。
表3 单语句子摘要系统的ROUGE得分
Table 3 ROUGE scores of monolingual sentence summary systems

系统GigawordDUC-2004R-1R-2R-LR-1R-2R-LABS[12]29.6011.3026.4026.557.0622.05ABS+[12]29.8011.9027.0028.188.4923.81SEASS[15]36.2017.5033.6029.209.6025.50Actor-Critic[14]36.1017.9034.30———FactAware[25]37.3017.7034.20———Transformer37.1018.2034.4030.6010.5026.60Transformer-BPE38.1019.1035.2031.2010.7027.10
3.4.4 机器翻译系统实验结果
在Pseudo-Source方法中,本文将英文的源端通过机器翻译系统生成对应的中文译文,因此需提前训练一个英中的翻译系统。使用Transformer作为翻译系统,训练集是约125万的LDC中英数据集,测试集分别使用NIST02、NIST03、NIST04、NIST05和NIST08,验证集是NIST06并使用multi-bleu.perl作为评测脚本。
如表4所示,本文分别呈现了中英(Our Transformer Ch2En)和英中(Our Transformer En2Ch)两个方向的翻译得分。在中英翻译系统中,每个NIST测试集包含4个人工生成的英文参考集。在英中翻译系统中,将中英的测试集交换语向,同时每个NIST测试集分别测试4个参考集的得分,最后4个参考集的平均得分作为该NIST测试集的最终得分。将本文翻译系统与Robust Translation[26]系统做对比,该系统是中英翻译系统,采用与本文相同的训练集及模型结构,在NIST02测试集上,本文Our Transformer Ch2En系统的得分低于该系统,但在平均得分上本文系统更具优势。
表4 中英和英中翻译系统在NIST测试集上的BLEU得分
Table 4 BLEU scores of Chinese-English and English-Chinese translation system on the NIST testing set
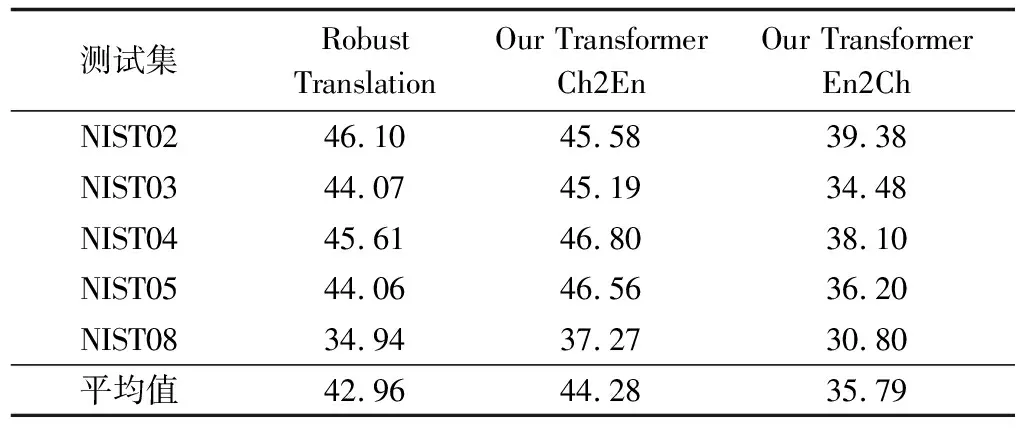
测试集RobustTranslationOurTransformerCh2EnOurTransformerEn2ChNIST0246.1045.5839.38NIST0344.0745.1934.48NIST0445.6146.8038.10NIST0544.0646.5636.20NIST0834.9437.2730.80平均值42.9644.2835.79
3.4.5 跨语言句子摘要系统实验结果
跨语言句子摘要系统得分如表5所示,其中前两个系统基于管道方法,其作为跨语言句子摘要的基准系统。Pseudo-Target[8]实现了英文句子到中文摘要的过程,使用的摘要系统是基于LSTM的模型结构,未使用BPE技术处理低频词。为实验公平起见,在Transformer-BPE的基础上进行Pseudo-Target从中文句子到英文摘要的实现。Pseudo-Target实验结果差于管道方法,主要原因为:1)Pseudo-Target中构建了目标端的伪语料,使模型训练过程中不能得到真实生成词的概率分布P(yi|y[1:(i-1)],X);2)在重现过程中,使用中文摘要语料LCSTS,该语料与Gigaword和DUC-2004具有一定的差异性。
表5 跨语言句子摘要系统的ROUGE得分
Table 5 ROUGE scores of cross-lingual sentence summary systems

系统GigawordDUC-2004R-1R-2R-LR-1R-2R-LPipeline-TS25.809.7023.6023.676.7820.92Pipeline-ST22.007.0020.9020.885.3318.32Pseudo-Target[8]21.506.6019.6019.334.2916.97Pseudo-Source27.9010.9025.6024.376.6421.39Contrastive-Attention29.4011.3027.1024.576.7121.72
本文提出的基于序列到序列的跨语言句子摘要系统的具体实验结果如表5中最后两行所示。Pseudo-Source通过回译将Gigaword语料中源端通过机器翻译系统生成对应的中文文本,与该语料中目标端构成了跨语言句子摘要的伪平行语料,用于训练序列到序列模型。该方法的BLEU得分相对于两种基准系统有显著的提升,基准系统主要是通过翻译系统和摘要系统得到最终结果,两种系统之间存在一定的差异性,从而导致摘要水平明显低于序列到序列模型。
在Contrastive-Attention方法中,目标端通过传统注意力机制获取源端与之最相关的信息,同时通过对比注意力机制获取源端最不相关的信息,联合两者进行训练。实验结果表明,Contrastive-Attention相对于Pseudo-Source有极大的性能提升,达到基于单语句子摘要的平行语料[12]效果。
4 跨语言句子摘要实例
下文列举了不同句子摘要系统生成的跨语言句子摘要实例如例1、例2所示,将本文跨语言系统生成的例句优于基于管道方法的单语句子摘要系统的结果部分进行加粗。通过例句可以看出本文系统生成的摘要短语明显优于基于管道方法的单语句子摘要系统,并且短语更加流畅,更加符合人类语言的表述方式。
例1
Ch-Sentence:意大利 左翼 反对派 在 # 月 选举 失败 后 , 希望 利用 反对 削减 教育 开支 的 抗议 活动 ,重新 获得 反对 总理 西尔 维奥 - 贝卢斯科尼 政府 的 主动权 。
En-Sentence:italy’s leftwing opposition,bruised by its election defeat in april,is hoping to take advantage of protests against education spending cuts to regain the initiative against the government of prime minister silvioberlusconi.
Reference:italian opposition seeks to UNK on education protests.
Pipline-TS:italy’s left party hopes to gain initiative of government.
Pipline-ST:italian left - wing opposition hopes to regain the government ’s initiative.
Pseudo-Target:italian left wing calls foroppositiontobudgetcuts.
Pseudo-Source:italy’s left seeks to rally opposition to education cuts.
Contrastive-Attention:italianoppositiontoprotestseducationcuts.
例2
Ch-Sentence:周一 早间 交易 中 , 兰特 对 美元 的 汇率 略有 走软 , 开盘 于 #.#### / ## 对 美元 的 比价 是 ####年 ## 月 ## 日 收盘 时 的 #.#### / ##% 。
En-Sentence:the rand was slightly weaker against the dollar in early trade here monday,opening at #.#### / ## to the greenback compared to its close friday of #.#### / ##.
Reference:rand slightly weaker against dollar in early trade.
Pipline-TS:foreign exchange rates in malaysia.
Pipline-ST:randt’s exchange rate against us dollar slightly soft.
Pseudo-Target:foreign exchange rates in hongkong.
Pseudo-Source:yuanweakensagainstdollarinearlytrading.
Contrastive-Attention:randweakeragainstdollarinearlytrading.
5 结束语
本文设计一种序列到序列的跨语言句子摘要系统,通过回译方法构建伪平行语料,解决跨语言句子摘要缺少平行语料的问题,并引入对比的注意力机制捕获源端与目标端中的不相关信息。实验结果表明,该系统相比基于管道方法的单语句子摘要系统整体性能有了较大提升。后续将通过无监督学习的方式构建序列到序列的句子摘要模型,进一步提高跨语言的句子摘要质量。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
思维与智慧·上半月(2022年4期)2022-04-08 21:24:29
小哥白尼(神奇星球)(2021年4期)2021-07-22 03:17:22
中文信息学报(2019年8期)2019-09-05 12:33:36
数码世界(2019年4期)2019-05-10 09:52:54
海外华文教育(2016年1期)2017-01-20 08:21:58
科技视界(2016年22期)2016-10-18 15:53:02
汽车观察(2016年3期)2016-02-28 13:16:36
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
