
社交网络用户发布模式和兴趣预测研究
2020-05-15 08:11崔晓晖
计算机工程与应用 2020年9期
胡 璨,崔晓晖
武汉大学 国家网络安全学院,武汉430072
1 引言
近年来,社交网络服务(SNS)在日常生活中的应用大大增加,已经成为用户分享想法的主要平台,使得人们可以跨越政治、经济和地理边界进行联系。社交网络服务允许用户创建公共个人资料,并为用户提供表达意见,分享内容和上传照片或视频的空间,其便利性吸引了数十亿用户。根据2018 年6 月更新的前20 个有价值的Facebook 统计数据[1],每月活跃的Facebook 用户超过22亿,每天上传大约3亿个帖子。
随着社交媒体的日益普及,为在线社交网络的增长提供了在更广泛的背景下分析用户文本的机会。在社交网络中,用户对各种主题感兴趣,并且通常具有不同的情感倾向和发布行为。社交网络用户的行为通常由他们的兴趣引发。例如,对政治感兴趣的用户经常分享很多新闻并发表他们的批评意见。更好地理解用户发布行为已成为许多个性化和信息过滤应用程序的关键。目前对社交网络用户发布行为的研究主要对基于帖子特征和发帖的动机来对用户类型进行分类。然而,现有研究简单地假设每个用户具有唯一的用户类型,由于存在不同的情绪模式和用户意图,这在许多社交网络的应用场景中并不准确。例如,一些用户可能具有混合的发布模式,而另一些用户则具有一致的发布行为模式。
为了解决这个问题,本文提出了一种全新的基于离散元组的LDA(Latent Dirichlet Allocation)模型来表征社交网络用户的发布行为,从而将用户的发布行为表示为发布模式的概率分布,而不是单一的类别。作为发布模式分布的应用,将发布模式的分布用于用户兴趣预测。
本文的贡献可归纳为如下两点:
第一,提出基于LDA 的社交网络用户发布模式模型,从而表征用户的发布模式。以这种方式,一个用户的发布活动被表示为发布模式的概率分布。
第二,验证将发布模式作为特征可提高用户兴趣的准确率。整合用户发布模式分布、用户资料和用户帖子类型特征,并与从用户喜欢页面中提取的语义特征相结合,构建兴趣预测模型。
在发布模式的实验中,本文选取最佳LDA 模型并确定了八种发布模式:(1)中立客观短文本;(2)中立非主观长文本;(3)积极主观中长文本;(4)中立客观长文本;(5)积极偏主观中长文本;(6)积极偏客观中短文本;(7)积极偏主观中短文本;(8)中性偏客观中长文本。
在兴趣预测实验中,分别使用发布模式分布特征、用户资料特征、用户帖子类型特征和用户喜欢页面中提取的语义特征。结果表明,使用所有特征比不使用发布模式分布特征时,预测的准确率更高。这表明发布模式分布特征尽管独立于兴趣或主题的语义,但可以有效提高预测的准确率。
2 相关工作
社交网络用户分析不是一个新的研究课题,目前已有大量关于分析用户行为和个人信息的研究。社交网络用户分类是一个有监督的机器学习问题,即需要首先确定用户的类别范围,然后通过训练分类模型预测用户的类别[2]。一些研究基于用户的行为和使用社交网络的动机来调查用户类型。例如,Brandtzaeg 等[3]提出了社交网络的用户类型,它识别并描述了人们使用社交网络的各种方式。他们分析了挪威四个主要社交网络中5 233 名受访者的调查数据,并确定了五种不同的用户类型:(1)散发性,(2)潜伏者,(3)社交者,(4)辩论者,(5)活跃者。Dewi[4]提出了一个两层的聚类模型并得到五种不同的用户类型。一些社交网络用户分类方法基于文本内容信息,采用成熟的文本分类模型进行用户分类。例如,Zubiaga[5]等通过采集用户的社会化标签数据,并应用支持向量机分类模型进行分类。此外,一些方法融合社交网络用户文本内容以及关系网络信息进行分类,如Mlcmlw 方法[6]集体分类方法。现有研究简单地假设每个用户具有唯一的用户类型。
检测社交网络中用户的情绪状态也引起了国内外学者的注意。一些研究调查用户情绪变化的时序模式[7-8]。例如,Gutierrez等[9]表明Twitter用户至少在30天内始终保持在一个情绪概况集群中。但是,有必要进一步研究典型和稳定的情绪集群。
针对用户兴趣分析,大多数研究侧重于通过使用从用户的日常帖子中提取的语言特征来预测社交网络用户的兴趣。研究表明,社交网络中50%左右的用户选择了隐藏他们的用户信息,70%的用户选择了隐藏他们的兴趣爱好[10]。丁宇新等[11]通过构造主题模型与语言模型相结合的双层模型,利用朋友关系与组织关系解决微博的个性化搜索问题。何炎祥等[12]提出一种针对社交网络用户生成内容和用户关注信息的用户偏好挖掘方法。黄泳航等[13]使用社交网络的拓扑结构信息挖掘社交用户的朋友圈社区去预测用户的偏好。Kim 等[14]利用Facebook中的喜欢数量和主题内容来预测用户兴趣。Su等[15]表明,对不同利益群体感兴趣的用户通常会有不同的情绪倾向和发布活动。因此,表征这些发布活动特征将改善用户兴趣的预测模型。
3 发布模式和兴趣预测模型
针对传统用户发布行为的研究在用户分类方面的不足,本文提出一种全新的方法,该方法包括发布模式模型和兴趣预测模型,方法的整体框架如图1所示。

图1 方法整体框架
整个方法由三个子过程来处理完成,其中数据收集模块从Facebook 中采集用户和帖子并进行情感分析。发布模式模块生成帖子的离散元组,并在离散元组上构建LDA 模型,从而获得潜在的发布模式。本文中,发布模式对应LDA 模型中的主题,指的是用户帖子集合中同时出现的离散元组的重复模式。经过非监督学习,LDA 模型得到表征用户的发布模式分布的参数。兴趣预测模块整合用户的发布模式分布、用户个人资料和帖子类型,并与从用户喜欢页面中提取的语义特征相结合,构建兴趣预测模型。
3.1 发布模式模型
3.1.1 离散元组
离散化是将连续变量转换为离散变量的过程,多元转换是数据离散化的方法之一。多元转换中,如果要分成n 类,就要给出n+1个阀值组成的数组,任意一个数都可以被放在某两个阀值的区间内。
本文利用多元转换的方法构造离散元组,具体操作主要分为两步。第一步,对每个帖子计算极性值、主观性值和字数,其中极性值和主观性值由TextBlob计算得到,字数即帖子中单词的数量;第二步,通过多元转换分别对极性值、主观性值和字数进行离散化,得到离散变量和,并构造三元组
根据多元转换方式的不同,可以得到不同类型的离散元组。例如,将极性值分为5 个区间,主观性值分为3个区间,字数分为5 个区间,可得元组类型1,如表1 所示。类似地,通过更精细的离散化,将三个维度分别分为9、5、9 个区间,得到元组类型2;将三个维度分别分为13、9、13个区间,得到元组类型3。
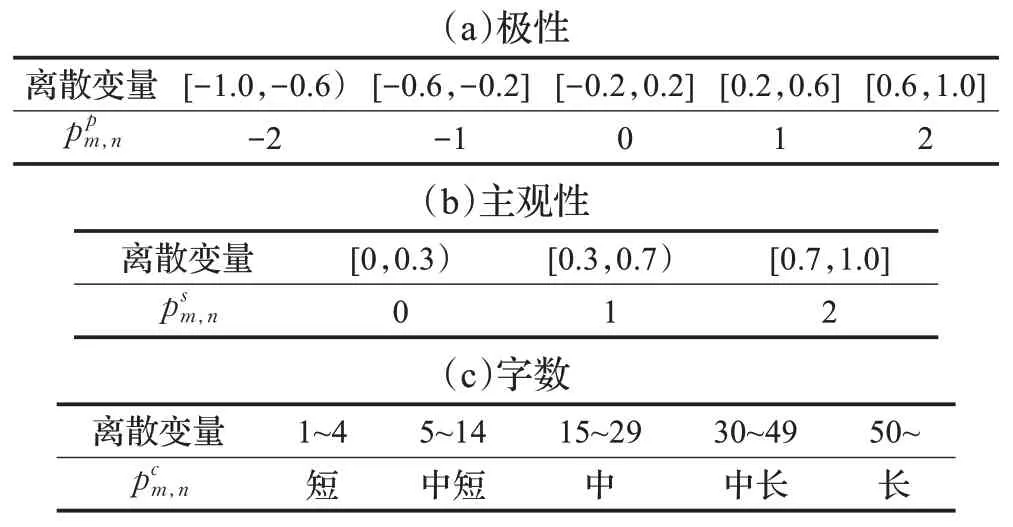
表1 离散元组类型1的多元转换方式
3.1.2 基于离散元组的LDA模型
LDA 是一种非监督机器学习技术,可以用来识别大规模文档集或语料库中潜藏的主题信息。在LDA中,每个文档可以被视为各种主题的混合。
基于传统的LDA 模型,本文提出一种基于离散元组的LDA 模型,模型的基本思想是:将文档对应于用户,将主题对应于用户的发布模式,将词对应于表示帖子的元组。模型中,每个用户可以被视为各种发布模式的混合,经过吉布斯采样(Gibbs Sampling),得到每个用户的发布模式的分布以及每个发布模式的帖子元组的分布。模型的框架与传统的基于词的LDA 模型一致,如图2所示。
模型基于以下假设:(1)帖子按时间顺序独立生成;(2)每个用户按照其时间线发帖,独立于其他用户;(3)每个帖子选用K 个有限的发布模式;(4)K 个发布模式对所有用户是统一适用的。
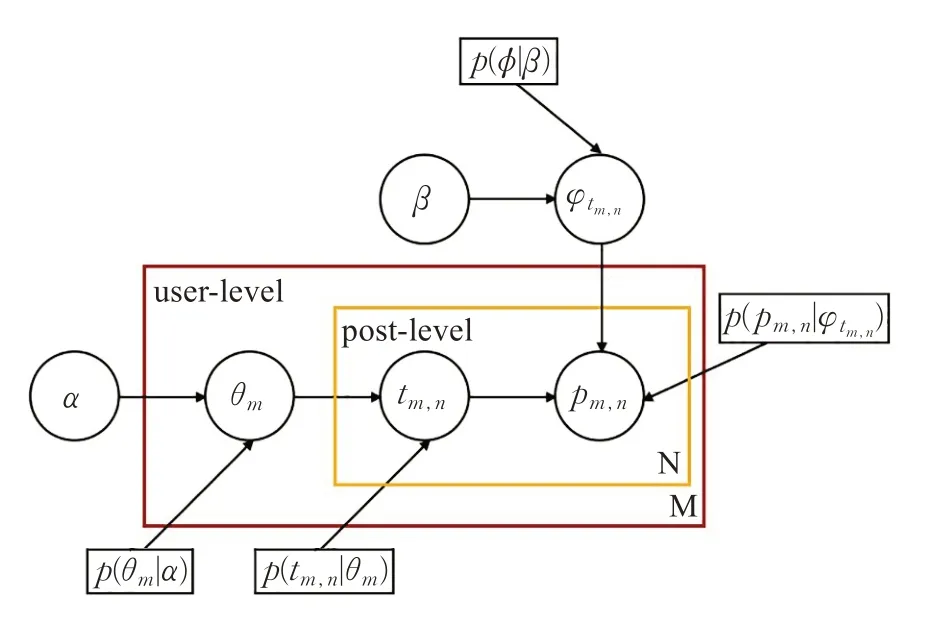
图2 基于离散元组的LDA模型
经过吉布斯采样,LDA 模型学习得到参数α,β,θm,φk,tm,n和pm,n,参数的定义以及与传统的LDA 模型参数的对比如表2所示。
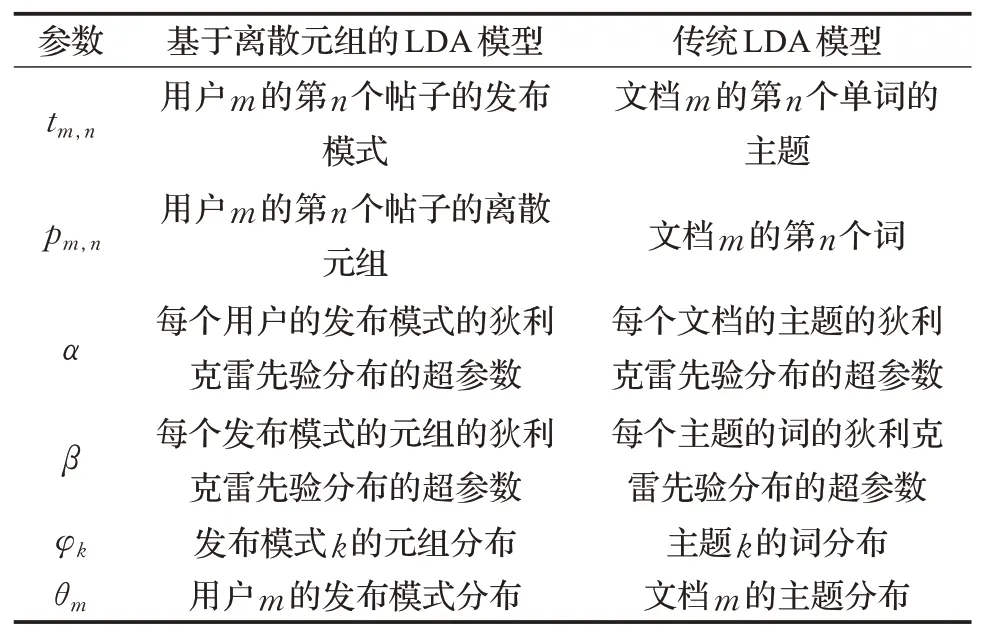
表2 本模型和传统LDA模型的参数对比
3.1.3 模型的测评
为了生成最佳的LDA 模型,需要调整模型的参数。LDA模型最重要的调整参数是发布模式的数量(K)。本研究采用两个指标来评估模型的好坏:困惑度(Perplex‐ity)和DB 指数(Davies-Bouldin index)。通过计算和比较不同K 值下模型的困惑度和DB 指数,选取最佳的LDA模型。
困惑度是衡量概率分布或概率模型预测样本的优劣程度的指标[16]。困惑度越低表示概率模型越善于预测样本。LDA模型的困惑度的计算方法如下:
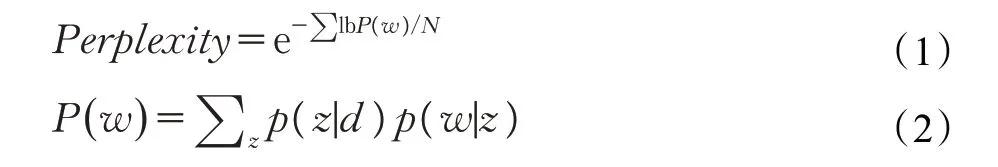
DB 指数是聚类质量的内部评估方案[17]。使用欧几里德距离的DBI由公式(3)给出:

在计算DB指数时,将帖子类型视为聚类,将元组视为点。ci和cj是聚类i和聚类j的中心。Ci是聚类i中的点与聚类的中心之间的平均距离。同样,Cj是聚类j 中的点与聚类的中心之间的平均距离DB指数越低表示聚类越好地被分离。
3.2 兴趣预测模型
作为发布模式模型的应用,将用户的发布模式分布作为特征,构建兴趣预测模型。本数据集中的用户来自15 个公共Facebook 兴趣小组,每个用户只属于一个Facebook兴趣组。
3.2.1 二元分类模型
采用二元分类(binary classification)模型进行用户兴趣预测。二元分类模型只预测用户是否对特定的兴趣主题感兴趣,而不将用户分为一个特定的兴趣小组。因为在现实情况下,一个用户可能有很多兴趣,所以二元预测模型比多元预测模型更为合理,且更适用于推荐系统。例如,旅游公司中的广告商只想知道一个用户是否对旅行感兴趣,而不关心此用户是否对其他兴趣主题感兴趣。对于每个兴趣主题,模型预测用户是否对其感兴趣,从而将多分类模型分别拆分为15 个二元预测模型。
3.2.2 用户兴趣预测的特征
用于用户兴趣预测的特征包括以下四类:
(1)用户发布模式特征:从发布模式模型中提取的用户发布模式分布。
(2)用户资料特征:用户个人资料,如互相关注人数,相册照片数等。
(3)帖子类型特征:用户的不同类型的帖子数,如使用表情的帖数,纯文本帖数等。
(4)从用户点赞的主页中提取的语义特征:使用语义特征进行兴趣预测是一种传统方法。Facebook中,用户点赞的主页通常与某些兴趣主题相关联。从用户点赞的主页中提取语义特征的方法如下:提取用户点赞的主页并将这些页面分类为1 200 个子类别,对于每个子类别,计算用户点赞的主页中属于此子类别的主页的数量,然后给每个用户赋予一个1×1 200向量,该向量即从用户点赞的主页中提取的语义特征。
3.2.3 预测算法
采 用XG Boost 分 类 器(Extreme Gradient boost‐ing)[18]作为预测算法。XGBoost 是在Gradient Boosting框架下部署优化的机器学习算法的库。预测中,采用十倍交叉验证,训练集和验证集之间的比例是7∶3。
4 实验结果及分析
4.1 数据收集
数据集中的用户来自15 个Facebook 公共小组,这些小组拥有超过1 000 名成员,与各种兴趣主题有关,如商业、政治、宠物、音乐、体育等,各兴趣组的用户数如表3所示。通过FacebookGraphAPI采集活跃用户,即上个月在关于兴趣小组中发表过至少一篇帖子的用户。剔除将发帖页面或个人资料页面设置为私有的用户后,共获得1 149 个用户。开放数据集下载链接:http://gituhub.com/sustainn/LDA-on-discrete-score-tuple。

表3 各兴趣小组的用户数
对于每个用户,从用户的主页中提取2018 年发布的所有公共文本帖子。在删除非英文帖子后,最终获得了138 810 个英文文本帖子,对于每个帖子,剔除URL和表情符号。
4.2 发布模式
4.2.1 最佳LDA模型
LDA 模型最重要的调整参数是基于发布模式的数量(K)。通过计算不同K 值下LDA 模型的困惑度和DB指数,选取困惑度和DB 指数均较低的模型为最佳的LDA主题模型。
对于不同的元组,不同K 值下模型的困惑度和DB指数如图3 和图4 所示。可以看出,当采用元组1,K 为8时,困惑度和DB指数较低。

图3 不同发布发布模式数和元组下模型的困惑度
4.2.2 标记发布模式

图4 不同发布发布模式数和元组下模型的DB指数
通过元组类型1的LDA模型,模型提取出八种发布模式,并得到表征发布模式的元组分布的参数φk。为了标记这八种发布模式,绘制各个发布模式的元组的概率分布的散点图。用两个二元组{极性,主观性}和{极性,字数}来表示三元组{极性,主观性,字数},对于每一种发布模式,用两个散点图表示二元组(极性,主观性)和(极性,字数)的概率分布。散点图中,点的横坐标表示极性,纵坐标表示主观性或字数;以点为中心的圆圈表示属性的值为点的横纵坐标的元组出现的概率,圆圈的面积与概率成正比;整个散点图的质心用一个黑色的点表示,质心的坐标标在图的右上角。根据质心的坐标和圆圈的大小,可为发布模式添加标签。
例如,发布模式1 的元组的概率分布如图5 所示。可以看到面积最大的蓝色圆圈位于极性轴的中间,主观性轴的底部和字数轴的底部,因此可以将发布模式标记为“中立客观短文本”。图中的质心说明了同样的结论。通过同样的方式,可标记其他发布模式为:“中立非主观长文本”,“积极主观中长文本”,“中立客观长文本”,“积极偏主观中长文本”,“积极偏客观中短文本”,“积极偏主观中短文本”,“中性偏客观中长文本。

图5 发布模式1的元组概率分布图
4.2.3 相似用户
通过元组类型1 的LDA 模型,模型提取出8 种发布模式,并得到表征用户的发布模式分布的参数θm,即表征用户m 的发布模式分布的八维向量。通过计算和比较用户的发布模式分布的余弦相似度,可以找到具有相似发布模式的用户。余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估向量的相似度。对于向量A和B:

例如,以下2 个用户的发布模式分布之间的余弦相似度为0.985,如图6 所示。通过人工检验,发现两个用户经常发布积极、中等长度的帖子。他们都属于JazzmastersJaguars 兴趣组。通过人工检验,可以验证发布模式分布的合理性和准确性。

图6 用户Cody Hanlon和Charles Hoerneman的时间轴帖子
4.3 兴趣预测
用于用户兴趣预测的特征包括用户行为特征和从用户点赞的主页中提取的语义特征。其中,用户行为特征如表4 所示,包含三个部分:(1)用户资料特征;(2)帖子类型特征;(3)从LDA 模型提取的用户发布模式概率分布特征。
图7 和图8 中显示了将不同K 值和元组下LDA 模型的参数值θm作为发布模式特征时,预测模型的准确率和F1值。可以看出,对于所有元组,当K 为7到9时,预测模型的准确率和F1值较高;随着K 值继续增大,预测模型的准确率和F1值下降。这是因为在LDA 模型中,主题数越多,模型越容易过拟合。预测模型的结果与LDA 模型的困惑度和DB 指数结果吻合。当选取元组1,K 为8 时,兴趣预测的准确率最高;当选取元组2,K 为7时,兴趣预测的F1值最高。

表4 用户行为特征

图7 采用不同发布模式数和元组时预测模型的准确率

图8 采用不同发布模式数和元组时预测模型的F1值
选取元组2,K 为7 时LDA 模型的结果作为发布模式特征。分别采用以下四种特征用于兴趣预测:(1)用户个人资料特征和帖子类型特征;(2)用户行为特征,即用户个人资料特征、帖子类型特征和发布模式特征;(3)用户行为特征用户个人资料特征、帖子类型特征和从用户点赞的主页中提取的语义特征;(4)所有特征,即用户个人资料特征、帖子类型特征、用户发布模式特征和从用户点赞的主页中提取的语义特征。表5 中展示了对于各个兴趣组,分别采用上述四种特征时二元分类模型的准确率,最佳结果标记为粗体。可以看到,使用特征2比使用特征1时的平均准确率高0.03,使用特征4比使用特征3时的平均准确率高0.02。这表明使用用户发布模式分布可以有效提高用户兴趣预测的准确率。除了旅行组,对于大多数兴趣组,使用所有特征时,预测的准确率最高,平均准确率达到0.81。
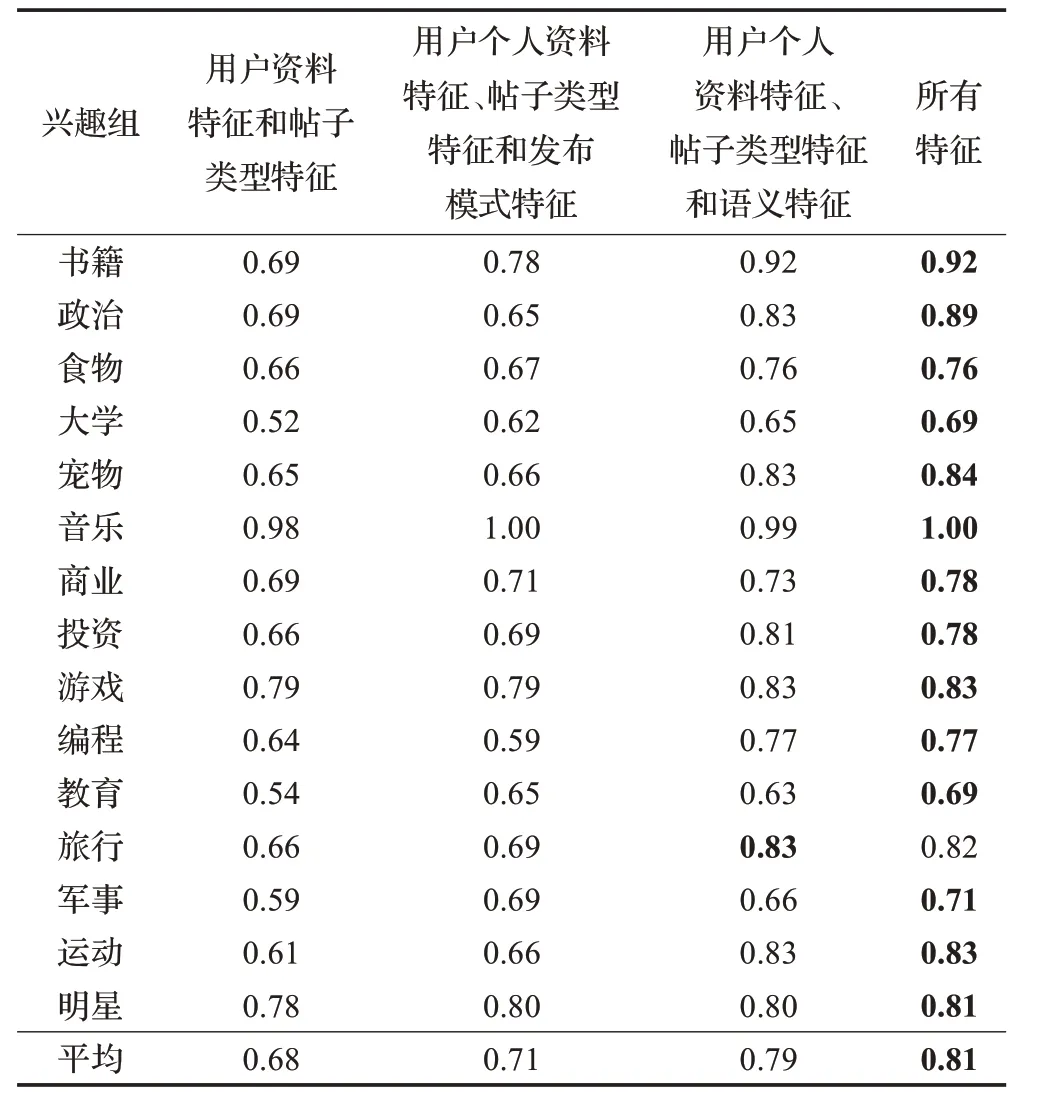
表5 使用不同特征时XGB算法下的二元分类模型的准确率
相关研究[15]提出了一种两层k-means 聚类方法,并发现了七种用户类型。将聚类模型的兴趣预测的准确率与本文结果进行比较,如表6 所示。可以看出,本文提出的发布模式模型比聚类模型在兴趣预测模型中可达到更高的准确率。
5 总结
本文提出了一种方法来挖掘社交网络用户潜在的发布模式并预测用户兴趣。首先,通过构建基于离散元组的LDA 模型,得到用户的发布模式分布。然后将发布模式分布特征与用户资料特征和帖子类型特征结合,得到用户行为特征。最后,将用户行为特征用于兴趣预测。在兴趣预测实验中,结果显示本文提出的用户发布活动特征可以有效预测用户的兴趣。与仅使用语言特征相比,将用户发布行为特征和语言特征结合可以实现更高的预测准确率。本研究可应用于用户分析、兴趣预测和个性化推荐系统等领域。

表6 发布模式模型与两层聚类模型的二元分类模型的准确率
猜你喜欢
电脑报(2021年14期)2021-06-28
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
软件学报(2019年11期)2019-12-11
计算机与生活(2019年5期)2019-07-18
中国交通信息化(2018年5期)2018-08-21
吉林大学学报(理学版)(2018年2期)2018-03-29
小雪花·成长指南(2016年11期)2016-12-07
小品文选刊(2009年7期)2009-05-25
