
一种改进的RFM模型在网店客户细分中的应用
2020-05-11 09:50李为康杨小兵
中国计量大学学报 2020年1期
李为康,杨小兵
(中国计量大学 信息工程学院,浙江 杭州 310018)
近些年,消费者的消费模式受到了电子商务的极大影响。根据最新资料[1]显示,进入21世纪以来,我国互联网普及率达到了57.7%,网民数量已经增涨到了8亿多人,其中网购客户规模达到近6亿。面对如此大的市场,网购平台的商家们对于如何挽留优质客户绞尽脑汁,其中客户细分的研究慢慢地成为了焦点[2]。相比于电子商务这种新兴产业,目前在传统行业内利用数据挖掘进行客户细分的手段已经屡见不鲜。
由于电商平台的发展以及消费者网购要求的日益提高,“客对客(C2C)”的零售网店模式受到了“商对客(B2C)”模式发展的冲击。电商平台的商家之间原本存在的竞争关系又因此变得更加激烈,但电子商务存在一个普遍的现象,那就是重营销不重维护。例如淘宝网的高价值客户平均转化率不足1%,这远不及传统企业的客户回头率[3]。想要通过增加回头率来维系不同价值的客户那就需要合适的方法从而提高利润。
如何从已有的网店销售数据中正确筛选并划分出不同消费水准的消费者,再对这些消费者划分等级提供针对性的维护方案是网店商家们关注的重点。文献[4]提出将同时具有高近度、高频率和高消费价值的客户定义为高价值客户,而根据GREENBERG总结[5]通过使用RFM(Recency,Frenquency,Monetary)模型[6-10]估计客户价值能有效提高现有客户的价值转换率,增加盈利。
客户细分[11]是将不同属性特征的客户细分出来再划分为特定的类别,是有效识别客户价值的重要工具,它能帮助网店商家针对不同价值类别的客户制定个性化的营销策略。本文运用亚马逊网站提供的网店公开数据建立基于RFM模型的RVMF(Average Recency,Average Views,Average Monetary,Frequency)模型,实现客户细分并提升准确度。再根据实验的得到的细分结果来分析各价值类的用户,提供简单的客户维护策略。
1 细分方法选择
1.1 常用细分方法
目前客户细分的主要细分方法有三种:ABC方法(Activity Based Classification,分类库存控制法方法),CLV方法(Customer Lifetime Value,用户终身价值方法),RFM方法。
1)ABC方法
ABC方法可以被用作识别用户价值的一种方法。通过分析用户的贡献、收入、品牌贡献等基本资料,定位出目标客户中价值最高的一部分客户。
2)CLV方法
CLV方法的核心思想是利用每个消费者在商家预期内会带来的收益期望来对客户进行评级,每一个消费者的级别构成都参考了该消费者的未来、当前和过去三大价值。
3)RFM方法
RFM方法是基于客户消费数据的一种细分方法,该方法通过客户的消费数据获取用户的近期消费的时间点、不同时间点间隔内的消费频率以及相应时间点间隔内的消费总额来建立RFM模型从而划分客户的价值等级。RFM方法强调以消费者的行为来区分消费者价值等级,而CLV和ABC方法着重在对于消费者贡献度的分析,所以RFM方法能指导的范围比前两者要广很多。
1.2 适合电商网店的细分方法
上述的三种方法在一般的情况下都有着各自的适用环境,ABC方法需要对客户进行主次的区分,但对于具体的区分方法没有一个明确的界定,而且在实际情况下,会出现成本分配不合理,导致成本比重不大但相对更加重要的对象被遗漏的情况。CLV方法需要足够多的数据来给一个客户评估价值,这对获取的数据有很高的要求,且它是根据客户曾经的消费模式或统计学特征来预测客户未来的行为和消费能力,这明显不能清晰地反映出客户价值的走向。
相较而言,在传统实体零售业被广泛运用的RFM方法,在强大的互联网技术的支持下,能够简单地获取数据量庞大的客户详细交易信息。对于网店来说,RFM是最适用的客户细分方法,不过由于其中F和M两个属性存在强线性关系,而且无法利用商品浏览量这一个网店的重要指标,最后划分客户时模型三种属性权重一样还会影响最终客户价值预测的准确性。所以,本文针对电商网店提出了一种改进的RFM模型——RVMF模型。
2 RVMF模型
2.1 RFM模型改进
准确的模型能够提升实验效果[7]。文献[9]中提出了一种改进RFM模型,但是无法适应电商网店客户量大、消费数据量大、数据来源覆盖面广的特点,忽略了R属性随机性大导致老客户无法被准确划分的问题,且F和M属性共线性较强的因素也被忽略。本文针对电商网店的客户特点对RFM模型进行适用性改进,将原本三个属性R、F、M,改善并扩展为AR、AV、AM、F四个属性,将客户对商品的浏览量这一电商客户特点作为主要参考因素之一,其中AR表示消费者一定时间内的平均订单交易时间间隔,AV表示消费者一定时间内的平均店铺商品浏览量,AM表示消费者一定时间内平均单次下单的消费金额,F表示消费者在一定时间内的下单次数,并将改进前后的模型属性作了比较,如表1。

表1 RFM与RVMF的属性对比Table 1 Attributes' comparison between RFM and RVMF
根据表1可以看出RVMF模型各个属性是根据网店订单数据重新生成的新特征,根据这些属性可以获得不同考察维度下消费者的消费行为数据,比如基于不同价位同种类型商品浏览量得出客户最感兴趣的商品种类或者基于相同价位的不同种类商品得出店铺客户的喜好,这些消费行为数据都能够被电商采用来预测客户价值。RVMF模型通过设置在单个消费时间间隔点内的条件消除了RFM模型中F属性与M属性之间的共线性问题,并通过平均时间内的订单间隔克服了RFM模型中R指标随机性较大的缺陷,对于交易频次较高的老客户,平均订单交易时间间隔更具有代表性。由于加入了店铺商品浏览数量,还提高了模型的可靠性以及对于客户价值预测的可信度。
2.2 RVMF模型属性权重设定
一般认为RFM模型在衡量一个问题时权重应该一致所以三个属性R、F、M一般被赋予相同的权重。但对于实际情况应该具体问题具体分析,比如根据客户信用卡信息相关的研究,结合银行这一特殊性应该认为模型中F属性最重要,其次是R属性最后是M属性。文献[9]中也给出了针对传统零售企业客户的具体加权方案。本文认为针对不一样的行业领域每一个属性的权重应该也应有所不同,相对于传统企业,电商平台能够更轻松地获取到客户具体的浏览数据、消费细节。
对于权重的确定应该使用一个定量的方法,所以实验中通过运用简洁实用且有机结合了“量”与“性”的层次分析法来确定RVMF模型的属性权重。而且层次分析法适合追求理解问题本质与要素的研究内容,它更注重更多的是定量的处理,同等情况下对相应数据的需求也更少,将层次分析法运用在RVMF模型的流程如图1。
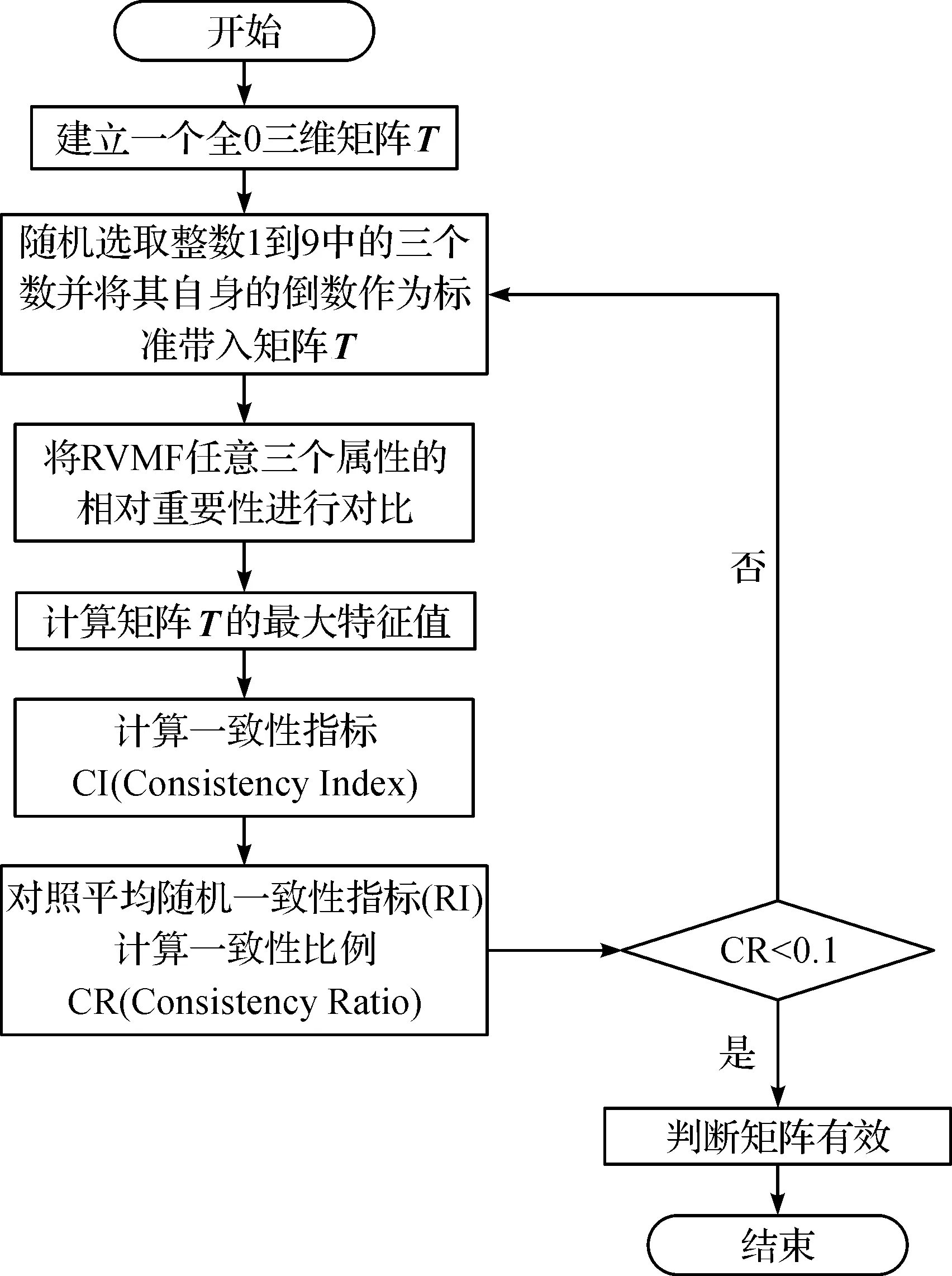
图1 层次分析法流程Figure 1 Analytic hierarchy process
图中
(1)
(2)
式(1)中,λmax是图1中建立的三维矩阵T的最大特征值,而n则是三维矩阵在运算时的阶数,RI的部分对照如表2。

表2 一致性指标Table 2 Consistency index
假设计算权重得到:WR=0.1,WV=0.2,WM=0.3,WF=0.4,那么认为消费者的消费金额是衡量客户价值的重要因素。基于这样对属性权重的判断,可以得到客户价值是模型各个属性与其对应权重的乘积的和:
RVMF=WR*R+WV*V+WM*M+WF*F。
(3)
3 数据预处理
3.1 数据来源
本文使用的数据样本来源于一个全球性的大型电商平台,该数据集中包含了超过5万条全球1 600位以上的不同客户从2011年至2015年中的消费数据,并且包含平台自身标记的客户价值标签。因为最终目的是客户细分所以仅选择B2C领域的消费者以及数据量最多的平台用户本土区域的消费数据来去除潜在的人口偏差[12]。从数据中统计出每个消费者最近一次的下单时间与分析时间点(2015年11月31日)的时间间隔,时间间隔内有效的下单次数还有每个消费者的消费总金额。统计的样本数据示例如图2,其中,Sales是时间间隔内有效的下单次数还有每个消费者的消费总金额,Views是时间间隔内有效的店铺商品浏览量。
图2 样本数据示例Figure 2 Sample data example
3.2 数据归一化
由于真实的数据集中存在干扰点,不管是用到均值还是标准差效果都不会很好。所以本文使用了离差规范化法。离差规范化法虽然受限于最小和最大值的取值,但却是消除纲量和数据取值范围影响最简单有效的方法。离差规范化法对样本数据进行处理时会在[0,1]内映射出原始数据的线性变换。转换公式为
(4)
公式中min和max是数据中样本的最小值和最大值,而将公式运用到RVMF模型中得到公式:
(5)
其中P即可带入改进模型的四个属性。
3.3 优化聚类中心
数据归一化之后可以更方便地通过聚类算法将数据进行处理得到分类后的数据[13-15]。本文采用文献[16]中的一种基于聚合度的聚类算法,主要概念如下:
欧式距离:假设每一个数据点的属性维度都是m,那么每个数据点可以用xi={xi1,xi2…xim}抽象体现出来,所以数据点xi和xj之间的距离便可以用公式(6)表示为
(6)
2)数据集平均距离:公式(7)是计算一个数据集中所有数据点之间的平均欧式距离
(7)
4)聚合度:Deg(xi)代表点xi与其间隔小于半径的点的个数,即;
(8)
5)集合平均间隔:与点xi的间隔小于R的所有点组成一个集合,那么点xi所在集合的平均间隔可以定义为
(9)
6)聚合度距离:G(xi)代表的是点xi与其他具有较高聚合度点之间的距离。若所有数据点中xi的聚合度最大,则其聚合度距离为xi与其余任何点的最大距离。若xi的聚合度不是所有数据点中最大,那么其聚合度距离为xi与其余任何点的最小距离。
7)聚合距离参数:聚合距离参数由聚合度,集合平均距离及聚合度距离三个参数决定。即
(10)
聚合度Deg(xi)越大,表明点xi周围的数据点越密集。聚合度距离G(xi)越大,则两个簇群之间的相异程度越高。集合平均间隔Cavgd(xi)越小,则其倒数越大,表明由xi组成的集合中的元素越紧密。由此可见,聚合距离参数值越大的点,越适合作为聚类中心。
实现的具体步骤如下:
1)根据式(6)到(10)对数据集中所有数据进行计算根据计算结果得到相关参数,从而获取到每一个点的聚合距离参数。
2)从步骤1中挑选聚合距离最大的点,作为第一个中心点,计算这个中心点与别的点的欧式距离,若距离小于领域半径R则将该点去除。
3)从剩余的点中重复步骤2,遍历整个数据集。
4)输出符合条件的中心点集合。
经过多次实验发现聚合度距离有时会出现区分度不高的问题,所以本文对聚合度距离加以改进,改进后的聚合度距离区分度更高且稳定,对点xi与其他聚合度较大的点距离改进公式如下:
(11)
其中d(xi,xj)代表欧氏距离参考式(6),Deg(xi)和Deg(xj)代表聚合度参考式(8)。
优化后的算法与优化前的对比实验如图3。
由图3可以看出,在相同的数据下未优化的聚类算法将一个离群点定为了蓝色簇群聚类中心,而优化后的聚类算法聚类效果明显更好。
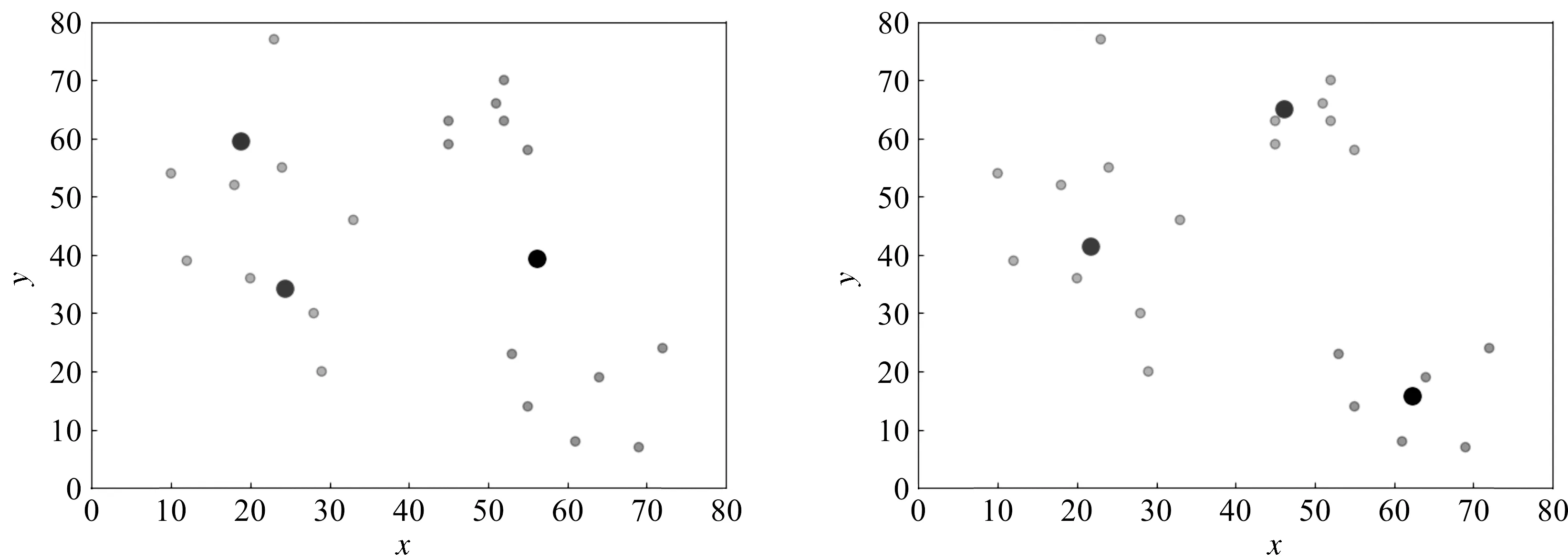
图3 算法优化结果对比Figure 3 Comparison of algorithm optimization results
3.4 优化k值选取
为了节省时间成本,本文参考杨善林等人[17]采用数据挖掘领域常用的DBI(Davies-Bouldin index)来确定合适的k值,DBI是精确型的集群评价指标,它以各个类之间的距离和类内数据点之间的距离作为衡量标准,类间距离越大越好,类内距离越小越好。算法保存每次的运算结果再遍历所有结果,输出符合最终条件的k值。计算公式如下:
(12)
其中Δ(Si)表示类Si的类内距离,dij表示两个类之间的距离,k是聚类数。具体步骤如下。
1)输入最大聚类数kmax和样本数据集。
2)令k=n(n>1,一般从2开始)直到k=kmax。
3)产生中心点。
4)重复上述2步。
5)将数据点分配给k个中心点中距离最小的中心点,直到数据集为空。
6)将每个类的中心点再进行运算处理。
7)当准则函数收敛时开始记录每个中心点。
8)利用式(12)计算DBI并转向步骤1。
9)根据DBI指标筛选出效果最好的k值。
10)输出k。
根据DBI计算得到最优k值为4。
4 实验结果与策略分析
通过层次分析法计算RVMF模型属性权重得到WR=0.072,WV=0.132,WM=0.517,WF=0.279,根据公式(3)计算后得到加权之后得到的部分结果如图4所示,R*、V*、M*、F*分别代表加权后的各个属性值。由图4中可以看出处理之后的结果相比处理之前能更加直观地进行比较。
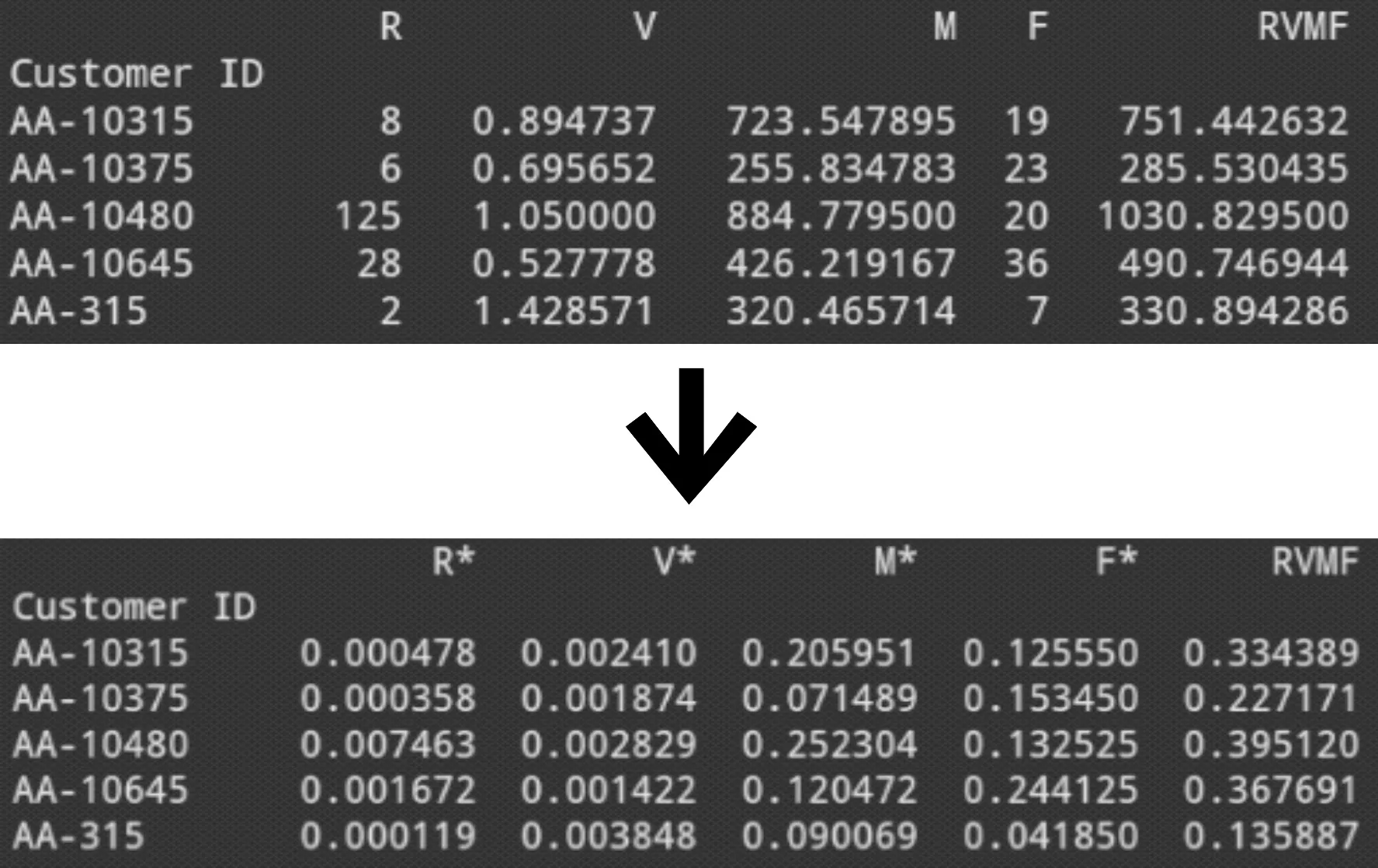
图4 加权后的RVMF值示意图Figure 4 Schematic diagram of weighted RVMF value
得到RVMF计算结果后应用聚类算法将R、V、M、F四个属性作为聚类变量对数据进行聚类并细分客户,根据优化聚类中心得到的结果将中心点数量设为4,RFM模型的细分结果如表3,RVMF模型的细分结果如表4。
对比表3、表4与表5可以看出RFM模型由于权重和共线性问题将部分M属性很高、F属性很高、R属性一般的客户划分为了第二类客户,将R属性很低F属性很高但是M属性一般的客户划分为了第一类客户,这明显是不符合期望的。而RVMF模型在引入V属性并改进了权重后准确的将M值较大的客户识别为第一类客户,并且解决了新老客户划分问题,消除共线性后准确地将R属性很低F属性很高M属性一般的客户划分为了第二类客户。
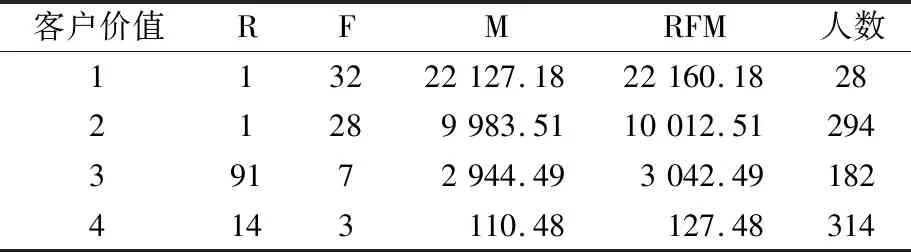
表3 RFM模型客户价值表Table 3 Customer value table of RFM model
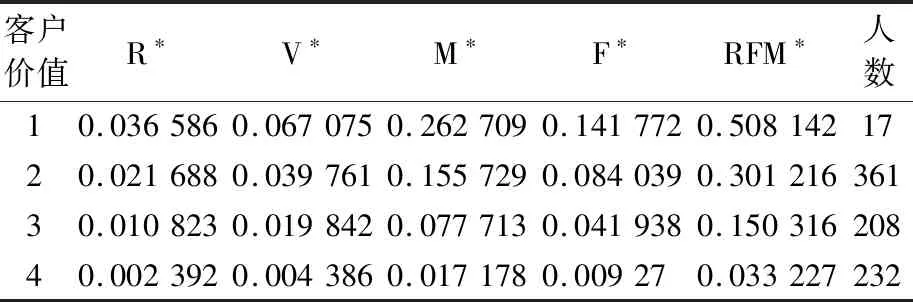
表4 RVMF模型客户价值表Table 4 Customer value table of RVMF model

表5 实验结果对比表Table 5 Comparison table of experimental results
从表5还可以看出RFM模型得出的结果在第一类客户和第二类客户与平台自身给出的价值标签差距较大并且无法直观通过R属性与F属性对比客户价值。而RVMF模型在这两者的结果上差异较小,还能够简单明了的判断客户价值的高低。由于平台自身价值标签只有3类,所以将细分之后结果中的第三类和第四类客户合并到“Low”类客户中。
根据RVMF模型得出的结果,第一类消费者包括17名,占据统计人数的2.1%。这类消费者的下单频率高而且单次订单的消费额度大,浏览网店商品的频率很高,可以划分为高价值客户。这类消费者作为电商最应该挽留的客户,应该着重维护,可以通过邮件或公众号等方式对他们进行宣传,对待高价值客户甚至也可以进行电话营销。
第二类消费者包括361人,占统计人数的44.1%。这一类的消费者的消费频率虽然高,但是每一笔消费的额度不高,浏览网店商品的频率也一般,可以划分为可挽留客户,这一类客户挽留优先级与重要客户一样。
第三类消费者包括208人,占统计人数的25.4%。这类消费者消费不够频繁,但还是偶尔会浏览商品,可以划分为次要客户,可以重点培养这类消费者,可以对他们进行发放电子优惠卷一类的营销活动。
最后一类消费者包括232人,占到统计人数的28.4%。这类消费者是价值最低的消费者。不论在下单频率还是订单的金额上都很低,平时也几乎不怎么浏览商品,可以划分为流失客户。
5 结 语
本文介绍了互联网技术高速发展的背景下针对电商平台网店的客户细分模型,并实现了优化的聚类算法在RVMF模型下的客户细分。从实验结果的分析可以看出利用互联网技术获取的客户数据进行客户细分能够快速直观地预测客户的价值,有助网店商家维护客户,最终提升利润。
当然本文也有不足的地方,比如对于聚类方法产生局部最优解的问题没有很好的优化,以及对于RVMF模型的属性还可以更加细化等。这些问题希望可以在日后通过更加深入的研究加以改进,达到更好的客户细分效果。
猜你喜欢
新型工业化(2022年8期)2022-10-14
中国造纸(2022年3期)2022-07-21
华人时刊(2020年23期)2020-04-13
无机盐工业(2019年11期)2019-11-15
铁道通信信号(2019年6期)2019-10-08
湖北农业科学(2017年2期)2017-03-27
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
专用汽车(2016年9期)2016-03-01
现代计算机(2016年17期)2016-02-28
