
Tiny YOLOV3目标检测改进
2020-05-10 03:04:44巩笑天欧阳航空
光学精密工程 2020年4期
马 立,巩笑天,欧阳航空
(上海大学 机电工程与自动化学院,上海 200444)
1 引 言
随着社会发展和科技进步,无人驾驶车辆成为未来交通的一大趋势。目标检测方法是无人驾驶系统必不可少的部分,可分为浅层学习和深度学习两种方法。浅层学习一般根据模板和图像稳定的特征点获得模板与场景中对象的对应关系来检测目标,使用 AdaBoost[1]和Canny[2]等特征提取方法和粒子群SVM(Support Vector Machine)[3]等分类方法进行检测。近年来,随着硬件运算能力提高,基于卷积神经网络的深度学习[4]得到迅速发展。相比浅层学习,深度学习能够更好地提取特征,目前分为两种:一种是结合预测框和卷积神经网络分类,为二阶段算法,以R-CNN[5-7]系列为主要发展方向,虽然检测精度大幅提升,但是速度非常慢;另一种是将分类和预测合并为一步,为单阶段算法,以SSD(Single Shot MultiBox Detector)[8]系列和YOLO(You Only Look Once)[9-11]系列为主,通过卷积网络提取特征,直接预测边界框坐标和类别。YOLOV3是YOLO系列最新的目标检测算法,融合了特征金字塔[12],借鉴了残差网络[13]和多尺度预测网络[14-15],大幅提升了目标检测速度和准确率。 但这些算法模型较大,对嵌入式系统来说,无法满足实时性要求,不适用于无人驾驶实际场景。
Tiny YOLOV3是YOLOV3的简化版本,卷积层数大幅减少,模型结构简单,不需占用大量内存,是目前最快的目标实时检测算法,但检测精度较低,尤其是在行人等小目标检测[16-17]中,漏检率较高。本文针对这一问题展开研究,在特征提取网络阶段添加2步长的卷积层,深化的网络可以更好地提取特征,提高检测精度,但增加卷积层数,会导致参数量剧增,这将极大地增加计算量并占用内存资源,因此本文采用深度可分离卷积构造反残差块,在提高检测精度的同时实现快速计算以满足实时检测要求。改进预测网络和损失函数,实现三尺度预测,进一步提高检测精度。
2 Tiny YOLOV3算法改进
2.1 Tiny YOLOV3算法
Tiny YOLOV3算法是在 YOLOv3算法基础上应用于嵌入式平台的轻量级实时检测算法,在检测精度上有所降低,但是实现了模型压缩,Tiny YOLOV3 将 YOLOv3 特征检测网络 darknet-53 缩减为 7 层传统卷积和 6 层 Max Pooling(最大池化)层,采用 13×13、26×26 两尺度预测网络对目标进行预测,网络结构如图 1 所示。
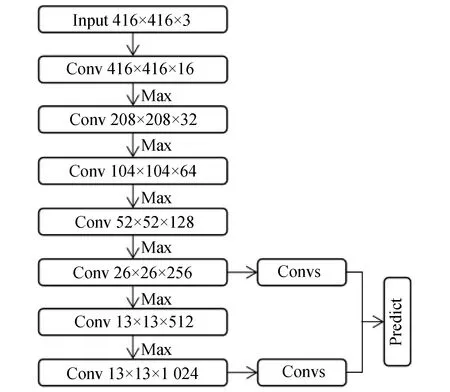
图1 Tiny YOLOV3网络结构Fig.1 Tiny YOLOV3 network structure
Tiny YOLOv3 将输入图像划分为S×S的网格,在每个网格内预测B个边界框,对C类目标进行检测,输出每类目标的边界框和置信度。置信度由每个网格中包含检测目标的概率和输出边界框的准确度共同确定,其公式为:
(1)
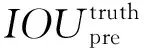
Tiny YOLOv3 的损失函数Loss主要从边界框位置误差项、边界框的置信度误差项以及分类预测误差项3个方面定义:
(2)
其中:第1、2项为位置坐标误差项,第3、4项为置信度误差项,第5项为分类预测误差项。
2.2 构造反残差块
传统卷积的参数计算量随着卷积层数增加而大幅增长,本文使用深度可分离卷积代替传统卷积,将传统卷积转变为深度卷积和逐点卷积两部分,可有效减少模型大小的参数计算量。但这种方法会随着卷积层数增加而出现梯度消失问题,残差结构能够解决这个问题,但残差结构会压缩特征图损害特征表达。本文在特征提取过程中采用反残差块,先通过1×1 卷积扩张通道,然后用3×3 的深度卷积提取高维空间特征,最后再通过1×1 的点卷积层将深度卷积结果映射到新的通道空间。残差块与反残差块结构如图2所示。图中:n为输入通道数,t为扩充或压缩通道的倍数,C为通道数。本文反残差块参数见表1。表1中:h,w分别为特征图的高和宽;n为特征图的通道数;s为步长。
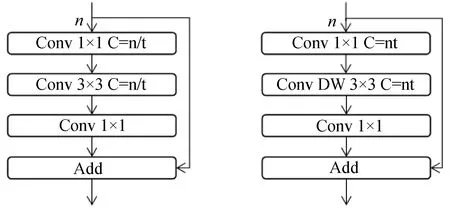
图2 残差块与反残差块结构Fig.2 Figure 2 residual block and anti-residual block structure
表1 反残差块参数
Tab.1 Anti-residual block parameter

输入卷积输出h×w×n Conv 1×1, Reluh×w×2nh×w×2n Conv DW 3×3, Reluh/s×w/s×2nh/s×w/s×2nConv 1×1 h/s×w/s×2n
2.3 网络模型改进
为了解决Tiny YOLOv3对行人等小目标检测精度低,漏检率高的问题,本文在原有网络基础上进行改进,网络结构如图 3 所示,其中,ARB为反残差块(Anti-Residual Block),虚线框中为网络特征提取部分。
在特征提取网络中,通过增加卷积层提高特征提取量,用步长为2 的卷积代替原网络中的最大池化层进行下采样,并用深度可分离卷积构造的反残差块代替传统卷积。改进的网络由12个反残差块构成,通过反残差块,扩张特征图通道提取高维特征,再进行通道降维,得到特征图。在增加特征提取的同时,有效降低模型尺寸和参数计算量。同时,在原网络26×26、13×13两尺度预测目标的基础上增加一上采样层upsample,形成52×52、26×26、13×13三尺度预测,进一步提高目标检测准确率。
表2列出了YOLOV3,Tiny YOLOV3及本文改进的网络模型大小及处理一张图片所需要的计算量。可以看出,本文改进后的网络模型与Tiny YOLOV3相比,模型尺寸仅大0.4 M,处理一张图片所需计算量增加0.17GFLOPs,远小于YOLOV3模型计算量,在模型大小和运算量上极具优势,满足嵌入式系统实时检测要求。
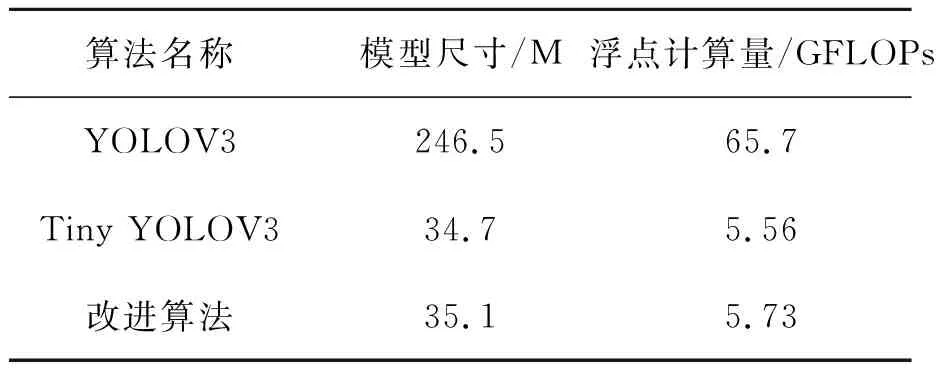
表2 不同网络模型大小及计算量

图3 改进的Tiny YOLOV3网络模型Fig.3 Improved Tiny YOLOV3 network model
2.4 损失函数改进
交并比(Intersection Over Union,IOU)度量预测框和真实框之间的交并集,是在目标检测基准中使用的最流行的评估方法,但是在预测框和真实框无交集的情况下不能进行度量评估。为此,本文对损失函数中边界框位置误差项进行优化,采用广义交并比(Generalized Intersection Over Union,GIOU)解决这个问题。GIOU为IOU与不含最小封闭面的预测框真实框交集与最小封闭面的比值的差。交并比和广义交并比的定义如式(3)和式(4):
(3)
(4)
其中:A表示真实框,B表示预测框,C表示预测框和真实框之间的最小封闭面。
使用GIOU检测目标时,比较两个轴对齐的边界框,真实框和预测框组成的交叉面和最小封闭面均为矩形,可用解析解来计算。
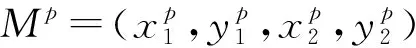
(5)
(6)
预测框与真实框的交集I为:
I=

预测框与真实框的最小封闭面Mc为:
(7)
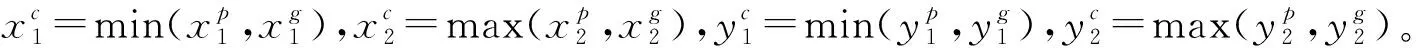
最小封闭面面积Nc为:
(8)
则Mp和Mg的IOU 和GIOU公式为:
(9)
(10)
由式(5)~式(10)可以看出,GIOU能更加准确地描述预测框和真实框的距离,对训练和检测效果更好,所以,本文在原损失函数中的位置误差项使用GIOU替换IOU。
3 实 验
本文中的整个实验在以TensorFlow为后端的keras中实现,实验环境为:Cuda 9.0加速;硬件配置为AMD Ryzen 5 Six-Core Processor@3.4 GHz、GeForce GTX 1080Ti 显卡;操作系统为:Ubuntu 18.04.1 LTS。总迭代次数为50 020,初始学习率设置为0.001,在40 000次迭代之后,学习率为0.000 1,小批量设置为16,细分设置为4,权重衰减系数设定为0.000 5,动量系数设定为0.9。训练时,模型的输入大小每次迭代改变10次,这样最终的模型对不同尺寸的图像具有更好的检测效果。
3.1 数据集制作
针对所研究的问题,本文使用混合数据集。首先使用自动驾驶数据集KITTI,将原始数据集8个类别重新划分:将汽车,卡车和货车合并为机动车类;行人,坐着的行人和骑车的人合并为人类;最后两项电车和杂项删除。最终得到的训练样本数量为:机动车33 250个、行人4 900个。削减KITTI中机动车数量,与INRIA行人数据集、VOC2007行人数据集混合,最终得到共50 000张图片的混合数据集,其中车类和人类比例接近1∶1,防止数据集中样本差距过大导致的过拟合问题,其中70%用于训练,20%用于验证,10%用于测试。混合数据集背景复杂,行人姿态多样,遮挡的程度和样本目标的大小不同,可以得到更好的训练效果和模型泛化能力。
3.2 实验结果与分析
为了评估改进算法的准确率,将KITTI、INRIA、VOC、混合数据集分别在YOLOV3,Tiny YOLOV3和本文改进算法中训练并验证测试,计算平均精度均值(mAP)和检测速度(FPS)。测试结果如表3所示。
由表3可以看出,本文使用混合数据集训练后的检测平均精度均值高于各单个数据集,能得到更好的训练效果和检测结果。YOLOV3的检测准确率远高于Tiny YOLOV3和本文改进的算法,但其网络的模型大,参数多,计算量大,从而导致FPS低,不适用于汽车的嵌入式设备对目标的实时检测。对比Tiny YOLOV3和本文改进的算法,虽然FPS下降了2.8,检测速度稍慢,但仍高于YOLOV3,满足实时检测要求。
表3 各算法用不同数据集训练后的测试结果
Tab.3 Test results of algorithms trained with different data sets
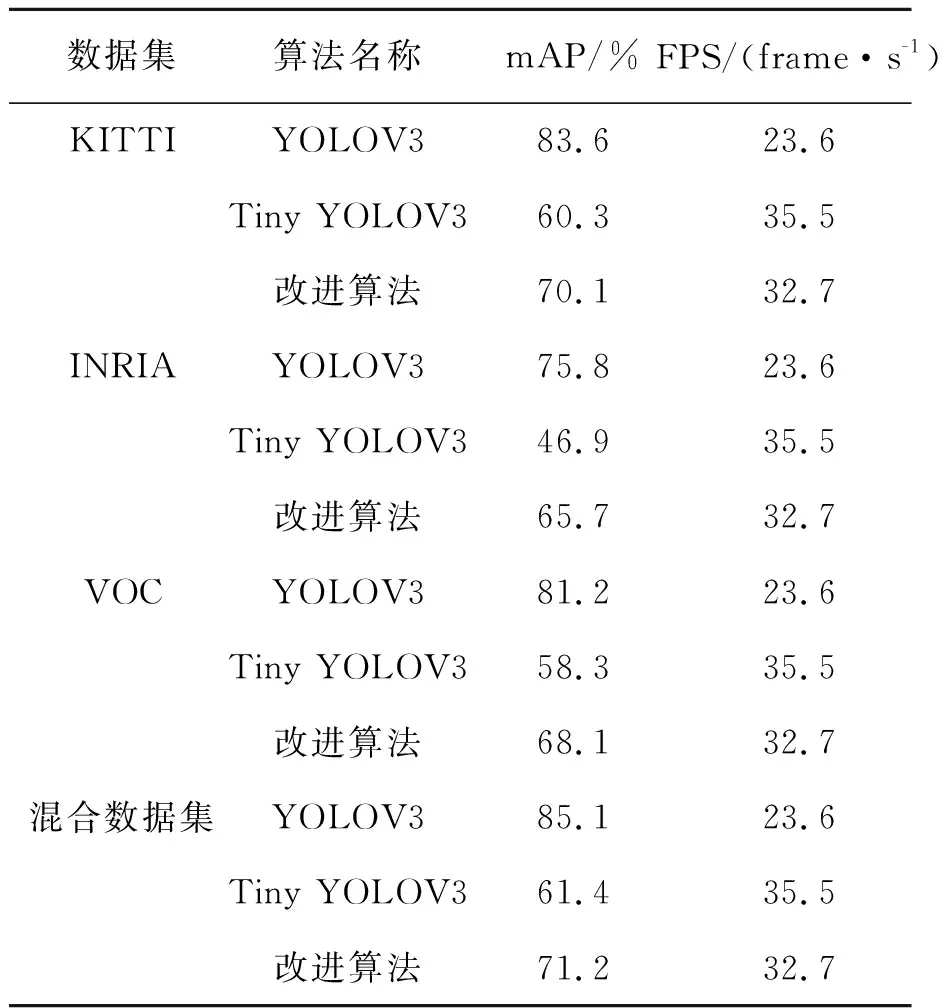
数据集算法名称mAP/%FPS/(frame·s-1)KITTIYOLOV383.623.6Tiny YOLOV360.335.5改进算法70.132.7INRIAYOLOV375.823.6Tiny YOLOV346.935.5改进算法65.732.7VOCYOLOV381.223.6Tiny YOLOV358.335.5改进算法68.132.7混合数据集YOLOV385.123.6Tiny YOLOV361.435.5改进算法71.232.7
表4 各算法在混合数据集上检测结果
Tab.4 Detection results of algorithm on a mixed data set

算法名称类别AP/%mAP/%YOLOV3机动车87.3高度小于16 pxl的行人76.585.1高度为16~32 pxl的行人85.5高度大于32 pxl的行人86.7Tiny YOLOV3机动车75.6高度小于16 pxl的行人38.661.4高度为16~32 pxl的行人45.3高度大于32pxl的行人57.7改进算法机动车76.3高度小于16 pxl的行人58.371.2高度为16~32 pxl的行人67.1高度大于32 pxl的行人72.9
表4为各算法在混合数据集上的检测结果,本文改进的算法对机动车的检测准确率比Tiny YOLOV3提高0.7%,对高度小于16 pxl、高度为16~32 pxl、高度大于32 pxl的行人检测准确率比Tiny YOLOV3分别提高了19.7%、21.8%、15.2%,平均准确率为71.2%,比Tiny YOLOV3算法61.4%的平均准确率提高了9.8%,在保证实时检测的前提下,提高了目标检测精度。
图4是本文算法的真实场景检测结果,并与Tiny YOLOV3检测结果进行比较。其中图4(a)~图4(e)为Tiny YOLOV3检测结果,图4(f)~图4(j)为相同情况下改进算法的检测结果。a1中,漏检了左侧高度小于16 pxl的行人,图4(f)中无行人漏检;图4(b)中将两个高度小于16 pxl的行人检测为一人,图4(g)中正确检测为两人;图4(c)中,漏检了远处高度为16~32 pxl的行人,图4(h)中无行人漏检;图4(d)中漏检了汽车遮挡身体的高度为16~32 pxl的行人,图4(i)准确检测出行人;图4(e)中,漏检了右侧高度小于16 pxl和高度为16~32 pxl的行人,图4(j)中无行人漏检。可以看出,本文改进算法对行人等小目标有更好的检测效果,并且在光线较弱的环境下仍有良好的检测结果,这表明改进算法对复杂实时环境具有良好的适应性,能更准确地检测目标。

图4 实验结果Fig.4 Experimental results
4 结 论
本文改进的Tiny YOLOV3算法,不仅通过在特征提取网络增加卷积层数提高了目标特征提取量,还通过深度可分离卷积构造反残差块替换传统卷积降低了网络模型尺寸和参数计算量,保证目标检测速度。同时,通过在预测网络增加尺度形成三尺度预测更好的检测行人等小目标。最后,通过优化损失函数中的边界框位置误差项进一步提高了目标检测准确率。通过在制作的混合数据集中训练后的实验结果表明:改进的Tiny YOLOV3算法目标检测准确率为71.2%,比原算法提高了9.8%,FPS为32.7 frame/s,满足实时检测要求。虽然改进后算法的目标检测准确率有所提高,但仍无法满足精度要求,跟大型检测网络相比还有较大差距,如何在满足实时检测的要求下进一步提高准确率,这是下一步工作要努力的方向。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
意林(2021年5期)2021-04-18 12:21:17
农业科技与信息(2021年2期)2021-03-27 07:27:38
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
扬子江(2019年1期)2019-03-08 02:52:34
中国交通信息化(2018年5期)2018-08-21 03:37:40
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
