
基于XGBoost模型的银行信贷高风险客户识别研究
——以我国Y银行为例
2020-05-08 02:51顾洲一浙江金融职业学院浙江杭州310018
上海立信会计金融学院学报 2020年1期
顾洲一(浙江金融职业学院,浙江杭州310018)
一、引言
随着大数据与人工智能技术的蓬勃发展,利用机器学习算法建立金融风控模型已成为金融科技关注的焦点。
“银行稳则金融稳,金融稳则经济稳”,商业银行作为金融市场的重要组成部分,在经济发展过程中,不仅承担吸收存款、发放贷款等基本职责,还要发挥正确引导货币流向、提高资金使用效率以及调节社会对资金的需求量等作用,俨然已成为国民经济发展的关键因素。一国经济的健康发展,离不开一个高效稳健的银行业运行系统,而维持该系统稳定运行的关键在于该领域的风险管理。
2006年年初,《巴塞尔新资本协议》开始实施,该协议将银行业面临的风险分为9 个方面,其中,信用风险是最主要的风险,占据了近60%,自此银行业信用风险研究开始受到各国专家、学者以及政府部门的高度关注。2019年2月,由中国银行业协会和普华永道联合发布的《中国银行家调查报告(2018)》明确指出,“信用风险管控”仍然是银行业风险管理的一个重点方向;《中国银行业发展报告(2019)》指出,2018年我国商业银行处置、核销不良资产接近2 万亿元,较2017年出现大幅增加,该报告认为国内信用风险防控仍然面临诸多风险。因此,科学、客观地评估银行业的信用风险对商业银行的管理以及发展有着举足轻重的作用。
传统商业银行信用风险评估主要通过银行从业人员线下收集个人年龄、职业和个人账户以及是否有法律诉讼等基本信息,并依靠自身的市场经验进行主观判断,该方式存在着效率低、周期长以及准确率难以保证等缺点。近年来,随着互联网的普及以及信息技术的发展,以大数据、人工智能(AI)、云计算为代表的互联网技术,对当前社会发展影响巨大。与此同时,面对爆炸式增长的数据量和业务量,传统商业银行信用风险评估方式已经无法满足当下商业银行信贷业务发展的需要,大数据风控成为新的趋势。因此,如何利用海量数据,实现数据价值,让数据说真话,是当前大家关注的焦点。
随着大数据与人工智能(AI)技术的蓬勃发展,“利用AI 为各行各业赋能”已不再是一句口号,机器学习、深度学习等大数据技术正迅速进入各行各业,为各行各业的发展插上了人工智能的翅膀。现阶段,大数据技术助力各行各业发展主要体现在两个方面:一方面,AI 为企业决策提供了更加科学的决策依据;另一方面,AI 为企业的生产经营提供了更有效率的方式,并大幅降低了企业的生产经营成本。因此,如何借鉴企业已有的人工智能技术,并依托商业银行现有的海量数据资源,形成一套多元化、实时性、高价值的大数据风控体系是值得进一步深入研究的问题。
本文利用人工智能技术对我国Y 银行(国有大型商业银行)的信贷数据建立客户申请评分模型,运用该模型对新客户的违约概率进行预测,并在训练集和测试集上对模型得分进行分箱,计算在每个分数段坏客户的累计召回率,从而对模型的预测效果进行评价。文章结构如下:第一部分为引言,介绍了本研究的行业背景与研究目的;第二部分为文献综述,梳理了关于商业银行信用风险、商业银行信用风险影响因素以及商业银行信用风险防控等方面的研究;第三部分介绍了数据来源及基本分析;第四部分建立基于XGBoost 模型的银行信贷高风险客户识别模型并进行实证分析,通过分箱后的得分结果识别信贷高风险客户;第五部分总结了本文的主要研究结论,并提出相应的政策建议。
二、文献综述
(一)商业银行信用风险研究
信用风险又称违约风险,主要是指借款人、证券发行人或交易对手由于各种原因,不愿意或者没有能力履行合同条件而做出了违约行为,从而使银行、投资者或交易对手存在遭受损失的可能性。《巴塞尔新资本协议》中明确提到,银行业面临的主要风险有信用风险、市场风险、操作风险、流动性风险、利率风险、法律风险、声誉风险、国家风险和转移风险共9 类,其中,信用风险是最关键、最复杂的风险,约占银行总体风险的60%。因此,信用风险控制的好坏决定了银行盈利水平的高低,并对银行业长期稳定发展有着至关重要的影响。早期,商业银行往往将信用风险等同于信贷风险,而实际上信贷风险只是信用风险的重要组成部分。随着商业银行业务的演变与发展,信用风险不仅仅出现在贷款中,也发生在担保、承兑和证券投资等表内、表外业务中。商业银行主营存贷款业务,信贷风险一直是商业银行信用风险管理的主要对象,因此,学者们通常认为狭义的信用风险就是指商业银行贷款业务所面临的信用风险,即信贷风险。本文所指的信用风险主要是狭义信用风险。
(二)商业银行信用风险影响因素研究
学者们关于商业银行信用风险影响因素的相关研究主要分为内因和外因两个方面。其中,内因主要是指客户的基本信息,如年龄、性别、受教育程度、月收入等,而外因包括了行业发展、国家政策等宏观因素。
内因方面,Copestake(2007)指出贷款申请者的年龄和性别将会影响客户信用;Vandell and Thibodeau(2010)研究发现,客户基本信息中的职业、从业年限、是否结婚对客户信用风险有显著影响。国内学者在商业银行信用风险领域起步较晚,但也颇有成果,王颖等(2012)认为影响商业银行客户违约概率的主要因素包括个人基本特征、还贷能力、信用记录等多个方面;方匡南等(2014)将客户内因精细化,并发现具有高中学历、年龄小于25 岁、未婚、初级职称等特征的客户违约概率较大;吴金旺和顾洲一(2018)指出影响客户信贷风险最主要的5 个因素分别为合同期限、银行服务年数、贷前6 个月月均贷方发生额、贷记卡最近6 个月平均使用额度以及贷款最近6 个月平均应还款。
外因方面,Salas and Saurina(2002)指出宏观经济政策会对商业银行信贷风险产生影响,同时GDP 增长也会对银行贷款损失产生重要影响;Hassan et al.(2019)研究发现,流动性风险会影响信贷风险,并呈现负相关。邱兆祥和刘远亮(2011)研究了宏观因素对商业银行信用风险的影响,结果表明:GDP 增长率、通货膨胀率以及货币供应增长率均对商业银行信用风险产生了影响;周南和黎灵芝(2015)分别从存款流失、资金成本上升,以及缩紧货币政策等方面分析它们对商业银行信用配置体系所产生的影响。
(三)商业银行信用风险防控研究
国内外商业银行信用风险贷前评估技术的发展历程大致可以分为三个阶段:比例分析法、统计分析法以及人工智能,即从主观定性分析走向客观定量分析(侯春霞,2018)。在比例分析法阶段,信用风险评估方法将商业银行的信用风险与贷款企业“是否发生违约行为”等同起来,采用所谓的“经济主义方法论”。其基本思想是,通过研究并挖掘“违约类”企业样本和“非违约类”企业样本的特征,建立判别公式,进而对新样本进行分类。这一阶段出现的信用风险评估方法主要包括“5C”“5W”或者“5P”要素分析法、杜邦财务分析体系和沃尔比重评分法等。但是,无论上述哪一种方法,本质上都大同小异,它们的共同之处都是对每一个要素逐一评分,对信用指标进行量化,从而确定每一名客户的信用等级。该信用等级被作为是否向客户贷款、贷款的标准和贷后跟踪监测期间的政策调整依据(陈诚高,2006)。在统计分析法阶段,Altman(1968)提出Z 计分模型,以制造业财务比率为基础来衡量信用风险,并且Altman and Saunders(1997)在Z 计分模型的基础上提出了ZETA 信用风险模型,这两个模型是当时众多信用风险评估方法和模型中最为经典的。针对以上两类经典的信用风险模型,学者们也给出了很多关于数理方面的具体方法,如判别分析法、Logistic 回归分析法(陈诚高,2006)。统计分析法克服了比例分析法的缺陷,但是自身存在着不足,例如,统计分析法对数据分布要求严格,通常要求数据集符合某种假设,而现实生活中所收集的数据往往是多变的,无法满足特定的分布要求。
随着银行信贷业务的快速增长以及客户信用信息爆炸式的发展,形成了复杂的数据资源,这也使得传统的信用风险评估需要作出改进。随着信息技术的发展以及数据量的飞速增长,人工智能方法被引入到信用风险评估中。Hashemi et al.(1998)采用神经网络和粗糙集理论对银行信用风险进行预测并得到了较好改进;Ferreira et al.(2019)对消费者信用风险体系进行优化,并利用集成方法得到价值信息;杨保安和季海(2001)设计了BP 神经网络模型决策工具,通过实验设计表明该方法的优越性。但是,随着人工智能技术的不断发展,上述方法在预测精度和准确性等指标方面还有待进一步提高。因此,本文将XGBoost 模型引入商业银行信用风险评估领域,以提高预测精度和准确性。
三、数据来源及分析
(一)数据来源
本文所使用的数据集来源于我国Y 商业银行的信贷机构,共计20000 笔客户的借款记录,经过数据预处理,剔除部分存在严重缺失的客户信息,剩余有效样本数据共计14073 条,其中,发生违约的借款200 笔,占比约为1.4%。本次样本数据集中共有21 个变量,包括20 个表示客户本身属性的变量和1 个表示客户是否违约的结果变量,变量名如表1所示。同时,对部分变量进行衍生,变量“客户的主担保方式”包含抵押担保类型、保证担保类型、信用担保类型、质押担保类型共4 种类型,采用One-hot 方式生产4 个哑变量。

表1 数据集中各变量的名称及含义
(二)变量之间相关性分析
分析变量之间的相关性,图1是相关性最高的7 个自变量与目标变量之间的相关系数矩阵热力图。①其中,X1~X7分别表示担保方式为保证担保类型虚拟变量、最近6 个月平均应还款、贷记卡最近6 个月平均使用额度、融资银行家数、担保方式为保证质押类型虚拟变量、贷前6 个月月均贷方发生笔数、贷前6 个月月均贷方发生额。第一行是被解释变量Y 与其他变量之间的相关系数,观察第一行数据可知,其他变量与被解释变量之间的相关性很低,相关系数绝对值最大不超过9%,这可能暗示建模的效果不会很好。解释变量之间的相关性也不大,因此可以不考虑变量的共线性问题。
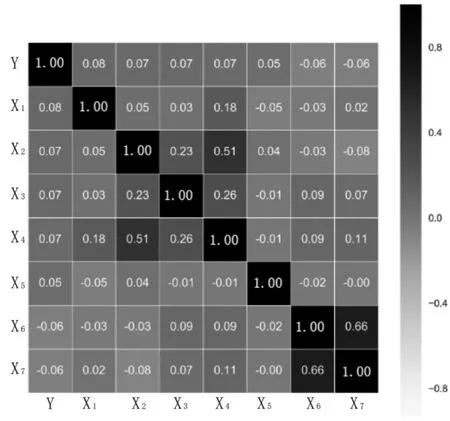
图1 相关系数矩阵热力图
四、基于XGBoost 模型的银行信贷高风险客户识别模型
(一)理论模型
1.SMOTE 算法
Chawla et al.(2011)提出合成少数类过取样算法,即SMOTE 算法。该算法主要利用少数样本生成人造样本来平衡原数据集中的非平衡状况,有效改善了由传统过抽样方法所引起的分类过拟合现象。假设数据量偏向于少数类别Mmin中的每一个样本Xi∈Mmin,搜索k 个最近邻点,其中,近邻点可以根据距离或者相似系数来进行选择。从k 个最近邻点中,随机选择一个样本点Yj。计算Xi与Yj所对应的特征向量的差值,并产生一个在区间(0,1)之间的随机数γ,最后合成一个少数类的人造样本Xs:

如果向上采样的倍率为N,那么在k 个最近邻点中随机选择N 个样本点,即j=1,2,3,…,n。重复上述操作步骤,直到所有的少数类样本都被处理好为止。
2.XGBoost 原理
XGBoost 由Chen and He(2015)提出,是一种Boosting 型的树类算法。该算法是在梯度提升决策树(GBDT)基础上扩展而来的,能够进行多线程并行计算,通过每一次的迭代生成新的树,即可将很多分类性能较低的弱学习器组合提升为一个准确率较高的强学习器。相比于传统GBDT 算法只利用了一阶导数的信息,XGBoost 在优化时作出了更好的改进,通过采用二阶泰勒公式对损失函数进行展开,即在保留一阶导数信息的基础上加入了二阶导数的信息,这样可以使得模型在训练集上更快地收敛,提高计算最优解的实际效率。不仅如此,XGBoost 为了平衡与控制模型的复杂程度,将正则项引入到损失函数中,从而避免模型出现过拟合的现象。综上,XGBoost 具有运行速度快、分类效果好、支持自定义损失函数等优点。具体算法步骤如下:
第一步,优化目标。假设模型具有k 个决策树,即:

式(2)中,xi是第i 个输入样本;yi为经过映射关系fk计算得出的预测值;F 为所有映射关系的集合。优化目标及损失函数为:

式(3)中,L(t)为第t 次迭代时的目标函数,n 为样本数量,l 为损失函数,(t-1)i为第t-1 次迭代时模型的预测值,ft(xi)为新加入的函数,Ω(ft)为正则项。
第二步,对式(3)进行二阶泰勒展开和移除常数项操作后可得:

式(4)中,di为l 对(t-1)i的一阶导数;gi为对(t-1)i的二阶导数,N 为叶子节点个数,Ij为每个叶子节点上的样本集合,w2j为每个叶子节点分数的L2模平方,λ 和γ则为比重系数,防止产生过拟合现象。
(二)实证分析
根据已有的行业经验将整个样本数据集划分为训练集和测试集,其中,训练集为原样本数据集80%的体量,测试集则为原样本数据集中剩余的20%。
1.基于SMOTE 算法的非平衡数据处理
在收集的样本数据中,存在违约现象的客户数据为200 个(约占样本数据集的1.4%),非违约客户数据为13873 个(约占样本数据集的98.6%),属于典型的非平衡数据。由于该问题属于类别严重失衡的二分类问题,传统的数据挖掘算法在处理这类数据时偏向于数据量偏大的一类,对数据量偏少的类别关注比较少(柳向东和李凤,2016)。在银行信贷业务领域中,这类数据问题比较常见,需要采用SMOTE 方法增加训练集上坏客户比例,本文采用上采样方式提高坏客户的比例,使训练集上好坏客户比例达到7∶3,并在后期训练XGBoost 模型得到了最优效果。
2.构建申请评分模型
在已处理的训练集②上构建XGBoost 模型,并且通过不断调整模型分类的参数,训练得到最优的XGBoost 模型。由图2可知,该模型在训练集和测试集上AUC 值分别高达0.97 和0.93,③充分说明了分类效果的优越性。
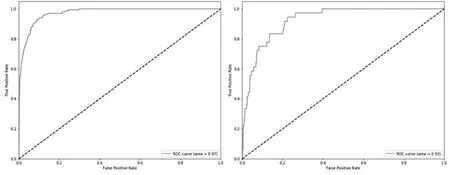
图2 训练集和测试集上的AUC 值
对于类别失衡问题,在评价模型预测效果时往往会采用准确率、召回率或F1值,但是其参考意义不是很大,因为大部分样本预测出的概率通常很低。本文创新性地采用样本得分分箱的方式,观察在每个分箱区间模型的召回率,表2和表3分别表示在训练集和测试集上累计召回率统计。

表2 模型在训练集上累计召回率表现
比较表2和表3,可以发现XGBoost 模型在训练集上的表现要优于在测试集上的表现,在训练集上,分数最高的5%客户可以召回78.66%的坏客户,而在测试集上分数最高的5%客户可以召回55.60%的坏客户。根据模型在测试集上的表现,我们可以根据模型得分选择得分最高的10%客户对其进行严格的资格审查,评估其违约风险大小,这部分客户需要重点审查,而对于得分最低的20%至30%客户,信用条件较好,可以对其适当放宽条件,提高授信额度。
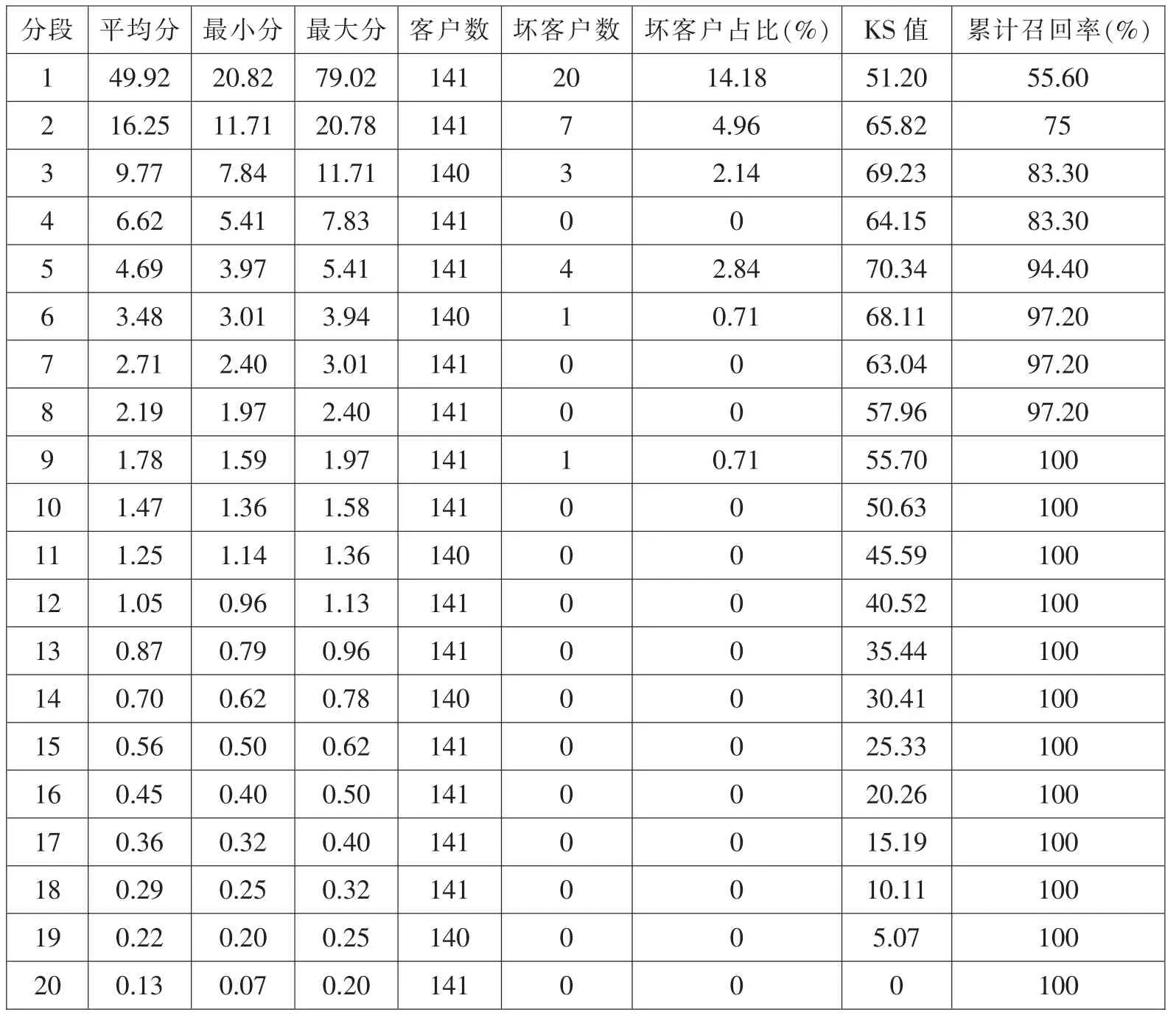
表3 模型在测试集上累计召回率表现
综上,本文采用XGBoost 模型对我国Y 商业银行信贷客户的违约风险进行建模,并利用建立的申请评分模型对新客户的违约风险进行评估,以达到提前识别违约客户、降低银行资产风险的目的。在建模的方法上,依次采用了特征工程(利用现有变量衍生新的自变量)、样本平衡化处理、网格搜索调参以及模型效果的分箱评估。模型的结果表明,在训练集和测试集上得分(模型预测为坏客户的概率)最高的5%客户可以分别覆盖78.66%和55.60%的坏客户,可以对不同得分的客户采取不同的风险措施。例如,对于得分最高的一批客户必须进行严格的风控审批或者降低客户授信额度,必要时可以直接拒绝客户的贷款申请。模型结果表明,得分最低的一批客户的违约概率几乎为0,说明对低风险客户可以采取放宽信贷条件或者提高授信额度等措施,以便最大限度地吸引新客户、增加客户的体验效果。
本研究仍存在一些不足,如在训练集和测试集上的效果有明显差异,测试集上的模型结果比训练集差;在训练集和测试集上模型得分分箱后分数段也存在较大的差异,主要原因是样本量不够多,入模的特征也比较少,这导致模型的训练效果不是很好,本文主要提供一种利用AI 技术在金融风控建模中实际应用的思路。
五、政策建议
当前,对银行信贷风险的研究多集中在经济金融形势、产业政策等宏观层面,随着商业银行业务互联网化程度越来越高,能接触和收集的数据也越来越多,数据的价值日益凸显。本文在微观层面,以银行大数据为基础,利用XGBoost 模型对我国Y银行的信贷数据构建客户申请评分模型,通过该模型对新客户的违约概率进行预测,然后在训练集和测试集上对模型得分进行分箱,并计算在每个分数段坏客户的累计召回率,最后对模型的预测效果进行评价。根据本文的研究结论,提出以下四点政策建议:
第一,严格把控得分较高的客户群体,降低该类客户授信额度。商业银行相关部门可基于客户申请评分模型的分箱结果进行客户群体的信用评级,原则上模型结果显示得分较高的客户群体需要有关部门跟进处理,并在科学研究之后再做风控审批;同时,为了降低风险的发生率及连带效应,银行从业人员可以根据评分直接降低该类群体的授信额度,必要时采取“一人一策”的方法,直接拒绝特殊客户,从而做好风险控制工作。
第二,放宽低分客户群体的信贷条件或提高授信额度。低分客户群体是当前经济环境下商业银行的潜在优质客户,商业银行有关部门应在原风控体系下,深度挖掘该类客户的特征,做好用户画像,进一步优化原有风控体系,更好地吸引该类新客户、增加客户的体验效果。
第三,加强对评分居中客户的创新放贷。低得分和高得分的信用评级为银行信贷风控提供了有力的技术支持,但是,当前市场中仍然存在一部分得分居中,信用良好的客户,因此,如何在原有的客户群体中科学、客观地挖掘出此类客户是值得深入研究的。商业银行有关部门应该加快部门间数据的互联互通,建立信息共享机制,聘用高素质的数据挖掘、数据分析、风险控制管理等专业技术人才,更好地应用机器学习、深度学习等大数据技术,从而形成一套可行性强的放贷机制,为商业银行实现精准放贷、业务精细发展以及风险管理提供支撑。
第四,加强信用立法,建立联合惩戒机制,加强对客户的自律教育。国家有关部门需加强信用立法,完善信用法律体系,以便进一步约束老客户以及新客户的信用违约行为,以便引导客户个体保持良好的信用记录;同时,需尽快发布惩罚机制,提高客户主观上对个人信用的重视程度。此外,商业银行相关部门可以在做好风险控制工作之前,开展科普性自律教育,使客户个体对自身的行为有一个清楚的认知,从而减少其违约行为。
注释:
①若对所有变量之间的相关系数矩阵热力图有需要,可单独与作者联系(guzhouyi1991@163.com)。
②通过上采样方式处理。
③AUC 越大,说明该分类器分类效果越好。
猜你喜欢
化工管理(2022年13期)2022-12-02
数学年刊A辑(中文版)(2020年2期)2020-07-25
大众投资指南(2020年10期)2020-07-24
数学物理学报(2019年6期)2020-01-13
唐山师范学院学报(2018年6期)2018-12-25
消费导刊(2017年20期)2018-01-03
当代经济(2016年26期)2016-06-15
新疆财经大学学报(2015年3期)2015-12-10
当代经济(2015年4期)2015-04-16
现代企业(2015年6期)2015-02-28
