
近红外技术在玉米品质检测中的应用
2020-05-06 02:50王明张倩
食品工业 2020年4期
王明,张倩*
北京市农林科学院农业信息与经济研究所(北京 100097)
玉米是我国第一大粮食作物,兼用经济作物和饲料作物,其种植面积和产量在各个主要粮食作物中居于首位,玉米种植效益较其他粮食作物中相对较高,是多个省市的农作物种植农户的主要收入来源,因此玉米在我国粮食及饲料供应中具有重要地位。提高玉米种植自动化程度,对进一步减少生产成本、提高产量、促进经济效益具有重大意义。
在玉米生产、储藏、流通、育种等过程中,准确检测玉米各项指标是保证各环节质量的关键步骤。目前在生产现场,玉米检测还是以化学分析方法为主,虽然检测精度较高,但也存在着明显的弊端,如会破坏玉米活性,检测样本不能回收利用,化学试剂会造成环境污染,并且试剂与玉米样品需要充分的反应时间,耗时耗力。近红外光谱分析法因其快速、准确、高效、绿色等[1-5]优点在粮食[6-9]、肉制品[10]、乳制品[11]、医药[12-14]等无损检测中开展了广泛的应用,受到了广大学者的青睐。在玉米品质检测中,国外起步较早,从90世纪60年代Norris等[15]就利用近红外技术测定谷物中的水分、蛋白质等物质含量。近年来,我国在玉米杂交纯度检测[16]、单倍体鉴别[17-18]、品种鉴定[19-21]、水分[22-23]、蛋白质[24]、淀粉[25-26]和脂肪[27-28]检测中已经开展了广泛的应用,并且取得了较大的进展[29-33]。
近红外光谱体现的是含氢基团倍频和合频的吸收[34-35],记录了丰富的结构、组成、属性等信息,因此理论上能检测出大多数成分含量。高分辨率的光谱仪能获取更多的光谱数据,大大提高了校正模型稳定性和预测精度[36],同时,近红外吸收波段重叠严重,存在数据冗余现象,对数据处理能力要求较高,如何分辨有效波段、剔除干扰信息、选择校正算法直接影响检测结果[37]。
1 近红外技术的分析方法
近红外光(NIR,波长介于780~2 526 nm)分为短波近红外(波长780~1 100 nm)与长波近红外(波长1 100~2 526 nm),短波近红外因其透射能力较强常用于液态农产品的品质检测,长波近红外则常用于反射分析,多用于固体样品的测量。近红外光谱信息记录的是含氢基团X—H(C—H、O—H、N—H等)的吸收特性,涵盖了大量的结构和组成信息,因此含有这些基团的成分可通过化学计量方法建立关系模型,用于样本的定性或定量分析[38]。
在光谱分析过程中,一般步骤分为样品收集、光谱数据预处理、波段及特征值选择、建立校正模型及模型评价[39-41],主要分析步骤如图1所示。
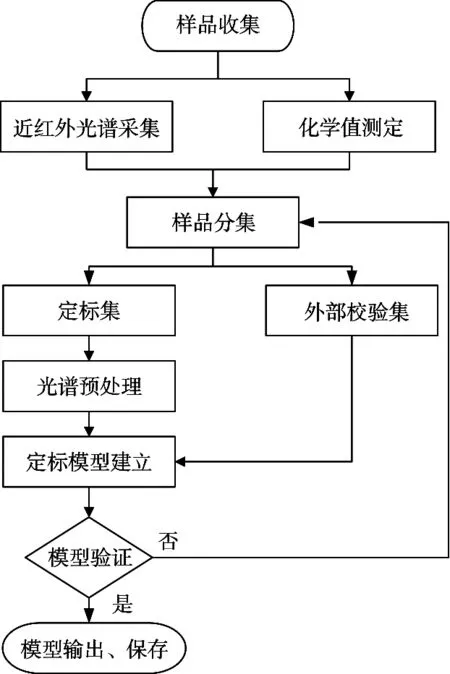
图1 近红外光谱技术分析步骤
1) 收集玉米样品,尽可能多地覆盖多个品种,使成分含量范围广,浓度分布均匀,保证样品具有较好的代表性,提高校正模型的稳健性,并用化学方法测定其含量作为参考值,用近红外光谱仪采集每个样品的近红外光谱,按照3∶1比例划分为校正集和预测集。
2) 光谱数据预处理,基线漂移、高频噪声、散射现象等会降低信噪比,影响预测精度,因此需要减小各干扰因素对光谱信息提取的影响,减弱甚至消除各种非目标因素对光谱信息的影响。常用预处理方法包括高频噪声滤除、代数运算、多元散射校正(MSC)、基线校正、微分等。
3) 选择波段及特征值,近红外光谱图会出现吸收不明显、重叠严重等问题,包含了冗余信息,因此建模时需要剔除不相关信息,筛选出相关性高的自变量[42]。常用方法有逐步回归、遗传算法(GA)、无信息变量消除(UVE)、蒙特卡罗(MCS)算法等。
4) 建立校正模型,采用线性和非线性方式建立样品近红外光谱与待测指标的校正模型,用来进行定性或者定量分析。其中常用线性建模方法包括主成分回归、偏最小二乘回归和多元线性回归;常见非线性回归校正模型如区域权重回归和人工神经网络(ANN)。
5) 模型评价,最后对建立的模型的稳定性和准确性进行评价,筛选优质校正模型。常用的指标有相关系数、校正集样品标准偏差、预测集样品标准偏差。
2 近红外在玉米检测中的应用进展
2.1 玉米杂交纯度检测
玉米种子好坏直接影响到粮食产量,提高杂交种玉米纯度能极大地促进粮食生产,带来更大的经济效益,目前玉米纯度鉴定采用人工鉴定、分子标定等方法,相比于近红外光谱分析手段,它们成本高昂,且需要专业的技术人员来操作。
赵盛毅等[43]选取农华101和对应的母本作为试验样品,采用MicroNIR 1700光谱仪和Matlab 2012a数据处理软件软件,研究近红外光源电压强度以及距离对杂交纯度预测精度的影响,采用导数和归一化进行数据预处理,用PCA及OLDA算法筛选建模波段,最后用支持向量机建立纯度预测模型,统计6组不同条件下的识别率,试验结果表明电压增大或者光源与样品距离缩小都会提高光谱分辨率,从而提高预测模型精度。
唐金亚等[44]进行了基于近红外技术的玉米种子纯度检测研究,选取了2个不同年份和不同品种一共640粒种子作为研究对象,试验过程中采用主动学习算法选择建模样本,并与基于随机选择算法和Kennard- Stone算法模型结果进行比较,结果表明在3种不同样本集划分比例下利用主动学习算法整体预测精度能提高40%以上,并且也提高了对旧样本预测精度的可靠性,模型更新效果明显优于RS和KS。
冉航等[45]研究利用近红外光谱分析玉米杂交纯度,提取玉米样品近红外透射光谱和反射光谱信息,采用中值滤波、大津法过滤噪声,筛选特征数据并使用降维算法进一步筛选特征信号,最后使用支持向量机建立基于两种光谱的纯度预测模型,结果显示平均鉴别准确率都达到85%以上,表明近红外光谱技术在鉴定玉米纯度上是可行的。
2.2 单倍体鉴别
单倍体育种技术能有效缩短产生纯合系的周期,显著提高育种率,因其快速、方便、准确的特点受到了专家学者的重视,由于自然产生率不高,一般低于0.1%,并且使用人工诱导技术也不会超过10%,因此快速、准确识别单倍体对提高育种技术显得非常关键,近红外在单倍体鉴别中也开展了一定的研究。
Qin等[46]研究了适合单倍体玉米粒鉴定的光谱测量模式,采用了漫反射和漫透射分别采集单倍体和二倍体玉米籽粒的近红外光谱,并建立校验模型,比较两种方式下的准确度,在漫反射模式下识别率小于60%,而采用漫透射则平均识别率可达到93.2%,并且预测稳定性较好,说明在漫反射方式下光谱与样品接触更加充分,更能代表样品内部结构信息。
李浩光等[47]提出了采用近红外技术对玉米籽粒油进行单倍体和多倍体的定性分类,即采用近红外技术间接地对玉米籽粒进行单倍体鉴定,结果表明在准确度方面近红外分析与核磁共振分析方法相当,在训练集相同时,近红外分析方法相比其他定性鉴别方法准确度较高,为近红外对玉米籽粒单倍体的鉴定提供了新的解决思路。
李伟等[48]采集三组遗传背景不同的玉米籽粒单倍体与二倍体样品光谱,用多种机器学习算法建立校正模型,对比建模方式、样品选取对结构的影响,结果表明采用偏最小二乘和神经网络预测鉴别单倍体准确率较高,为93.26%和95.42%,大数据集建模能提高模型预测精度,并且根据籽粒颜色标记挑选出的单倍体和二倍体,基于偏最小二乘构建的机器学习模型预测精度可达到93.39%,说明基于机器学习的NIR单倍体鉴定效果较好,为自动化、智能化鉴别提供了很好的基础研究。
2.3 品种鉴定
目前玉米品种鉴定还是以形态学分析、DNA图谱分析为主[49-50],但是都存在成本高昂、技术要求较高的弊端,近红外因其独特的技术优势在玉米品种鉴定中也展开了一系列的探索。
贾仕强等[51]研究了近红外反射和透射方式对玉米品种识别率的影响,从而判断玉米籽真实性,采用判别式偏最小二乘提取光谱特征并降低维数,选取9个因子建立仿生模式识别模型,结果表明样品放置位置以及采用建模波段的选取都对预测结果影响较大,最优预测模型对品种玉米籽平均识别率达到94.6%以上,为玉米籽品种鉴定提供了很好的思路。
李浩光等[52]针对玉米种衣剂对品种识别率的影响问题,研究了基于栈式自编码神经网络(SAE)的NIR模型分析方法,选用无种衣剂的玉米籽作为建模训练集,建立的模型用来预测有种剂样品,试验结果表明采用SAE建模能有效识别玉米籽,能将其对准确率的影响控制在3%以内,说明基于机器学习算法较传统近红外建模算法有较大优势,提供了新的解决思路。
2.4 成分检测
玉米主要成分包括水、蛋白质、淀粉和脂肪等,含量高低直接影响产品价格及市场定位,其中玉米粒水分含量对贮藏和育种非常关键,需要考虑水分过多引起发霉和水分过少影响种子活力的问题,玉米粒水分往往控制在13%以下,快速检测玉米粒水分含量是把控玉米种子质量好坏的重要环节。因此能快速、准确检测各成分含量对了解玉米品质十分重要。
李晋华等[53]利用短波段近红外漫透射原理设计了短波近红外品质检测仪,获取了38组玉米样品光谱,用多元散射校正进行光谱预处理,并采用偏最小二乘对其主要成分水、蛋白质、淀粉和脂肪建立定量分析模型,预测结果的相关系数分别为0.922 4,0.942 8,0.912 8和0.995 6,总体误差在±0.5%以内,预测精度较好。
姚鑫淼等[54]收集了多个省份一共368份玉米样品,通过短波近红外建立了基于黄色和混合样品的神经网络预测模型,预测平均残差为0.15,0.05和1.04,均方误差分别为1.06,1.07和1.12,说明玉米粒外观颜色对预测模型的预测精度影响较大。
田喜等[55]通过波段比和阈值相互结合,提取了经过处理的300粒郑单958玉米样本的长波段光谱,用化学方法标定样本水分含量,研究了水分含量与胚区域光谱关系,采用多种算法筛选出吸收波段,并建立偏最小二乘预测模型,试验表明光谱吸收与水分含量呈现正相关,基于胚结构的光谱建立的CARS、GA及SPA波段筛选的偏最小二乘模型预测相关系数Rp为0.931 2,0.917 6和0.922 7,对应的RMSEP分别为0.315 3,0.336 9和0.336 6,在减少了49,12和24个特征波段的前提下,精度与全外表面光谱信息建模结果无明显差别,说明扫描玉米胚结构的近红外光谱对检测水分含量效率更高。
沈广辉等[56]搜集全国各省份171个玉米籽粒作为研究对象,以自行研制的近红外光谱扫描仪为基础,获取玉米样品的近红外光谱图,采用CARS筛选出特征变量,采用偏最小二乘建立玉米籽粒中水分、蛋白质、粗灰分和脂肪的校正模型,预测集相关系数分别为0.76,0.89,0.72和0.83,相对分析误差对应为2.41,3.04,1.80和2.42,为近红外光谱快速分析玉米粒成分含量提供了可行性。
常冬等[57]选取了来自多个省份的116个玉米品种作为研究对象,选用MPA型多功能近红外光谱仪获取样品光谱,分别对不做处理和粉碎0.5 mm两种状态下的玉米样品建立了淀粉预测的近红外预测模型,并将两种结果进行了对比,得出粉碎前后的相关系数分别为0.983和0.988,说明粉碎后样品与近红外反应更充分,吸收特性更好,预测精度也会有一定程度的提升。
吴晗等[58]采集了210份玉米样本的近红外光谱,采用不同的散射方式对光谱进行预处理,并且用不同的回归分析算法建立玉米直链淀粉的预测模型,对比结果表明采用SNV和Dtrend的散射处理,改进的偏最小二乘回归算法建模准确度最高,其交叉验证误差是1.465,定标决定系数是0.963,建立的定标模型有较好的预测能力。
杨泉女等[59]利用近红外光谱技术对104份甜玉米进行了葡萄糖、果糖、蔗糖含量的测定,分别对不同的测量目标采用了不同的预处理方式,统一采用偏最小二乘法建立校正模型,得出最优校正模型的交叉验证标准差分别为0.321,0.275和1.508,外部验证预测相关系数分别为0.593,0.780和0.891,其中果糖、蔗糖预测效果较好,为甜玉米品种选育提供了可行性方案。
3 总结和展望
3.1 问题总结
从以上国内外研究可以看出,近红外技术在玉米种子纯度检测、育种、品种识别、成分分析等中取得了较大的进展,但是也存在着一些共性问题:
1) 检测环境(外界温度、湿度、光谱仪零部件、种类等)的不同导致采集到的光谱存在一定的差异,直接影响校正模型精度,并且光谱数据兼容性不好,不能互相移植。
2) 样品的选取影响校正模型的可靠性和适应性,样本选取代表性不强,浓度范围覆盖不够宽,并且样品的颜色、状态差异导致获取到的近红外光谱差异较大,导致模型的适应性不好。
3) 不同的预处理方式对模型预测结果影响比较大,目前还未找到统一或者标准的预处理方式,在数据处理中往往需要针对不同的组分进行预处理。
4) 随着光谱仪技术的不断发展,获取到的近红外光谱分辨率也会随之提高,但同时也会加载大量冗余信息,计算压力增大,如何提取有用的特征波段和特征值、剔除无关信息也是亟待解决的问题。
5) 针对玉米检测建立的校正模型的稳健性、传递性[60]仍然需要进一步提升,不同的仪器没有行业统一规范,预测不同的品种时效果较差,需要针对特定的预测品种单独建模,阻碍了近红外光谱仪规模化、产业化发展。
3.2 研究展望
鉴于近红外光谱技术在玉米检测中的发展现状和出现的各种问题,提出了以下几个方面的展望,以期近红外光谱技术能真正地走向生产现场。
光谱仪生产行业需要统一规范,制定通用标准,从硬件和软件上打通跨仪器的障碍,提供开发的数据接口,以增加模型的传递性;需要建立不同地区、不同品种的玉米近红外光谱数据库,扩大建模样品覆盖面,包括不同种植年份、品种、种植地区等,提高玉米的预测范围和准确度;与人工智能技术相结合,通过深度机器学习优选波段及特征值,自动过滤掉无关信息,不需要人工进行筛选,建立最优模型,以提高玉米品质检测模型的稳健性、连续性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
山西农业科学(2020年8期)2020-08-13
国学(2020年1期)2020-06-29
数学物理学报(2017年6期)2018-01-22
河南农业科学(2018年5期)2018-01-19
摄影之友(影像视觉)(2017年1期)2017-07-18
中国光学(2015年5期)2015-12-09
中国学术期刊文摘(2015年8期)2015-10-29
西北农林科技大学学报(自然科学版)(2015年5期)2015-02-21
食品工业科技(2014年23期)2014-03-11
