
基于深度可分离卷积的地铁隧道巡检视频分析*
2020-05-04 06:54孙明华李渊博
计算机工程与科学 2020年4期
孙明华,杨 媛,李渊博
(西安理工大学自动化与信息工程学院,陕西 西安 710048)
1 引言
地铁隧道内需要检测的对象主要包括轨道与隧道。相比于地面铁路巡检,地铁隧道内的环境固定、异物入侵概率较低,同时可见度较低,需要靠隧道壁两侧的LED灯提供照明。国内外提出了很多自动铁路异常检测和隧道评估的方法:Rodriguez等人[1]提出了一种使用霍夫变换完成轨道内异物检测的系统,该系统通过摄像机采集图像能够实时地检测障碍物,并且在发现异物时能够发出警报;Gibert 等人[2]使用计算机视觉和模式识别方法完成对轨道的自动检查,该方法通过在多任务学习框架内组合多个检测器,能够更准确地检测铁路枕木和轨道扣件上的缺陷。但是,传统图像特征提取的方法容易受到场景和光线的影响,无法满足智能分析的需要。而深度学习凭借着其针对特定问题自动构建最合适特征的优势,在图像分析领域相对于传统图像处理方法有着巨大优势。
将深度学习技术应用于自动化异常检测已经成为一种趋势。Xu等人[3]提出了一种基于深度学习的方法来识别铁路路基探测数据的探地雷达剖面缺陷,通过识别各种缺陷类型的比较实验证明了该方法的鲁棒性。Santur等人[4]利用3D激光相机和深度学习的方法,提出了一种用于铁路表面检测的软硬件架构,其中3D激光相机能够快速检测铁路表面和横向的缺陷,而深度学习具有极高的特征表达能力。Zhang等人[5]提出了一种基于卷积神经网络和多声发射事件概率分析的铁路轨道状况监测的方法,该方法消除了一次性分类引起的检测误差,提高了分类精度。Makantasis等人[6]提出了一种基于深度学习的全自动隧道评估方法。该方法使用单个单目相机采集原始输入信息,利用卷积神经网络构建高级特征,结果显示了深度学习架构对隧道缺陷检测问题的适用性。Protopapadakis等人[7]提出了一种用于隧道评估的机器人自动检查方法,使用卷积神经网络完成视觉检查。整个系统已经在铁路和公路隧道中进行试用,显示了检查自动化领域研究的活跃性。
自2012年以来,深度学习技术飞速发展,卷积神经网络模型也不断推陈出新。从最初的AlexNet[8]到VGG[9],从GoogleNET[10]到ResNet[11]。网络模型的结构也从单分支演变为多分支,层数不断加深,计算量不断增加,特征提取能力不断加强。
网络层数的加深虽然使网络的性能得到了提高,但是同时也带来了效率问题:网络模型的大小与单幅图像的处理速度。对于效率问题,通常的提升方法是进行模型压缩(Model Compression),即对已经训练好的网络模型进行压缩,使得网络携带更少的参数,从而改善模型大小以及处理速度,但是这种方法会对网络模型的准确率造成影响。相比于对训练后保存的模型进行处理,轻量化模型的设计另辟蹊径。轻量化网络模型也具有各种不同的架构设计,如使用fire module 的SqueezeNet[12]、使用深度可分离卷积的MobileNet_v1[13]与MobileNet_v2[14]、使用分组卷积和通道混洗的ShuffleNet[15]。这类网络模型的主要思想在于使用更高效的计算方式(主要是改进卷积方式),从而在减少网络参数的同时保持网络的性能。
为了完成在地铁隧道环境中的实时异常检测,所构建的卷积神经网络需要在保证识别准确率的前提下缩减网络的参数量,加快网络的处理速度。即在控制卷积神经网络计算量的前提下,增强网络的特征提取能力。GoogleNet网络由多个inception结构堆叠而成,该网络的特征提取能力强但是计算量较大;而MobileNet网络的计算效率高但是网络的拓扑结构采用VGG的思想,特征提取能力较弱。并且2种网络中都使用了1×1卷积,因此将2种网络的优势互补成为了一种可行的选择,即使用深度可分离卷积对inception结构进行改进。
2 本文方法
地铁隧道巡检视频分析系统的工作流程如图1所示,其由2部分构成: 左半部分是对网络模型的训练与优化,其中还包括对数据集的划分和图像的预处理。本文通过设置不同的训练轮数EPOCHS、初始学习率INIT_LR、批大小BS等超参数对SubwayNet网络模型进行多次训练,记录实验结果。SubwayNet网络模型是使用改进后的inspection结构构成的轻量化网络。通过实验结果的对比不断调整各种超参数以获得更好的分类效果,从而完成网络模型的优化,保存实验中效果最优的网络模型参数供分析系统调用。右半部分则是分析系统。运行分析系统软件,自动读取待检测的视频并对视频中待分析的图像进行预处理;然后调用已保存的网络模型,将分析结果反馈到系统中;最后预测类别与置信度的分析结果会在系统界面中直观显示,并在发现异常时进行声音报警。

Figure 1 Workflow of video analysis system for subway tunnel inspection图1 地铁隧道巡检视频分析系统工作流程
2.1 地铁隧道巡检数据集的制作及预处理
本文所采用的地铁隧道视频均采集于地铁线路实景。制作数据集时首先使用Python中的OpenCV库将采集到的1080×1920的视频数据按照10帧的间隔频率提取图像。然后结合日常地铁运营检修中出现的异常情况将数据集分为正常、轨道内存在异物、隧道壁渗漏水、钢轨扣件螺丝紧固、钢轨扣件螺丝松动5大类。之后将对视频中提取到的图像进行人工判断分类,分别为Normal、Object、Water、Fasten、Loosen,作为Subway-5数据集,用于后续网络模型的训练和测试,训练和测试图像所占比例为8∶2。图2所示为5种不同类别的图像示例(方框为后期标注,真实数据无方框)。

Figure 2 Image samples of Subway-5 dataset图2 Subway-5数据集图像示例
在数据量有限的情况下,可能存在偏斜类的问题,即训练网络模型时不同样本的数目相差很大,最终对网络模型的泛化能力产生影响。在本数据集中表现为正常情况与钢轨扣件螺丝紧固情况类别的样本数远多于其余异常情况的样本数,如果不进行处理,那么训练后的网络模型即使将所有图像都判别为以上2类也能有较高的准确率,所以本文去除Normal、Fasten文件夹中差异不明显的图像。最终选定的每类图像的数目都为100幅,Subway-5数据集共有5类总计500幅图像。
数据集中的图像在用于训练和预测之前还需要对其进行预处理。本文主要采用以下3种预处理方法:
(1)图像尺寸的调整:将数据集中待输入网络模型的图像统一调整为320×320的尺寸,便于网络模型的训练和测试。
(2)数据的归一化处理:图像的像素为[0,255],采用对所有像素值除以255的方法将图像的原始像素值缩放到[0,1],加快网络模型使用梯度下降法求得最优解的速度。
(3)数据增强(Data Augmentation)[16]处理:本文在原始Subway-5数据集的基础上对图像进行剪切、缩放、随机旋转、随机偏移等处理。数据增强是一种常用的技术,有利于网络模型在小数据集上的训练,能够加速拟合或者充当正规化项,从而减少过拟合并增强网络模型的泛化能力。
预处理方法(1)和(2)在网络模型的训练和预测阶段都需要实行,而预处理方法(3)只在训练时使用,预测时不使用。
2.2 Subway_inception_v1结构设计
利用MobileNet_v1网络模型中使用的深度可分离卷积对inception结构进行改进,改进后的结构称为Subway_inception_v1结构,如图3所示。在inception结构的基础上使用卷积窗口大小为3×3的深度卷积 (Depthwise Conv)替换3×3标准卷积并在之后增加1×1标准卷积,而且inception结构中3×3卷积之前的1×1卷积操作具有降维和通道间特征融合的作用,在进行深度卷积操作之前就能够融合不同层间的特征信息,更好地缓解了深度可分离卷积带来的层间信息流通不畅的问题。
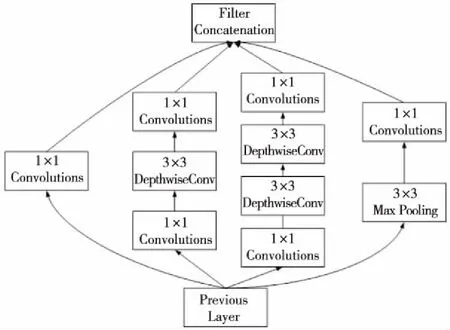
Figure 3 Subway_inception_v1 structure图3 Subway_inception_v1结构图
2.3 Subway_inception_v2结构设计
考虑到MobileNet_v2网络模型在 MobileNet_v1网络模型基础上做出的改进:在基本构建块中引入ResNet的skip connection跳跃连接结构,本文对Subway_inception_v1结构进行改进提出了Subway_inception_v2结构,如图4所示。Subway_inception_v2结构在深度可分离卷积的中间2个通路分支中引入跳跃连接。这种改进只增加了2个跳跃连接少量的相加运算,对总体结构的计算量无显著影响,却能够保留更多的之前层提取到的特征信息。
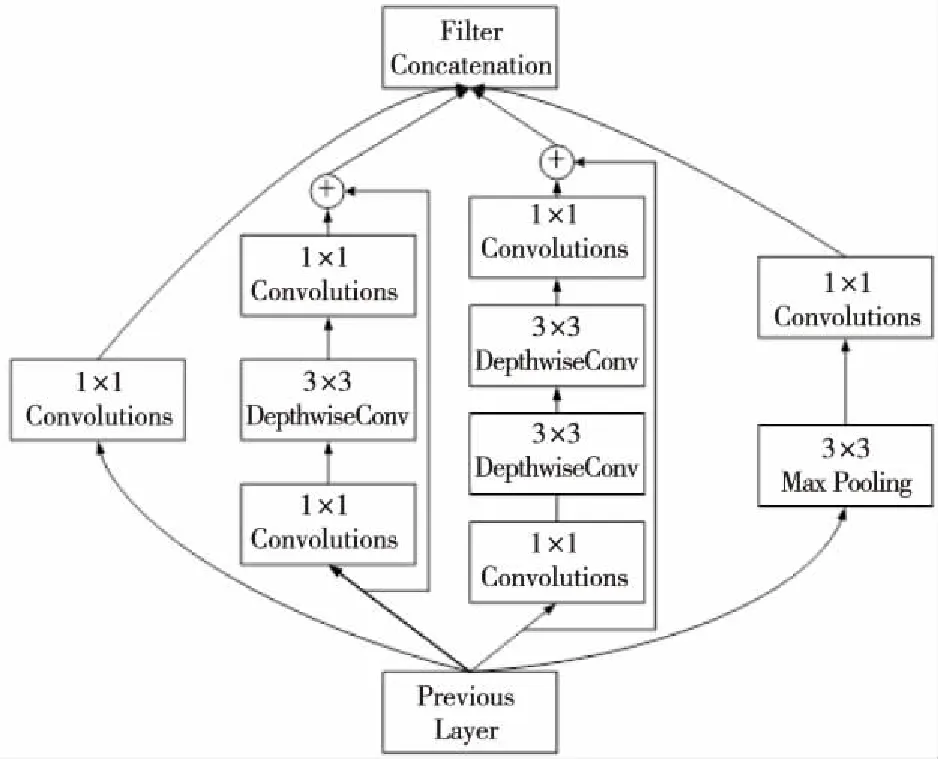
Figure 4 Subway_inception_v2 structure diagram图4 Subway_inception_v2结构图
2.4 SubwayNet网络模型设计

Figure 5 SubwayNet model图5 SubwayNet模型
本文使用提出的2种Subway_inception结构分别设计了2种对应的SubwayNet网络。如果直接使用较深的网络结构会出现梯度消失的问题,而层数太少则会导致分类准确率较低。SubwayNet_v1网络模型的核心是Subway_inception_v1结构,因此需要通过对比实验来确定其数量。对于卷积神经网络模型来说,通常层数越深,卷积核的数目越多,SubwayNet_v1网络模型也是如此,增加的每个Subway_inception_v1结构都有比上一个结构更多的卷积核个数。具有不同Subway_inception_v1结构数量的网络模型在Subway-5数据集上的分类准确率如表1所示。从表1中可以看出:当Subway_inception_v1结构数量为2,3时,准确率较低;当Subway_inception_v1结构数量为4时,准确率相比之前有显著提升,达到了94%;当Subway_inception_v1结构数量为5时,准确率相比Subway_inception_v1结构数量为4时提升了1%,但是参数量是之前的2.5倍。在准确率相近时需要对比模型的计算速度,在本文的神经网络模型中,Subway_inception_v1结构数量越少就意味着参数量越少,计算速度就越快,模型的复杂度越低。因此,出于对模型准确率和计算速度的综合考量,本文所构建的SubwayNet_v1网络模型具有4个Subway_inception_v1结构,如图5所示。

Table 1 Comparison of the number of different subway_inception_v1 structure表1 不同Subway_inception_v1结构数量的效果对比
由于Subway_inception_v2结构只是在Subway_inception_v1结构的基础上进行了部分改进,SubwayNet_v2与 SubwayNet_v1网络模型的结构完全相同,只是将所有Subway_inception_v1结构替换为Subway_inception_v2结构。
图5为本文提出的SubwayNet网络模型结构。输入是尺寸为320×320×3的图像,首先经过卷积窗口尺寸为7×7、步长为2的标准卷积(conv)操作进行初步的特征提取;然后通过窗口尺寸为3×3、步长为2的最大池化(Max Pooling)操作来减少数据量,保留有效特征;之后将得到的特征图按顺序依次输入到4个Subway_inception结构中进行多尺度的特征提取与多通道的特征融合;在全连接层(FC)之前添加了全局平均池化(Global Average Pooling)[17]操作AvgPooling,加入全局平均池化相比于直接使用全连接层,可在减少网络参数的同时降低过拟合的几率;最后经由Softmax分类器得到相关类别概率的输出。
2.5 图形用户界面设计
为了使网络模型检测结果的显示更加直观,方便人机交互,本文使用Pycharm软件中的Qt Designer工具制作了相应的图形用户界面。最终生成的图形用户界面包含:界面中间的视频显示区域,用于显示预测结果和可信度的Detect_Result窗口。open_camera为打开视频按钮,点击后系统开始加载保存的网络模型和待分析的地铁隧道巡检视频,加载完成后开始实时分析。close_camera为关闭视频按钮,点击后系统停止视频的播放与分析。
2.6 声音报警功能的添加与程序打包
原始的网络模型只能提供分类结果的显示,而在检测到异常状况时声音报警提示也十分重要。所以本文使用Python的第三方库pygame为系统添加了发现异常状况时声音报警的功能。当检测到视频中的图像类别为轨道内存在异物、隧道壁渗漏水、钢轨扣件螺丝松动时,分别播放3种不同的报警声音,便于提醒和区分。
由于所有的代码都使用Python语言编写,在运行时就需要通过命令行进行操作,这样会降低地铁隧道巡检视频分析系统应用的便利性。所以,本文使用Python的第三方库pyinstaller将所需文件打包生成Detector.exe可执行程序,便于其在电脑端移植使用。使用鼠标双击打开程序就会出现图形用户界面,点击open_camera按钮即可对视频进行分析,相比通过命令行进行操作,操作更为便捷和易用。
3 实验结果及分析
实验是在Ubuntu16.04版本的 Amax Sever 环境中进行的,Amax Sever包括2块Intel Xeon E5-2620V4 CPU、4块NVIDIA TESLA-K80 GPU。本文使用Keras深度学习框架设计网络模型。Keras使用Tensorflow和theano作为后端的高级封装库,相当于在二者基础上构建的高级API,虽然灵活性有所降低但是易用性强,可以很方便地对网络模型进行修改。本文使用其中的Tensorflow作为后端。网络模型的训练使用AdamOptimizer,它是一种自适应学习率的优化算法,能够自动调节学习率以加速网络收敛。
3.1 不同网络模型的准确率与速度对比
为了将SubwayNet与其它轻量化网络模型比较,本文根据原始论文复现了SqueezeNet、MobileNet_v1、MobileNet_v2、ShuffleNet 4种轻量化网络模型,并使用Subway-5数据集作为输入进行对比实验,输入图像尺寸均为320×320×3。
网络模型参数量与分类准确率如表2所示,从表2中可以看出:SubwayNet_v1在Subway-5数据集上的准确率能够达到94%;SubwayNet_v2 在SubwayNet_v1的基础上将准确率提升了2%,达到96%,而参数量保持不变;剩余4种轻量化网络模型中MobileNet_v2的准确率较高但也只达到了90%,而参数量却是SubwayNet_v2的8.4倍,SqueezeNet的参数量与SubwayNet_v2的参数量数量级相同,但是准确率只能达到80%。

Table 2 Different network models classification accuracy and parameter quantity表2 不同网络模型分类准确率与参数量
网络模型大小与处理单幅320×320大小的地铁隧道图像的速度的关系如表3所示,测试分别在单块Intel Xeon E5-2620V4 CPU下和单块NVIDIA TESLA-K80 GPU下进行,其中,model_size表示将模型保存为.h5文件所占用的内存大小。处理时间为多幅图像的处理时间求平均并保留小数点后4位,帧速率将计算结果向下取整。根据视觉暂留原理,视频的图像变化速度需要大于24 fps画面才能流畅平滑。从表3中可以看出,在本文的实验条件下:各种网络模型中SubwayNet_v1网络模型所占用的内存最少,仅为3.6 MB,处理速度也最快,在CPU上能达到25 fps、在GPU上能达到52 fps;SubwayNet_v2由于添加了skip connection,计算量相比SubwayNet_v1略微增加,在CPU、GPU上的处理时间也略微增加,但网络模型大小以及帧速率保持不变;剩余4种轻量化网络模型中,MobileNet_v1网络模型所占用的内存最多,为37.3 MB,是SubwayNet_v1网络模型的10倍,处理速度也最慢,在CPU上只能达到15 fps,不满足视觉连续性的要求。
3.2 2种SubwayNet的分类效果对比
为了更好地评估2种SubwayNet对Subway-5数据集中5类图像的分类效果,本文计算了2种网络模型的准确率(Precision)、召回率(Recall)和F1值(F1_score)。
从表4中可以看出,SubwayNet_v1网络模型能够精准地检测钢轨扣件螺丝紧固、钢轨扣件螺丝松动、隧道壁渗漏水的情况,但是存在轨道内异物漏检和正常状态误报为异常的情况。其中正常类的F1-score仅为0.88,异物类的F1-score仅为0.84。

Table 3 Network model size and processing speed表3 网络模型大小与处理速度
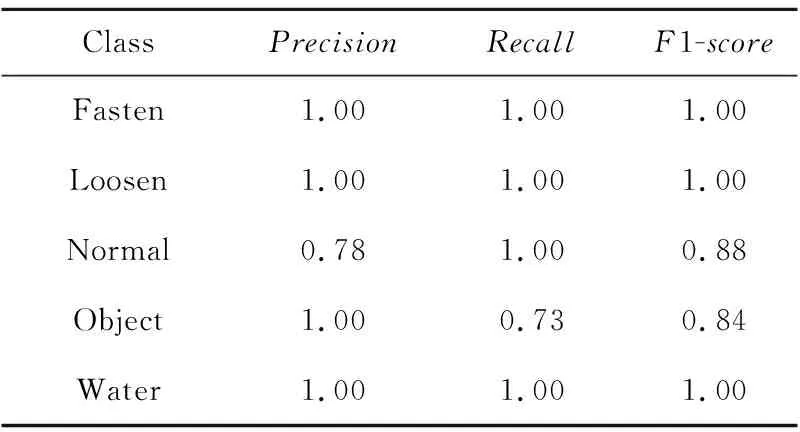
Table 4 Classification effect of SubwayNet_v1表4 SubwayNet_v1的分类效果
从表5中可以看出,相比于SubwayNet_v1网络模型,SubwayNet_v2网络模型虽然在钢轨扣件螺丝紧固、钢轨扣件螺丝松动2种情况中的识别准确率有所降低,但是整体5类情况的F1-score很高(最低为0.95)。这说明SubwayNet_v2网络模型在Subway-5数据集上的综合性能优于SubwayNet_v1网络模型的,在实际应用中的可靠性更高。
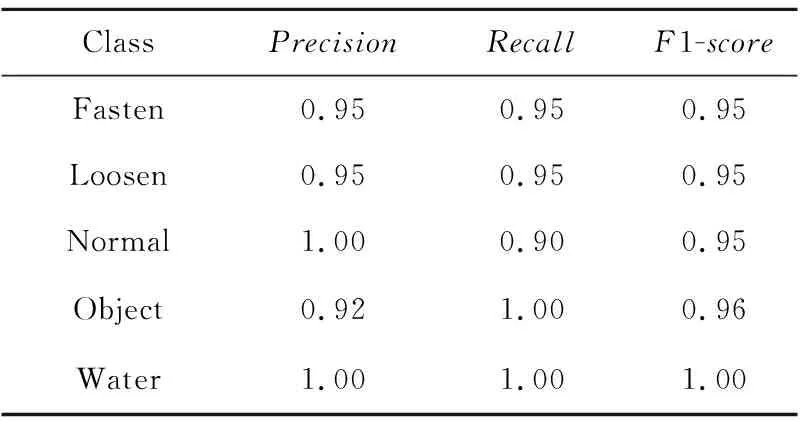
Table 5 Classification effect of SubwayNet_v2表5 SubwayNet_v2的分类效果
3.3 SubwayNet_v2的特征图与类激活图可视化
为了进一步分析综合性能较高的SubwayNet_v2网络模型提取到的地铁巡检图像的特征,本文将Subway-5数据集中5幅不同类别的测试图像分别输入到训练后保存的网络模型中,并对网络模型中部分层得到的特征图进行了可视化处理,如图6所示。从图6中可以看出:测试图像在经过第1次Conv_7×7卷积操作后过滤了大量无关信息并保留了图像的纹理等主要特征,此时特征图的尺寸变为160×160;在经过第1个Subway_inception_v2结构后特征图的抽象程度进一步提升,此时特征图的尺寸变为80×80;在经过第4个Subway_inception_v2结构后特征图的抽象程度极高,已无法进行视觉上的直观分析,此时特征图的尺寸变为20×20。而且从Object类中还能够看出光线对于网络模型的特征提取效果影响极大,网络模型提取到了隧道壁上LED灯的特征以及地面上手电光线的特征,这会减弱轨道内异物特征对于最终分类结果的影响。

Figure 6 Feature map visualization图6 特征图可视化
为了更好地分析SubwayNet_v2网络模型的图像分类依据,本文还可视化了类激活图CAM(Class Activation Map)并叠加在输入图像上生成类激活热图(Heat Map)。类激活图是与特定输出类别关联分数的二维网格,其针对于输入图像中的每个像素位置进行计算,并指示每个像素位置对于所判定结果的类的重要程度,如图7所示。从图7中可以看出:SubwayNet_v2网络模型对正常情况图像的判别依据是轨道的中间部分以及侧边隧道壁的部分;对隧道壁渗漏水情况的判别依据是侧边隧道壁渗漏水的部分以及轨道的中间部分;对于钢轨扣件螺丝紧固以及钢轨扣件螺丝松动情况的判别依据是钢轨扣件的部分。以上情况基本符合人工巡检的检查位置,但是对于轨道内存在异物的情况,系统却把隧道壁上的LED灯的部分当做判别依据,说明网络没有正确地学习到相应的异物特征。这与Subway-5数据集中轨道内存在异物类别的图像数据采集的位置有关,这段隧道内的亮度较低,灯光的亮度成为了主要影响因子。根据以往的深度学习研究经验,采集更多不同隧道环境下的轨道内异物的图像数据,增加同类数据的差异性可能会使效果得到改善。

Figure 7 Class activation map and heat map visualization图7 类激活图和热度图可视化
3.4 系统整体运行效果
由于最终地铁隧道巡检视频分析系统的结果是以Python文件打包后得到的应用软件中视频的形式呈现,因此本文截取了一段测试视频中的5种不同情况进行说明,如图8所示(箭头为后期标注)。从5种情况的分析结果中能够看出,分析系统具有较高的准确率,并且在情况2、情况3和情况5中有警报声,与设置相符。

Figure 8 Analysis system operation results图8 分析系统运行结果
4 结束语
本文利用MobileNet中的深度可分离卷积与ResNet中的跳跃连接来改进GoogleNet的inception结构,提出了2种Subway_inception结构,建立了2种SubwayNet卷积神经网络模型,并构建了完整的地铁隧道巡检视频分析系统。通过不同轻量化网络模型在Subway-5数据集上的效果对比检验了2种SubwayNet的性能,还通过可视化特征图和类激活图分析了SubwayNet_v2网络模型对于图像特征的提取效果。在文中的实验条件下,SubwayNet_v2网络模型的准确率能够达到96%,图像处理速度能够达到52 fps,满足视频实时、准确处理分析的要求。本文为地铁隧道日常巡检,保障地铁的安全运营提供了一种新方法。对算法进行改进,在分类的基础上完成异常状态位置的检测是下一步的改进方向。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
铁道建筑技术(2020年11期)2020-05-22
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
西南交通大学学报(2018年5期)2018-11-08
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
