
基于深度卷积神经网络的小目标检测算法*
2020-05-04 06:53李航,朱明
计算机工程与科学 2020年4期
李 航,朱 明
(1.中国科学院长春光学精密机械与物理研究所,吉林 长春 130033;2.中国科学院大学,北京 100049)
1 引言
随着计算机技术的迅速发展,计算机视觉技术已经广泛应用于各行各业,在智能视频监控、人机交互、机器人视觉导航、医学诊断和图像分类等领域有着十分广阔的应用前景[1 - 3]。目标检测是指从一幅原始的图像中分离出背景和感兴趣的目标,确定这一目标的类别和位置。目标检测技术是计算机视觉中十分重要的组成部分,为计算机感知世界、认知世界提供基础。
传统的目标检测算法主要基于图像梯度直方图的局部特征(SIFT)和全局特征(HOG)提取方法[4,5],利用滑动窗口找出目标的潜在区域,提取出特征信息,再利用支持向量机(SVM)和自适应提升(Adaboost)等分类器对目标特征进行分类。还有一些算法使用全局注意力机制在整个检测场景中选择突出的候选区域。虽然这些算法检测效果较好,但鲁棒性较差,无法用于不同的应用场景中。而且由于滑动窗口策略会导致大量重复计算,算法的执行速度较慢。
近年来,基于深度卷积神经网络[6 - 8]的目标检测技术以其局部感知和权值共享的特点,在目标检测领域取得了飞速的发展。与传统的目标检测算法相比,基于深度卷积神经网络的目标检测算法通过卷积神经网络对训练数据集的学习,可以自动地从图像中提取特征,获得目标的位置和类别,学习能力强、精度高、鲁棒性强。当前基于卷积神经网络的目标检测算法主要分为2类:一类是基于区域的目标检测算法,如Faster RCNN[2]和CornerNet[9]。这类算法将特征提取、区域建议和边界框分类与回归整合到1个网络中,提高了小目标的检测率,但是在嵌入式平台上无法满足实时检测的要求。另一类是基于回归的目标检测算法,如YOLO(You Only Look Once)[10 - 12]和SSD(Single Shot multibox Detector)[13],只需经过1次卷积运算,便可直接在原始图像上完成目标检测工作。这类算法检测速度较快,满足实时性的要求,但是对小目标的检测效果不尽人意。
为了在嵌入式平台上实现小目标检测精度和检测速度方面的良好平衡,本文借鉴YOLO算法,设计了一种新的dense_YOLO目标检测算法。在特征提取阶段,通过将DenseNet[14]网络的思想和深度可分离卷积[15,16]思想相结合,设计出基于深度可分离卷积的slim-densenet特征提取网络,增强了小目标的特征传递,也加快了算法的检测速度。在检测阶段,采用自适应多尺度融合检测的思想,在不同的特征尺度上进行目标的分类和回归,提高了小目标的检测精度。dense_YOLO目标检测算法可以为深度学习[17]目标检测技术应用于嵌入式平台提供可能。
2 dense_YOLO目标检测算法
2.1 原始YOLO算法
YOLO算法将物体检测问题处理成回归问题,用1个神经网络结构就可以从图像中直接预测目标的位置和类别。在网络结构上,首先采用ReLU(Rectified Linear Unit)[6]激活函数和卷积操作来提取特征,之后采用全连接层进行目标位置和类别的预测,从而得出最终的检测结果。
YOLO算法采用分块思想,将输入图像分成S×S个小块(grid cell),若目标的中心点落入到某一个小格中,那么这个小格便负责这个目标的预测任务,通过网络的训练学习数据分布,预测出这个目标的中心坐标、长宽和类别;再经过非极大值抑制NMS(Non-Maximum Suppression)算法[18],将置信度高的候选框作为最终的目标位置输出,如图1所示。虽然YOLO算法检测速度较快,但全连接层丢失了较多的空间信息,使得算法对小目标的检测效果不好。
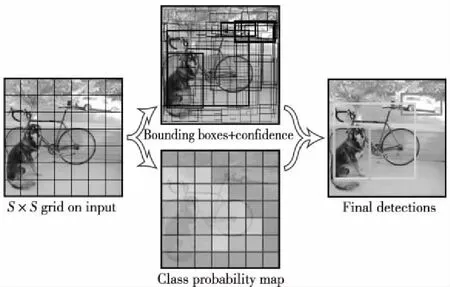
Figure 1 YOLO detection principle图1 YOLO检测原理
2.2 dense_YOLO目标检测原理
本文针对YOLO算法在检测小目标时精度低的问题,设计了新的dense_YOLO目标检测算法,算法由2部分组成:特征提取模块和多尺度目标检测模块。dense_YOLO目标检测算法舍弃了原始YOLO算法中的全连接层,改为采用全卷积网络(Fully Convolutional Networks)[19]的结构,使得网络可以适应不同大小的输入图像。然后使用新的基于深度可分离卷积的slim-densenet特征提取网络来提取特征,新的网络结构参数量更少,特征在网络中的传递速度更快。最后采用自适应多尺度融合算法进行目标检测,在不同的特征尺度上进行目标的分类和回归,得到目标的具体位置和类别信息,提高了算法对小目标的检测准确率。
2.2.1 slim-densenet特征提取模块
本文借鉴DenseNet网络结构,设计了slim-densenet特征提取网络结构。原始的YOLO网络结构中,特征的传递方式为逐层传递,每层的输入只来自和它相连的前一层。而本文的slim-densenet特征提取网络结构改变了特征在网络层之间的传递方式,使得特征可以跳过部分网络层直接传递到后面的网络层中,不仅减轻了梯度消失的问题,而且还加快了特征在网络中的传递。本文的slim-densenet特征提取网络结构如图2所示。其中Dense block模块是slim-densenet网络中加速特征传递的部分。从图3可以看出,特征经过Dense block可以跳过其中的部分网络直接传递到后端网络,因而加快了特征在网络中的传递。

Figure 2 Network structure of slim-densenet图2 slim-densenet特征提取网络结构
为了进一步提高特征在网络中的传递速度,本文将特征提取模块中的7×7,5×5和3×3卷积替换为深度可分离卷积。深度可分离卷积区别于传统的卷积:传统的卷积利用卷积核对输入的多通道图像进行卷积操作,随着卷积核的增大,计算量成指数增长。而深度卷积神经网络将卷积操作分为Depthwise Convolution和Pointwise Convolution 2部分,如图4所示,Depthwise Convolution对输入的多通道向量进行分层卷积,即对每一层通道都进行卷积运算;之后Pointwise Convolution使用大小为1×1的卷积核对Depthwise Convolution得到的中间结果在通道维度进行扩充,最终得到和传统卷积操作相同的结果。与传统的卷积操作相比,深度可分离卷积在减少参数量的同时加快了特征的传递。

Figure 3 Dense block module图3 Dense block模块

Figure 4 Depthwise separable convolution图4 深度可分离卷积
2.2.2 自适应多尺度融合检测模块
针对小目标检测这一难点,本文提出了多尺度融合检测的思想。基于深度学习的YOLO目标检测算法需要经过多个下采样层来提取特征,在最后一层特征图上进行目标的分类和回归,而每经过1个下采样层,网络的分辨率就会被压缩1次,从而损失不同分辨率的特征图的信息,这样使得网络在最后很难提取到针对小目标的特征,因此YOLO算法对小目标的检测效果不尽人意。针对这一情况,本文在3个特征尺度上进行目标检测,每1个特征尺度都融合了其他特征尺度的信息,网络浅层提取目标边缘和纹理等细节特征,网络深层提取物体轮廓的特征,将它们相互融合之后进行卷积运算,提取出目标的位置类别信息。本文的自适应多尺度融合检测流程如图5所示。

Figure 5 Adaptive multi-scale fusion detection图5 自适应多尺度融合检测
首先通过最后3个Dense block模块提取出3个尺度不同的feature map。接着进行特征融合,将小尺度的feature map包含的特征传入前面一层大尺度的feature map中,这样每一层预测所用的feature map都融合了不同分辨率、不同语义强度的特征,大尺度feature map由于其分辨率较高,保留了较多的细节特征,更容易预测小的预测框。小尺度feature map由于其分辨率较低,保留的是物体的轮廓等信息,更容易预测大的预测框。然后在特征融合之后的3个feature map上进行卷积运算,提取出目标的坐标信息和类别信息。最后将3个特征尺度上提取到的目标信息相结合,采用非极大值抑制NMS算法得到最终的检测结果。
2.3 dense_YOLO目标检测流程
dense_YOLO目标检测算法分为3部分。算法首先通过基于深度可分离卷积的slim-densenet模块进行特征的提取,之后将提取到的特征在不同尺度上进行融合和检测,最后采用非极大值抑制NMS算法将不同尺度上提取到的目标位置和类别信息进行结合,得到最终的检测结果。算法的基本流程如下:
(1) 图像初始化。将输入图像进行初始化,转换成大小为608×608的彩色图像送入网络。
(2) 特征提取。使用slim-densenet特征提取模块对送入的图像进行特征提取,将结果送入后续的目标检测模块。
(3) 自适应多尺度融合检测。使用多尺度融合检测算法对特征进行目标的位置和类别预测。
(4) 检测结果输出。通过NMS算法计算出不同尺度特征中目标的具体位置和类别,并在原始图像上进行标注,最终输出结果。
算法的流程图如图6所示。

Figure 6 Flow chart of dense_YOLO algorithm图6 dense_YOLO算法流程
3 数据集与实验设计
3.1 数据集和评价指标
本文在MS COCO(Microsoft COCO:Common Objects in Context)[20]通用数据集上进行了测试,也在本文制作的小目标数据集上和原算法做了对比实验。
目标检测领域主要有2大通用数据集,一个是PASCAL VOC数据集,另一个是MS COCO数据集。MS COCO数据集是微软构建的一个数据集,其包含detection、segmentation和keypoints等任务。在检测方面,MS COCO包含80种类别,相对于PASCAL VOC数据集的20种类别,MS COCO数据集类别丰富,包含了自然图像和生活中常见的目标图像,背景比较复杂,目标数量比较多,目标尺寸更小,因此在MS COCO数据集上的实验更难。
本文制作数据集的方法是使用无人机平台,对三亚海滩附近场景进行视频拍摄,着重选取一些陆地上和海滩上的行人进行拍摄,拍摄时光线充足,无雨雾雪,温度27℃。对得到的视频每隔1 s提取1帧,最终得到270幅尺寸为1920×1080的彩色图像。采用开源的Labelimage软件对采集到的270幅图像进行标记,对应得到270个.xml文件。对其中的210幅图像进行数据增强,通过各种变换增加训练的数据量,增加噪声数据,防止网络模型过拟合情况的出现,以得到能力更强的网络,更好地适应应用场景。本文主要使用的数据增强方法有:旋转、缩放、裁剪,得到近2 100幅图像,大小为1000×600。这2 100幅图像转换成voc数据集的格式作为训练样本。剩余的60幅图像作为验证集。
本文采用的主要评价指标是AP,因为目标检测领域中Precision和Recall是一对对立关系的指标,一个指标升高伴随着另一个指标下降,故人们采用PR曲线,即Precision和Recall曲线的线下面积来作为评价一个算法性能的指标AP,对于多个类别,AP的平均值称为mAP。AP@0.5的含义为:将交并比IoU(Intersection over Union)阈值设置为0.5,与真值框的IoU大于0.5的检测框判定为检测正确,通过在召回率坐标轴上每隔0.1计算出对应的准确率值,绘制出PR曲线,最终得到检测指标AP。其中IoU指预测结果框和真值框重合区域的面积与总面积的比值。同时还有针对小目标、中目标和大目标的mAP以及在IoU改变时各个Recall的值。另一个评价指标为TOP-1,即置信度最高的检测结果的准确率。
3.2 训练参数的设置
本文使用的训练参数及其值如下所示:
batch:每次迭代训练的图像数目,本文设置为32。
subdivisions:将batch进行分组后送入网络,本文设置为16。
网络输入尺寸:本文设置为608×608。
angle:图像角度变化,单位为度,以增加训练样本数,本文设置为7°。
weightdecay:权值衰减正则项系数,防止过拟合,本文设置为0.000 5。
saturation:饱和度,以增加训练样本数,本文设置为0.75。
exposure:曝光度,以增加训练样本数,本文设置为0.75。
hue:色调变化范围,以增加训练样本,本文设置为0.1。
learningrate:学习率,本文设置为0.001。
max_batches:最大迭代次数,本文设置为500 000。
policy:学习率调整策略,本文选择poly策略。poly的表达式为new_Ir=base_Ir*(1-iter/maxiter)power,可以看出学习率主要由power参数控制,power<1,学习率为凸状,power>1,学习率为凹状。
anchors:预测框大小的预设值,具体如下:
(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90),(156×198),(373×326)。
k:anchor的数目,本文设置为9。
本文采用kmeans_YOLO聚类来处理数据集,不同k值对应的损失如图7所示。

Figure 7 Clustering results on dateset图7 数据集聚类结果
3.3 实验环境和训练方法
实验环境硬件配置为:训练时采用计算机服务器,配置core i7处理器,2块Titan xp显卡。检测时采用NVIDIA JETSON XAVIER[21]嵌入式平台,为NVIDIA公司为深度学习专门设计的嵌入式系统,内置CPU和GPU模块,默认安装ubuntu系统。
网络在每个卷积层前都加入了BN(Batch Normalization)层,将每一层的神经网络中的任一个神经元的输入进行归一化,分布为均值为0、方差为1的标准正态分布,解决了训练过程中,随着网络层数的加深,输入数据的分布逐渐发生偏移,从而导致的训练收敛慢和梯度消失问题。
本文使用交叉熵损失函数替换YOLO算法使用的Softmax函数。YOLO算法中的损失函数将1个实数的k维向量压缩成另1个k维向量,使得所有分量的范围在(0,1),并且分量的和为1。但是,在实际的分类任务中,检测到的目标可能会属于多个类别,比如在Open Images Dataset中,1个目标有多个标签(例如人和女人),故本文使用交叉熵损失函数来替代Softmax函数,使得网络预测的目标可以有多个不同的类别与之对应。
训练时采用的是深度学习经常使用的随机梯度下降算法,从所有训练数据里随机选择1个batch作为样本,送入网络学习,接着再随机选择样本来进行学习,最终达到最优点。
和大部分的目标检测算法一样,本文首先使用slim-densenet分类网络在ImagNet竞赛数据集上进行预训练,得到预训练权重。使得初始的网络学习到类别的大致特征,为之后的检测提供基础。接着在backbone网络上添加自己的检测网络,在通用的MS COCO数据集上进行训练,经过10天500 000次迭代之后,损失稳定在3.5左右不再变化,结束训练。损失值与迭代次数的关系如图8所示。

Figure 8 Loss function visualization图8 损失函数可视化
4 实验结果对比与分析
本文基于slim-densenet的网络模型在ImageNet分类数据集上的表现如表1所示。

Table 1 Network classification result表1 网络分类结果
从表1中可以看出,在TOP-1准确率方面,本文基于slim-densenet的网络模型比VGG-16和Darknet19提高了7%,和经典的ResNet 101相差无几,但是在速度方面有着明显的优势。
在通用的目标检测数据集MS COCO上,硬件平台为NVIDIA JETSON XAVIER,将dense_YOLO-416算法和YOLO-608、SSD512等经典算法进行了比较,其中dense_YOLO-416、YOLO-608、SSD512中的416,608,512分别代表网络的输入尺寸大小。具体的检测性能和检测结果如表2和图9所示,其中APS表示对小目标(像素小于32×32)检测的AP指标;AP50即AP@0.5是3.1节中的AP@0.5的简写形式;AP为将IoU阈值从0.5~0.95中每隔0.5进行取值,计算出的10个AP值求取平均所得;Weights为网络模型的权重大小;GPU Time表示算法检测单幅图像所用时间。

Table 2 Detection results on MS COCO表2 MS COCO上的检测结果
在本文创建的目标检测数据集上,硬件平台为NVIDIA JETSON XAVIER,本文设计的dense_YOLO算法检测性能如表3所示,检测结果如图10所示。
在NVIDIA JETSON XAVIER嵌入式平台上,本文的dense_YOLO目标检测算法相较于原YOLO算法,检测时间缩短了15 ms左右,可以达到20 fps以上的实时性,也优于其他的算法。在检测准确率方面,针对MS COCO数据集中的小目标,本文设计的dense_YOLO算法相较于YOLO算法在APS指标上提高了7%,而在AP0.5指标上, dense_YOLO算法超过了YOLO、SSD和Faster RCNN算法,都至少提高了10%,并且网络模型大小为原YOLO算法的66%。针对本文创建的数据集,dense_YOLO算法也比原YOLO算法的AP0.5提高了8%。

Figure 9 YOLO algorithm and dense_YOLO algorithm detection results on MS COCO dataset图9 原算法(左)和改进算法(右) 在MS COCO数据集上检测结果

Figure 10 YOLO algorithm and dense_YOLO algorithm detection results on own dataset图10 原算法(左)和改进算法(右)在本文创建数据集上的检测结果
5 结束语
本文提出了一种新的基于深度卷积神经网络的dense_YOLO目标检测算法,在嵌入式平台上可以实现高准确率的实时目标检测。dense_YOLO算法首先利用新提出的slim-densenet特征提取模块对图像提取特征,减少了参数量,加快了网络的训练和预测。然后采用自适应多尺度融合检测方法丰富了小尺度特征图的信息,提高了小目标的检出率。最后通过非极大值抑制算法得到最终检测结果。实验表明,在通用的MS COCO数据集上,dense_YOLO算法在小目标检测方面,较原YOLO算法mAP指标提高了7%,检测时间缩短了15 ms,网络模型大小为原算法的66%。此外,在本文采集并手工标注的数据集上,该算法检测准确率和速度也明显优于原算法,满足嵌入式平台对算法速度和精度的要求,可为深度学习在嵌入式平台上的应用提供借鉴。本文提出的算法还有很多地方需要改进,比如slim-densenet还可以通过剪枝操作,减少通道的冗余,加快推断速度,在本文的模型上进行压缩仍然需要更进一步的研究。

Table 3 Detection results on dataset created in this paper表3 在本文创建数据集上的检测结果
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年13期)2020-01-14
电子制作(2019年15期)2019-08-27
电子制作(2019年11期)2019-07-04
电子制作(2018年19期)2018-11-14
北京航空航天大学学报(2018年1期)2018-04-20
自动化学报(2017年11期)2017-04-04
太空探索(2016年5期)2016-07-12
噪声与振动控制(2015年4期)2015-01-01
