
运用GA-SVM模型的砂石骨料分类方法
2020-04-29 06:15:50余罗兼童昕沈国浪李占福
华侨大学学报(自然科学版) 2020年2期
余罗兼, 童昕, 沈国浪, 李占福
(1. 华侨大学 机电及自动化学院, 福建 厦门 361021;2. 福建工程学院 机械与汽车工程学院, 福建 福州 350108)
随着我国城镇化水平及基础设施建设的快速发展,天然砂消耗量急速增长,天然河砂资源日趋紧缺.人工砂的重要性也就日趋明显,将充当混凝土细骨料的补充材料、甚至完全取代天然砂[1].在岩石分类的研究上,最为传统的做法就是采用人工方式在偏光显微镜下对岩石薄片图像进行人工鉴定,这需要专业人员进行判读,工作量大且易受到主观因素影响[2].刘凤英等[3]提出采用BP神经网络对岩石的氧化物含量为特征量建立分类模型.袁颖等[4]提出采用主成分分析的遗传算法和支持向量机相结合的算法,同样对岩石的氧化物含量为特征量建立分类模型.Harmon等[5]采用激光诱导击穿光谱系统(LIBS)采集岩石光谱数据,结合偏最小二乘判别分析法(PLS-DA)识别火山岩的类型.
人工砂开采后需要经过机械破碎、筛分等工序制成机制砂.在破碎、筛分的过程中,自然可以形成一些表征人工砂石骨料特征的物理量.因此,本文提出采用遗传算法(GA)-支持向量机(SVM)分类模型,对破碎、筛分后的人工砂石骨料物理特征量进行训练,建立骨料分类模型.
1 经遗传算法优化的支持向量机基本原理
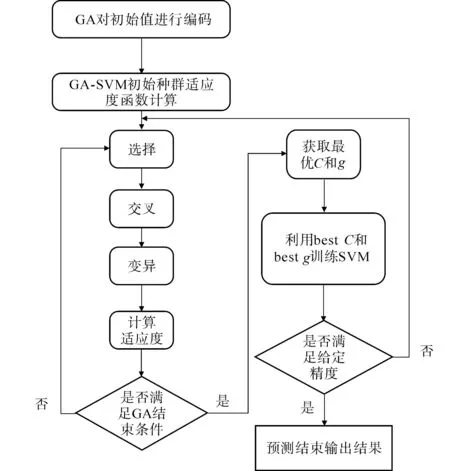
图1 GA优化SVM算法流程Fig.1 Flow chart of GA optimized SVM algorithm
支持向量机(SVM)是由Vapnik等提出的一种研究小样本、小概率事件的,基于统计学习理论的神经网络模型[6].其基本思想就是通过一个非线性映射,将数据映射到高维特征空间,将实际问题转化为一个带不等式约束的二次规划问题[7],即寻找一个最优超平面进行分类[8].
遗传算法(GA)是基于达尔文生物进化过程启发的优化算法[9].其将每一个解t看作染色体中的基因编码,通过反复的基因重组、突变等操作生产新的基因编码,最终求得O(t)的最优解t*.
GA优化支持向量机,主要是优化SVM的惩罚参数C和核参数g,其算法流程如图1所示.具体有如下5个主要步骤.
步骤1对数据进行预处理.对训练样本数据和测试样本数据进行归一化处理,消除量纲差异.
步骤2染色体编码与种群初始化.对SVM的惩罚参数C和核参数g进行二进制编码[10],并产生初始化种群.
步骤3GA判断优化是否终止.对种群进行选择、交叉、变异、计算适应度,直至满足GA终止条件,输出此次优化的最优参数.
步骤4SVM精度判定.将最优惩罚参数C和核参数g代入SVM中进行分类,判断是否符合给定精度;如不满足,重新进行步骤3.
步骤5测试集进行分类.将满足精度的GA-SVM分类模型对测试集进行分类,输出结果.

图2 砂石颗粒破碎试验台Fig.2 Gravel crushing test equipment
2 破碎实验与数据采集
实验的人工砂石骨料分别取自宁夏的花岗岩、福鼎的石灰石和浙江的灰绿岩,在砂石颗粒破碎试验台(图2)上进行单核破碎实验.
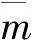
表1 三种岩石破碎物理特征量Tab.1 Three physical characteristics of rock fragmentation
3 GA-SVM分类模型建立与实验结果分析
3.1 模型数据配置
模型建立硬件环境为Win10,i5,8 GB内存,软件环境基于MATLAB2018a运行.GA-SVM分类模型数据采用表1的数据,每种石头试件样品做30组破碎实验,每组破碎实验数据中有10个特征量,三种石头试件样品总共90组数据;然后,随机选择63组作为训练数据集,剩余27组测试数据集,并对其进行归一化处理.
3.2 SVM核函数的选取
核函数的选择对支持向量机的性能有着至关重要的作用,如果核函数选择不合适,意味着将样本映射到一个不合适的特征空间,将会导致其性能不佳[11].因此,需要进行核函数选择的对比分析.常见的核函数有线性核函数、多项式核函数、径向基核函数,以及Sigmoid核函数.选择不同的核函数对分类结果进行对比分析,结果如表2所示.

表2 不同核函数下的SVM分类效果Tab.2 SVM classification effect under different kernel functions
从表2可知:选用线性核函数的分类正确率平均值为62.963%,训练平均时间为36.30 s;而选用径向基核函数的分类正确率平均值为66.667%,训练平均时间为11.83 s.在正确率平均值上,两者相差不是很大,但在训练平均时间上,径向基核函数训练更快.径向基核函数相比线性核能够处理分类标注和属性的非线性关系,同时具有简单实用、普适性好的优点[12].其他两种核函数的正确率平均值远远低于径向基核函数.因此,确定SVM的核函数选择径向基核函数.
3.3 K折交叉验证的选择
支持向量机可以以交叉验证法的准确率作为适应度函数.交叉验证是消除取样随机性造成训练偏差的方法,使用交叉验证能够有效评价训练模型性能,提升模型稳定性与泛化能力[13-14].采用K折交叉验证方法,核函数选择径向基核函数,支持向量机暂未经过GA优化,分别将K取5和10,验证分类效果,结果如表3所示.
从表3可知:当K取5,8,10时,其正确率平均值分别为70.370%,56.790%,58.025%,训练时间分别为11.969,21.034,26.401 s.因此,选用五折交叉验证.未经GA优化的选择径向基核函数、五折交叉验证的SVM分类结果,如图3所示.

表3 不同K值下的SVM分类结果Tab.3 SVM classification results at different K values

(a) 训练集 (b) 测试集图3 未经GA优化的选择径向基核函数的SVM分类结果Fig.3 SVM classification results of RBF kernel function without GA optimization
3.4 GA优化的SVM分类效果分析

图4 GA适应度变化曲线Fig.4 GA fitness curve
选用径向基核函数的SVM,惩罚参数C和核参数g对SVM的泛化性能有很大的影响[15],因此,采用遗传算法GA对其进行寻优.配置SVM核函数为径向基核函数,进行五折交叉验证,参数组合寻优空间范围为[0,100],种群规模选择为50,进化迭代次数为300次,交叉概率和变异概率选择默认值,结果分别如图4,5所示.
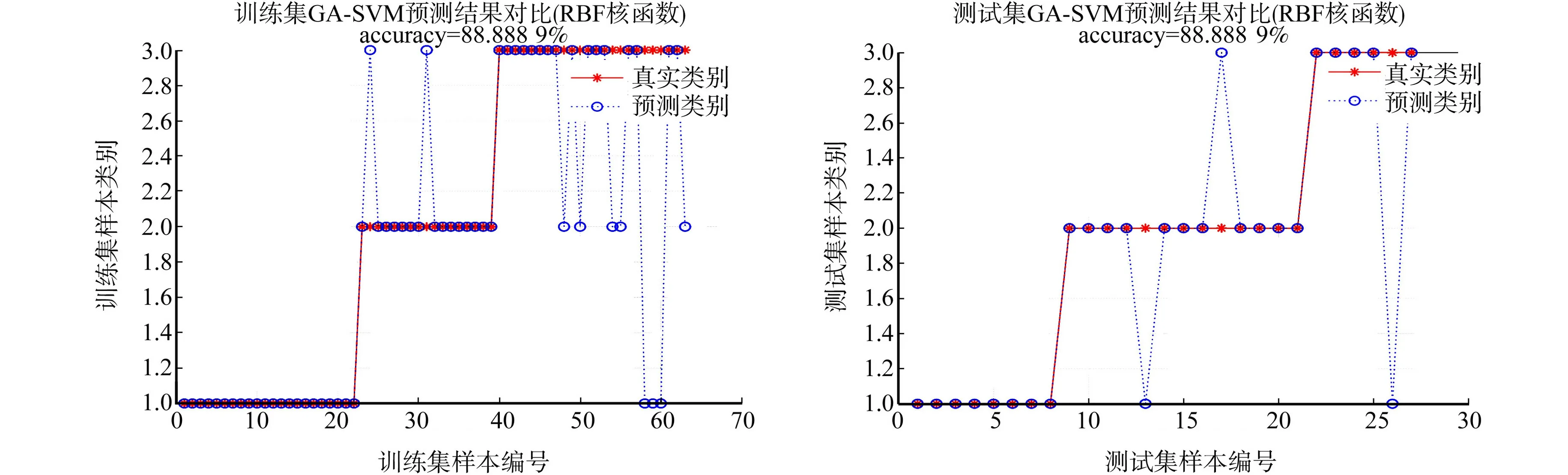
(a) 训练集 (b) 测试集图5 经GA优化的选择径向基核函数的SVM分类结果Fig.5 SVM classification results with RBF kernel function optimized by GA
从图4可知:遗传算法适应度随着迭代次数的增加而增加,当迭代到第38次的时候收敛至稳定值,可得最优惩罚参数Cbest=1.319 5,gbest=0.217 6.
对比图3和图5可知:在人工砂石骨料分类的模型建立基础上,与未经GA优化的SVM相比,经过GA优化的SVM的岩石识别正确率提升了约11%,正确率达到了88.89%.在测试集样本中,花岗岩的识别正确率同为100%,识别错误的地方都存在于石灰石与辉绿石上.
4 结束语
文中研究了人工砂石骨料分类识别的方法.在分析了传统岩石分类工作量任务大、主观因素强,所提岩石分类方法预处理成本高等缺点的基础上,提出了一种能够直接从破碎工序上识别骨料成分的算法模型.实验结果表明:基于GA-SVM的人工砂石骨料分类模型能够较好地识别人工砂石骨料成分,相比BP、PLS算法具有优势,为人工砂石骨料特征上的研究提供了一种新思路.在未来的研究工作中,需要将GA-SVM模型运用在其他常见的人工砂石骨料上,进行分类模型的建立,进一步验证此方法的有效性,为砂石骨料的智能加工打下基础.
猜你喜欢
科学大众(2022年9期)2022-06-05 07:27:30
中学生数理化·高一版(2021年3期)2021-06-09 06:10:20
数学物理学报(2021年1期)2021-03-29 03:14:18
中华养生保健(2020年7期)2020-11-16 01:14:26
重型机械(2020年3期)2020-08-24 08:31:40
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:44
家教世界·创新阅读(2016年11期)2016-12-27 18:49:15
天津护理(2016年3期)2016-12-01 05:40:01
故事会(2016年15期)2016-08-23 13:48:41
现代工业经济和信息化(2016年19期)2016-05-17 05:38:09
