
基于耳蜗倒谱系数的说话人识别
2020-04-23 01:22曾金芳徐文涛黄费贞
电子技术与软件工程 2020年5期
曾金芳 徐文涛 黄费贞
(湘潭大学物理与光电工程学院 湖南省湘潭市 411105)
说话人识别又叫声纹识别。说话人识别技术以其独特的方便性、经济性、准确性受到 了世人的瞩目,被广泛应用到信息安全领域、通信领域、司法领域和军事领域[1]。说话人识别就是从说话人的一段语音中提取出说话人的个性特征,通过对这些个性特征的分析和识别,从而达到对说话人进行辨认的目的[2]。这些个性特征就是说话人识别重点研究的内容。
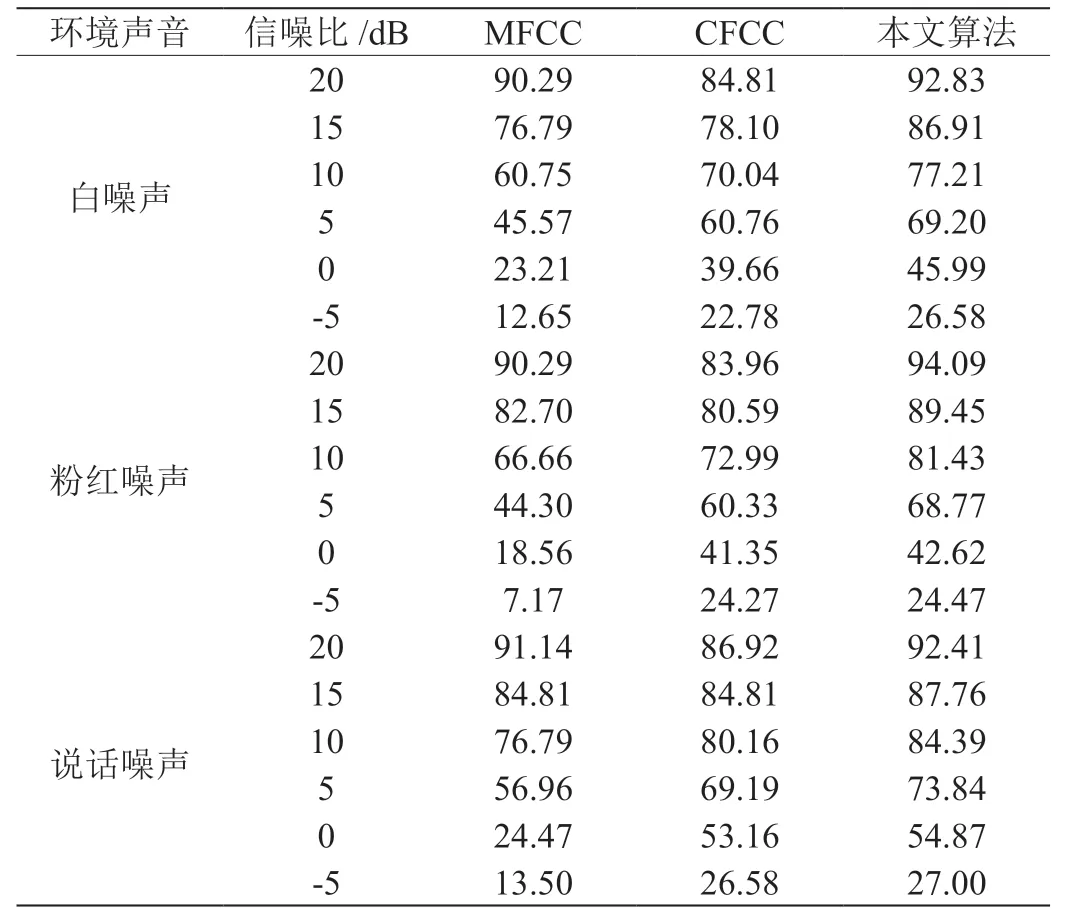
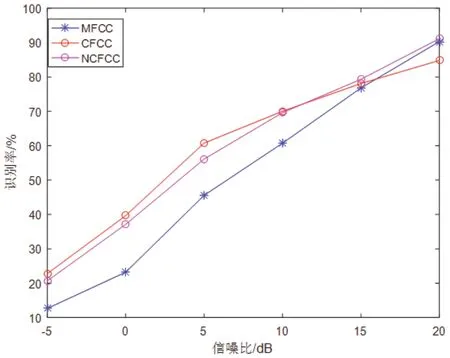
声学特征主要有:线性预测系数(Lin- ear prediction cepstral coefficient, LPC C)、梅尔倒谱系数( Mel frequency cepstral coefficient, MFCC)[3]以及耳蜗倒谱系数(Cochlear filter cepstral coeffi- cients, CFCC)[4]等。最常用的MFCC 是根据人耳结构设计的三角滤波器组进行特征提取的,但在噪声情况下的识别效果急剧下降[5]。CFCC特征提取方法并没有考虑到人耳听觉的神经元动作电位发放率与声音强度的饱和关系特性,而这种关系特性推导出非线性幂函数可以近似于听觉神经元[6]。通过对文献[6]的算法实验分析,发现其非线性幂函数参数调整为1/15 时,在说话人识别方面信噪比较高的情况下有较好的效果。为了提高低信噪比情况下说话人的识别率,本文将语音增强算法的维纳滤波[7]加入前端处理。虽然增加了步骤,但总体上容易实现。
笔者在前人研究的基础上,在说话人识别方面采用能够模拟人耳听觉特性的非线性幂函数提取新的耳蜗倒谱系(New Cochlear filter cepstral coeffici- ents,NCFCC),验证NCFCC 特征对于CFCC的优势和缺点,然后通过维纳滤波来改进其缺点。
1 CFCC特征参数提取
CFCC 是由贝尔实验室的Li Q 在2011年首次提出的并应用于说话人识别的特征参数[4]。CFCC 特征参数提取方法如图1 所示。
假设f(t)是一个原始的输入语音信号,则耳蜗滤波器变换的函数可以定义为:
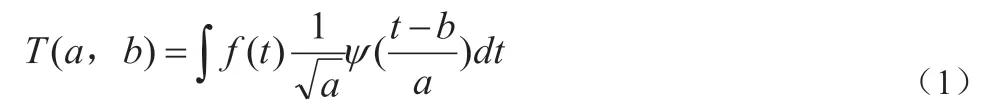
式中:a,b 为实数。
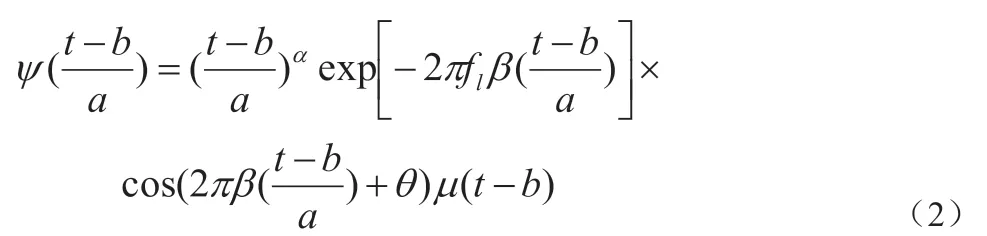
式中:α>0 和β>0,α,β 决定了ψ(t)的频域形状和宽度,α 和β的一般取经验值为α=3、β=0.2。θ 为控制冲激响应的角度,它的取值应该满足积分表达式:

μ(t)为单位步进函数,b 为随时间可变的实数,a 为尺度变量,一般情况下可由滤波器的质心频率fc和最低中心频率fL决定:
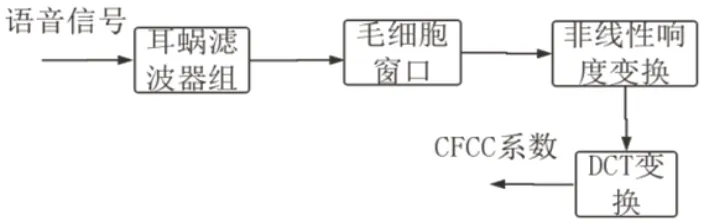
图1:CFCC 特征提取框图
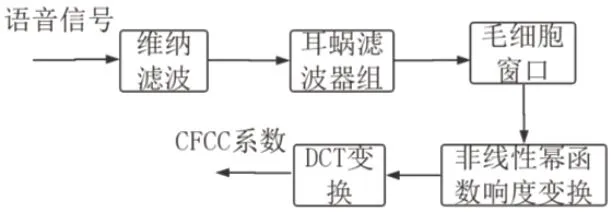
图2:本文特征提取过程

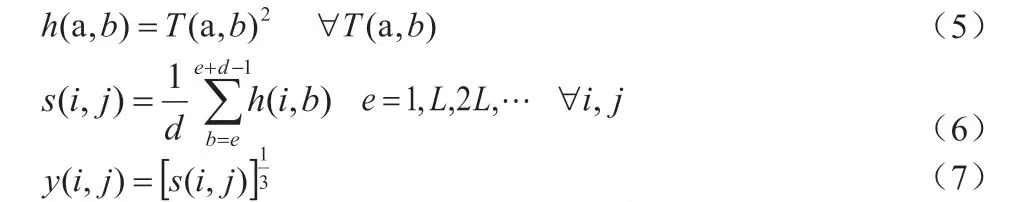





猜你喜欢
中学生数理化·七年级数学人教版(2023年3期)2023-03-21
新世纪智能(数学备考)(2021年9期)2021-11-24
新世纪智能(数学备考)(2021年9期)2021-11-24
新世纪智能(数学备考)(2020年9期)2021-01-04
舰船电子对抗(2019年4期)2019-09-10
太原科技大学学报(2019年3期)2019-08-05
中学生数理化·七年级数学人教版(2018年3期)2018-05-30
中学生数理化·七年级数学人教版(2017年3期)2018-01-20
计算机应用与软件(2017年3期)2017-04-14
洛阳师范学院学报(2017年2期)2017-03-12
