
基于数据挖掘的信用卡欺诈检测
2020-04-16 05:29李梦涛吕朝辉
中国传媒大学学报(自然科学版) 2020年6期
李梦涛,吕朝辉
(中国传媒大学信息工程学院,北京 100024)
1 引言
信用卡欺诈数目的不断增加带来了巨大的经济损失。国内外各大银行都在想办法减少信用卡欺诈带来的损失。针对这一趋势,如何准确快速的检测到信用卡欺诈的风险成为一大研究热点[1]。就目前而言,信用卡欺诈风险的防范可以从两个角度去解决,主要是是非技术手段宏观调控和技术手段的信用卡欺诈检测。国内外非技术方面防范手段是建立良好的避险,防险,监督,管理,补偿等信用卡机制[2]。在技术手段上时,早期,国外的金融机构利用员工的经验去对有可能的欺诈行为进行标记,跟踪,预测,这种方法需要耗费大量的人力资源和成本。接着用专家构建一个基于规则的专家系统模型,对信用欺诈进行检测。这两种方法都可以在一定程度上检测出信用卡欺诈,但同时带有很强的主观性,得到的结果不科学,解释性较差,因此检测结果不可信[3]。但随着信息科学技术的不断发展,国内外学者开始从数据挖掘角度去解决信用卡欺诈这个问题。于是出现了神经网络,决策树,组合分类器,支持向量机等信用卡欺诈检测的方法。
Y Sahin等[4]研究出一种新的基于成本敏感决策树方法,该方法在选择每个非终端节点处的分裂属性时最小化错误分类成本的总和,实验证明这种新的决策树的欺诈检测效果较好。潘俊[5]使用以C4.5为基础的Adaboost与Cost-sensitive算法相结合的组合分类器模型,实验表明,在改善信用卡欺诈数据非均匀分布问题上,上述方法表现出良好的分类性能。R.Brause,T.Langsdorf,M.赫普[6]展示了如何成功地组合先进的数据挖掘技术和神经网络算法,以获得高欺诈覆盖率和低误报率。徐永华[7]针对信用卡数据的高纬性稀疏性,使用支持向量机的方法,实验结果显示,采用支持向量机的信用卡欺诈检测精度达到95%以上,且检测时间只有0.565 秒,说明支持向量机是一种有效的信用卡检测方法。
大部分的方法对于数据量的要求比较高,这些方法的高精确率都是建立在大量数据为前提的。其次是有些方法的运用会导致欠学习,过拟合的现象。接着在面对高纬度稀疏性的样本时,会存在一些方法的处理效果欠佳。最后最重要的是,很多研究者过多的注重方法或者算法的研究,而忽视了前期数据特征预处理的工作。基于以上方法研究出现的一些问题,本文详细介绍了数据挖掘前期预处理的方法和步骤,采用随机森林的方法,对预处理后的数据进行建模,预测,结果表明该模型在本实验数据上的信用卡欺诈检测效果更好。
2 信用卡欺诈相关技术分析
2.1 信用卡欺诈检测问题描述
信用卡欺诈检测本质是一个分类问题,那就是将信用卡消费行为,分为有欺诈和无欺诈风险的消费行为。主要流程是将信用卡用户基本数据和消费信息数据,建立样本数据X。然后根据银行信用卡欺诈信息记录给这些样本数据添加一个标签Y。即Y=0,该信用卡消费行为是非欺诈的,Y=1,该信用卡消费行为是欺诈的。然后对这些数据信息进行数据预处理,数据模型构建,然后用该模型对持卡人当前消费行为进行分析和处理,从中识别该行为是否是信用卡欺诈交易。
2.2 信用卡欺诈算法分析
(1)随机森林算法应用前景介绍
随机森林是利用多棵树对样本进行训练并预测的一种分类器。作为新兴起的,高度灵活的一种机器学习算法,随机森林在各种机器学习以及数据挖掘类比赛上有较好的成绩,同时也拥有较好的应用场景。随机森林能够能够估计哪个特征在分类中更重要和处理过拟合问题,同时当数据集中存在大量的噪音时同样可以取,并且模型训练速度比较快,能够估计哪个特征在分类中更重要,最重要的对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据[8]。
(2)随机森林算法原理分析
随机森林是组合分类方法的一种。组合分类器是将使用的数据集D,划分为D1,D2,...,Dk,然后使用这k个训练集创建K个分类器M1,M2,...,Mk,将这K个分类器组合在一起,意在创建一个改进的复合分类器模型。给定一个待分类的新的数据元组,每个基分类器通过返回类预测投票。组合分类器基于基分类器的投票返回类预测。
随机森林是中每个分类器都是决策树,这种分类器的集合就叫做“森林”。同时单个决策树的每个节点使用随机选择的属性决定划分,换句话说就是每个树都是独立抽样,并与森林中其它分类器组合,分类时,每棵树都投票,并且返回得票最多的类。
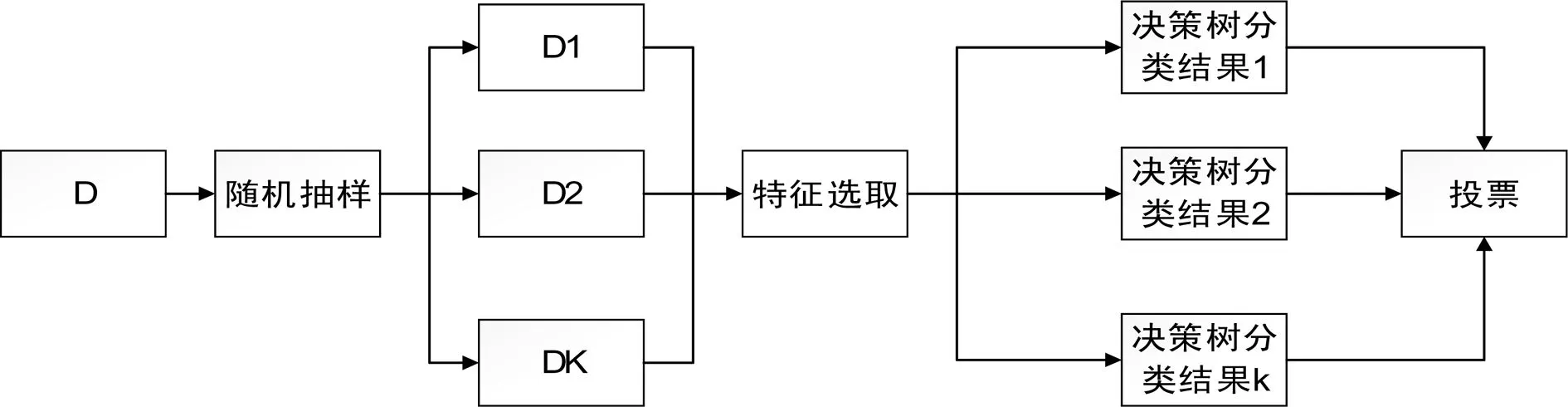
图1 随机森林原理图
2.3 数据预处理试验分析
在数据挖掘过程中,海量的原始数据中存在着大量不完整数据(有缺失值),不一致,有异常的数据,严重影响到数据挖掘的建模效率和结果,所以进行数据清洗就非常重要,数据清洗完成后接着进行或者进行数据集成,转换,规约等一系列操作,该过程就叫做数据预处理。本次实验数据来自UCI机器学习数据集网站的德国信用数据,数据属性如表1。
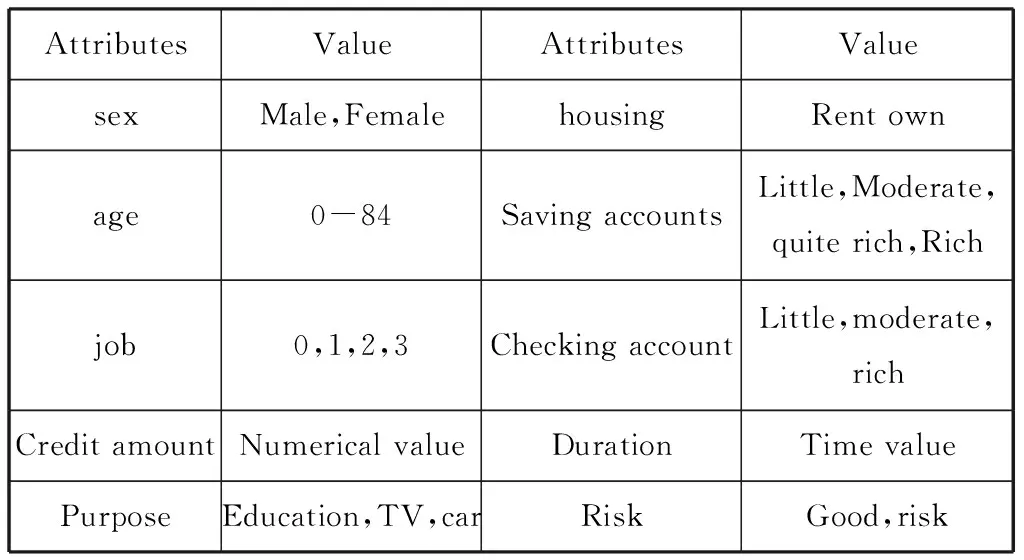
表1 原始数据属性表
(1)数据清洗
在实际的样本数据中,样本可能会由于某些原因,造成一个或多个值的缺失。在表格中缺失值通常是以空值的形式或者是NA(Not A Number)存在的。如果直接忽视这些缺失值或者删除这些缺失值会导致算法异常和数据浪费,这将会影响我们训练出来模型的泛化能力。本次信用卡欺诈数据经检测后发现属性Saving accounts和Checking account有空值。这里对缺失值的处理办法是:使用最有可能的值填充。把空值归于little属性值。
(2)数据变换
数据变换主要是对数据进行规范化处理,将数据转换成“适当的”形式,以适用于数据挖掘任务及算法的需要。在进行数据变换之前,为了使数据结构更加清晰,需要对数据进行分类。

表2 数据分类表
1)针对定类型数据,采取的数据变换是标称二元化.即
sex:male,female→sex:0,1
Risk:good,risk→Risk:0,1
2)在对定量型数据进行数据变换前,先进行数据探索,分析连续变量的相关性。这里采用相关性分析。其中最直观的的就是散点图。
图2和图3是都是信用卡发卡时间和持卡人年龄的散点图,为了使图中的变量分布更加清晰,所以改变其中横轴和纵轴的属性得到的两个图。上面两图很明显可以看出,信用卡发行时间Duration分布比较均匀。针对以上的数据分析,可以对连续定量型数据进行如下数据变换。
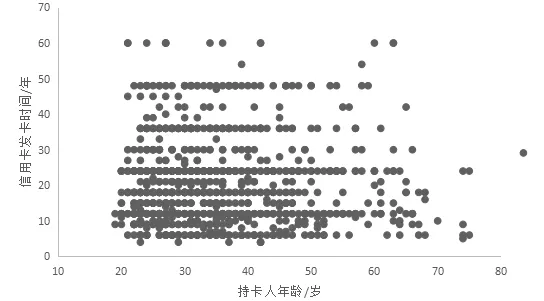
图2 信用卡发卡时间和持卡人年龄的散点图
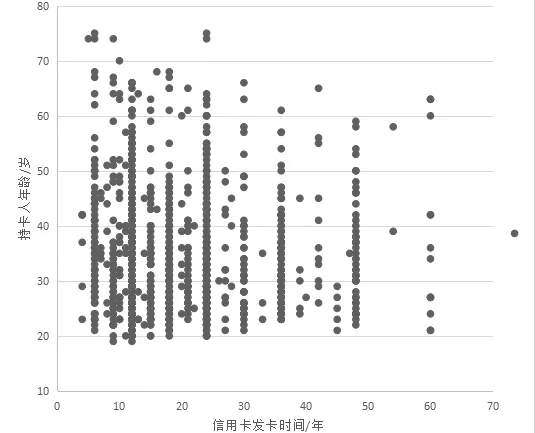
图3 信用卡发卡时间和持卡人年龄的散点图
age:(18,25,35,60,100)
↓
age:[’Student’,’Youth’,’Adult’,’Senior’]
duration:(0,12,24,36,48,60,72,84)
↓
duration:[’year1’,’year2’,’year3’,’year4’,’year5’,’year6’,’year7’]
Credit amount:由于Credit amount属性值很大,不进行数据处理会影响数据挖掘的结果,所以为了消除指标之间的量纲和取值范围差异的影响,需要进行归一化处理。归一化处理也叫数据规范化,主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速,便于进行综合分析。
3)经过之前的几次数据变换,除了sex,Credit amount,risk这三个属性之外,其它的属性都是离散的,定序型属性。通常对这些数据要进行特征数字化。但是普通的数字特征处理并不能直接放入机器学习算法中。所以针对这一现象,本文进行数据的独热编码。独热编码,也称one-hot编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。One-Hot编码是分类变量作为二进制向量的表示。这首先要求将分类值映射到整数值。然后,每个整数值被表示为二进制向量,除了整数的索引之外,它都是零值,它被标记为1。
(3)数据规约
在经过One-hot编码后,数据维度变得很大,同时也有可能出现一些无效,错误地数据。数据规约产生更小但保持原数据完整性的新数据集提高建模的准确性,也可以降低存储数据的成本,缩减数据挖掘所需的时间。数据规约包括属性规约和数值规约,针对处理后的数据,我们采取属性规约,主要的方法是主成分分析(pca)。pca是对数据高维度特征的一种预处理方法。它是将高维度的数据保留下最重要的一些特征,去除噪声和不重要的特征,从而实现提升数据处理速度的目的。
3.3 信用卡欺诈检测流程
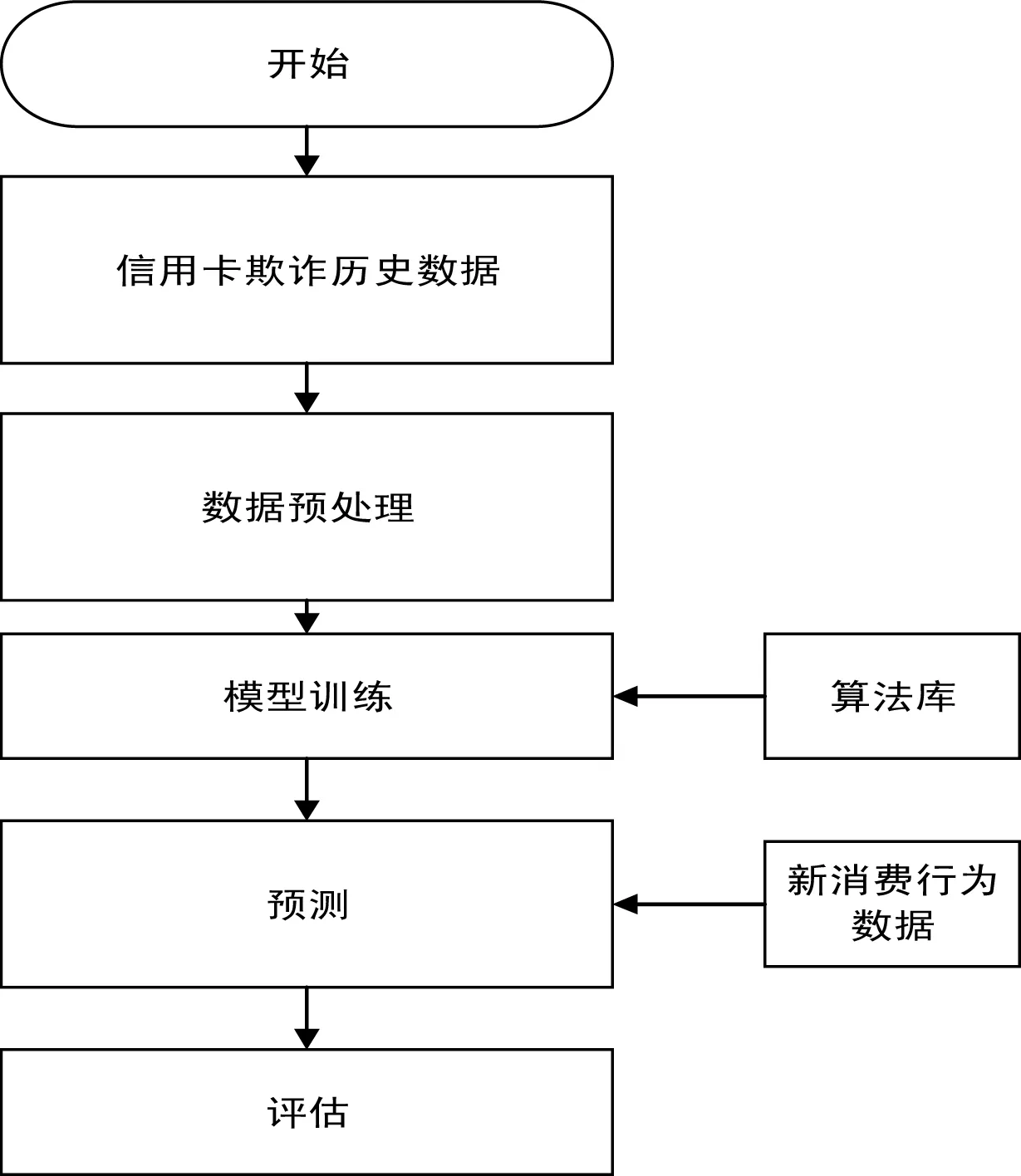
图4 信用卡欺诈检测流程图
(1)收集带标记的信用卡消费数据
(2)对信用卡数据进行预处理,包括数据清洗,数据变换,数据规约等,将试验数据变换成算法能识别的数据形式。
(3)数据划分:将试验数据划分为训练集和测试集,经试验证明训练集与测试集占比为1:3效果最好。
(4)利用支持向量机对训练样本进行学习,采用sklearn模块的GridSearchCV确定最优参数从而确定最优模型。
(5)采用最优检测模型对信用卡检测集进行检测,验证模型的有效性,并输出检测结果。试验
4 实验研究
4.1 验验环境
本次试验是在windows条件下的jupyter notebook平台下进行的。Jupyter基于开放标准,在Web前端使用HTML和CSS的交互式计算,在后端采用可扩展的kernel架构,内部使用WebSocket和ZeroMQ进行通信交互。核心是通过IPython实现,由IPython提供终端,IPython内核提供的计算和通信的前端界面。
4.2 数据预处理
原始数据来自UCI机器学习数据集网站,一共有1000条信用卡数交易数据,其中700条正常交易数据,300条交易欺诈风险数据。数据预处理是对这100条信用卡交易原始数据进行数据清洗,归一化,离散化,独热编码之后进行数据规约。数据预处理之后的数据作为欺诈模型的输入。
4.3 模型参数的选择
模型参数的调节是数据挖掘后期很重要的一个部分,尤其是调节网络参数,通常待调节的参数有很多,参数之间的组合更是繁复。依照注意力>时间>金钱的原则,人力手动调节注意力成本太高,非常不值得。For循环或类似于for循环的方法受限于太过分明的层次,不够简洁与灵活,注意力成本高,易出错。本文使用sklearn模块的GridSearchCV模块,能够在指定的范围内自动搜索具有不同超参数的不同模型组合,有效解放注意力。
4.4 模型的构建与检测结果的分析
(1)模型的构建
采用随机森林算法对经过预处理后,并且经过划分好的训练数据集进行训练,进而构建信用卡欺诈模型。并采用信用卡欺诈模型对测试集数据进行检测,进行测试的同时采用GridSearchCV去自动确定检测率最高的参数,并返回欺诈检测结果。
(2)检测结果与分析
在使用随机森林构建的模型进行欺诈检测之后,同时采用逻辑回归,支持向量机,XGBoost等对其进行对比检测。得出如下结果,结果如下表3。
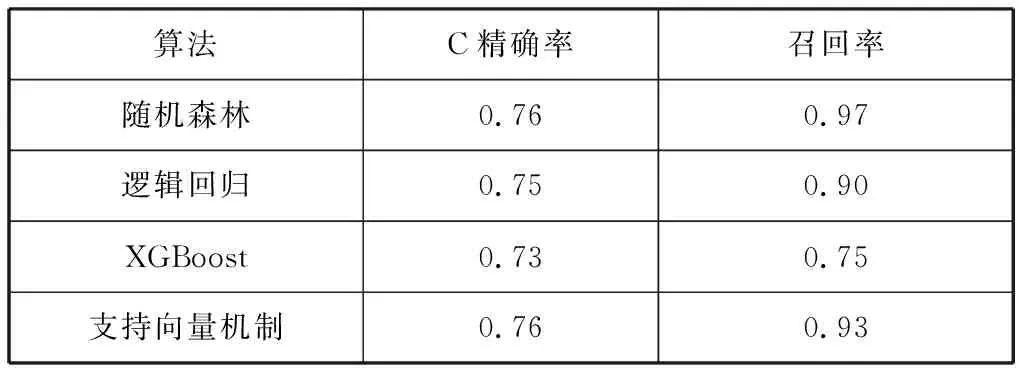
表3 算法结果表
从表3可以看出随机森林算法得出的精确率的方法是较好的,达到76%,并且它的召回率高达97%,是它们之中最高的。本文开始并没有给出一个明确的方法,因为目前大多数学者给出的方法都是建立在不用的数据前提之上的。数据量和数据维度的差异会对结果产生很大影响,所以本文从数据挖掘这个大的方向出发,把重点放到本次试验数据上,探索性的挖掘数据背后的信息,然后对比给出试验结果最好的方法。由于信用卡欺诈检测结果需要根据实际信用卡检测结果加以验证,即采用本文方法对信用卡数据检测出可能是欺诈行为后,还必须由银行机构对其进行进一步检查,才能最终确定本次交易行为是否存在欺诈行为,因此本文的信用卡欺诈检测方法主要作用是起到预警作用,提高银行机构对信用卡欺诈行为的效率。
结束语
随着信用卡的不断发展,未来肯定还会有各种各样的信用卡欺诈手段出现,本文从数据挖掘的角度出发,对信用卡欺诈进行检测,发现随机森林方法是信用卡欺诈检测的一个好的方法,但是和以往学者的研究对比,可发现之前的研究方法得到的结果并不一定是最好的。所以,针对以后的信用卡欺诈研究,一定要应用到实际数据中,不能生搬硬套其它研究成果,要从数据的角度出发,得出预实验数据相适应的最好方法。
猜你喜欢
眼科新进展(2022年12期)2022-12-29
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
汽车维修与保养(2019年7期)2020-01-06
电子技术与软件工程(2019年18期)2019-11-18
中国外汇(2019年16期)2019-11-16
中国外汇(2019年10期)2019-08-27
时代金融(2018年22期)2018-10-09
瞭望东方周刊(2017年35期)2017-09-22
电子技术与软件工程(2017年14期)2017-09-08
