
基于多图神经网络的个性化推荐模型
2020-04-16 05:29陈征宋轩杜先瑞张钟勤
中国传媒大学学报(自然科学版) 2020年6期
陈征,宋轩,杜先瑞,张钟勤
(1.中国传媒大学 协同创新中心互联网研究院,北京 100024;2.中国传媒大学 信息化处,北京 100024;3.中国传媒大学 协同创新中心大数据中心,北京 100024)
1 引言
随着互联网技术逐步更新发展,信息资源呈现高速增长的趋势,并出现了“信息过载”的问题。用户很难直接从海量信息中快速的获取自己所需要的信息。而推荐系统可以根据用户的历史交互数据,更清楚的了解用户的兴趣偏好,为用户推荐可能喜欢的物品,因此通常使用推荐算法来解决“信息过载”的问题,各种推荐方法[2-5,7-8]的研究成为计算机科学领域的研究重点之一。在推荐系统的研究过程中,由于数据多样性的发展,图计算成为一个非常重要的研究方向,其中图神经网络(Graph Neural Network,GNN)[1]被有效使用于图的表征学习中。与传统的图学习相比,图神经网络不仅既能学习图网络的拓扑结构,也能聚合邻居的特征信息,从而能够有效的学习到图网络中的各种结构,为后续的推荐工作起到关键作用。原有的推荐学习算法[2]主要基于用户与物品交互进行学习,对用户-物品的连接关系进行建模,难以捕获节点之间更复杂的关系。而传统的图学习一般针对图拓扑进行工作,也较少考虑节点间或节点的各种特征信息。
与原有的推荐方法相比,图神经网络推荐方法不仅能学习图网络的拓扑结构,也能聚合邻居节点的各种相邻关系,从而能够更有效的学习到图网络中的信息,为后续的推荐工作起到关键作用。Monti等人[3]使用图神经网络来提取用户和物品的网络表征,然后结合递归神经网络进行消息传递过程。Berg 等人[4]提出了一种图自动编码框架,通过在用户-物品图上传递消息聚合的形式,生成用户和物品的潜在特征。Hartford等人[5]考虑了两个及多个不同的对象集合之间的关系预测问题,并向深度模型中引入了一个权重绑定方案。这些模型通常仅使用了用户-物品的单图交互信息,忽略了现实存在更多更丰富的多图信息,如物品间的交互信息和物品侧信息等。通常用户与物品之间的交互不仅仅有评分信息,还有更多如用户曾浏览过、购买过的其他物品与物品之间的交互信息。
针对以上问题,本文提出了一种基于多图神经网络的个性化推荐模型,该模型利用了图神经网络能够更有效的挖掘图数据的深层信息的特性,将输入的用户评分信息与物品侧信息转变成多个图(包括用户-物品图、物品-信息图等)进行有效特征提取。该模型使用图神经网络经过节点上的信息传递和信息聚合,有效的对用户偏好信息进行建模,同时引入注意力网络,最后得到评分预测。
2 基于多图神经网络的推荐模型
2.1 整体框架
本文模型由以下部分组成:用户特征建模,物品特征建模和评分预测。用户特征提取部分使用用户-物品图来对用户的偏好特征进行建模,通过用户对物品的交互可以有效提取用户的偏好;物品特征建模使用物品-用户图和物品-信息图,通过物品的交互用户以及物品的辅助信息来建模物品特征;评分预测将用户特征和物品特征聚合,并进行评分预测。整体模型框架如图1所示。下面将详细介绍每个模块。
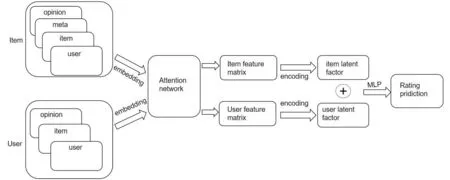
图1 模型框架
2.2 用户特征建模
由于用户-物品图中不仅包含用户、物品之间的交互信息,而且还包含用户对物品的评分信息。因此使用图神经网络同时捕获用户-物品图中的交互信息和评分信息,以便学习用户的特征向量U (user item factor),它通过用户-物品图中的交互信息以及用户对物品的评分来对用户特征向量进行建模。函数的数学表示为:
U=σ(W·Accumi(pij,∀j∈I(i))+b)
(1)
其中I(i)是与用户ui(或用户-物品图中的ui的邻居)有交互的物品的集合,pij是表示ui与项目vj之间的评分感知交互的表示向量,σ表示非线性激活函数(即校正线性单元),W和b是神经网络的权值和偏差。一个常用的聚集函数Accumi()是取(pij,∀j∈I(i))中向量的元素平均值的平均算子。该基于平均值的聚合器为局部谱卷积的线性近似。我们通过给每个评分分配权重允许交互对用户的特征向量做出不同的贡献,同时使用Softmax函数对上述权重进行归一化,得到最终权重值,该值可解释为评分对用户ui的项目空间用户特征向量的贡献量。
2.3 物品特征建模
在物品特征建模部门,使用图神经网络同时捕获物品-用户图中的交互信息和物品-信息图中的交互信息,对项目vj进行项目建模,以此学习项目的特征向量,记为Ι。
第一,项目与用户-项目图相关联,其中包含交互和用户的评分。因此,需要联合捕获用户-项目图中的交互和评分,进一步构建项目特征向量。第二,项目与项目-侧信息图相关联,其中包含跟此项目有关的丰富的侧信息。
第一步,我们通过用户聚合来学习项目空间项目的特征向量IU。对于每个项目vj,我们需要从与vj交互的用户集合中聚集信息,表示为U(j)。即使对于同一个项目,不同的用户也会有的不同的评分。这些来自不同用户的评分有助于对项目特征向量进行建模。对于带有评分的从ui到vj的交互,我们引入了一种评分感知交互用户表示qij,它是由用户嵌入和评分嵌入通过MLP获得的然后,为了构建项目特征向量Ι,我们还提出了对项目vj在U(j)中用户的评分感知交互表示进行聚合。用户聚合函数为Accumu(),这是聚合(qij,∀i∈U(j))中的用户可感知评分的交互表示,由此有,
IU=σ(W·Accumu(qij,∀i∈U(j))+b)
(2)
第二步,我们使用同样的方法对侧信息进行聚合,以此来学习侧信息空间项目的特征向量II。对于每个项目vj,我们从与vj有关的侧信息集合中聚合信息,表示为M(m)。同时将与项目vj有关的侧信息的交互表示为tjm,这是由项目嵌入与侧信息嵌入通过MLP获得的,由此有,
II=σ(W·Accumm(tjm,∀m∈M(j))+b)
(3)
学习项目特征向量。为了更好地学习项目特征向量,需要将用户空间项目特征向量和侧信息空间项目特征向量结合起来考虑,因为侧信息图和用户-项目图从不同的角度提供用户信息。我们建议通过一个标准的MLP将这两个特征向量结合到最终的项目特征向量中,其中用户空间项目特征向量IU和侧信息空间项目特征向量II在进入MLP之前连接在一起。形式上,项目特征向量Ι定义为,
d1=[IU⊕II]
(4)
d2=σ(W2·d1+b2)
(5)
……
I=σ(Wl·dl-1+bl)
(6)
2.4 评分预测
在用户特征建模部分获得用户的特征向量U。在物品特征建模部分获得物品的特征向量Ι。通过将用户和项目的特征向量(即U和Ι)进行串联,然后将其输入MLP可最终进行评分预测。
3 实验
为了验证本文提出的模型性能,将在真实数据集上对融合注意力机制的图神经网络推荐模型MGNR和一些常用的推荐模型进行对比实验并分析。
3.1 数据集
实验使用了3个不同的公开数据集来评估MGNR,分别是来自亚马逊的Toys、Office数据集和Douban数据集。其中亚马逊的数据集来源自文献[6]。这几个数据集的评分都是[1,2,3,4,5]。各数据集统计信息如表1所示。
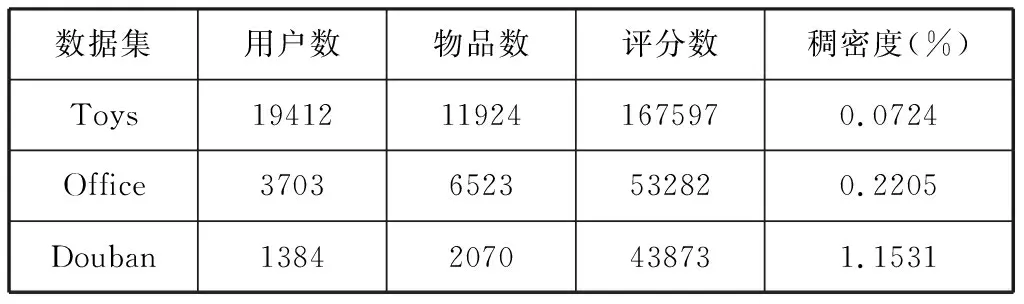
表1 数据集统计
3.2 评价指标
为了评价推荐算法的质量,采用了常用的预测精度指标均方根误差(RMSE)。RMSE值越小,预测精度越高。RMSE的公式如下:
(7)
3.3 超参数
本文在以上3个数据集上进行了多组实验,本模型的嵌入层大小取值为8,16,32,64,128。批处理大小分别取值32,64,128,512。同时在使用dropout机制来防止过拟合,参数分别取0,0.1,0.3,0.5,0.8,1.0。我们将测试训练比设置为0.8/0.2。其他模型为原始模型参数。
3.4 算法对比
本文选取一下几种常用的推荐算法与我们的模型进行对比:
PMF[2]:概率矩阵分解模型,其仅利用用户物品评分矩阵,通过高斯分布对用户和物品的特征向量进行建模;
GCMC[4]:一种图自编码器框架,从链路预测的角度解决推荐系统中的评分预测问题;
Factorized_EAE[5]:通过预测两个或多个不同对象集元素之间的关系来完成矩阵补全的工作;
MGNR:本文基于多图神经网络的推荐模型,利用了评分与物品等多图信息改进预测;
3.5 实验结果与分析
3.5.1 算法对比和分析
从表2中可以看出我们的模型MGNR在3个数据及上的表现都是最好的,其次是Factorized_EAE和GCMC,最后是PMF。虽然都是矩阵补全,但是Factorized_EAE比GCMC多了多种不同对象集元素之间的关系,所以Factorized_EAE比GCMC的效果要好;而GCMC利用图自编码器,效果又比PMF的矩阵分解要好。而我们的模型利用图神经网络,能够有效捕获多图深层的用户和项目信息来进行用户偏好的建模,因此效果最好。
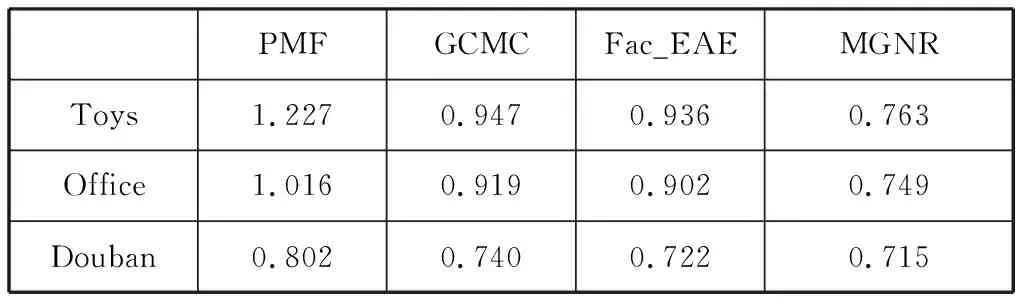
表2 实验结果对比
3.5.2 参数影响性分析
在神经网络的模型中,嵌入层的大小是模型中重要的超参数之一。这里,我们将比较本模型在不同嵌入大小下的性能,由于参数将经过较多测试,故选取相对较小的Douban数据集。而神经网络中,批处理大小也是一个重要参数,即一次训练所选取的样本数。这里需要与迭代次数区分开来,迭代次数指的是一个完整数据集的训练次数,而批处理大小是指在一个迭代里每次训练选取的样本数。对于大数据集而言,选取合适的批处理大小尤为重要,这将影响到模型的运行效率。
从图2可以看出随着嵌入层大小d的增大,模型的训练效果也明显变好,这是由于嵌入维度越多,对于节点的特征描述就越详细,相应的模型精度就越好。但是嵌入层大小也不是越多越好,可以看到当嵌入层大小为128时,指标与64相比反而升高了。这说明使用大量的嵌入层具有强大的表示能力。然而,如果嵌入的长度过大,模型的复杂性将显著增加。因此,我们需要找到合适的嵌入层长度,以平衡性能和复杂性之间的关系。本文选取的最佳嵌入大小为64。
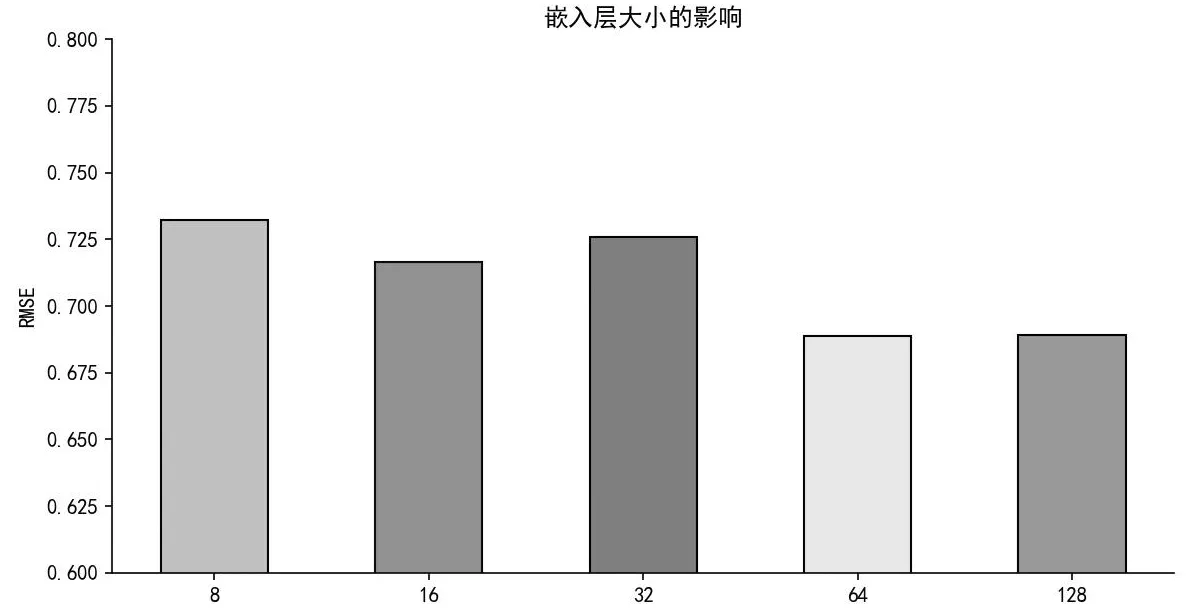
图2 嵌入层大小的影响
从图3可以看出随着批处理大小的增大,训练用时在不断减小,但是模型效果并不是随着批处理大小的增大而逐渐变好。当批处理大小为32时,RMSE是最大的且用时也是最长;当批处理大小为64时,RMSE值是最小的。当批处理大小为512时,用时是最少的,但RMSE表现不佳。因此,考虑预测最优时应选取批处理大小为64。如考虑预测与用时均衡时,应选取128作为批处理大小的值,因为当批处理大小为128时预测效果与64十分接近,但用时较少。
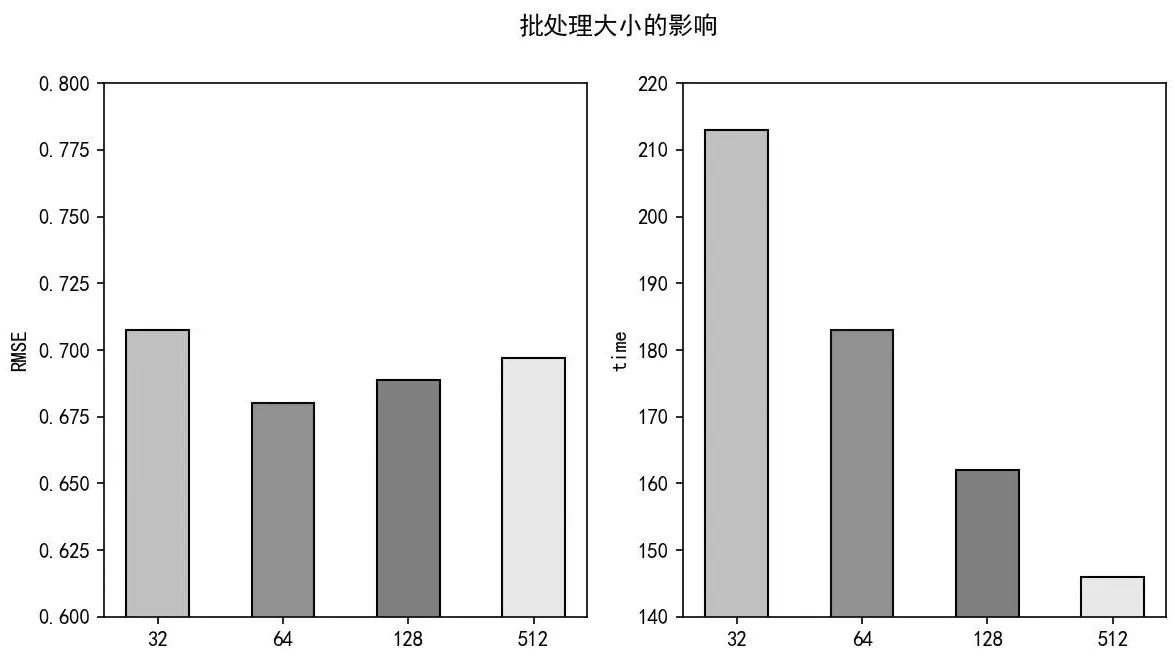
图3 批处理大小的影响
4 结论
用户的历史评分信息与物品的侧信息对于推荐系统来说都是起决定因素的,但是由于传统模型对于这些图信息的信息挖掘不够充分。因此本文提出了一种基于多图神经网络的个性化推荐算法MGNR,采用了图神经网络来对如用户物品图等多个图数据进行挖掘建模,以此提升推荐效果。相比于传统的推荐模型,该模型能更好的从多种信息中提取用户和物品特征。在3个公开数据集上的实验结果表明,我们的模型具有更好的性能效果。由于本文提出的模型基于图神经网络,而图神经网络方法也带来了更高的计算复杂度,在未来的工作中,我们将尝试在不降低准确度的同时,对模型进行效率上的优化;同时也将继续尝试将更多的信息融入到模型中来,以实现模型的优化。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
小学生学习指导(低年级)(2022年5期)2022-05-31
保定学院学报(2022年2期)2022-04-07
疯狂英语·初中天地(2021年11期)2021-02-16
科学导报·学术(2020年84期)2020-11-08
电脑爱好者(2019年1期)2019-10-30
少年漫画(艺术创想)(2019年2期)2019-06-06
数学学习与研究(2018年15期)2018-11-12
电脑爱好者(2017年18期)2017-11-03
小天使·一年级语数英综合(2015年8期)2015-07-06
