
同步语言Lustre的编译前端的设计与实现
2020-04-15 02:59:30宋宇婷孙小祥
计算机技术与发展 2020年2期
宋宇婷,孙小祥,冉 丹
(南京航空航天大学 计算机科学与技术学院,江苏 南京 211100)
0 引 言
随着计算机技术的飞速发展,人们的工作、学习和生活各个方面都越来越依赖于计算机技术以及计算机技术的产物,它们已经成为人们工作、学习和生活中不可分割的一部分。近年来,它们的安全性和正确性等方面也受到越来越多的关注。因为,一个小小的错误很可能造成很严重甚至是不可挽回的后果。为了保证系统设计的正确运行,需要一种可靠的编译器,它能够检测到词法语法等方面的错误,并将错误反馈出来,帮助及时修改系统程序,保证系统的正确运行。编译器的构建分为前端和后端两大部分,前端主要是负责分析输入的源代码,对源程序进行词法分析、语法分析和语义分析[1-2]。同时,前端还会将分析的有效信息保存起来,传递给后端。
传统的同步语言Lustre的编译器前端大都采用OCaml语言编写,OCaml语言是一种函数式编程语言[3],适用度没有C++语言[4-5]高,C++语言是开发人员和用户们最易于使用和易于理解的语言之一。新型的Lustre语言的编译前端采用C++语言进行描述,可以准确地编译Lustre语言程序,保证Lustre语言所描绘的模型的正确运行。这对航空航天、国防建设、核电建设、金融监管等领域具有重要的意义。编译前端所产生的抽象语法树结构的实际应用也很广泛,既可以应用于编译器后端的开发,也可以应用于模型检测、软件验证等工具的开发。目前,国外比较成熟的是Kind和Kind2[6],而国内对同步语言Lustre及其编译器的研究比较少,L2C编译器是比较成熟的[7-8]。
1 系统分析
新型的Lustre语言的编译前端,提供了一种新型的检验Lustre语言所描述的模型是否正确的方法。如果Lustre语言所描述的模型是基本正确的,不存在任何词法和语法的错误,系统会正确地输出Lustre语言模型的抽象语法树;否则,系统会给出词法或者语法错误的提示。为了保证系统的正确性和可靠性,系统应该具备如下的性能需求。
(1)词法规则和语法规则的正确描述。系统在对Lustre语言模型进行词法分析和语法分析时,应该严格按照Lustre语言的说明文档进行解析;否则,很可能造成无法正确解析Lustre语言模型,给出错误结果,影响系统的正确运行。
(2)信息处理的准确性。当Lustre语言模型存在任何词法和语法错误时,系统能够及时快速地给出反馈信息,将模型的第几行存在词法错误或者语法错误的提示消息发送给用户,保证用户能够及时进行Lustre语言模型的更正。
2 系统的设计与实现
2.1 同步语言Lustre
同步语言Lustre是一种常用的数据流语言,其基本的数据对象是流[5]。一个同步语言程序就是一个函数,具有零个或者更多的输入流以及一个或者更多的输出流,一个流就是一个变量值的序列。在同步语言Lustre程序中,任何变量和表达式都诠释了一个流,一个流是由给定类型的变量的无穷多序列值和一个时钟组成的[9-10]。流通常用(a,b,c,d,e)表示,括号内的a,b,c,d,e表示流在某个时刻点所对应的值。同步语言Lustre的时序操作符主要包括如下几种:
(1)pre(previous):求变量或者表达式的前一时刻的序列值。比如,整数型变量X的当前值为(x1,x2,…,xn,…),那么,pre(x)=(nil,x1,x2,…,xn-1,…)。
(2)->(followed by):定义了前一个表达式被后一个表达式赋值之后的初始值。比如,X=(x1,x2,…,xn,…)和Y=(y1,y2,…,yn,…)是相同类型且具有相同时钟的两个表达式,那么X->Y是与X和Y具有相同类型和相同时钟的表达式,且X->Y=(x1,y2,y3,…,yn,…)。这意味着,除了时钟的第一时刻,X->Y总是等于Y。在Lustre语言中,时序操作符->也可以采用关键字fby的形式进行表示,即:X->Y与XfbyY的含义是相同的。
(3)when:作为下一条语句执行的条件,与C语言中的when类似。如果X是一个表达式,B是一个布尔表达式,而且它们有相同的时钟,那么XwhenB是一个表达式,且它的时钟由B决定。但是,要注意的是,XwhenB表达式的值是在B为true时所对应的B的序列值。比如,B=(false,true,false,true,false,false,true),X=(x1,x2,…,x7),那么,XwhenB=( ,x2, ,x4, , ,x7)。
(4)current:求变量或表达式的当前序列值。基于when时序操作符中的例子,假设Y=current (XwhenB),那么,Y=(nil,x2,x2,x4,x4,x4,x7),其中nil表示空值。
2.2 Lustre语言的词法分析设计
词法分析的主要任务是从左到右读入源程序的输入字符,然后根据构词规则识别单词符号。实际上就是将源程序翻译为词法单元,并将词法单元作为语法分析的输入[11]。通常情况下,词法单元分为如下的五大类。第一类是关键字词法单元,程序语言中的每个关键字都有一个词法单元,词法单元名就是关键字的大写。比如:Lustre语言中的VAR(var)、RETURNS(returns)等词法单元。第二类是运算符词法单元,每个运算符可以有一个独立的词法单元,也可以按照运算符的阶数或者含义进行分类。比如:Lustre语言中的FOLLOWBY(->)、PRE(pre)等。第三类是表示所有标识符的词法单元,比如程序中定义的变量名和数组名等。第四类是表示常量的词法单元,比如:INTEGER([1-9]+[0-9]*|0)。第五类是标点符号词法单元,而且,每个标点符号都有一个词法单元。比如:SEMI(;)、COMMA(,)等。除了关键字类的词法单元名,其余类别的词法单元名一般都是相应符号的英文名称的缩写。在Lustre语言中,逻辑运算符也是以关键字的形式表示的,所以,这类运算符词法单元要加入到关键字词法单元中。而且,这些词法单元都作为终结符号。Lustre语言词法单元的部分定义如表1所示。
2.3 Lustre语言的语法分析设计
语法分析的主要任务是将单词序列组合成各类语法短语,如“程序”、“语句”、“表达式”等等,实际上就是将词法单元翻译为抽象语法树。语法分析的目的是判断源程序在语法结构上是否符合正确的语法规则,而源程序的结构通常由上下文无关文法描述[11]。
Lustre语言的编译前端的语法分析模块主要是通过查找可以与当前记号进行匹配的规则来进行操作。主要的算法思想为:当语法分析模块读取符号时,每当它读取到的符号无法结束一条Lustre语法规则时,它会把这个符号压入一个内部堆栈,形成一个新的状态,这个新的状态能够反映出刚刚读取的字符。如果语法分析模块发现压入的所有字符正好可以组成语法规则的右部时,就将右部符号全部弹出堆栈,并将与语法规则右部对应的语法规则的左部符号压入堆栈,这个过程被称为“规约”。持续上面的进栈和规约过程,直到所有的Lustre语言的字符都已经扫描完毕。最终,所有的Lustre语言模型都会被规约为“Program”。其中,“Program”代表着所有Lustre语言程序的开始符号。
为了避免在词法分析和语法分析时出现二义性冲突,必须将关键字和特殊符号的定义与语法规则的相关定义进行优先处理。本次实验将关键字和特殊符号的定义放在标识符的定义之前进行判定和处理。

表1 词法单元的定义
2.4 抽象语法树的结构设计
抽象语法树类ASTNode[12-13]定义了五个属性,一个用来记录该节点的父节点的变量parent;一个用来记录节点的开始位置的变量location;一个用来记录该节点在源程序中的位置startPosition,startPosition的初始值被设置为-1;一个bool类型的用来判断该元素是否是必要的变量MANDATORY,此变量的初始值被设置为true(表示当前的元素是必要的,不可缺少的);一个bool类型的判断操作的变量OPTIONAL,这个变量的初始值为false(表示当前的操作是不可以为空的)。如果一个变量带有OPTIONAL属性,就表示这个变量可以为空,否则这个变量的值是不可能为空的。抽象语法树类ASTNode还定义了几个方法,主要包括一个设置父节点的函数setParent(),一个获取父节点的函数getParent(),一个获取根节点的函数getRoot(),一个删除当前节点的部分属性的函数deleteNode()。
函数getRoot()的算法思想主要是先调用getParent()函数获得当前节点的父节点,然后判断这个父节点是否为空,如果父节点为空,就返回这个父节点,即:根节点;否则,就继续循环地判断这个父节点的父节点是否为空,直至满足前边的所有判断条件为止。函数getRoot()的伪代码如图1所示。

图1 getRoot()的伪代码
类ASTNode中的函数deleteNode()的算法思想是首先调用getLocation()函数,获取到节点的开始位置,然后判断这个开始位置是否为空,如果为空,系统就什么都不做。再然后,判断这个开始位置是否是ChildProperty类别的,如果属于此类别,就先调用getParent()函数获得当前节点的父节点,此父节点会调用setStructuralProperty()函数设置结构属性。最后,判断这个开始位置是否是ChildListProperty类别的,如果属于此类别,就先调用getParent()函数获得当前节点的父节点,此父节点会调用getStructuralProperty()函数获取结构属性,再将获取到的结构属性赋值给孩子节点列表childList。删除节点的属性的函数deleteNode()的伪代码如图2所示。

图2 deleteNode()的伪代码
3 实验结果展示
同步语言Lustre的编译前端系统的实验对象为图3所描绘的Lustre语言模型,Lustre语言模型实例如图3所示。
图3描述的Lustre语言模型实例包含了四个node函数单元,第一个node函数单元名为compute,主要包含了算术运算符加、减和乘;第二个node函数单元名为E,主要包含了时序操作符->和pre,以及逻辑运算符与(and);第三个node函数单元名为call_E,调用了第二个node函数单元,主要包含了逻辑运算符非(not);第四个node函数单元名为Switch,主要包含了if-then-else表达式。在同步语言Lustre中,if-then-else的使用比较特殊,它们不再代表常见语言C/C++中的if-then-else语句,而是以表达式的形式展现,通常作为赋值表达式的右部。

图3 Lustre语言模型实例
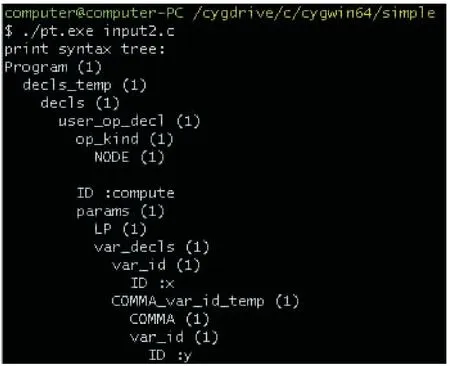
图4 Lustre语言模型的实验效果
图4描述了基于图3所描述的Lustre语言模型实例的部分实验效果。图4中的所有大写字母节点代表了程序中的终结符,都是抽象语法树的叶子节点;其余节点都是进行语法规则推导时需要按照语法规则说明定义的非终结符号。其中,每个孩子节点都会相对于它的父节点缩进两格输出,兄弟节点的输出则是处于同等水平的。比如,图4中的“Program(1)”表示Lustre语言程序的整体定义是在源程序的第一行开始的,它的孩子节点为“decl_temp(1)”。节点“decl_temp(1)”的孩子节点为“decls(1)”,表示Lustre语言程序的声明也是从源程序的第一行开始的。节点“ID:x”和节点“COMMA(1)”就是兄弟节点,表示标识符x(node函数单元compute中定义的一个变量)和关键字分号(;)是同级别的。其余节点的含义以及节点之间的关系都与这几个节点类似。
4 结束语
新型Lustre语言的编译前端的设计与实现准确地编译运行了Lustre语言程序,保证了Lustre语言程序不存在任何词法和语法的错误,为编译后端和模型检测等方面的研究提供了坚实的基础。经过检测,新型的Lustre语言的编译前端可以准确地检测所有Lustre语言程序。由于新型的Lustre语言的编译前端采用C++语言进行设计,非常易于相关人员的理解和使用。未来,会有越来越多的计算机学者加入对同步语言Lustre进行编译和检测研究的行列,也会出现更加成熟的Lustre语言编译工具。
猜你喜欢
科学24小时(2021年10期)2021-10-09 23:09:37
数学物理学报(2020年2期)2020-06-02 11:29:10
安顺学院学报(2020年1期)2020-04-05 10:57:20
现代计算机(2019年6期)2019-04-08 00:46:50
科技经济市场(2017年5期)2017-09-16 19:20:11
海外华文教育(2016年3期)2017-01-20 08:22:19
价值工程(2014年17期)2014-04-16 03:29:20
长春大学学报(2012年10期)2012-09-21 07:14:12
商(2012年11期)2012-07-09 19:07:55
中学生英语高效课堂探究(2011年4期)2011-07-07 01:48:30
