
一种OpenStack的业务保障设计
2020-04-09 04:48陈垦
计算技术与自动化 2020年1期
关键词:云计算
陈垦
摘 要:基于OpenStack云计算管理平台的原生资源管理技术,通过对接兼容Vmware云计算管理平台,来实现一种更为合理高效的业务保障技术。通过配置高可用HA来保障物理机、逻辑节点、裸机和虚拟机的业务可用性。通过可用域设置DRS来保障虚拟机的业务连续性。
关键词:OpenStack;云计算;HA
中图分类号:TP39 文獻标识码:A
A Business Support Design for OpenStack
CHEN Ken?覮
(Wuhan Research Institute of Posts and Telecommunications,Wuhan,Hubei 430079,China)
Abstract:This article achieve a more reasonable and efficient business support technology through docking compatible VMware Cloud management platform based on OpenStack Cloud computing management platform of native resource management technology. Securing the business availability of physical machines,logical nodes,bare metal,and virtual machines by configuring high-availability HA,and securing the business continuity of virtual machines by setting up DRS with available domains.
Key words:OpenStack;Cloud computing;HA
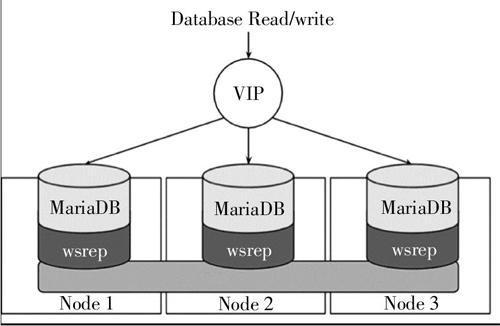
云计算以其高效迅捷的部署和灵活的资源管理得到了众多支持,并且成为一种成熟的商业模式。云计算通过提供基础设施或者平台,来为用户实现快速部署和应用,并以租赁的方式盈利[1]。在如今庞大的网络体系中,云计算的出现提高了资源的利用率,使得上层用户能够专注于开发,而不受底层影响。可以说,云计算的发展是网络发展的必然,也是未来最受关注的领域之一[2-3]。作为提供服务的云计算厂商来说,提供一种稳定的计算与存储业务才能够获得用户的青睐。使用KVM虚拟化技术的OpenStack云计算管理平台受其社区开源性的制约,并没有采用Vmware、EC2、Xen等商用虚拟化技术的方案,而是自己开发了一套技术集。由于OpenStack是协同开发的产物,早期的版本并不重视业务稳定性与可靠性管理,而是以有效性为主要目的[4]。随着OpenStack版本的不断迭代以及使用率上升,各种原生方案与第三方方案开始部署于各个OpenStack云计算商的产品中,其中比较流行的方案有两种,一种是Load Balancer + Keepalive保证HA(High Availability)[5];还有一种是Load Balancer + Keepalive + Pacemaker + Corosync 配置 HA,它们都可以某种程度上保证OpenStack的业务可靠性[6]。然而以上方案存在一定的缺陷,Load Balancer虽然可以让系统达到网络访问的负载均衡,但却没办法解决内存、CPU等资源的负载不均衡问题[7];Keepalive实际上是通过配置一个虚拟IP地址来隐藏实际节点IP,而虚拟IP作为一个分发访问任务的中间站,将访问均衡分配到不同的实际节点上,如图1所示,同样没法直接均衡内存与CPU的负载。本文基于OpenStack原生技术,结合VMware的技术,通过对接OpenStack与VMware平台,从而调用DRS(Distributed Resource Scheduler)技术设计一种对OpenStack平台下管理的实例进行动态资源调度的方案,先于负载超过阈值前均衡内存与CPU,保障业务稳定性[8]。
图1 虚拟IP的使用
1 OpenStack原生业务保障
1.1 OpenStack静态资源调度
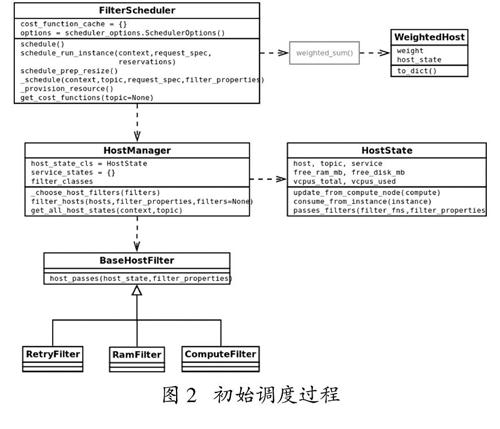
业务保障基于OpenStack的资源调度,资源调度分为静态调度与动态调度,其中静态调度是最为基本,也是实现正常功能所需的技术。静态调度也可称之为初始调度,它是实现实例(虚拟机)所进行的最开始的步骤。OpenStack的虚拟机调度策略主要是由FilterScheduler和ChanceScheduler实现的,其中FilterScheduler作为默认的调度引擎实现了基于主机过滤(filtering)和权值计算(weighing)的调度算法,而ChanceScheduler则是基于随机算法来选择可用主机的简单调度引擎[9]。在设计上,OpenStack基于filter和weighter支持第三方扩展,因此用户可以通过自定义filter和weighter,或者使用json资源选择表达式来影响虚拟机的调度策略从而满足不同的业务需求。
所谓filter,是在选取资源(主要是计算资源)时,设立一系列规则和门槛,从而使得OpenStack在创建实例时能够尽量平衡,不会产生一台机器超负荷运转而其他机器空闲的情况[10]。理想的情况下,所有的机器能均分所有负载,比如要运行5个实例,那么就会依次运行于5个计算节点上(如果计算节点数量大于或等于5);如果要运行3个计算节点,那么就有两个节点运行两个实例,一个节点运行一个实例,从而实现尽可能的平衡。
以上是一种理想的情况,实际情况是创建的实例有着不同的资源需求(比如所需内存和CPU不同)。这就使得分配实例的时候不能单纯的看数量,而应当考虑到资源,也就是从数量的平衡转移到资源的平衡。假设所有计算节点的能力基本一致,实际情况可能会存在不同的实体机混用,这也造成了计算节点的性能不一致。同时,有些计算节点也运行着其他服务,对内存和CPU资源的过度占用可能会影响其他服务。因此,针对不同的实体机,可能会配置不同的规则,比如可以配置某个节点最多承载5个实例,或者配置其最多负载50%的内存或CPU,以此来人为留出余裕。
Filter的过滤条件有许多,可以是可用域,内存,CPU,磁盘,image等等。当经过这些条件筛选后的节点就会进入weight的过程,即根据一定的评分标准进行优先级的排序。比如默认为根据计算节点空闲的内存量计算权重值,空闲越多的节点权重越高,优先级越高,会优先承载实例,如图2所示。
图2 初始调度过程
1.2 OpenStack的HA
实例创建之时OpenStack会进行静态的资源调配,这意味着分配好的资源在实例创建之后就不会进行变化,但是实际应用中这样是存在风险的。某个计算节点可能会无法正常工作,比如网线断开,电源断开,或者是某人不小心重启了网络服务,以及其他种种导致不能正常承载实例的错误。这样的错误一旦发生而实例无法继续维持,可能会造成业务的中断,也会成为云计算最大的风险。于是一种用于应急灾备的方案被用于OpenStack——高可用HA。
高可用HA系统力求最大限度地减少以下问题:
1. 系统停机
2. 数据丢失
大多数高可用性系统仅在发生故障时才能保证防止系统停机和数据丢失。但是,它们也可以防止级联故障,在这种情况下,一次故障的发生就会恶化为一系列相应的故障。许多服务提供商保证服务级别协议 (SLA),包括计算服务的正常运行时间百分比,该协议是根据可用时间和系统停机时间 (不包括计划停机时间) 计算的[11]。
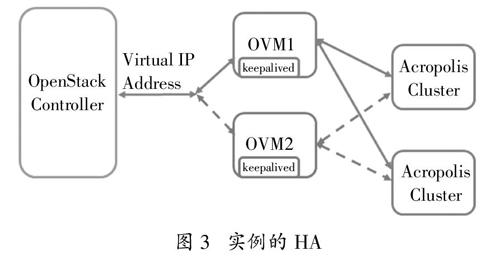
图3 实例的HA
如图3所示,OVM1和OVM2是两个实例,通过Virtual IP可以依次访问它们。当它们都运行了keepalive时,即使所在的Cluster发生了宕机,也可以安全转移至其它可用的Cluster。
OpenStack目前满足其自身基础结构服务的高可用性要求,这意味着接近百分百的正常运行时间对于OpenStack基础架构本身来说是可行的[12]。但是,OpenStack不能保证单个客户实例的可用性接近百分百。
集群最小数量被定义为一半以上的节点数量,高可用性环境中的每个集群都应该有奇数的节点。如果多个节点失败,使集群数量大小低于最小数量,则集群本身将故障。
例如,在七節点集群中,最小数量应设置为 floor(7/2) + 1 = 4。如果最小数量是四个节点,而四个节点同时故障,则集群本身将故障;如果不超过三个节点故障,则集群继续正常工作。如果拆分为三个节点和四个节点的分区,则四个节点的最小数量将继续决定分区工作状态。
当四个节点同时故障时,集群也将继续工作。但是,如果拆分为三个节点和四个节点的分区,三个节点的最小数量将使双方都试图隔离其他资源和主机资源。如果不启用Fence,它将直接运行每个资源的两个副本。
2 应用DRS
VMware的分布式资源调度(Distributed Resource Scheduler,DRS)可以持续不断地监控资源池的利用率,并能够根据商业需要在虚拟机中智能地分配合适的资源。通过这样的动态分配和平衡计算资源,IT架构和商业目标就可以达成同步。VMware DRS能够整合服务器,降低IT成本,增强灵活性;通过灾难修复,减少停机时间,保持业务的持续性和稳定性;减少需要运行服务器的数量以及动态地切断当前未需使用的服务器的电源,提高了能源的利用率。
DRS与HA原本是VMware的技术,随着VMware进入OpenStack社区并提供支持后,两者之间的融合逐渐加深。在新的OpenStack版本中,对接VMware虚拟机以及相应的HA与DRS技术已经可以实现。
DRS可以在平台平稳运行时根据配置,协调各个节点之间的负载,实现一定范围的负载均衡。举个例子,当设置策略为CPU使用率平衡某个节点的CPU使用率,一旦超过了阈值,就会触发DRS功能,节点上就进行相应操作来使得CPU降低到某一水平(通常是执行迁移实例来释放CPU资源),同样的,也可以设置内存模式来达到控制内存使用率。
2.1 OpenStack对接VMware的方案
在OpenStack的新版本中,社区在Nova中提供了两种连接VMware的Driver,分别是ESXDriver和VCDriver。前者由于丢失了一些VMware的集群特性诸如HA和DRS,已经逐渐被抛弃,因此本文选择后者作为接口驱动。
由于需要纳管VMware虚拟机,而OpenStack原生的KVM与VMware是不同的虚拟化方式,因此我们需要使用一个独占的物理节点来配置VMware。并且由于VCDriver的局限性,我们还需要在VMware的节点上安装vCenter。
VMware提供了一种用于OpenStack的计算驱动,名为VMware Nova vCenter Driver,其与OpenStack的交互如图4所示。
实际上OpenStack只是起到一个控制的作用,由控制节点下发指令,最终还是靠vCenter来完成ESXi主机的控制。上文提到的VMware vCenter Driver会让Nova-Scheduler将ESXi主机看作OpenStack中一个普通的计算节点进行管理,这样在OpenStack看来,纳管的VMware主机就不具有太多的特殊性,只要通过驱动进行中间代理就能够下发指令。
图4 Nova vCenter Driver与OpenStack的交互
VMware节点的配置和vCenter的安装过程较为繁琐且并非本文所关心的要点,因此本文不再详细赘述。在成功配置好VMware节点并安装好vCenter后,需要在OpenStack的控制节点上修改Nova服务的配置文件,即nova.conf文件,具体配置如下:
[DEFAULT]
compute_driver=vmwareapi.VMwareVCDriver
[vmware]
host_ip=
host_username=
host_password=
cluster_name=
datastore_regex=
wsdl_location=https://
以上配置指定了VMware节点的IP,datestore的用户名和密码,集群的名称等信息,这些信息都是在vCenter的安装时指定的。
完成以上配置后,便可以在vCenter与OpenStack的Dashboard中看见新建的虚拟机,并且可以使用VMware的DRS特性。
2.2 DRS功能的应用验证
为了验证对接后的DRS功能,在OpenStack平台上建立好所需的资源,比如网络,租户,集群,硬盘等等。
如图5所示,在UI界面上可以看见已经建立了一些云主机,也就是实例,首先要确保这些云主机都在同一个节点上,并且该节点所在可用域有至少3个节点。
图5 云主机列表
DRS进程虽然在所有计算节点上都有安装,但是只会在同一个可用域中的一个节点上运行一个DRS进程,也就是说,只有一个节点的DRS进程是处于active状态。但是所有的节点都需要配置统一的文件,以设定DRS服务的开启与否,运行的模式,阈值,轮询周期等等参数。下面进行DRS配置文件的设置,如图6所示。
图6 DRS配置
其中enable_global_mode = True表示全局模式,意味着无需对可用域进行其他配置;rs_rule = cpu_percent表示CPU使用率模式;rs_threshold = 50表示阈值为50,即CPU使用率到达50%以上时会触发DRS功能;rs_name = CPU utilization4为该DRS策略的名称,方便区分;rs_enable = True表示DRS功能开启,相当于总开关;rs_stabilization = 3 表示每3次轮询时间执行一次DRS。
要验证DRS功能,需要创造条件来触发节点达到DRS阈值,一个方法就是使用人为加压来让计算节点达到阈值。通过编写一个脚本,可以令计算节点不停的执行某个命令,从而消耗大量CPU资源。在compute-0节点上运行CPU加压脚本后,使用TOP命令查看节点CPU资源使用情况。
设定CPU超过阈值并且稳定10分钟后执行DRS,在等待10分钟后,可以观察到虚拟机开始执行迁移,此时在控制节点上查看compute-0节点的虚拟机,如圖7所示。
图7 虚拟机运行状况
在上图可以看到,第三行的实例,状态显示migrating,也就是迁移,说明DRS功能触发实例执行迁移。
之前设定DRS执行迁移周期为三个轮询时间,一个轮询时间为20秒,也就是大约一分钟迁移一台,直至CPU使用率降至阈值以下,实际上,在加压脚本的影响下,哪怕没有实例存在,CPU使用率也无法降低至50%以下,所以实例只会一直迁移,直至所有实例全部迁出,或者可用域内其他节点无法承载。
30分钟后,再次查看compute-0上的实例,如图8所示。
图8 虚拟机迁移后运行情况
从上图可以看出,对比执行DRS之前,其上的实例已经迁走许多,所有实例都可正常运行。
4 结 论
基于OpenStack原生功能的基础上,通过对接VMware vSphere平台,从而实现了HA与DRS的高级功能,设计了一种保障OpenStack云计算平台业务的方案。本设计在保留OpenStack原有结构的同时,引入了VMware的管理方式,使得该云计算管理平台有着更好的兼容性,通过使用VMware成熟的设计,加强了OpenStack云计算管理平台的稳定性。该方案既可发挥灾备的作用,也可实现预防的功能,通过手工配置的方式可以让用户更加灵活的调整方案,具有广泛的应用场景。
参考文献
[1] NANDA S,CHIUEH T. A survey on virtualization technologies[R]. Technical Report,TR-179,New York:Stony Brook University,2005:1—42.
[2] LI Y,LI W,JIANG C. A survey of virtual machine system:current technology and future trends[C]// International Symposium on Electronic Commerce & Security. IEEE Computer Society,2010:332—336.
[3] ROSENBLUM M,GARFINKEL T. Virtual machine monitors:current technology and future trends[J]. Computer,2005,38(5):39—47.
[4] JACKSON K. OpenStack cloud computing cookbook[M]. Birmingham:Packt Publishing Limited,2012:151—154.
[5] CORRADI A,FANELLI M,FOSCHINI L. VM consolidation:a real case based on OpenStack cloud[J]. Future Generation Computer Systems,2014,32(1):118—127.
[6] VYAS U. HA in OpenStack[M]// Applied OpenStack Design Patterns. Apress,2016.
[7] DU Q,QIU J,YIN K,et al. High availability verification framework for OpenStack based on fault injection[C]// International Conference on Reliability,Maintainability and Safety. IEEE,2017:1—7.
[8] SAHASRABUDHE S S,SONAWANI S S. Comparing openstack and VMware[C]// International Conference on Advances in Electronics,Computers and Communications. IEEE,2015:1—4.
[9] SHANMUGANATHAN G,GULATI A,VARMAN P. Defragmenting the cloud using demand-based resource allocation[J]. Acm Sigmetrics Performance Evaluation Review,2013,41(1):67—80.
[10] 毛軍礼. OpenStack之Nova服务[J]. 计算机与网络,2018(3):60—63.
[11] 王侃,刘钊远. 基于OpenStack云平台的弹性资源配置系统[J]. 数码世界,2018(3):199—200.
[12] 闫映东,文成玉. 中小企业OpenStack云平台高可用技术研究与实现[J]. 无线互联科技,2018(5):131—132.
猜你喜欢
数字技术与应用(2016年9期)2016-11-09
数字技术与应用(2016年9期)2016-11-09
知音励志·社科版(2016年8期)2016-11-05
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年21期)2016-10-18
科技视界(2016年22期)2016-10-18
中国新通信(2016年16期)2016-10-18
大学教育(2016年9期)2016-10-09
科技视界(2016年20期)2016-09-29
