
经济评论情感分析与评分
2020-04-07 04:17刘志强余薇温和铭孔枞李欣
经济技术协作信息 2020年4期
◎刘志强 余薇 温和铭 孔枞 李欣
一、引言
随着人们参与经济活动日益频繁,人们每天会接触到成百上千条经济评论文本数据,评论者的情感倾向和态度往往会对读者造成影响。有学者的研究表明人们在做出选择或决策前,通常倾向于参考他人的评论信息。因此对经济评论文本中经济特征进行情感分析及评分可谓颇具意义,它能较好地反映了人们对某经济事件的情感认知倾向,在个人的经济决策,企业的经营决策,甚至国家的政治与经济政策中发挥一定的作用,以实现个人经济效用的最大化和社会经济资源的最优配置。
文本情感分析,又称为意见挖掘,是利用自然语言处理技术、数据挖掘算法等对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。目前情感分析的主要方法有:基于情感词典的情感分析方法、基于机器学习的情感分析方法和基于深度学习的情感分析方法。贾春光在卷烟评论方面应用基于情感词典的方法进行情感分析,实验明基于词典的情感分析方法在具体领域文本情感分析中仍具有优势。李明等使用朴素贝叶斯、支持向量机(SVM)、决策树、K 最邻近算法(KNN)四种机器学习分类方法对商品评论进行情感分析,比较结果之后发现支持向量机(SVM)算法具有较好的情感分类效果。高欢等在单一机器学习模型的基础上使用集成学习进行情感分析,将逻辑回归、随机森林、轻量梯度提升机三种分类方法聚集在一起,以提高情感分类准确率。近年来,深度学习方法在情感分析领域引起了许多关注。顾军华等提出一种基于卷积注意力机制的神经网络模型(CNN_attention_LSTM),能够突出文本关注重点的情感词与转折词,在具有转折词的文本中能更精确地判别文本情感倾向。杨善良等将条件随机场模型与循环神经网络模型LSTM 相结合,形成基于注意力机制的LSTM-CRF-Attention 模型,能够有效提高文本数据情感特征的抽取效果。Hossein Sadr 等将卷积和递归神经网络合并到一个新的鲁棒模型中,捕捉了长期的语句间语义依赖关系,并减少本地信息丢失,优于基本的卷积神经网络和递归神经网络模型。
本文将情感分析方法应用于经济评论领域,考虑到经济评论中情感词的领域性、评论文本长度较短,采用基于情感词典的情感分析方法。同时,采用该方法人工提取情感特征能够从一定程度上减少情感特征提取环节模型中的误差。另外,本文在传统基于情感词典的情感分析方法的基础上进行改进,引入互信息和左右熵新词发现方法提高分词精度,将ITD*MI 算法[8]应用于情感词加权,进一步提高该方法情感分析准确度,解决经济评论领域的情感分析问题。
二、情感分析技术与方法
本文充分考虑经济评论文本较短、含有趋势词词组、含有经济专业词汇的特点,构建经济评论情感分析体系。对于文本数据的分词问题,采用中科院分词系统NLPIR-ICTCLAS 进行分词,再使用互信息和左右熵新词发现方法对分词结果进一步改进。对于领域情感词典构建,本文在基础情感词、拓展情感词的基础上,加入人工筛选获得的领域情感词,共同构建领域情感词词典。在情感分析中,对于情感词的加权问题,本文采用ITD*MI 方法对文本中的情感词进行加权,对于趋势词词组按该评论中的情感词权重均值进行加权,将情感词加权评分和趋势词词组加权评分相加获得该评论最终情感评分。
1.经济评论文本数据的特点。
经济评论文本数据具有文本句子短、包含大量经济趋势词、不完全遵循语法规则、难以通过有限句子信息在当前句子的语境给出明确判断的特点,而且经济评论文本数据有别于一般的评论数据的一大显著特点是它涉及经济金融领域各类专业术语,讲究不同的词语搭配方法和句式结构。
以下简要举例说明经济评论文本数据一些显著特点:
(1)经济评论文本数据一般句子较短,但包含众多信息,需要在特定的语境下才能全面理解,其中包含的不同情感色彩因句而异。
(2)经济评论文本中有大量的专业术语有别于一般的评论文本,比如"做多"、"利好"、"通胀"等,这些专业词汇在特定语境下都可以展示不同的情感色彩。
(3)经济评论文本数据中涉及众多趋势词词组,比如"再创新高"、"涨势低迷"、"触底反弹"、"成本降低"等等,它们在经济金融领域都涉及一定的情感色彩。
而且在经济评论文本的情感分析中存在一些特殊情况。因经济评论文本中有很多的特殊的词语搭配,要结合语境分析情感倾向,如果通过分词单独分析个别词语则会造成一定谬误。因此注意不同词语间的相互修饰,及词语搭配,而不是单独分析个别词语的情感极性有助于提高文本情感分析的准确度。另外,经济评论文本中否定词也会影响分词结果的情感倾向判断,否定词会改变整个句子的句意,如:"不 尽如人意",否定词"不"将褒义词"尽如人意"的反转为贬义词。
2.分词方法。
对收集的语料进行分词,英文单词是以空格作为分隔符,而汉字词语之间没有明显标记,因此中文分词是文本情感分析不可或缺的一步。对比结巴分词的效果,我们选择使用中科院分词系统NLPIR-ICTCLAS 进行分词工作。NLPIR 分词系统含有中文分词、新词发现、词性标注等多种功能,可以较好得对我们的语料进行分词。经济领域内专有名词较多,为了提高分词精确度,在NLPIR 分词系统的基础上,再利用互信息与左右熵来对分词结果进行完善。互信息指体现词语间语义相关程度的量,其计算方法如公式(2-1)所示。

其中,MI(X,Y)指两相邻词的互信息值,P(X)为词X 出现的概率,P(Y)为词Y 出现的概率,X 和Y 指两相邻词,互信息值越高,表明两相邻词相关性越高,其组成短语的可能性越大;同理,互信息值越低,则表明两相邻词组成短语的可能性较小。
信息熵最初被定义为离散随机事件的出现概率,左右熵则表示词表达中左边界的熵与右边界的熵,用来体现词表达中的自由程度。此处以左熵为例,其计算方法如公式(2-2)所示。

其中,EL(W)指预选词左边界的信息熵,W 指预选词,aW 为位于预选词左边的词汇,P(aW|W)为条件概率,即为预选词为W时,左边界出现的aW 的概率,左右熵值越大,表明预选词左边与右边更换的词越多,则该预选词越有可能是单独的词。利用互信息与左右熵来提高新词发现效果,从而达到较好的分词精度。
3.领域情感词典构建方法。
构建情感词典,目前的研究有两种思路:一种是基于语义计算,一般可根据知网情感词计算语义相似度,计算目标词语跟基准词之间的紧密程度,得以判定情感极性;另一种是基于统计分析,计算目标词语基准词之间的点互信息值,确定两个词之间的紧密程度,从而获取目标词的情感倾向。
为了提高情感分类的准确性,建立专门的经济领域情感词典,本文选择基于语义计算构建情感词典,该情感词典由基础词和领域词构成。基础情感词由现有的知网Hownet 情感词典和台湾大学简体中文情感极性词典构建。领域情感词典是指用于某一特定领域文本语料进行分词的情感词典。其在基础情感词典的基础上采取人工提取情感特征的方法,构建经济评论情感词典,这类基础情感词必须要人工标记,在基础情感词之上,配合爬取的经济评论进行分词、人工筛选划分得到评论情感词汇,将情感词分类别归纳,得到适用于经济评论的情感词典。
4.情感词加权方法。
(1)ITD*MI 算法介绍。
在文本情感分析范畴,情感词权重通常考虑两个影响因素:该词在文本中的重要性(ITD)和其在表达情感上的重要性(ITS)。Deng 等人在情感词加权测试中,将ITD 和基于交互信息(MI)的ITS 结合的算法效果最佳,记为ITD*MI 算法。
(2)公式表示。
首先引入相关定义,将积极评论的集合记为V1,消极评论的集合记为V2。设X={X1,X2...,Xn}为V1_V2中的所有情感词。设待分析的经济评论为Cj,情感词Xi在经济评论Cj中的加权为Wij,则Cj可由特征向量Cj={W1,W2j...,Wnj}表示。加权Wij由两部分构成,一是ITD(Xi,Cj),表示情感词Xi在经济评论Cj中的重要程度,计算方法如公式(3):

其中,Xij表示Xi在Cj中出现的次数。
Wij的另一组成是ITS(Xi),表示Xi在情感倾向表达上的重要性,在ITD*MI 算法中,用MI(Mutual Information,交互信息)表示,计算方法如公式(2-1)。
其中概率的解释见表2-1。

表2-1 概率含义解释
对于给定的情感词Xi,其ITS(Xi)定义为:

综上,得到情感词Xi在经济评论Cj中的加权:

三、数据与实证
根据以上分析,本文构建经济评论情感分析体系(如图3-1)。

图3-1 经济评论情感分析流程图
1.数据来源。(1)网站选择。
Alexa 是世界权威的网络流量统计机构,专业发布各大网站的世界排名,即Alexa 排名。本文考虑Alexa 排名,选择排名较前的经济网站作为语料库的原始文本数据来源。
(2)话题选择。
百度指数(index。baidu。com)是一个数据分享平台,它以海量百度用户的网络行为作为基础数据,是当今数据时代和互联网十分重要的统计分析平台之一。可以利用百度指数可以获取当期人们对经济热词的关心程度。近期由于猪肉价格的上涨人们对猪肉价格的关注度越来越高;国家对于发展区块链技术高度重视,在未来的技术发展与产业变革中区块链技术发挥着不容小视作用,是国内经济发展的有效动力;科创板的设立给股市中股民一个新的投资方向,所以话题会相对较多;对于直播经济来说,网络直播在一定程度上能够刺激公众消费,带动经济发展,是一种新型的营销手段,这其中有利有弊,成为了人们评论的焦点。因此,本文选取猪肉价格、区块链、科创板、直播经济这4个热门话题进行实验研究。
2.数据处理。
(1)数据获得。
本文通过Alexa 综合排名(2020 年3 月数据)查询经济评论类权威网站,最终选择"财经腾讯网"、"新浪财经"、"搜狐财经",作为经济评论原始文本数据来源。利用爬虫获得的原始评论分别为:区块链1180 条、科创板1210 条、直播经济863 条、猪肉价格1384 条。
(2)数据清洗。
由于网络爬虫获取的原始数据格式混乱,有部分原始数据由于评论主题偏移、非经济评论、重复等原因不可用。先对原始数据去重,再筛选关键词,去掉不相关评论后,得到可用经济评论:区块链1111 条、科创板1111 条、直播经济830 条、猪肉价格1359 条。
(3)分词。
使用python 中的NLPIR 分词包对文本数据进行分词,再利用左右熵互信息新词发现算法对分词结果进一步细化。
3.经济评论情感词典。
(1)基础情感词与拓展情感词。
通用情感词典的构建主要通过现已开源的基础情感词典来构建,本文选择知网Hownet 情感词典以及台湾大学简体中文情感极性词典去重及删除无用词后整合构建基础情感词典。Hownet 是一个以汉语和英语的词语所代表的概念为描述对象,以揭示概念与概念之间以及概念所具有的属性之间的关系为基本内容的常识知识库。
(2)经济领域情感词。
领域情感词典是指利用某一特定领域的大量语料所构建的情感词典,用来对这一领域的文本语料进行分析。与通用情感词典相比,领域情感词典在用于特定领域的具体情感分析任务中精确度更高,总体更具实用性。本文通过分词,人工筛选得到所选经济名词的1.033 个常用情感词汇。
4.经济评论情感词加权。
为了直观地反映情感词的情感倾向,在爬取得到经济评论里,对抽取出来的1000 多个情感词,对比所构建的经济评论情感词典,划分积极倾向和消极倾向,再根据ITD*MI 算法得到的加权分别排名。积极情感加权排名前五的情感词有"创新"、"发展"、"复苏"、"可观"、"欢迎",消极情感加权排名前五的情感词有"悲观"、"亏损"、"危机"、"非理性"、"风险"。
对比加权结果发现,根据ITD*MI 算法,在经济评论中出现次数较多的情感词ITD 较高,而在两类经济评论频率相差较大的情感词普遍可以获得更高的ITS,比如创新(973(积极评论频率),13(消极评论频率))、发展(658,9)、悲观(18,834)、亏损(12,572)。综合来看,加权较高的情感词具有出现频率高、情感极性明显的特点。
5.趋势词词组。
(1)名词与趋势词词典。
经济评论中含有大量趋势词词组,这些词组所包含的情感倾向不可忽略。因此,为了计算趋势词词组的情感评分,本文构建经济领域的名词词典与趋势词词典。通过常见的趋势词查找其近义词,共同构成趋势词词典。人工筛选曼昆《经济学原理》一书中的经济学名词,结合语料库中的经济名词,共同构成经济名词词典。其中,定义与"增"趋势搭配表达积极情感倾向的名词为积极名词,反之为消极名词。与"减"趋势搭配表达积极情感倾向的名词为消极名词,反之为积极名词。
(2)趋势词词组情感评分。
定义"增"趋势词评分为1,"减"趋势词评分为-1,积极名词评分为1,消极名词评分为-1,计算趋势词词组原始情感评分,计算方法如公式(3-1)所示。

其中OSij,(Original Score)是第i 条经济评论第j 个趋势词词组的原始情感评分,TSij(Trend Score)是该词组的趋势词评分,NSij(None Score)是该评论的名词评分。
对趋势词词组的原始评分进行加权,计算方法如公式(3-2)所示。

其中WTij,(Weighted Trend Score)为第i 条经济评论第j个趋势词词组的加权后情感评分,WEij(Weighted Emotion Score)为公式(2-5)中计算所得第i 条经济评论第j 个情感词加权情感评分,n 为该评论中的情感词总数。
四、送结果与检验
1.实验结果。
本文对经济评论情感评分采用二级分类,将第i 条评论的情感词和趋势词词组加权情感评分加总,得到第i 条评论的原始情感评分,将其0-1 标准化后与0.5 比较,大于0.5 分为积极情感,小于0.5 分为消极情感。对经济热词评论的情感倾向分类统计得到,区块链的积极评论占68.95%,科创板的积极评论占64.81%,直播经济的积极评论占71.57%,猪肉价格的积极评论占32.89%。
2.结果检验。
(1)检验指标。
精确率、召回率、F1 分数是用来衡量二分类模型精确度的重要指标。精确率将积极(消极)评论判定为积极(消极)评论的数量,即正确判定评论数,占判定为积极(消极)的总评论数的比率。是指召回率是指正确判定积极(消极)评论数,占实际总积极(消极)情感倾向评论数的比率。而F1 分数兼顾了分类模型的精确率和召回率,可以看作两者的一种调和平均数。
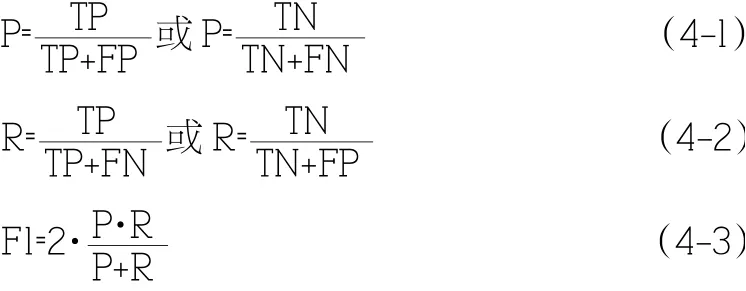
其中,P(Precision Ratio)为精确率,R(Recall Ratio)为召回率,F1(F1 Score)为F1 分数,TP(True Positive)为将积极评论判定为积极评论的数量,FP(False Positive)为将积极评论误判为消极的数量,TN(True Negative)为将消极评论判定为消极的数量,FN(False Negative)为将消极评论误判为积极的数量。
(2)检验结果。
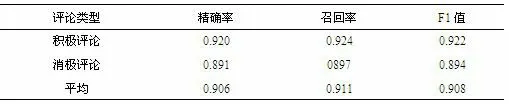
表4-1 经济评论情感分析精确度检验结果表
从表4-1 可知上述经济评论情感分析体系在实践中有较好效果,精确率平均能达90.6%,召回率平均可达91.1%,F1 值平均可达90.8%,但负向情感极性判别精确度的各项指标基本低于正向情感极性判别,情感词典中消极情感词可能存在不完善等问题。
五、结论
本文采用基于情感词典的情感分析方法解决经济评论领域的情感分析与评分问题,通过人工提取特征构建经济评论情感词典,引用互信息和左右熵新词发现方法优化分词结果,引用ITD*MI 方法对情感词加权,同时考虑经济评论文本短和含有趋势词词组特点,计算经济评论综合情感评分并进行情感极性判别。使用精确率、召回率、F1 值3 个情感极性判别精确度评价指标对实验结果进行验证,各项指标均高于90%,该方法较好地解决了经济评论领域的情感分析问题。
本文将情感倾向简单地进行二分类,评分并不能精确反映情感倾向程度,未来的研究重点是在完善经济评论情感词典、进一步提高判别精确度的基础上,使情感评分能够更好地反映文本的情感倾向程度。
本论文得到了江西财经大学科研课题
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
小学阅读指南·低年级版(2015年11期)2015-09-10
海峡姐妹(2015年3期)2015-02-27
中国卫生(2014年12期)2014-11-12
高中生学习·高三版(2014年3期)2014-04-29
中国社会公共安全研究报告(2013年1期)2013-03-11
中学生英语·外语教学与研究(2008年4期)2008-03-18
