
基于深度信念网络的近红外光谱鉴别莲子粉掺假
2020-04-02 03:33胡仁伟倪明龙周俊伟李占明
食品科学 2020年6期
胡仁伟,俞 玥,倪明龙,俞 娇,周俊伟,朱 诚,李占明,
(1.中国计量大学生命科学学院,浙江 杭州 310018;2.湖州职业技术学院,浙江 湖州 313000;3.广东食品药品职业学院,广东 广州 510520)
莲子在中国有着悠久的文化历史,其富含磷脂、生物碱和类黄酮等成分,广受青睐[1]。由于提取工艺和隐蔽掺杂等因素的存在而影响着市面上的莲子粉品质,掺入其他淀粉为常见的掺假方式,不但会影响消费者的食用感和健康,还会对企业的信用及竞争带来影响[2-3]。现有检测方法表明[4-5],莲子粉质检具有步骤比较繁琐、花费时间长、样品的用量大且预处理过程复杂、多种有机试剂的消耗加重环境负担、不能实现大批量的现场快速分析等缺点[6],因此国内外研究人员将目光转向近红外光谱(near-infrared spectroscopy,NIRs)技术。目前NIRs技术在行业产品质量评定中发挥着越来越重要的作用。国内NIRs分析技术的研究主要在人参[7]、黑胡椒[8]、 蜂蜜[9]、茶叶[10]等方面应用。NIRs技术是一种无损的快速检测方法,因无需消耗试剂,无复杂的预处理过程,能够对莲子粉直接进行光谱测定,可直接进行现场应用和在线分析。
早期研究给出众多光谱数据建模方法,付才力等[10]提出了采用最小二乘支持向量机和聚类算法对莲子粉进行NIRs分类,陈建等[11]运用误差反向传播(back propagation,BP)的Levenber-M arquardt优化算法对不同品种的玉米的NIRs进行分析,何凯琳[12]则运用自编码融合卷积神经网络算法对烟叶原料的NIRs进行分析。非线性模型比线性模型有更好的预测精度,因此,目前常采用深度学习模型对光谱进行建模[13-14]。在样本量足够的时候运用上述的方法均可达到令人满意的效果,针对小样本多分类的相关研究,需要探索新的更加适宜的方法。目前对NIRs的研究大多数基于特征波段建立模型,重点在于预处理数据和筛选特征波段,对模型的提出和改进需要更深入。优质的建模方法可简化数据预处理过程,同时也能够保证精度的准确[15-16]。
深度学习模型的复杂建模能力,可以解决传统的机器学习方法在多分类问题上的劣势[17-18]。在2006年提出的深度信念网络(deep belief network,DBN)[19]模型作为一种概率生成模型,通过训练各个神经元之间的权重和获得神经元的偏置,DBN模型可使整个神经网络以最大概率生成训练数据[20-22]。DBN一般由3 层或3 层以上神经元构成,其中这些神经元可以分为显性神经元和隐性神经元。显元接受输入数据,隐元提取数据的特征,其中每一个神经元代表数据向量的一维。DBN按层进行训练,在一层上用数据来推断隐层,再将本层的隐层当做下一层的数据,以此类推[23]。
与传统方法相比,DBN具有更复杂的非线性和高层次特征提取能力,对非线性函数表示能力更强,能够抽取更加有效的特征信息,使分类和预测更加容易[24]。目前基于随机隐退深度信念网络(dropout-DBN)处理农产品、食品,尤其是莲子粉制品掺假的相关研究鲜见报道。鉴于此,本实验提出以NIRs结合深度学习方法的莲子粉鉴别模型,作为真假莲子粉鉴别的一种有效手段。利用NIRs对掺杂的莲子粉进行鉴定,在类别已知的情况下运用支持向量机(support vector machine,SVM),在类别未知的情况下运用DBN进行判别。本研究有望为莲子粉等农产制品掺杂的鉴别及溯源提供新的解决方案。
1 材料与方法
1.1 材料与试剂
莲子样品是从市场上购买的绿田、粒粒珍、宏兴隆、方家铺子等湖南湘莲、福建建莲、浙江宣莲各20 份,经粉碎机粉碎,过60 目筛网,充分混合,编号后密闭保存;所掺杂的小麦粉、玉米粉、地瓜粉购于当地超市,将粉碎的莲子粉掺入不同比例的小麦粉、玉米粉、地瓜粉,参考文献[10]将掺入比例设置为5%、10%、15%、20%、25%,各比例分别设置30 份样品,纯莲子粉样品160 份,总计610 份。
1.2 仪器与设备
Antaris II采用傅里叶变换近红外光谱仪、CaF2分束器、InGaAs检测器(扫描范围为4 000~10 000 cm-1,分辨率为8 cm-1,实验室的温度为25 ℃,相对湿度为60%) 美国赛默飞世尔仪器公司。
1.3 方法
本实验在类别已知的情况下使用SVM模型对掺杂了各类作物粉的莲子粉NIRs的特征数据进行测试,使用支持向量机回归(support vector regression,SVR)与SVM进行对照。本实验调用了LibSVM库,其同时实现SVM与SVR,便于对照。在类别未知的情况下采用的模型是DBN,其模型由三层受限玻尔兹曼机与一层BP调节构成的深层神经网络[25-27]。
1.4 数据处理
1.4.1 数据预处理
所采集到的原始光谱中除包括与样本有关的信息外还包括各种因素造成的噪声信号。这些不仅对光谱图信息造成干扰,还会对模型的建立和对未知的样品组成或性质预测造成影响。因此,光谱数据预处理就显得尤为的重要,也有利于下一步模型的建立和提升预测精度。本研究采用区间正规化处理(1),用原始数据集中的各个元素减去所在列的最小值再除以该列的极差,可以将量纲不同、范围不同的变量表达为值均在0~1范围内的数据。
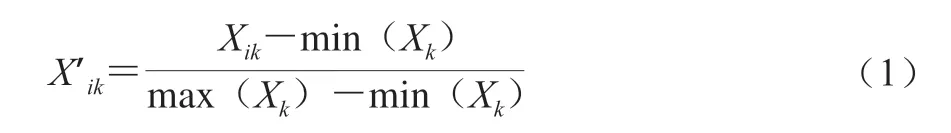
式中:Xik为第i行第k列的原始数据,Xk为所有k列的数据,X’ik为第i行第k列经过归一化后的数据。
1.4.2 数据分析
使用IBM SPSS Statistics 22对数据进行预处理并进行特征提取,使用Origin 2018进行光谱二次求导,在Pycharm上使用Python语言对光谱数据进行分析。
2 结果与分析
2.1 NIRs分析
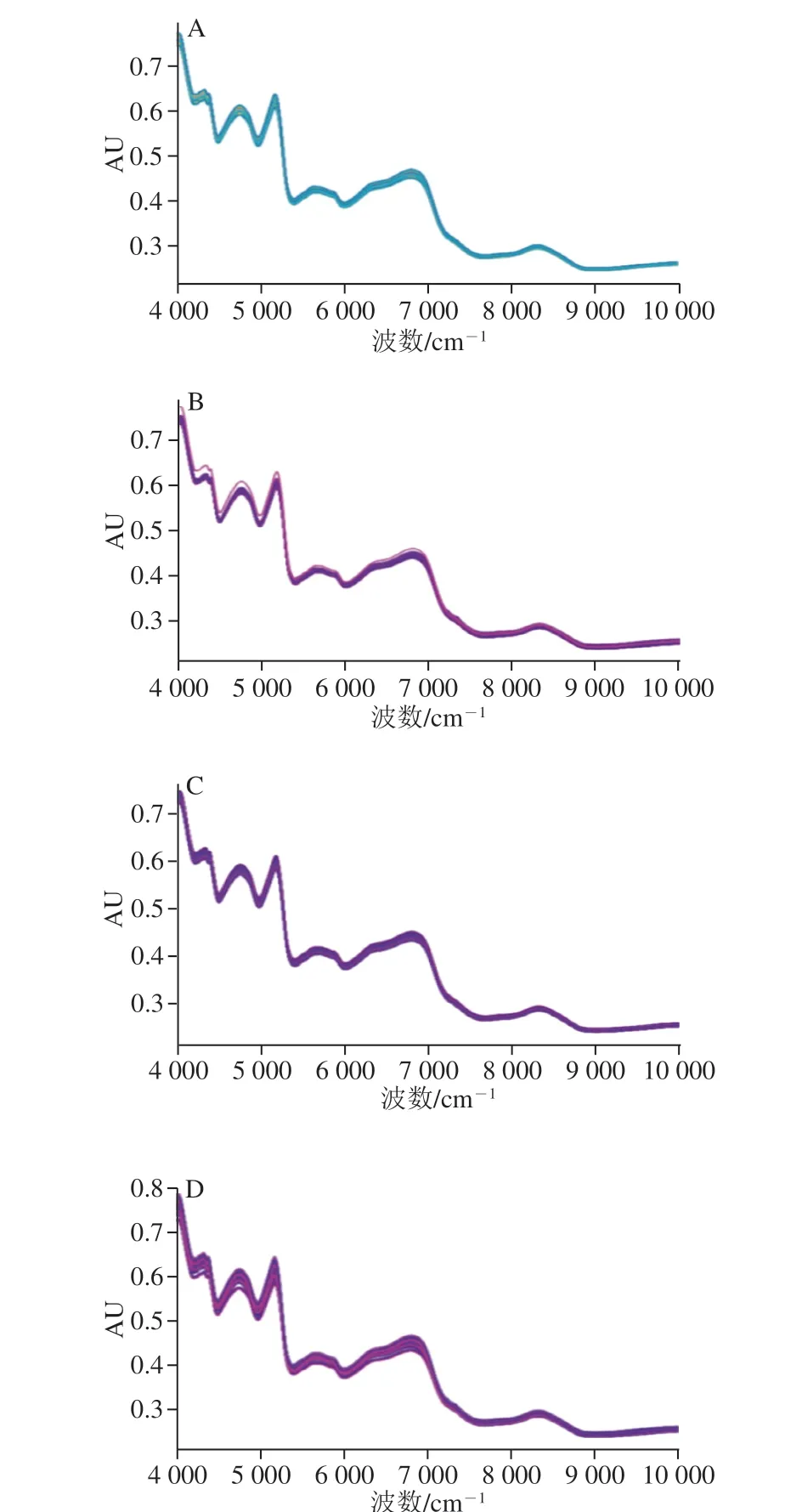
图 1 纯莲子粉(A)与掺杂了各比例小麦粉(B)、玉米粉(C)、 地瓜粉(D)的莲子粉NIRs图Fig. 1 Near-infrared spectra of pure lotus seed flour (A) and lotus seed flour mixed with wheat flour (B), corn flour (C) or sweet potato flour (D)
图1 为纯莲子粉和掺杂了小麦粉、玉米粉和地瓜粉的莲子粉NIRs图,不同物质组成的样品的NIRs差异较小,直接从光谱上难以分辨掺杂的物质及掺杂的比例。图2为求得平均光谱后的光谱图,纯莲子粉的N I R s 图与另外3 种存在差异,然而掺杂了其他物质的样品的N I R s 仍旧比较接近。图3为对光谱数据4 000~7 500 cm-1范围内二阶求导后的微分光谱,在4 300~4 320 cm-1处的峰是C—H组合频,在4 454 cm-1附近的峰是C—H倍频和O—H组合,由于多种不同作物粉的掺杂,导致了这两处多糖和纤维素有着细微的区别,从而影响两处强峰两侧的小肩峰。其他分布为:5 800 cm-1左右是C—H的倍频吸收,6 000~7 000 cm-1为O—H和N—H的二级倍频,8 400 cm-1左右是C—H 的拉伸三级倍频。从中可以看出各样品峰的位置和强度很接近[28]。通过主成分分析(principal component analysis,PCA)进行初步分析,得出了主成分分布图,图4A、B、C分别为掺杂了不同比例的小麦粉、玉米粉、地瓜粉的莲子粉NIRs图数据的主成分分布图,图4说明利用NIRs技术鉴别莲子粉掺假可行。

图 2 莲子粉NIRs图Fig. 2 Near-infrared average spectra of pure and adultered lotus seed flours
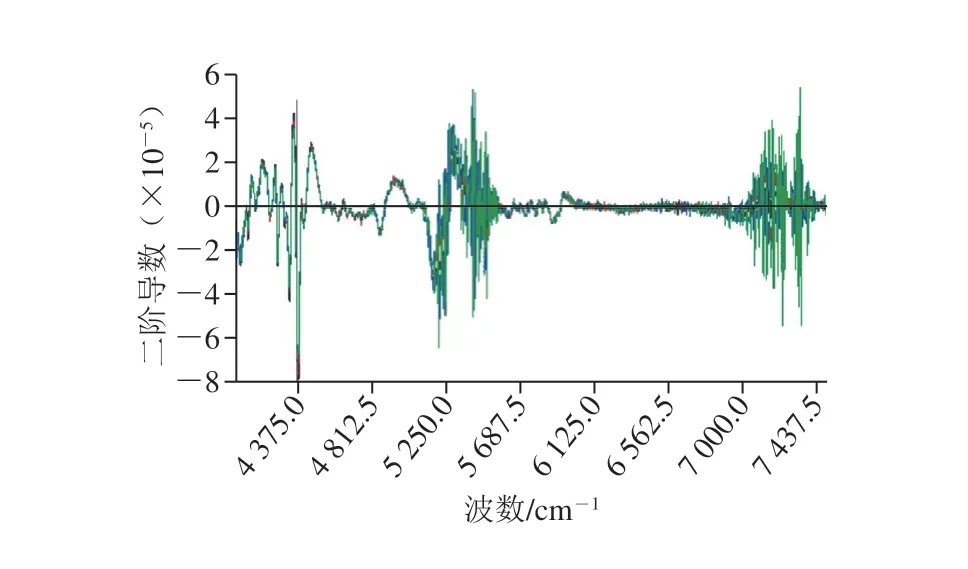
图 3 莲子粉NIRs二阶导数光谱Fig. 3 Second derivative near-infrared spectra of lotus seed flour
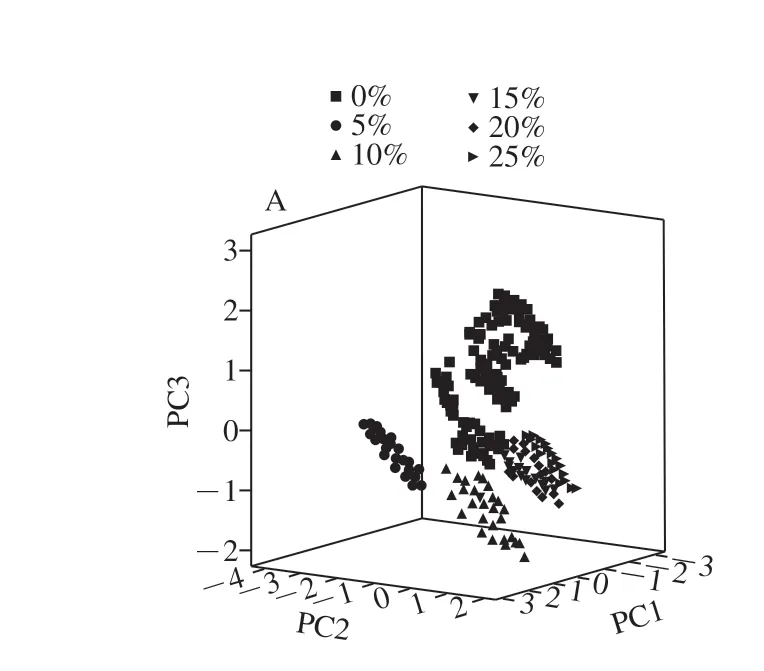
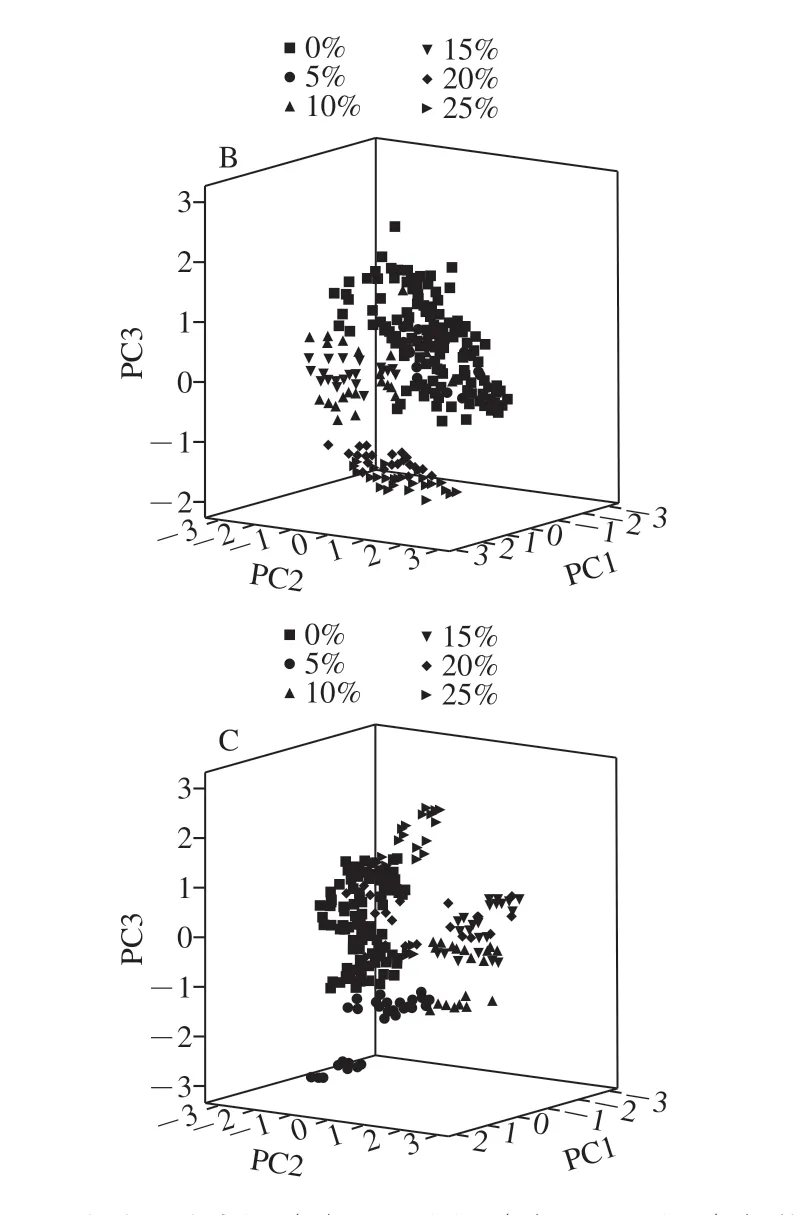
图 4 掺杂了小麦粉(A)、玉米粉(B)、地瓜粉(C)的 莲子粉NIRs数据三维主成分分布图Fig. 4 Three-dimensional principal components distribution patterns of near-infrared spectral data of lotus seed flour incorporated with wheat (A), corn (B), or sweet potato flour (C)
2.2 莲子掺杂模型分析
本研究基于Tensor Flow深度学习框架,采用Pycharm和Anaconda3进行编程。在Anaconda下搭建Tensor Flow环境并调用,利用已有的样品数据进行测试,最终确定莲子粉NIRs的DBN分类模型。
通过实验设定激活函数为Relu和Softmax,设定权重学习率为0.1,可见层偏置学习率为0.1,隐藏层偏置学习率为0.1,权重为0.001,累积冲量初始值为0.5,最大迭代次数为350。训练过程中的损失函数如图5A所示。迭代次数越多,训练集与测试集准确率逐渐上升并趋于稳定值,损失函数逐渐下降并趋于稳定值,整体上网络训练正常。图5B运用了Dropout技术,训练集与测试集准确率更加接近。
但过拟合问题存在于所有的机器学习问题中,且机器学习的根本问题就是优化与泛化的对立。优化指调节模型让其在训练数据上获得最佳性能,泛化指训练好的模型在新数据上训练的性能好坏[29]。但无法人为控制泛化能力,可在训练数据基础上修改模型。为了防止模型学习到训练数据中的无关数据,最优的解决方案是获取更多的训练数据,其次是调节模型对其进行正则化,本研究采用Dropout进行正则化,为确保模型丢失个体线索后仍保持健壮性,通过减少权重连接,增加网络模型在缺失个体连接信息时的鲁棒性[30-31],即在网络训练期间随机删除隐藏层的部分单元。
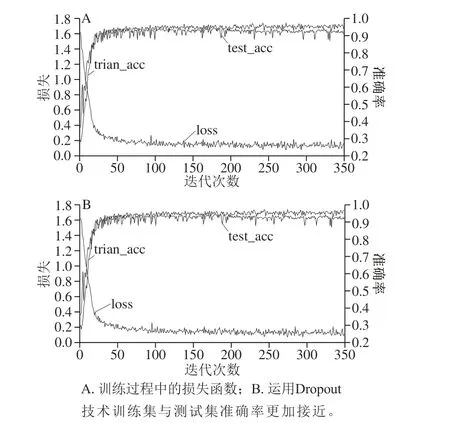
图 5 损失率与准确率随迭代次数增加的变化图Fig. 5 Changes in loss rate and accuracy with increasing number of iterations

图 6 不同Dropout值随迭代次数增加的准确率变化曲线Fig. 6 Changes in accuracies of different Dropout values with increasing number of iterations
神经网络中Dropout技术已被广泛应用,正常设置为0.2或0.1[31]。本模型输入时是1 557,输出时是6 类。如图6所示,该图为修改Dropout的值后导出的准确率图,经过多次数据处理发现,在迭代次数超过一定的次数后Dropout设置为0.15、0.1相差不大,而迭代次数较少的时候0.1的值效果较好,故将Dropout设置为0.1。
2.3 模型评价
将610 个有效样本划分为训练集与测试集,用全部样本的80%,即488 个样本建立模型,剩余122 个样本测试模型的准确性,训练集包含了交叉测试数据。本研究选取具代表性的掺杂各比例小麦粉的莲子粉数据300 条,训练集和测试集比例选取与上述相同。掺杂各作物粉的莲子粉610 条和掺杂了小麦粉的莲子粉300 条数据基于SVM及DBN的平均准确率和平均运行时间。从表1、2可以看出,随着样本数量的增加,SVM的鉴别准确率已达到90%;而DBN准确率在95%左右,随着样本数量的增加准确率也有所增加。而随着样本数的增加训练时间也相应增加,经过Dropout的DBN算法相较于传统的DBN算法时间要短,这是因为经过Dropout,DBN中的一些神经元没有被调用,减少了正向反向传播的时间,虽然准确率个别情况下稍有降低,但是经过Dropout可以有效避免小数量样本的过拟合问题。
2.4 建模样本量对模型预测精度的影响
为了检测DBN训练效果,对数据重新划分,经过多次训练计算准确率与训练时间,SVM亦采用相同的数据进行计算。取5 次重复试验的平均值,如表1~4所示。运行时间为Python自带的time函数计算程序的运行时间,即模型的训练时间。由于神经网络训练模型的时间较长,但保存后用来检测可以节省预训练的时间,达到实时检测的目的。
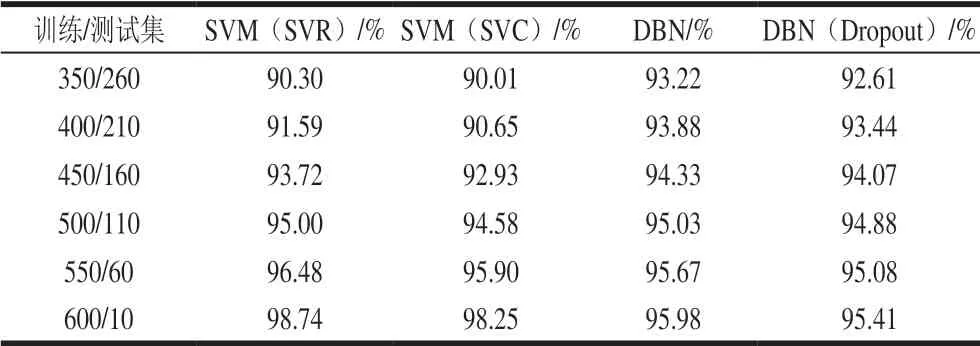
表 1 全部样本在不同比例训练集下各模型的平均准确率Table 1 Average accuracy of each model for all samples at different ratios between the numbers of training and test samples
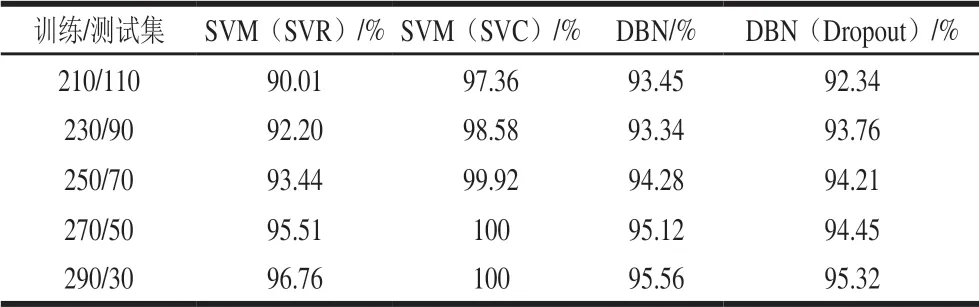
表 2 掺杂玉米粉样品在不同比例训练集下各模型的平均准确率Table 2 Average accuracy of each model for adulterated corn flour samples at different ratios between the numbers of training and test samples
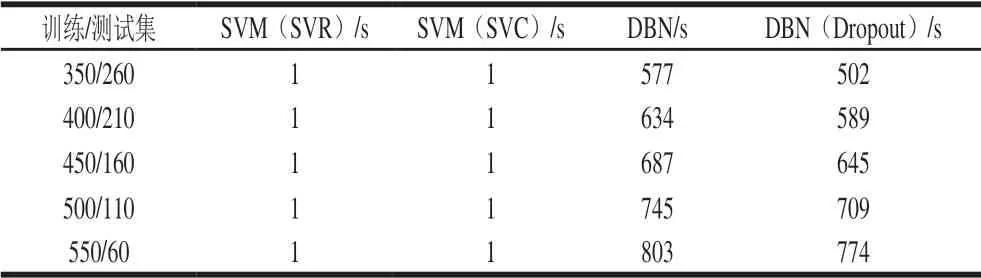
表 3 全部样本在不同比例训练集下各模型的训练时间Table 3 Training time of each model all samples at different ratios between the numbers of training and test samples
在所有比例作物粉掺入莲子粉并且训练集数目达到600时,SVM平均准确率达到了98%,而DBN平均准确率达到了96%。但经过对数据的深入处理,发现除15%的掺入比例外,DBN的准确率都比SVM要高,但在掺入比例为15%的其他作物粉的莲子粉,SVM的精确度达到了100%,而DBN的准确度在96%左右。虽然准确率在此比例下DBN较SVM而言并无优势,但总体上来讲,DBN的平均准确率要比传统的模型平均准确率要高。而且在现实情况下不可能对所有的莲子粉进行鉴定并且标定分类,DBN能够有效识别掺假比例在25%以内的其他作物粉的莲子粉,可以为莲子粉真伪鉴别提供一个有效的手段。训练集数量较多时使用DBN精确度明显高于传统的模型,在当前大数据的背景下结合此法能够快速有效的进行预测与分类。

表 4 掺杂玉米粉样品在不同比例训练集下各模型的训练时间Table 4 Training time of each model for adulterated corn flour samples at different ratios between the numbers of training and test samples
3 结 论
本研究针对莲子粉的掺假识别分析,提出了利用DBN对NIRs数据建模的方法,得到了较好的效果。首先,对掺杂了不同比例的其他作物粉类的光谱图进行常用的预处理及PCA处理,然后将处理后的数据输入SVM及DBN模型中,接着修改代码和网络参数微调,建立DBN光谱分类判别模型。所建立的模型能够对光谱数据进行分类,并与添加了Dropout的DBN及SVM进行对比,当样本量超过500时,较之于传统的有监督学习模型,平均预测精度得到提升,而且可以将训练好的模型保存以达到快速检测的目的。当训练集数目达到600时,SVM平均准确率可达98%,DBN平均准确率可达96%。Dropout-DBN模型在较大样本量光谱数据的建模可以取得更好的效果。该研究有望为相关农产食品的掺假鉴别及溯源研究提供技术支持。
猜你喜欢
粮食加工(2022年5期)2022-12-28
今日农业(2022年14期)2022-11-10
农业工程学报(2022年14期)2022-10-19
食品安全导刊(2021年21期)2021-08-30
河南畜牧兽医(2021年1期)2021-01-07
河南畜牧兽医(2021年5期)2021-01-06
农产品加工(2020年18期)2020-12-21
恋爱婚姻家庭·养生版(2018年9期)2018-09-30
恋爱婚姻家庭(2018年27期)2018-03-11
红领巾·探索(2018年12期)2018-01-26
