
基于高斯核层次聚类的汽车工况构建
2020-03-18 01:39韩鑫
智能计算机与应用 2020年9期
韩 鑫
(西安石油大学 计算机学院, 西安 710065)
0 引 言
汽车行驶工况也被称为车辆测试循环,描述了汽车行驶速度的时间曲线(通常在1 800 s以内),反映了道路上汽车的运动特性[1]。其是汽车工业中重要且常见的基本技术、车辆的能耗排放测试方法和极限标准的基础,也是汽车各种性能指标的校准和优化的最重要基准。中国幅员辽阔,不同城市之间的发展程度、气候条件和交通条件的差异,使各个城市的驾驶条件特征明显不同。因此,作为车辆开发和评估的基础,越来越需要从城市自身的驾驶数据中进行汽车行驶工况构建的研究。
大多数已有研究在工况构建时选择k-means 聚类方法作为聚类手段[2],但由于k-means 聚类需要提前确立数据中聚类的个数k。根据已有的研究结果及经验,将类别分为 3 类或者4类[3]。然而,当数据量较大,采集数据情况复杂时,先验知识具有很大的局限性[4]。在不观察数据就确立类别数,势必会给聚类结果带来很大的误差。层次聚类算法可以返回一颗聚类树,从聚类树中可以得到所有的聚类结果供使用者选择,从而避免了选择聚类个数的问题。由于一般汽车工况特征比较复杂,极有可能导致数据在低维空间下不可分,而使用核方法特别是高斯核方法,可以将数据特征空间映射到高维甚至无限维的空间,从而更好地将数据分开[5]。因此,本文采用基于高斯核的层次聚类算法,对构建的车况特征进行聚类,提高聚类准确度。
1 特征定义
将收集的速度数据转换为特征参数数据的过程,可以视为数据转换。特性参数可以更好地表达短途行驶的情况,并且更有利于分析。在分割的短行程中只有速度和时间数据,但是仅使用速度和时间并不能完整地表征短行程运行的特征。因此,本文从统计信息、形状信息以及熵信息中共提取构建了21个特征。
1.1 统计特征
短行程的统计特征数据主要为速度、加速度的比例、均值、标准差、最大最小值等,速度与时间数据是直接采集的。由于采集频率为1 HZ,所以对于任意时刻i,则有ti+1-ti=1, 加速度计算如式(1)所示:
(1)
其中,ai,i+1为第i秒到第i+1的加速度,m/s2;vi为i秒的速度,km/h;ti为第i秒时刻,s。
(1)最大速度、平均速度、速度方差(vmax,vm,vme,vsd)的计算公式分别为:
(2)
(2)最大加速度、最小加速度、平均加速度、平均减速度、加速度方差(amax,amin,aa,ad,asd)的计算公式分别为:
(3)
其中,Ta为加速度大于0.15的时间;Td为减速度小于0.15的时间。
1.2 形状特征
除构建统计特征外,由于片段为时间序列,需要捕获速度在波形形状上的特征。最新研究表明,将偏度和峰度相结合是对序列相关性度量的有用特征。偏度是统计数据分布中偏斜方向和程度的度量,是统计数据分布中偏斜度的数值特征。峰度表示概率密度分布曲线的峰值在平均值处高度的数量特征。直觉上,峰度反映了峰的锐度[6]。
对于长度为T的时间序列XT={x1,…,xT},其均值μ和方差σ分别为:
(4)
(5)
T的偏度定义为其三阶标准化矩为:
(6)
T的峰度定义为其四阶中心矩与方差平方的比值:
(7)
1.3 序列熵特征
除构建片段统计特征和形状特征外,还需要描述片段的确定性或者稳定性。在本文中,对于速度片段的时间序列,加入Binned 熵和Approximate 熵用于分别度量速度片段的均匀性和稳定性。
Binned熵考虑将时间序列XT的取值进行分区操作。之后计算时间序列的取值分散在所有区域中的概率分布的熵。
(8)
其中,pk表示时间序列XT的取值落在第k个桶的比例(概率);maxbin表示区域的个数;len(XT)=T表示时间序列XT的长度。
片段速度序列的 Binned 熵越大,说明这一段时间内速度取值的分布,在[min(XT),max(XT)]之间越均匀。如果一个片段的速度序列的 Binned 熵值较小,说明这一段时间序列的取值是集中在某一段上。
Approximate熵是为了判断一个序列是随机出现还是具有某种趋势。其基本思想是,把一维空间的时间序列映射到高维空间中,并通过高维空间向量之间的相似度判断,推导出一维空间的时间序列是否存在某种趋势或者确定性。
ApEn(m,r)=Φm(r)-Φm+1(r).
(9)
其中,Φm(r)为一个m维的函数。
2 基于高斯核的层次聚类
层次聚类是一种常见的聚类算法,该算法能在不同的层次上对数据样本进行划分归类,而不需要提前确定聚类的类别的数量。同样,该算法适用于对样本不确定或缺乏领域知识时使用。通常,层次聚类可分为两种特定的策略。一是:将样本(小类)从底部到顶部(大类)进行分组的策略;二是拆分型层次聚类:将大类从顶部进行划分。根据研究对象及数据的具体情况,本文采用第一种凝聚型层次聚类策略。
凝聚型层次聚类的具体步骤,是将每个样本视为具有单个元素的单个聚类,然后计算类之间的距离(相异性),合并具有最短距离的类(即最大的相似性),并遍历整个过程,逐步将小类合并,直到所有样本都在同一类中为止。设给定n个样本点x1,x2,…,xn,具体流程如下:
(1)将每个样本点视为一个类,并计算两个样本之间的距离dist(xi,xj);
(2)将两个最接近的类,合并为一个新类;
(3)更新类间的距离;
(4)重复(2)和(3)步骤,直到所有样本都被合并到一个类中/达到结束条件为止。
从层次聚类算法流程中可以看出,凝聚型层次聚算法的关键问题是,确立对象(样本)间,以及簇与簇之间的距离。而类与类之间的距离是根据不同的连接函数(如单连接、全连接)从样本间的距离产生。因此,两两样本之间的距离在算法中发挥着重要作用。在计算两个样本之间的距离时,传统的层次聚类法往往采用欧式距离。对于样本xi和xj,其距离度量如式(10)所示。
dist(xi,xj)=‖xi-xj‖2.
(10)
然而,基于欧式距离的凝聚型层次聚算法受噪声点的影响较大。当两个类的距离较近时,会由于少量距离较近的点优先合成一个簇,而实际两个类的大多数样本并不接近,从而造成聚类误差。基于欧式距离的凝聚型层次聚类算法,可看做是使用线性模型学习决策边界,由于它只能学习非常简单的线性决策边界,因此造成该算法对噪声点非常敏感,从而无法将类别有效的分开。对于在线性空间中无法分开的情况,可以将数据提高维度,在高维空间中找到分类边界,进而避免噪声点在原始空间的影响[5]。
本文采用高斯核度量的方法实现维数的增加,其定义如下:
(11)
如式(12)所示,高斯核函数的特性是把低维空间转化为无限维空间,同时又实现了在低维计算高维点积。
k(x,y)=〈φ(x),φ(y)〉=e-σ‖x-y‖2=e-σ(x2+y2)eσ2xy=
(12)
若给定n个样本点x1,x2,…,xn,基于高斯核的凝聚型层次聚算法如下:
(1)将每个样本点视为一个类,并基于式(11)计算两个样本之间的距离;
(2) 将两个最接近的类合并为一个新类;
(3)更新类间距离;
(4)重复(2)和(3),直到所有类都被合并到一个类中/达到结束条件为止。
从高斯核凝聚型层次聚类算法流程可以看出,该算法将样本间的距离计算修改为基于高斯核函数的度量,其它则保持了原始算法的步骤。该算法在保证了原始层次聚类算法简单性的同时,又可提高算法在克服线性不可分情况的缺陷。
3 实 验
原始采集数据经过运动学片段的划分、筛选,采用基于高斯核的层次聚类结果,使用TSNE在二维空间中可视化的展示如图1所示。 所有运动学片段可被分为3个类别,但每个类别中仍然有数百个运动学片段,则可从每个类别中提取适当的片段,这些片段应该尽可能完整地反映每种类型的片段特征,从而使构造的车况曲线可以客观地反映车辆的实际驾驶情况。
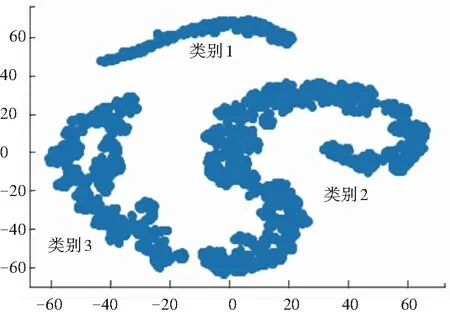
图1 聚类结果图
通过分析每一类的运动学片段发现:第一类的加速、减速时间比例最低,怠速时间比例最高, 说明汽车长时间怠速,但是起步加速与制动减速运行时间较短,第一类可代表汽车在拥堵的主干道上的交通特征;第二类的加速、怠速、减速时间比例均中平,匀速时间比例最高,表明汽车匀速行驶时间较长,同时也要经历一定的停车、怠速、起步,第二类可代表汽车在比较畅通的支干道上行驶的特征;第三类的匀速、怠速时间比例最低,加速、减速时间比例最高,代表汽车行驶中可以长时间加速、减速行驶,停车怠速时间很短,该类可代表汽车在通畅的城郊道路上行驶的特征。
从每个类中挑选运动学的一个片段,拼接成1 300 s的工况循环曲线,如图2所示。
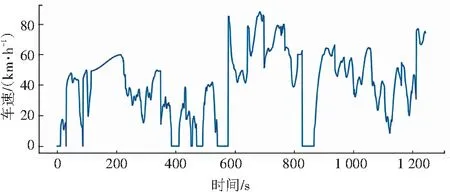
图2 构建工况图
由此可见,其结果完全符合汽车工况规律,具有有效性。
4 结束语
汽车行驶工况描述了汽车行驶速度的时间曲线,反映了道路上汽车的运动特性,是车辆的能耗排放测试方法和极限标准的基础,是汽车各种性能指标的校准和优化的最重要基准。本文在定义了包括统计特征、形状特征、熵特征等共计14个运动学片段的有效特征后,构建基于高斯核的层次聚类算法对片段进行聚类。 根据运动学片段类别的比例及
时间比例,从聚类结果的中抽取具有代表性的片段拼接成1 300 s的工况图。经试验结果表明,构建的工况图具有较大参考价值。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
煤气与热力(2022年4期)2022-05-23
南京理工大学学报(2022年1期)2022-03-17
计算机应用与软件(2021年7期)2021-07-16
舰船科学技术(2021年12期)2021-03-29
汽车工程(2021年12期)2021-03-08
北京汽车(2020年1期)2020-05-07
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
小天使·二年级语数英综合(2019年4期)2019-10-06
电影故事(2015年16期)2015-07-14
