
基于残差网络的智能交通标志识别算法
2020-03-18 01:39:06王佳琪高睿杰谢冰洁谷殿月于慧伶
智能计算机与应用 2020年9期
王佳琪, 李 哲, 高睿杰, 谢冰洁, 谷殿月, 于慧伶
(东北林业大学 信息与计算机工程学院, 哈尔滨 150040)
0 引 言
随着人民生活水平的日益提高,机动车作为一种舒适便捷的交通工具,逐渐成为人民生活中不可或缺的产品。据调查,美国公路上每年发生约600万起交通事故,其中的94%是由人的操作和是失误引起的[1]。发展无人驾驶汽车可以减少或防止交通事故的目的。自动驾驶技术研究已有近百年的历史,随着计算机技术以及人工智能的迅速发展,自动驾驶技术的研究与开发也进入了一个高速发展的阶段,其中交通标志识别技术是无人驾驶汽车感知静态交通环境的关键内容,世界各大院校及研究机构在交通标志识别领域均有不同程度的研究[2]。目前主流的方法有基于模板匹配、机器学习和深度学习的方法。
模板匹配方法是将预先已知的小模版在大图像中找到与模板最匹配(相似)的目标,确定其坐标位置。冯春贵等人提出了一种改进的模板匹配方法,对限速标志进行识别[3],与传统模板相比较,识别率由80.95%提高到95.24%。基于模板匹配方法的识别结果易受到图像遮挡、变形、破坏等影响,不能同时兼顾计算量和鲁棒性的要求。随后基于机器学习的交通标志识别成为了一种更为流行的方法。该算法主要采用“人工提取特征+机器学习”的模式,先提取能够描述交通标志信息的特征,随后结合机器学习算法完成识别。常用的机器学习分类器有支持向量机(SVM)、BP神经网络和最近邻算法(KNN)。胡晓光等人提出使用SIFT方法提取标志的局部特征,使用SVM训练得到分类模型,在采集测试影像集上的识别率为93%[4]。深度学习具有十分强大的特征学习能力,深度卷积神经网络(CNN)不需要设计手工特征,输入的图像可以通过监督学习来自动完成特征提取和分类。Sermanet等人提出的多尺度CNN应用于交通标志的识别,达到99.17%的准确率[5]。基于深度学习的交通标志识别方法相比于传统人工设计特征方法更有优势,准确率更高。但是计算效率较低,对硬件要求较高。
采用以上各方法,目前已经基本可以实现对各类交通标志的准确识别。准确率不断提升的同时也提高了对硬件的要求,提升了生产成本,给智能交通标志识别系统的普及造成了一定的困扰。本文提出的基于残差神经网络的智能交通标志识别算法,在Mxnet框架下引入残差神经网络模型,支持多机多节点、多GPU的计算,在保证了识别率的前提下,加快了识别速度,同时提高了算法的可移植性,使得智能交通标志识别系统可以在多种用户端使用,具有较大的应用前景。
1 数据
本研究采用中国交通标志检测数据集(CCTSDB)中的58类交通标志,如图1所示,合计6 164幅图像作为实验数据。CCTSDB数据库中的交通标志图像全部从自然场景中采集得到,能够真实反映出实际道路条件下的交通标志外貌。同时,数据集中也包含了大量不利条件下的交通标志图像,比如低分辨率、部分标志遮挡、不同光照强度、运动模糊、视角倾斜等,能较全面的反应现实驾车情况,增加识别系统的鲁棒性。

图1 中国交通标志检测数据集
2 数据预处理
由于每张交通标志图片的数据量较大,所以在实验之前,需要对所有的图片预处理,提取图片中的有效信息,如图2所示。
首先,读入图片,进行尺寸变换。由于数据集中的每张图片存在尺寸差异,在保证图片清晰的前提下,使用opencv中的立方插值方法将每张图片的尺寸变换为64×64像素大小,同时将其灰度化处理;其次,对变换后的图片高斯滤波。本文设置高斯滤波器模板大小为5×5,偏差sigma参数值为1.5。以去除图片中高光点对边缘提取的影响;最后,将滤波后的图片进行非微分边缘检测算子Canny边缘提取,设置阈值大小为30。Canny方法不容易受噪声干扰,可以检测到真正的弱边缘。设置高阈值为30,低阈值为70,高阈值将提取轮廓的物体与背景区分开来,低阈值平滑边缘的轮廓。高阈值可能使边缘轮廓不连续或者不够平滑,通过低阈值来平滑轮廓线,使不连续的部分连接起来,让边缘轮廓更加明显。由于图片存在除边缘外的无效像素信息,为避免对实验的干扰,需要进一步裁剪,最终仅保留图片需要识别的48×48的像素信息,减少了无关因素对实验的影响。

图2 交通标志预处理
3 实验过程
3.1 实验方法
在本研究中,采用ResNet模型。该模型可以解决“退化”问题,一般的神经网络模型在学习时,梯度弥散/爆炸成为训练深层次的网络的障碍,导致网络无法收敛。而该神经网络模型不同于一般模型,引入了残差模块,如图3所示。在输入和输出之间建立了一个直接连接,新增的层仅需要在原来的输入层上学习新的特征,即学习残差。
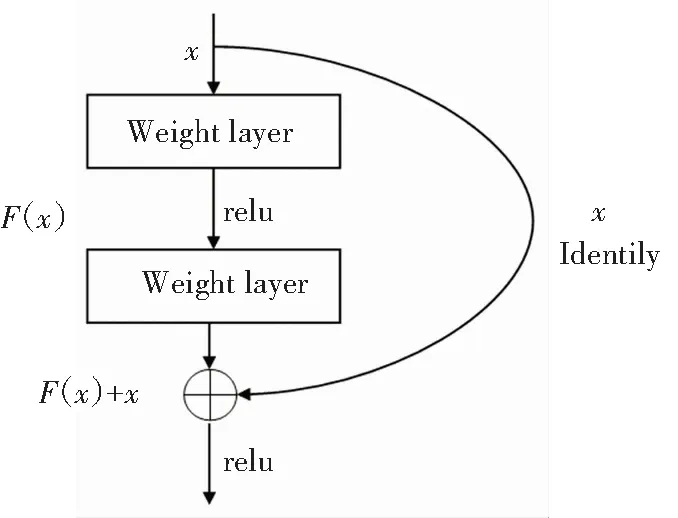
图3 残差模块图
通常残差模块的结构有二种,一种具有二层3×3的卷积层,另一种有3层卷积层,分别为1×1、3×3、1×1,本文选择ResNet18模型中的残差模块为二层卷积的结构作为基础。该模型的残差模块第一层(weight layer)为3×3卷积层,加入Batch Normalization层,经过Relu激活函数后还存在一层3×3卷积层,其次一层为Batch Normalization层,最后一层为相加层。ResNet18包含17个卷积层和一个全连接层。该模型首先是将预处理好的图像进行7×7、步数为2的卷积,之后通过同样步数,3×3的池化层,将池化后的结果依次带入到4个残差模块(ResBlock)中,最后加入一层全连接层,输出一个1×1的矩阵,通过Softmax运算即可以进行图像的分类,模型中的每一层参数值大小见表1。通过引入残差模型可以在不降低准确率的情况下快速的学习并分类。
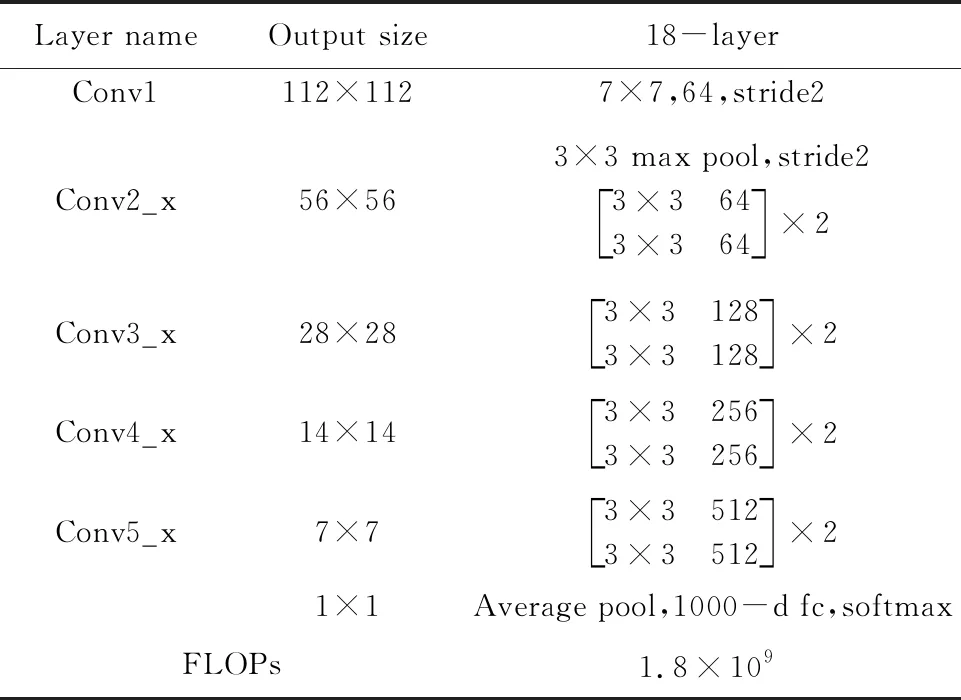
表1 ResNet各层参数值
3.2 实验结果与分析
分类模型的评价需要关注分类后的结果的影响,本实验将正确划分的类别和没有被正确划分的类别计为评价指标中的二类。
(1)Truepositives(TP):被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数;
(2)Falsepositives(FP):被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
(3)Falsenegatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
(4)Truenegatives(TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
本文选取灵敏度和正确率作为残差神经网络分类器的评价指标,检查分类器是否能够大概率识别所有的正例。
通常判断分类模型的好坏需要关注分类后的结果的影响,本实验将正确划分的类别和没有被正确划分的类别计为评价指标中的二类。
(1)Truepositives(TP): 被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数(样本数);
(2)Falsepositives(FP): 被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数;
(3)Falsenegatives(FN):被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数;
(4)Truenegatives(TN): 被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数。
本文选取灵敏度和正确率作为残差神经网络分类器好坏的评价指标,检查分类器是否能够大概率识别所有的正例。
灵敏度(sensitive)表示所有正例中被分对的比例,衡量了分类器对正例的识别能力,式(1):
sensitive=TP/(FP+TP).
(1)
正确率(accuracy)越高,分类器越好,式(2):
accuracy=(TP+TN)/(FP+TP+FN+TN).
(2)
在CCTSDB中,针对每一个不同的交通标志,通过本文的残差神经网络分类器识别后,得到的TP为2778,FP为223,FN为278,TN为2 885,经过计算,最终得到的灵敏度为92.57%,正确率为91.87%.
4 结束语
本文首先对图像高斯平滑和Canny锐化,提取边缘轮廓,得到更利于分辨的图像;其次,将预处理后的图像带入到神经网络框架MxNet中的ResNet18的模型中,该神经网络框架可以多GPU快速处理,并有较好的移植性;得到的交通识别分类结果准确率为91.87%,与SVM方法比较错误率降低了10.36%,见表2。本文的交通标志图像智能识别方法可以快速的识别交通标志。该识别模型的较高可移植性在无人驾驶技术上有较高实际应用价值。在保证识别率的前提下,加快了识别速度,提高了算法的可移植性,使得智能交通标志识别系统可以在多种用户端使用,具有较好的应用前景。

表2 各算法识别率对比图
猜你喜欢
中小学课堂教学研究(2023年12期)2024-01-05 16:14:43
东方少年·布老虎画刊(2023年12期)2024-01-01 08:51:05
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
汽车实用技术(2022年9期)2022-05-20 06:04:02
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
数学教学通讯·小学版(2019年7期)2019-09-09 01:07:24
自动化学报(2019年6期)2019-07-23 01:18:32
小天使·一年级语数英综合(2016年8期)2016-05-14 19:43:16
新课程·下旬(2016年3期)2016-05-10 08:59:34
河南科技(2015年8期)2015-03-11 16:23:52
