
基于异构信息网络表征学习的推荐方法
2020-03-15 10:15李亚莹
现代计算机 2020年4期
李亚莹
(四川大学计算机学院,成都610065)
0 引言
近年来,由不同类型的节点和边构成的异构信息网络备受关注,它已被作为一种信息建模工具应用于推荐系统,称为基于异构信息网络的推荐。现有方法主要依赖节点相似性提取推荐辅助信息,其有效性略显不足。因此,有学者提出基于异构信息网络表征学习的推荐[1]。网络表征学习为网络中的节点学习低维表示向量,该向量被认为保存着节点在网络中的特征信息,可以直接用于现有机器学习算法解决问题。
异构网络表征学习面临着诸多挑战,如节点和边的异构性以及网络中信息融合等带来的挑战,而这些与基于异构信息网络表征学习的推荐息息相关[2]。为解决上述问题,Shi等[1]利用元路径抽取异构网络中的多个同构网络并对其进行表征学习,然后利用融合函数及矩阵分解进行评分预测。实验结果展示了其在推荐性能上的提升,但依然存在不足。
首先,元路径只能表示简单语义,对复杂语义无能为力。为了捕获复杂语义,Huang等[3]提出元结构。其次,网络表征学习启发自自然语言处理中词向量学习,多数算法将节点类比为词汇,将节点序列类比为语句,在训练向量时亦采用训练词向量的skip-gram模型。然而,语句长度通常多变,而由随机游走生成的节点序列却长度相同。
针对以上问题,本文提出基于元结构和截断随机游走的异构信息网络表征学习MSHE,并将每个元结构上学习到的节点向量作为特征融入推荐样本,结合FFM模型预测评分,提出基于异构信息网络表征学习的推荐方法MSHER。实验表明,该方法在推荐性能上表现良好。
1 相关定义
本节将介绍相关背景知识,以便对后续算法的阐述。
定义1(异构信息网络[4])一个异构信息网络可以表示为G={V,E},其中V、E分别是节点和边集合。网络中还存在着映射φ:V→A以及φ:E→R,其中A、R分别是节点和边的类型集合,满足|A|>1、|R|>1。
定义2(网络模式[4])对于异构信息网络G={V,E},其网络模式TG=(A,R)是定义在A和R上的有向图。
图1 展示了一个构建在Yelp数据集上的异构信息网络,图2是其网络模式。在该网络中,有6种类型的节点:用户(U)、商家(B)、类别(Cat)、城市(Ci)、评论(R)以及关键字(K);节点之间存在不同类型的关系,如用户和项目的签到关系、项目和类别的属于关系等。

图1 异构信息网络示例

图2 网络模式示例
定义3(元路径[4])元路径P是定义在网络模式TG=(A,R)上的路径,用于表示节点之间的复合关系,其表示形式如下:可简写为A1A2···Al+1。
定义4(元结构[3])给定网络模式TG=(A,R),元结构S=(N,M,ns,nt)是一个以ns为源点、以nt为终点的有向无环图,其中N、M分别是A和R的子集。
图3 展示了Yelp网络中一个元路径及元结构示例。元路径P表示由两个用户发表的评论包含同一关键字。而元结构S表示由两个用户发表的评论不但包含同一关键字,并且针对同一商家。

图3 Yelp网络中的元路径及元结构示例
2 基于异构信息网络表征学习的推荐
2.1 基于元结构和截断随机游走的异构信息网络表征学习
本文利用网络表征学习的方法提取和表示异构信息网络中用于推荐的信息。本节将按照图生成、随机游走以及表示学习对MSHE模型进行介绍。
(1)图生成
给定一个由推荐数据集构建的异构信息网络,本文的目标是为每个用户、项目节点学习低维表示向量。与先前工作不同,本文主要基于元结构挖掘网络中的语义。为解决元结构的非线性结构问题,将以图3中元结构为例,提出如下方案:
①首先,从原网络中抽取用户和评论节点,并依原网络建立链接,构成异构图BG;
②其次,从原网络中找出既包含相同关键字又针对同一商家的评论对,并放入集合W;
③最后,遍历集合W,将W中存在的评论对,于BG中建立链接,形成关系R-R。
如图4所示,BG中的R-R关系等价于图3中元结构的分支关系,在BG中沿元路径URRU进行矩阵运算可得到具有元结构语义的同构邻接矩阵AUU,根据该矩阵构建同构网络HG,以便后续节点序列的生成。
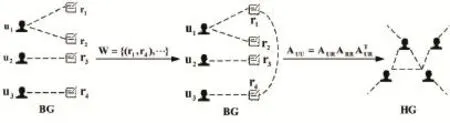
图4 图生成示例
(2)随机游走
MSHE模型将在HG上进行随机游走。为了获得更有意义且与语句特征更相符的节点序列,在随机游走中引入节点相似性和停止概率。与当前节点相似性越高的节点,更有可能成为下一跳节点;而停止概率则表示随机游走在当前节点终止的概率,若当前节点到其邻居节点的所有转移概率均小于停止概率,则随机游走在当前节点终止。
对于从当前节点i到下一跳节点x的转移概率,本文有如下定义:

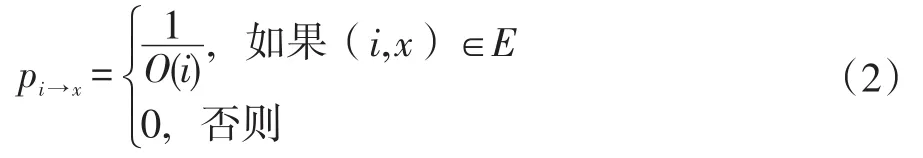
其中,O(i)表示节点i在HG上的度。
(3)表示学习
给定节点序列及固定窗长,便可构建节点u的邻居集合Nu。依照node2vec[5],得到如下优化函数:

其中,g:V→Rd是将节点映射到d维特征空间的目标学习函数,Nu⊂V表示在给定元结构上节点u的邻居集合,可以利用SGD优化式(3)学习映射函数g(·)。
综合上述三个过程,下面给出MSNE模型在单个元结构上的整体描述。
2.2 基于异构信息网络表征学习的推荐方法
通过MSNE模型,每个用户节点u和项目节点b均会生成多组低维向量。不同于现有工作,本文并未学习融合函数,而是以推荐为导向,将低维向量作为特征融入推荐样本,助益推荐。对于每个推荐样本xn,本文有如下定义:

给定(4)式中的所有特征,本文利用FFM[6]计算样本xn的评分:

其中,w0是全局权重;wi是第i个特征的一阶权重;fj是第j个特征所属的域,vi,fj是第i个特征在域fj上的隐向量。本文域个数由元结构数量决定,并规定由同一元结构生成的特征属于同一个域。上述模型参数可以通过下式学习:

其中,yn是第n个样本的真实评分,N是所有样本的数量。
3 实验
3.1 实验数据
实验数据来自Yelp网站提供的Yelp数据集以及文献[7]提供的Amazon数据集。表1和表2给出了两个数据集的详细信息,并于表3展示了本文设计的元结构。

表1 Yelp数据集

表2 Amazon数据集

表3 实验数据集上的元结构
3.2 实验分析
本文使用均方根误差RMSE作为评估指标,RMSE越小,算法性能越好。
本文先比较算法本身。图5的①、②分别展示了MSNER方法在两个数据集上是否使用元结构进行推荐的结果。由图可知,使用元结构结果明显优于未使用结果。由此可见,挖掘语义信息时,元结构的确优于元路径。


图5 实验结果
除自身比较,还将算法与其他算法对比。由于使用基于元结构的截断随机游走捕获网络语义信息,并且避免了学习融合函数带来的损失,从图5的③、④可以看出,MSNER算法在两个数据集上性能均高于文献[1]中使用元路径及学习融合函数的HE-Rec算法,由此也说明了本文算法的有效性。
4 结语
随着数据的海量增长,推荐系统对众多线上应用愈发重要。本文介绍了一种基于异构信息网络表征学习的推荐方法,利用异构信息网络对推荐辅助信息建模,提出基于元结构和截断随机游走的异构信息网络表征学习去刻画用户和项目特征。对于单个用户和项目的多组特征,本文并未学习统一的融合函数,而是将每组特征融入推荐样本,直接利用FFM模型进行评分预测。实验结果证明了该方法对推荐的有效性。
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
北京航空航天大学学报(2022年8期)2022-08-31
计算技术与自动化(2022年2期)2022-07-04
小学教学研究(2022年5期)2022-04-28
福建基础教育研究(2019年11期)2019-05-28
新教育时代·教师版(2016年26期)2016-12-06
求知导刊(2016年30期)2016-12-03
职工法律天地·下半月(2016年10期)2016-11-30
科技视界(2016年21期)2016-10-17
长江学术(2016年4期)2016-03-11
