
基于特征选择的TLS蒙古栎人工林点云分类研究
2020-03-11 05:32汪献义邢艳秋
中南林业科技大学学报 2020年3期
邢 涛,汪献义,邢艳秋
(东北林业大学 森林作业与环境研究中心,黑龙江 哈尔滨 150040)
地面激光雷达(Terrestrial laser scanning,TLS)可以获得高精度与高层次的几何数据,其已经广泛应用于林分参数提取、树干提取、单木分割[1]与建模及生物量估计等研究[2]。在林业研究中,将地面激光雷达点云快速标记为地面、树干与枝叶3个类别可为上述研究奠定基础,所以研究点云分类具有重要意义。
点云分类可分为逐点分类、基于分割的分类与基于多实体分类的3 种策略[3]。逐点分类的策略先逐点搜索一定数量的近邻点,然后依据近邻点计算点特征训练分类器以达到分类目的。如Demantké 等[4]基于建筑物多存在线状、面状或体状的特性,研究了逐点计算定半径内点云特征的建筑物分类;Weinmann 等[5]通过逐点搜索构造了一系列2 维与3 维几何特征训练随机森林[6]分类器实现城市点云分类;Becker 等[7]通过逐点计算点近邻计算了包含几何特征、高程特征与颜色特征的17个特征训练随机森林分类器实现城镇点云分类。基于分割的分类可分为两种方式,分别为基于分割面片辅助的点云分类与基于体素分割的点云分类。如Zhang 等[8]研究了基于分割面片辅助的点云分类,其在分类过程中首先采用区域生长法[9]将点云分割成相对独立的面片,然后计算这些面片关于几何特性、辐射强度特性、回波特性与拓扑关系的一系列特征训练支持向量机[10]实现点云分类;在基于体素分割的点云分类过程中,考虑到每个体素内点特征相近,Hackel 等[11]定义了9个尺度的体素化滤波分别下采样待分类的点云,在每一次下采样后逐点计算体素重心与邻近9个体素重心关于几何特性、状态特性与高程信息的16个特征,计算好特征之后训练随机森林分类器实现点云分类,该方法遍历完9个尺度后每个点使用144个维度的点特征表示。基于多实体的分类是以每个实体为单位计算特征实现点云分类。现阶段这种分类方法多应用机载分类,如Xu 等[12]将点云分为孤立点、分割面片与meanshift 分割面片3个实体[13],然后针对每一个实体都计算了相关特征训练5 种分类器,最终将表现最好的分类器应用于点云分类;倪欢等[3]将点云分为规则面片、粗糙面片与单个点3个实体,在点云分类过程中首先进行实体表达,而后进行地面分割与非地面实体分类,在非地面实体分类过程中分别计算了包含回波特性、描述子特性与几何特性的21个特征训练随机森林分类器实现点云分类。虽然这3 种分类的具体实现方式不同,但仔细分析发现大多的研究都需要构造较多的经验特征训练分类器实现分类,其中Hackel 等[11]的研究构造的点特征维度最高,达到144 维,这在处理大规模数据点云分类时特征计算将消耗较多运行内存。
为了解决上述问题,本研究以逐点分类策略为基础,在分类过程中引入特征选择[14]技术实现降低特征维度,从而达到避免盲目构造特征的目的。本研究的点云分类特指将地面激光雷达扫描的蒙古栎Quercus mongolica人工林数据分为地面、树干与枝叶点云3个类别,在分类过程中首先计算19个经验特征训练xgboost[15]分类器,然后依据分类器的表现,在保证分类器性能的基础上选择适当数量的特征参与点云分类。
1 数据与方法
1.1 数据与样本
本研究的地面激光雷达设备为徕卡Scanstation C10,扫描仪测距长,工作效率高,可快速获取高精度三维点云数据,具体仪器参数见表1。本研究的数据采集自东北林业大学实验林场的蒙古栎Quercus mongolica人工林(图1b),该人工林地势平坦、林下灌木较少,通视条件较好,单木间隔为3 m 左右,单木垂直特性较好且单木间存在枝叶遮挡,单木胸径与树高均值分别为13.55 cm与9.98 m。数据采集时间为2016年6月,研究区样方尺寸为20 m×20 m,在扫描过程中共架设5个扫描站,即A1~A5 站(图1a),站间间距 20 m 左右,其中A1 站为全景扫描,其余测站为定向扫描。
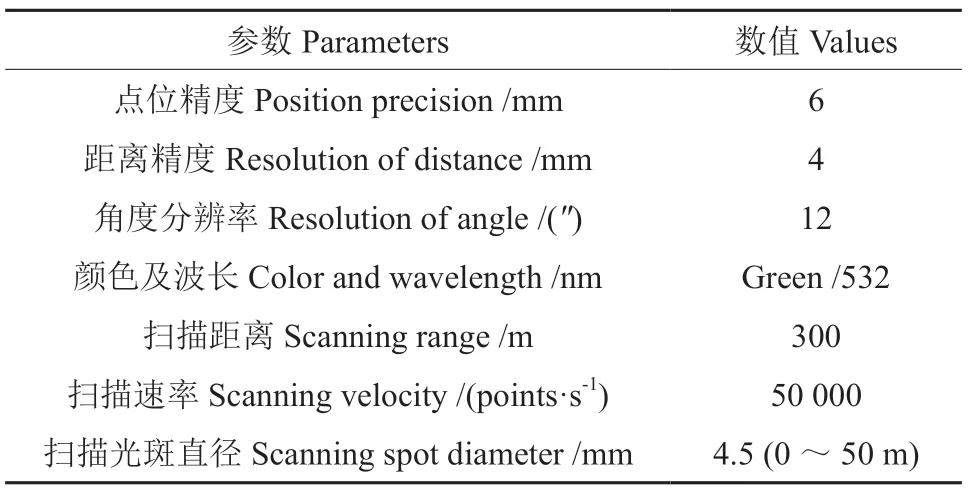
表1 三维激光扫描仪技术参数Table 1 Technical parameters of TLS
训练分类器过程中需要用到训练样本、验证样本与测试样本。训练样本用于训练分类器,验证样本用于判断分类器训练过程中是否出现过拟合或欠拟合,所以本研究的训练样本与测试样本来自同一扫描站。鉴于本研究的5个扫描站点云数据特征相近,全景扫描的数据量相对丰富,所以本研究的训练样本与验证样本分别为从标记好的全景扫描数据中按9:1 的比例随机分配获得,测试样本为剩余4个站点中任选1站的点云数据。
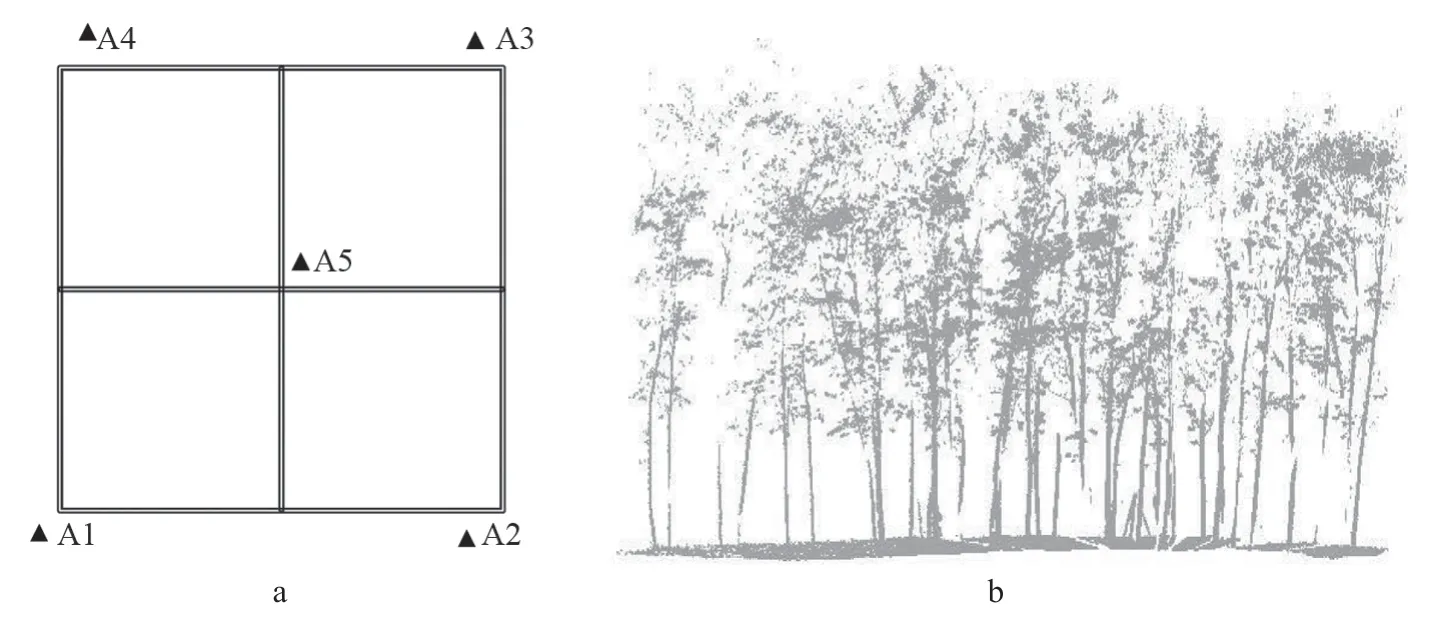
图1 研究方法与对象Fig.1 Research method and object
1.2 点云特征
在点云分类任务中,分类器的性能往往取决于特征对待分类对象的表征能力。近年来通过各领域研究人员的不懈探索,提出了许多不同应用场景的点云特征[14]。本研究引入19个经验特征,其包括4个基于水平投影构造的特征与15个基于三维点云构造的特征。
1.2.1 基于水平投影构造的特征
基于水平投影构造的特征由仅取三维点云的XY 坐标分析点云特性获得,本研究引入的4个特征描述如下:
1)基于特征值的特征:
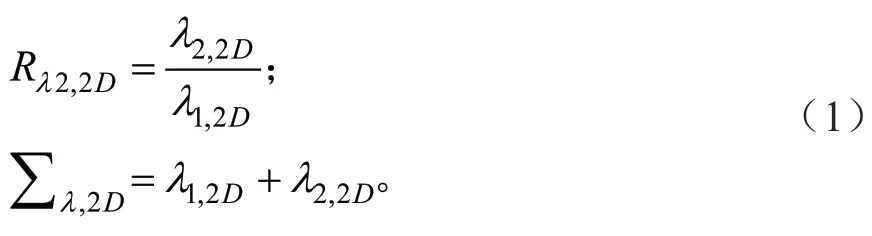
式中:λ1,2D与λ2,2D分别为近邻点云在水平投影面中协方差矩阵的特征值,特征Rλ,2D由λ2,2D与λ1,2D的比值获得,其描述了点云的二维平面特性,Σλ,2D由λ2,2D与λ1,2D的和构成。
2)基于距离的特征:
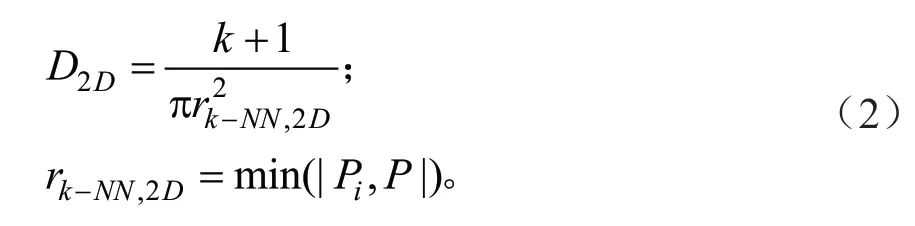
式中:k表示当前点云的近邻数量,表示水平投影面中当前点与k个近邻点最远距离的平方,特征D2D由k+1 与的比值获得,其表征当前点在二维投影面中的点云密度,特征rk-NN,2D表示当前点与近邻点的最近距离。
1.2.2 基于三维点云构造的特征
基于三维点云构造的特征由分析XYZ 维度的点云特性获得,本研究引入的15个特征描述如下:
1)基于特征值的特征:
基于特征值构造的点云特征值较多,包括面度(Pλ)、散度(Sλ)、各向异度(Aλ)、全向方差(Oλ)、特征值和(Σλ)、线度(Lλ)、特征值熵(Eλ)及曲率(Cλ):
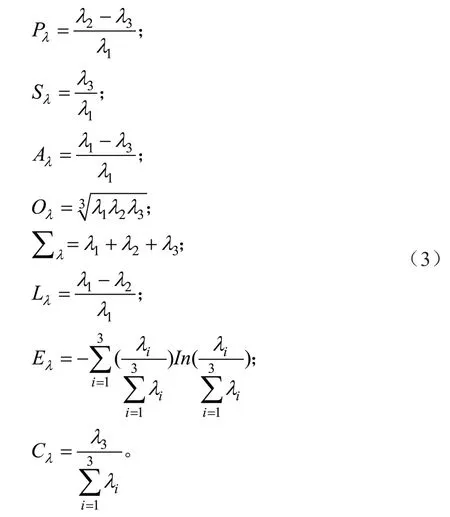
式中:λ1、λ2、λ3表示三维点云的特征值,由解算近邻点的协方差矩阵获得。
2)基于法向量的特征:

式中:|nZ|表示当前点关于近邻点拟合平面法向量的在Z 轴的分量。
3)基于距离的特征:
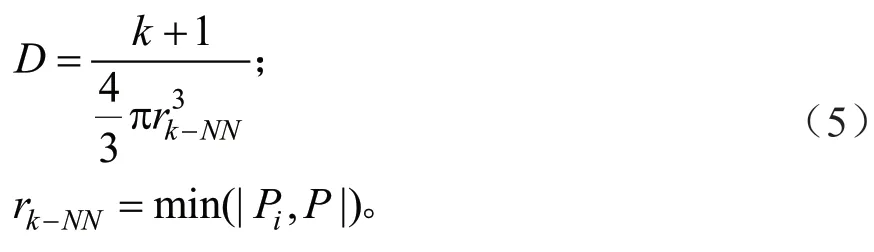
式中:k表示当前点的近邻数量,表示当前点与k近邻中最远点确定的球体积,特征D 由k+1 与的比值获得,其表征当前点的点云密度,rk-NN,2D表示当前点与近邻点的最近距离。
4)基于高程的特征:
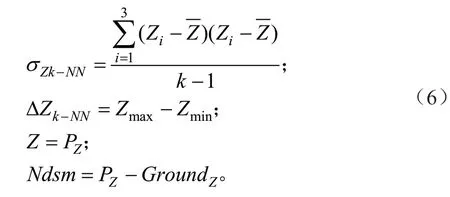
式中:σZk-NN表示近邻点高程的方差, ΔZk-NN表示近邻点的最大高程差,Z当前点高程,Ndsm 表示归一化高程值。
1.3 xgboost 分类器与特征选择
1.3.1 xgboost 分类器
xgboost 是GBDT[16](Gradient boosteddecision trees)的改进,其优点如下:1)引入正则化项,防止分类器过拟合;2)采用剪枝技术,保证算法精度;3)目标函数采用泰勒展开式的二项逼近;4)支持并行计算,提高运算效率。
xgboost 优化的目标函数定义如下:
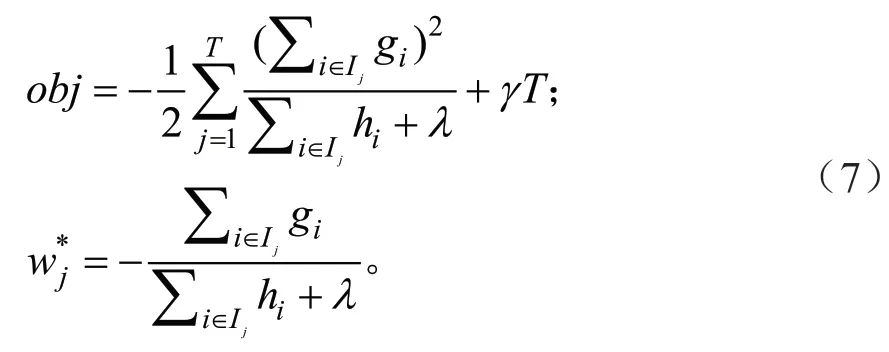
式中:gi,hi为目标函数的一阶与二阶梯度,γ,λ是目标函数的优化参数,T是决策树的叶子节点数,Ij是训练样本所在的叶子索引,是第j个叶子节点的权重。只与样本梯度相关,在决策树中每个样本的得分用其所在的叶子节点权重表示。那么在xgboost 中,样本类别通过计算其在每个决策树中的得分和获得。
在xgboost 中节点的分裂方式是决定分类器性能的关键,其通过计算子节点对目标函数的信息增益来控制节点分裂(式8)。
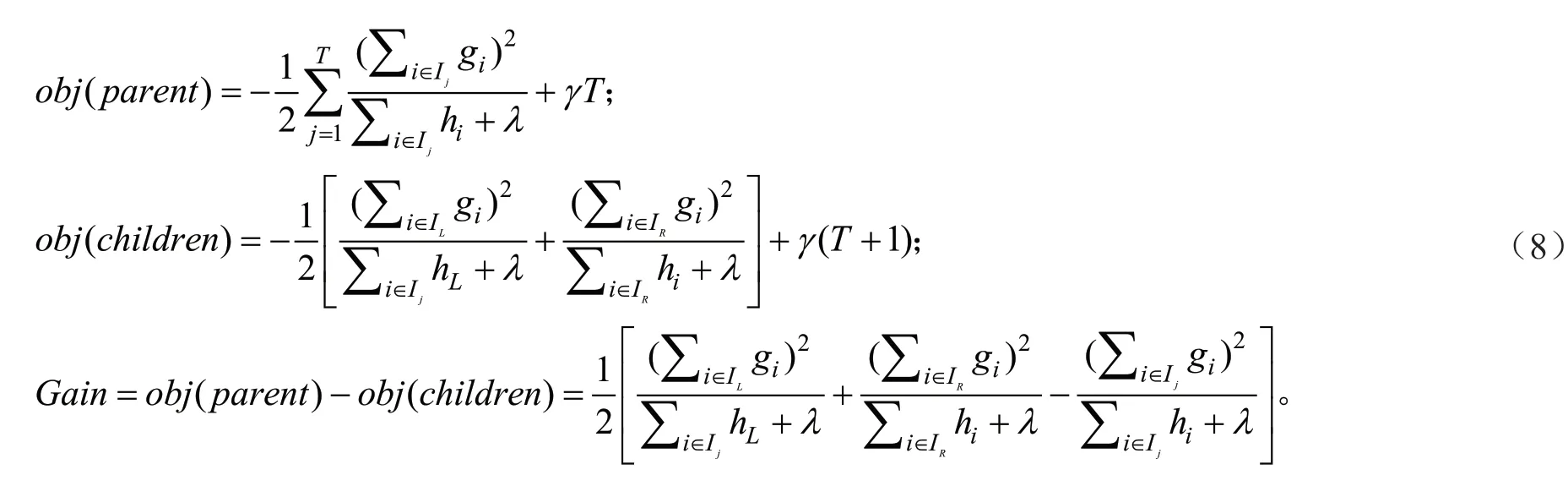
式中:obj(parent)、obj(children)、Gain分别表示分裂前目标函数值、分裂后目标函数值与信息增益,L,R分别表示左右叶子节点。若信息增益大于0 表示当前分裂能够促进目标函数值减小,允许分裂,反之禁止分裂。
1.3.2 特征选择
本研究构造了19个经验特征训练xgboost 分类器,特征维度较高,研究者总希望用较低维度的特征用于训练分类器,这样既可以保证算法的效率又有利于节约计算成本,故此引入特征选择技术势在必行。特征选择方式一般包括基于统计的特征选择与基于模型的特征选择。基于统计方式包括方差检验、相关系数法与卡方检验等,这种方式仅依据特征自身判断特征的重要性。基于模型的方式包括递归特征消除法、基于惩罚项的特征选择法与基于树模型特征选择法等,这种方式通过特征对分类器的贡献来判断特征的重要性,更加直接客观。本研究的xgboost 属于一种较为稳定的树模型分类器,所以本研究考虑将上述19 维点云特征直接应用于xgboost 分类器实现特征选择。在xgboost 中,分类器训练结束后将统计以某一特征为依据进行分裂的节点数量,本研究依此判断各个特征对模型的贡献从而实现特征选择。
1.4 精度评价
在完成分类之后需要采用一定的准则定性分析分类器的精度,本研究衡量分类器性能定义如式(9)所示:
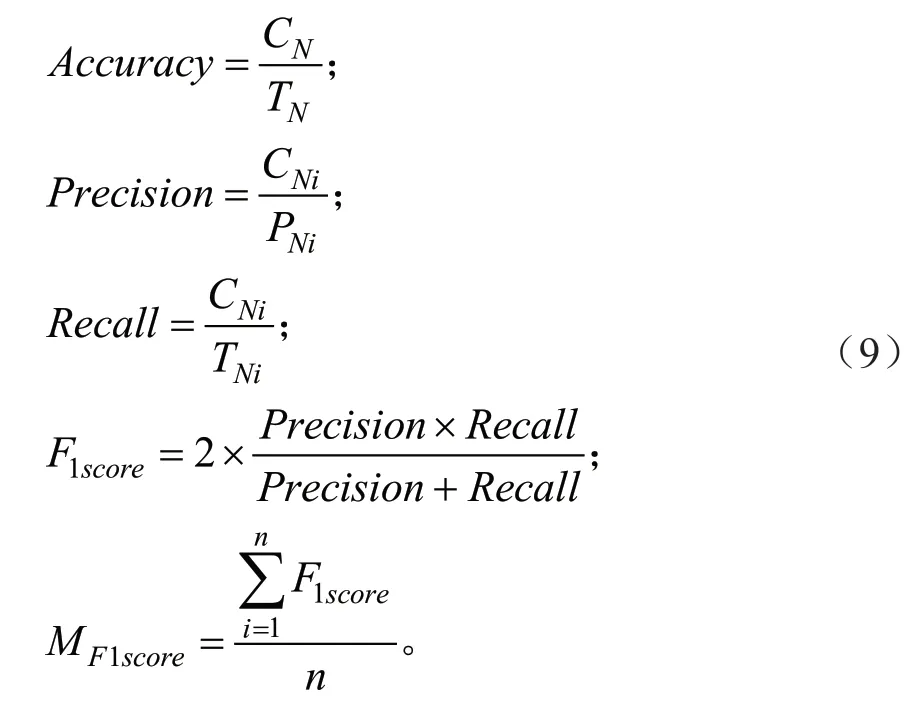
式中:Accuracy、Precision、Recall、F1score、MF1score分别表示分类器的准确率、查准率、召回率、F1score与F1score均值。CN表示正确估计的样本数,TN表示样本总量,CNi表示类别i中正确估计的样本数量,PNi表示估计为类别i的总量,TNi表示实际为类别i的总量,n表示样本类别个数。研究者通常采用Accuracy与MF1score衡量分类器的总体表现,其值越大表示分类器分类效果越好。
2 结果与分析
搜索适当数量近邻点对分类器的性能影响不大,本研究通过搜索点的100个近邻点计算特征。在使用xgboost 过程中梯度树的数量为100,每一个梯度树的最大训练深度为6。本节就特征选择结果及特征选择前后点云分类结果展开分析。
2.1 基于xgboost 的特征选择
图2 统计了xgboost 特征重要性分布直方图,该特征重要性表示在xgboost 训练过程中梯度树节点依据某一特征产生分裂的频率。图3 为依据特征重要性依次增加特征训练xgboost 的测试准确率。结合图2~3 易知特征Z、Ndsm与V重要性较为显著,其值均大于1 500,当仅引入特征Z 时分类器的测试准确率介于0.75~0.80 之间,若继而引入特征Ndsm与V则测试准确率攀升至0.90与0.95 之间,分类器性能明显提高。当引入到第5个特征(ΔZk-NN)之后,分类器测试准确率均稳定于0.95~0.96 之间。考虑到引入第7个特征(Cλ)后分类器性能有微弱降低(图3),所以本研究特征选择结果为前6个重要性较高的特征。
本研究特征计算均使用同一种计算机语言在同一台电脑运行,为了考量特征选择前后特征的计算效率,表2 统计了在训练集与测试集分别计算19个特征与6个特征的特征计算用时,同时给出了计算6个特征与计算19个特征的用时比。本研究的训练集数量比测试集多,所以容易发现训练集相应特征计算用时均大于测试集。观察特征计算用时占比发现,在训练集与测试集中计算6个特征用时均约占计算19个特征用时的一半。
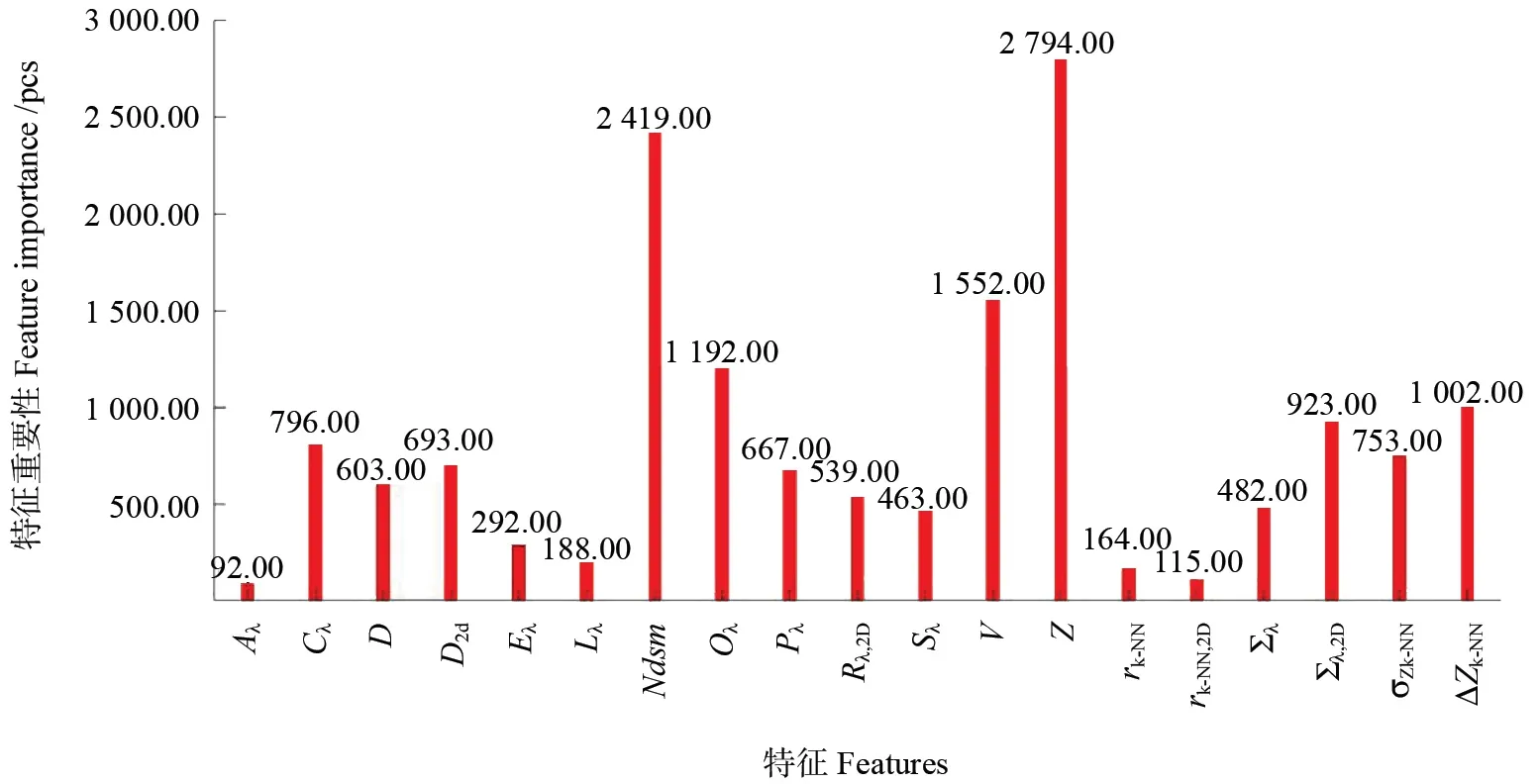
图2 xgboost 特征重要性分布直方图Fig.2 The feature importance histogram of xgboost
2.2 点云分类结果分析
为了定性分析特征选择前后分类器的性能,本研究在表3 中分别统计了分类器使用6个特征与19个特征在测试集的准确率、查准率、召回率、F1score与MF1score。分类器基于6个特征与19个特征的测试准确率分别为0.954 8 与0.956 2,前者比后者低了0.001 4。仔细分析易知,在使用6个特征与19个特征的过程中,分类器关于地面类别的查准率、召回率与F1score相近,使用19个特征的分类器关于树干与枝叶类别的查准率、召回率与F1score的性能均比使用6个特征的分类器性能有千分级的优势。基于6个特征与19个特征的MF1score分别为0.959 2 与0.962 2。综合准确率与MF1score易知,特征选择前后的分类器均可较好的完成本研究的地面激光雷达 点云分类任务。
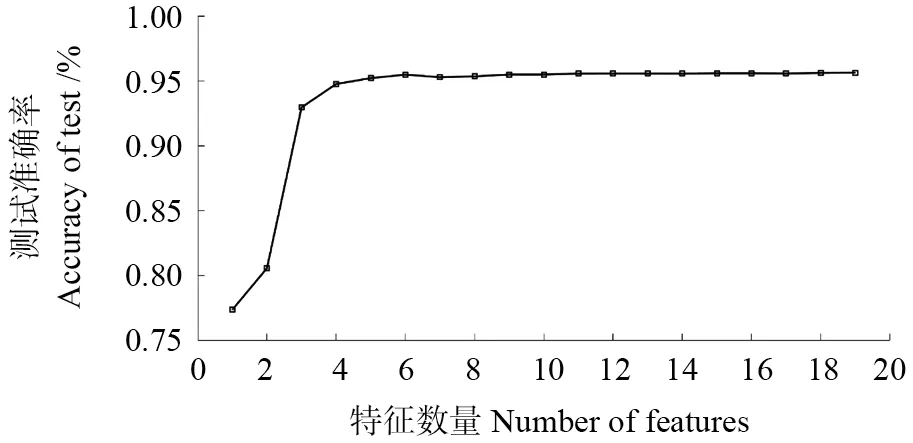
图3 基于特征选择的分类器测试准确率Fig.3 The classifier’s test accuracy based on feature selection
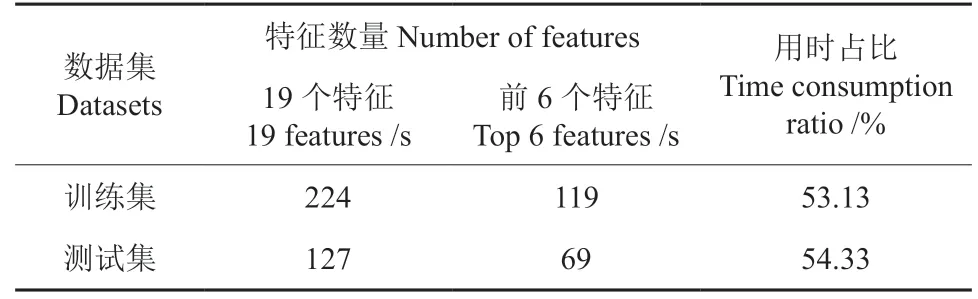
表2 特征计算用时统计Table 2 The statistics of feature calculating time
图4 展示了分类器基于特征选择的测试集分类结果,颜色绿红灰分别表示枝叶、树干与地面点。由召回率易知分类器正确的估计了大多的地面点,错误估计的点云大多来自枝叶与树干(表3),所以在图4b 中仅展示了树干与枝叶错分的细节图。由于枝叶与树干在空间上存在邻近的点云,这些邻近点云特征相似度较高,所以本研究容易将部分枝叶错分为树干(图4b-2),同时也存在将部分树干错分为枝叶(图4b-1)。
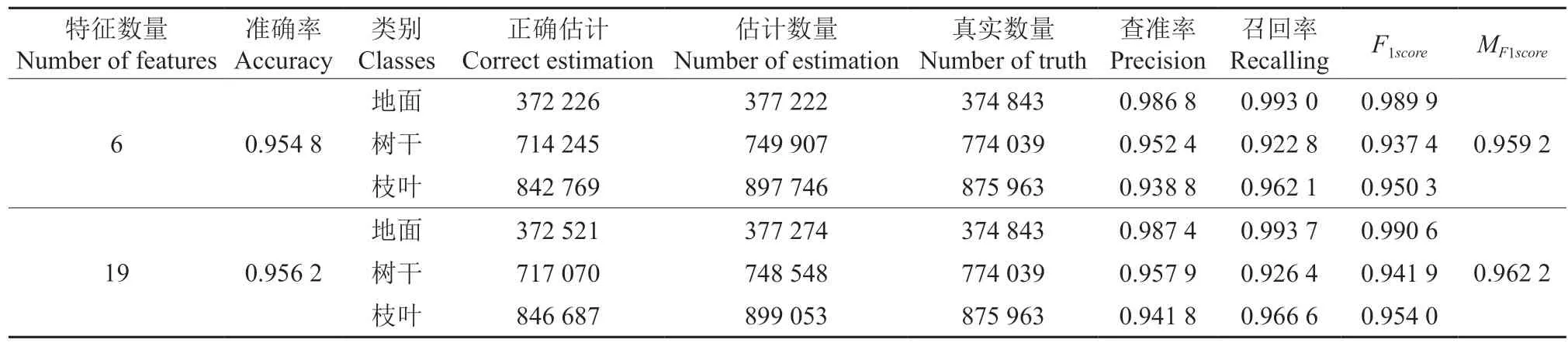
表3 不同特征分类统计量Table 3 Thelabelingstatisticsofdifferentfeatures
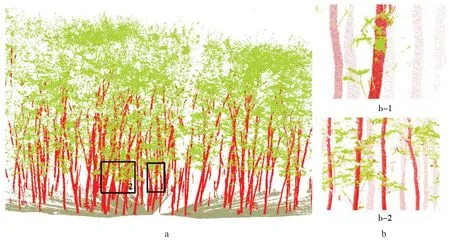
图4 xgboost 测试集分类结果Fig.4 The xgboost’s test sets result
3 结论与讨论
本研究先通过逐点搜索点云定近邻点集计算19个点特征,然后使用该特征训练xgboost 分类器并依据分类器表现得到特征对模型的重要性。获得特征重要性之后将特征按重要性做降序排列,并按此序列依次增加特征训练xgboost,最终在保证分类器的性能情况下保留适当数量的特征以达到特征选择的目的。现得结论如下:
1)特征选择策略可有效提高特征计算效率。由表2 易知特征的计算效率与点云的数量呈正相关变化,在同一数据集中计算6个特征均约占计算19个特征用时的一半,所以当点云数量一定时,减少特征维度可明显提高了特征计算的效率。
2)在保证分类器性能的前提下,特征选择策略可以避免特征构造的盲目性。常规的点云分类任务多依据经验构造较多的特征训练分类器,在特征选择之前本研究引入了19个经验特征,依据这些特征训练分类器的测试准确率为0.956 2。本研究依据xgboost 表现选择了6个重要性较高的训练分类器的测试准确率为0.954 8。相较于使用19个特征分类器性能仅降低了0.001 4,所以在忽略该精度影响的情况下,在本研究的点云分类任务中仅计算特征选择的6个特征即可。
由上述分析易知使用特征选择技术可有效提高特征计算效率。在不影响分类器性能的前提下,本研究仅使用6 维特征就可代替19 维经验特征。在前述的研究中构造的点云特征维度介于16~144 之间,其中以Hackel 等[11]研究为最,特征维度达到144 维,这144 维特征由9个分割尺度的16 维经验特征构成。在大数据集点云分类任务中每个点使用144 维特征表示需要消耗较多内存,若在构造特征之前引入特征选择技术则可有效降低特征维度,使用较低维度的特征在节约算法运算内存的同时可有效提高特征计算效率。
本研究错分点云大多来自树干与枝叶这两个类别,由于部分树干与枝叶点云在空间上分布较近,当遍历点云搜索近邻时容易混淆部分空间上较近的枝叶与树干点云,从而使该部分点云的特征不稳定,最终导致分类器产生错误估计。所以本研究的后续工作准备从改进点云搜索方式或构造更具表征能力的特征方面着手,进一步开展点云分类研究。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
诗歌月刊(2022年1期)2022-01-28
福州大学学报(自然科学版)(2022年1期)2022-01-21
计算机系统应用(2021年2期)2021-02-23
当代陕西(2020年17期)2020-10-28
电子技术与软件工程(2019年18期)2019-11-18
好孩子画报(2018年6期)2018-07-31
小型微型计算机系统(2018年5期)2018-07-04
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年3期)2017-05-24
