
类图像处理面向大数据XSS入侵智能检测研究
2020-03-11 12:51张海军陈映辉
计算机应用与软件 2020年2期
张海军 陈映辉
1(嘉应学院计算机学院 广东 梅州 514015)2(嘉应学院数学学院 广东 梅州 514015)
0 引 言
随着互联网技术的大力发展以及网络用户的大量增加,产生了大量蕴含较高价值的大数据。从服务器的交易系统和业务系统数据库的数据到各个终端的数据,如各种流水操作、网购记录、网络浏览历史、播放的音视频、微博数据、微信数据等,因而基于WEB应用的攻击逐渐成为主要攻击,如跨站脚本攻击(Cross-Site Scripting,XSS)[1-2],表现为:① 网络钓鱼,盗取用户的账号和密码;② 盗取用户Cookie数据,获取用户隐私,或者利用用户身份进一步进行操作;③ 劫持浏览器会话,从而冒充用户执行任意操作,如非法转账、强制发表博客;④ 强制弹出页面广告,刷流量;⑤ 进行恶意操作,如纂改页面信息、删除文章、传播跨站蠕虫脚本、网挂木马;⑥ 进行基于大量的客户端攻击,如DDoS攻击;⑦ 联合其他漏洞,如CSRF漏洞;⑧ 进一步渗透网站等。传统的计算机病毒检测方法主要是利用病毒特征库中的已有特征,通过提取相应样本的特征,用病毒库搜索比较是否存在相匹配的特征来确定病毒。这种方法主要是基于已知的病毒检测,难以检测新出现的病毒,特别是对于变形病毒更加无能为力,而且效率低,特别是对于大数据。当前安全防护措施也已经由过去的“80%防护+20%检测及响应”变成了“20%防护+80%检测及响应”。深度学习在语音、图像、自然语言处理等方面都展现出了比传统机器学习方法更强的学习能力,取得了非常好的效果,特别是对于大数据。为此,本文进行类图像处理面向大数据XSS入侵智能检测研究。
1 大数据处理和建模
Web异常检测本质上就是基于日志文本的分析,即对访问流量语料库进行数值化的特征提取和分析,如:URL参数个数、均值和方差、字符分布和访问频率等。当前基于安全防护的样本数据比较缺乏,标注好标签的样本少之又少,因而需要进行数据处理和建模,包括数据获取、数据预处理(数据清洗、数据抽样、特征提取)、数值分析、行为决策等。
在计算机里,任何信息都是以0和1二进制序列表示,如所有的字符(包括字母、汉字、英语单词等语言文字)都有一个编码,而图像也是以数字化信息表示。因而本文把大数据日志文本转换成数值数据并以矩阵表示,从而利用图像处理的方法进行数据处理和分析。即将攻击报文转换成类似于图像数据即像素的矩阵,也将字符串序列样本转换成具有相应维度值的向量,如图1所示,进一步可求矩阵相关性、维数约减、聚类和主元素分析法PCA等运算,然后利用人工智能方法进行用户行为分析、网络流量分析和欺诈检测等。

图1 类图像处理大数据日志文本向量化原理图
1.1 语料大数据获取
用于实验的数据包括两类大数据:① 正样本大数据(带有攻击行为),利用爬虫工具从网站http://xssed.com/爬取获得,由Payload数据组成;② 负样本大数据(正常网络请求),为了体现特殊性和普遍性,共收集了两份数据,一份来自本单位网络中心从去年5月份到12月份的访问日志大数据,另一份是从各网络平台通过网络爬虫获得,它们都是未处理的语料大数据。
1.2 大数据处理
利用基于神经网络的词向量化(Word2vec)[3-4]工具——连续词袋模型(Continous Bag of Words Model,CBOW)实现大数据语料处理,进行数据切割、分词、词向量化,把独热编码(One-hot Encoded)的词向量映射为分布式形式的词向量,降低了维数,减少了稀疏性,同时通过求向量间的欧氏距离或夹角余弦值可以得出任何词间的关联度。具体处理过程如下:
(1) 首先,遍历数据集,把数字都用“0”替换,把http/、HTTP/、https/、HTTPS用“http://”替换;其次,按照html标签、JavaScript函数体、http://和参数规则进行分词;基于日记文档构建词汇表,再对单词进行独热编码。
(2) 构建基于神经网络的词向量化模型结构[5-9],包括输入层、投射层和输出层,利用输入样本,训练模型,获得分布式词向量,相应模型及训练过程如图2所示。
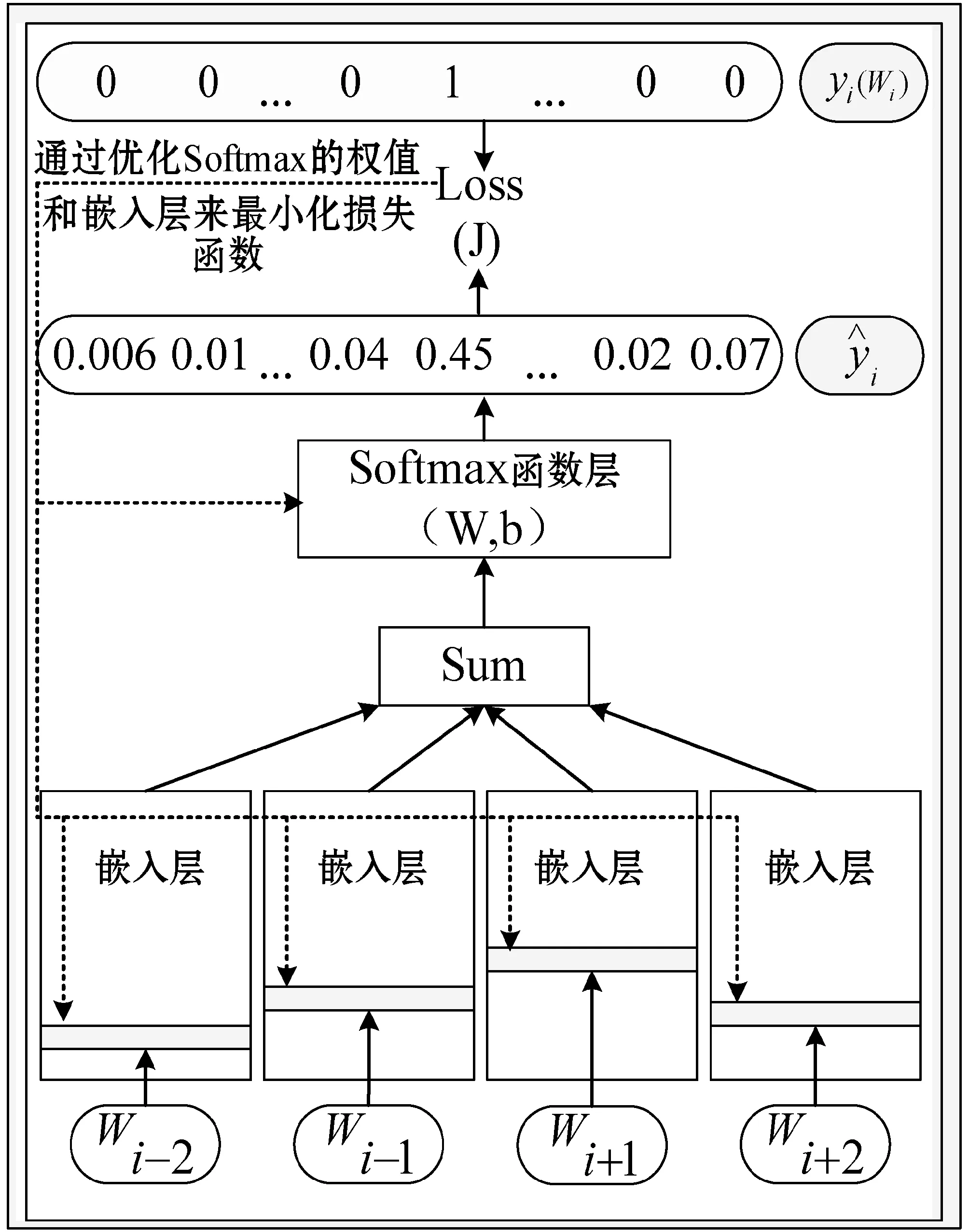
图2 CBOW模型及训练过程图
(3) 统计正样本词集,用词频最高的3 000个词构成词库,其他标记为“COM”,本文设定分布式特征向量为128维度,当前词与预测词最大窗口距离为5,64个噪声词,进行5次迭代。
因为每条数据所占字符长度各不相同,以所占字符长度最多为标准,不足则以-1填充,在为数据集设计标签时,使用One-Hot编码,正样本标签即属于攻击样本的以1表示,负样本标签即正常网络请求以0表示。
通过以上方法处理,共获得正样本数据集40 637条,负样本数据集分别为105 912条和200 129条,它们数量大、计算复杂性高[10-13]。为了提高训练效果,将正样本集和两类负样本集分别进行合并,随机划分为训练集和测试集,数量比为7∶3。
2 算法设计
2.1 词向量化算法设计
利用CBOW实现词向量,即已知上下文词语预测当前词语出现的概率。为此,需要最大化对数似然函数:
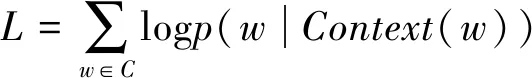
(1)
式中:w表示语料库C中的词,这可以看作多分类问题,而多分类是由二分类组合而成,因而可以使用Hierarchical Softmax方法。先计算w的条件概率,公式如下:
(2)
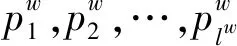
(3)
由于d只取0和1,所以式(3)可以以指数的形式表示:
(4)
将式(4)代入式(1)可得:

(5)
对式(5)中的每一项可以记为:
(6)

(7)
式中:σ(x)为sigmoid函数。所以σ′(x)=σ(x)[1-σ(x)],代入式(7)可得:
(8)
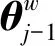
(9)

(10)
由于Xw是上下文的词向量和,在处理时把整个更新值应用到上下文每个单词的词向量上去:
(11)
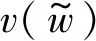
基于上面的主要算法建立模型,把原始语料作为输入,可以得到词向量。
2.2 深度神经网络算法设计
深度神经网络相对于传统的神经网络或其他ML算法显示出了优异的性能,特别是对于大数据,具有更高的识别率、更强鲁棒性、更好的泛化性等优点[14-22]。为此,设计深度神经网络算法来实现安全防护检测,通过大数据训练模型。训练时的均方误差可以表示为:
(12)
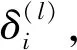
(13)
接下来可求l=nl-1,nl-2,…,2时,各个层的单元的残差,如l=nl-1层的各单元的残差为:

(14)
式中:W表示权值,b表示偏置,(x,y)表示训练样本,hW,b(x)表示最后的输出量,f(·)表示激活函数。将式中的nl-1与nl的关系替换为l与l+1的关系,就可以得到:
(15)
利用以上公式可以求出每个单元的残差,从而进一步求出基于权值等变量的偏导数:
(16)
由此可以得到权值的改变过程:
(17)
偏置项的改变过程为:
(18)
由此可以实现DNN的学习和训练。
3 实 验
3.1 实验数据
第2节实现了语料大数据的获取、处理、建模、分词和词向量化处理。共获得正样本数据集40 637条,负样本数据集分别为105 912条和200 129条,数量大、计算复杂性高。为了提高训练效果,将两类负样本集分别同正样本集进行合并,都以7∶3的比例随机划分为训练集和测试集,记为第Ⅰ和第Ⅱ大数据集。
3.2 实验结果与分析
基于DNN,分别构建3、4、5、6、7层等深度,设计不同的超参数,包括样本块大小、学习率以及各层包含的不同神经元数等,利用词向量大数据集样本进行训练和测试实验。为了检验系统的稳定性,对每类数据分别进行了20次实验,结果如下:
(1) 基于各深层DNN设计不同的超参数,对第Ⅰ类大数据集进行20次实验得到的识别率如表1所示。可以看出,最低识别率为0.983 9,最高识别率为0.995 5,识别率随着训练次数的增加而增加,最后趋于稳定。曲线展示如图3所示。
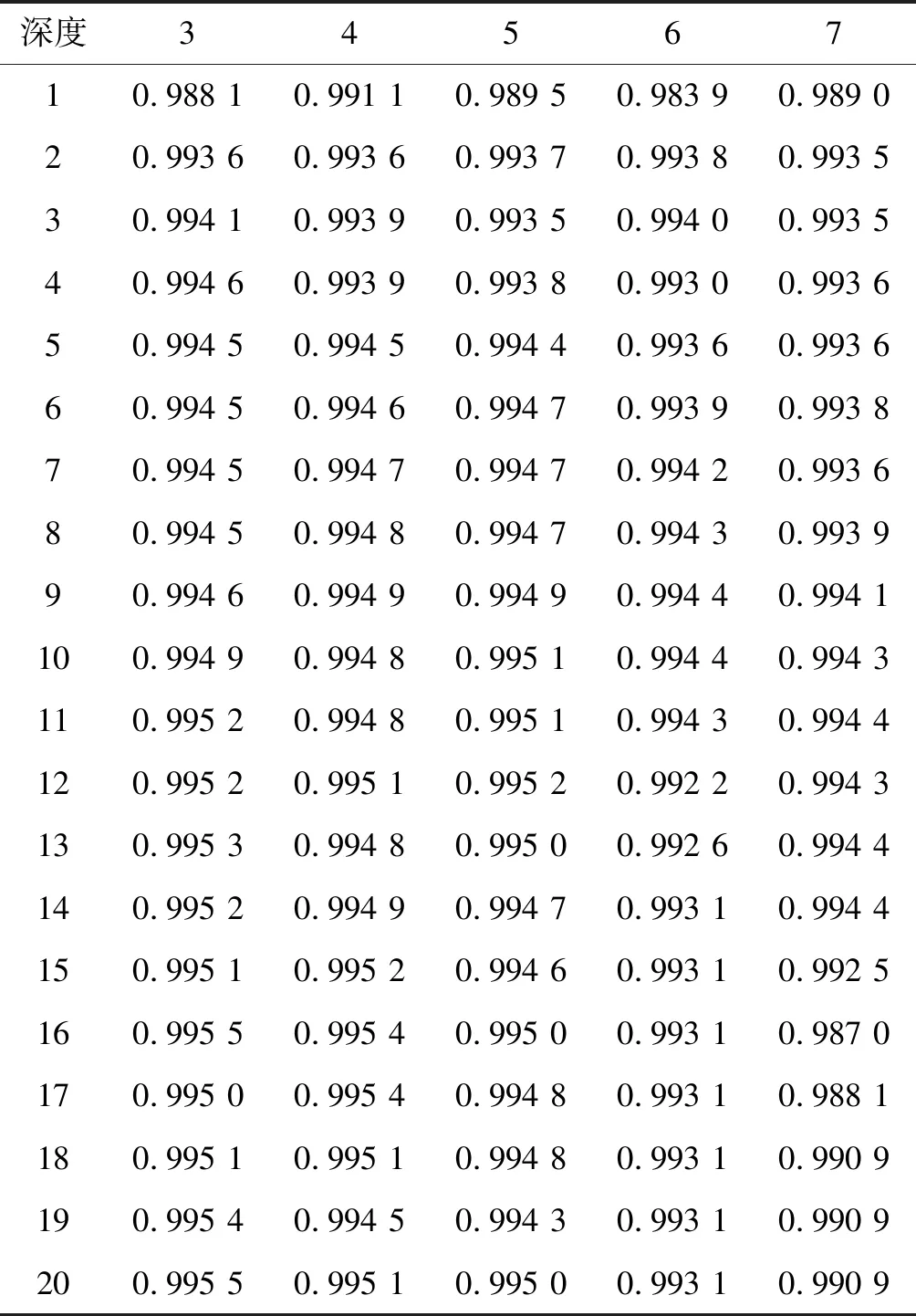
表1 各深层DNNs对第Ⅰ类大数据集进行20次实验 得到的识别率
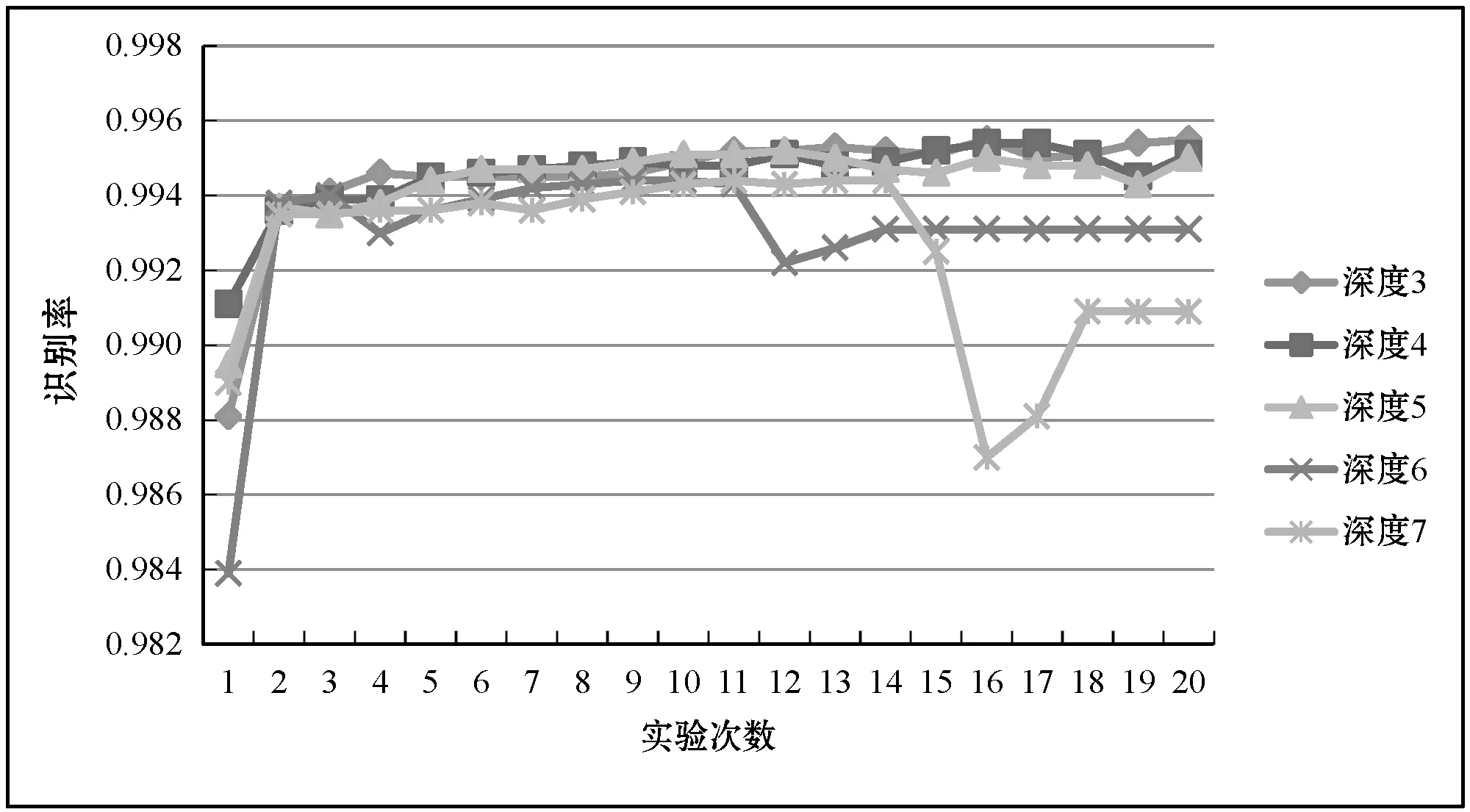
图3 对第Ⅰ类大数据集进行20次实验时 得到的识别率曲线图
(2) 基于各深层DNN设计不同的超参数,对第Ⅱ类大数据集进行20次实验得到的识别率如表2所示。可以看出,最低识别率为0.986 4,最高识别率为0.999 0,识别率随着训练次数的增加而增加,最后也趋于稳定。曲线展示如图4所示。
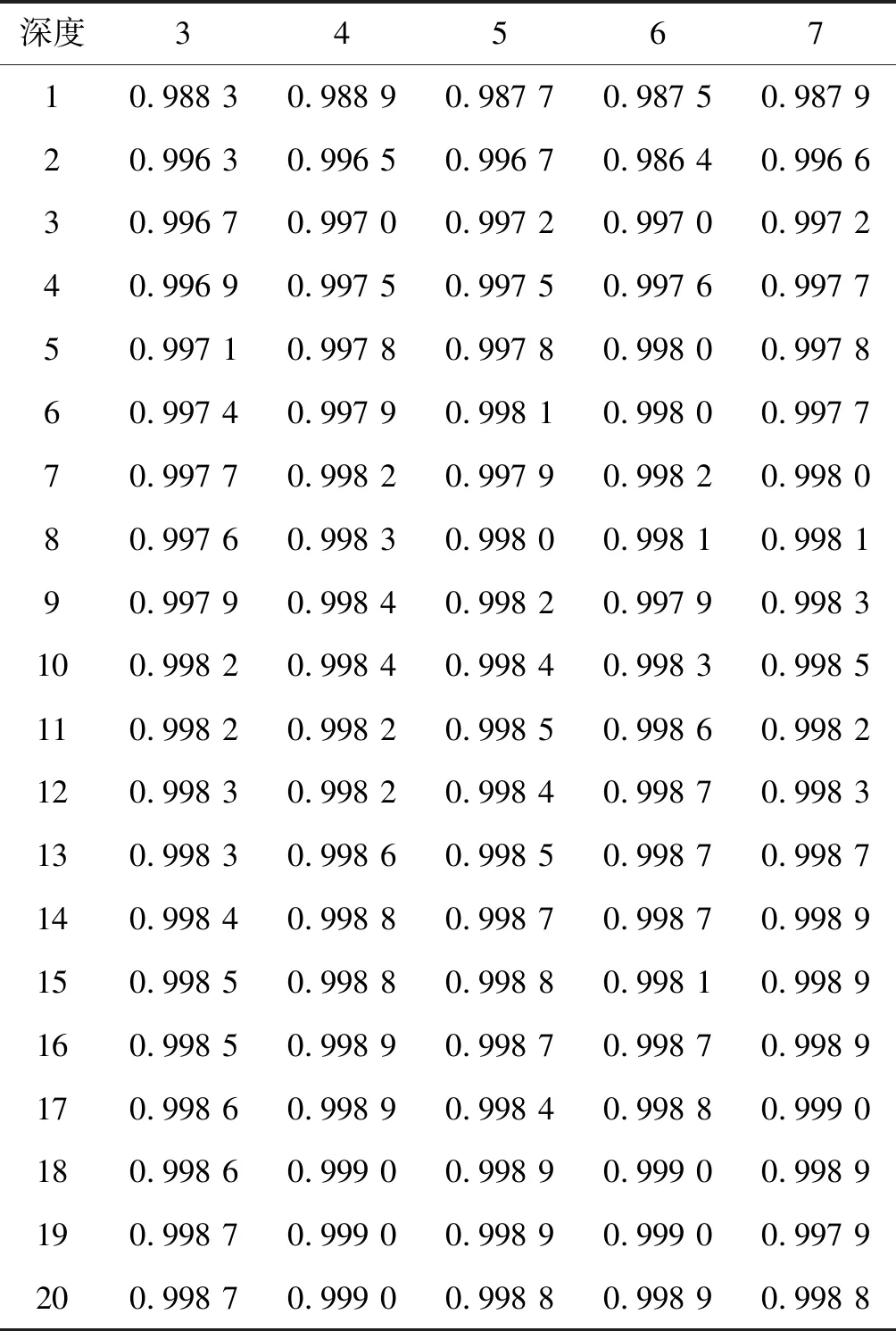
表2 各深层DNNs对第Ⅱ类大数据集进行20次 实验时得到的识别率
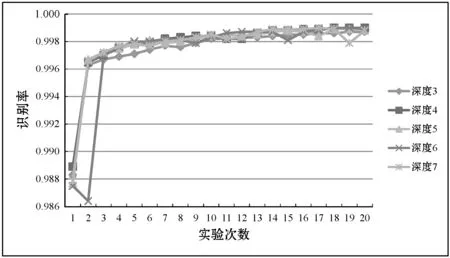
图4 对第Ⅱ类大数据集进行20次实验时 得到的识别率曲线图
另外,通过实验,得到各深层DNN对第Ⅰ类大数据集的平均识别率为99.44%左右,方差为0.000 002左右,标准差为0.001 589左右,如表3所示。
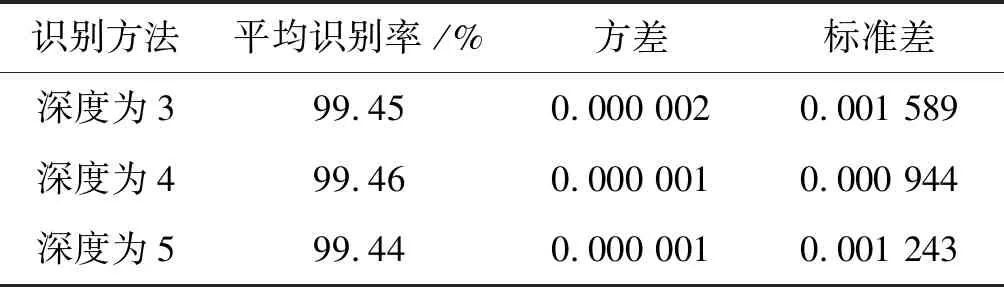
表3 各深层DNNs对第Ⅰ类大数据集进行20次实验时 得到的平均识别率、方差和标准差
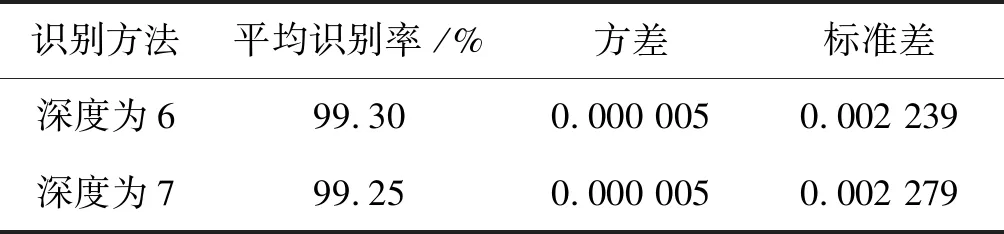
续表3
同样,通过实验得到各深层DNN对第Ⅱ类大数据集的平均识别率为99.77%左右,方差为0.000 006左右,标准差为0.002 427左右,如表4所示。
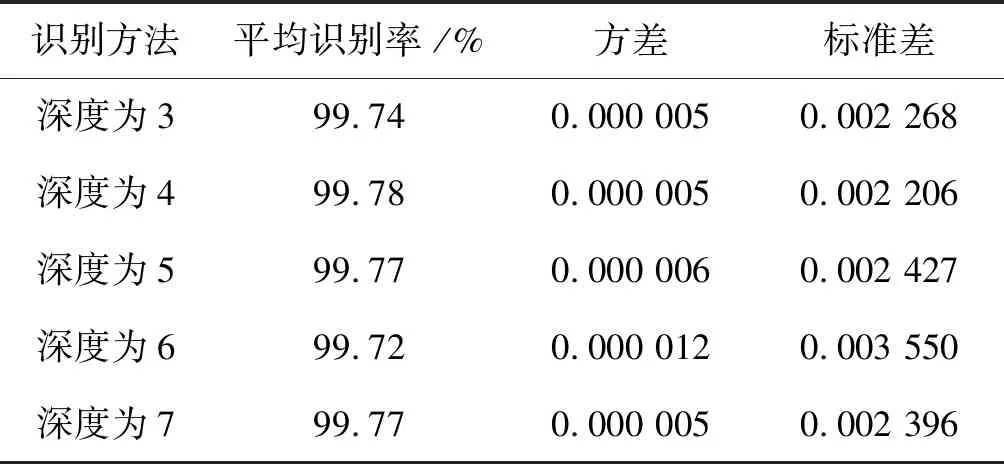
表4 各深层DNNs对第Ⅱ类大数据集进行20次实验时 得到的平均识别率、方差和标准差
对于第Ⅰ和Ⅱ类大数据集的识别率均值条形图展示如图5所示,标准差条形图展示如图6所示。
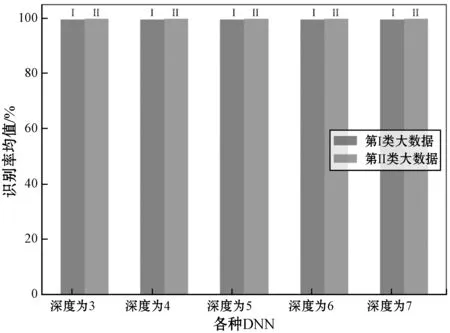
图5 对于第Ⅰ和Ⅱ类大数据集的识别率均值条形图

图6 对于第Ⅰ和Ⅱ类大数据集的标准差条形图
为了描述系统的识别变化过程,得到识别率变化过程曲线如图7所示,可以看出识别率随着训练的进行不断增加并趋于稳定。
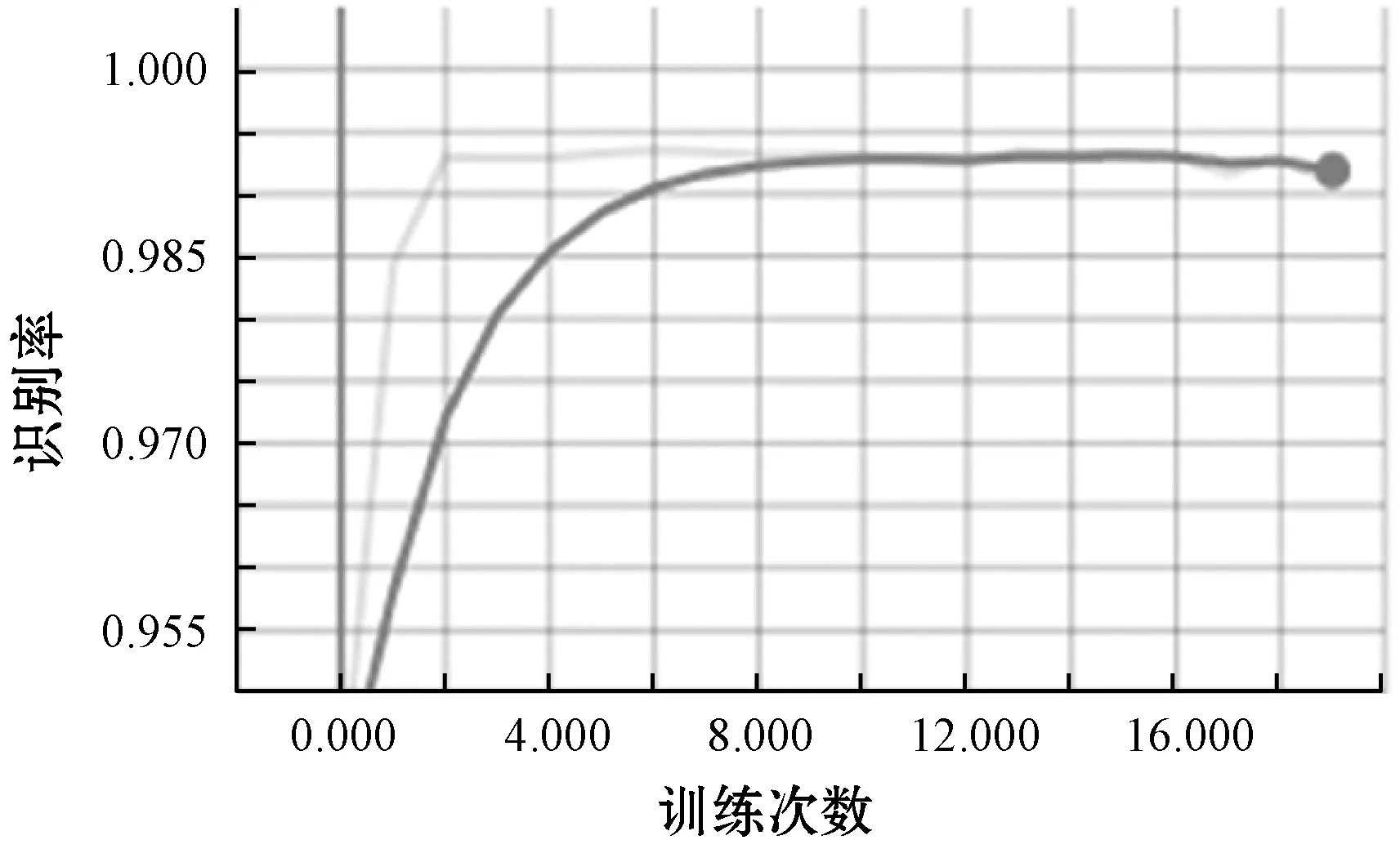
图7 识别率变化曲线图
同样,得到平均绝对误差变化过程曲线,如图8所示,可以看出随着训练的进行,平均绝度误差不断减小并趋于最小的稳定值,这同图7中的识别率的变化是一致的。
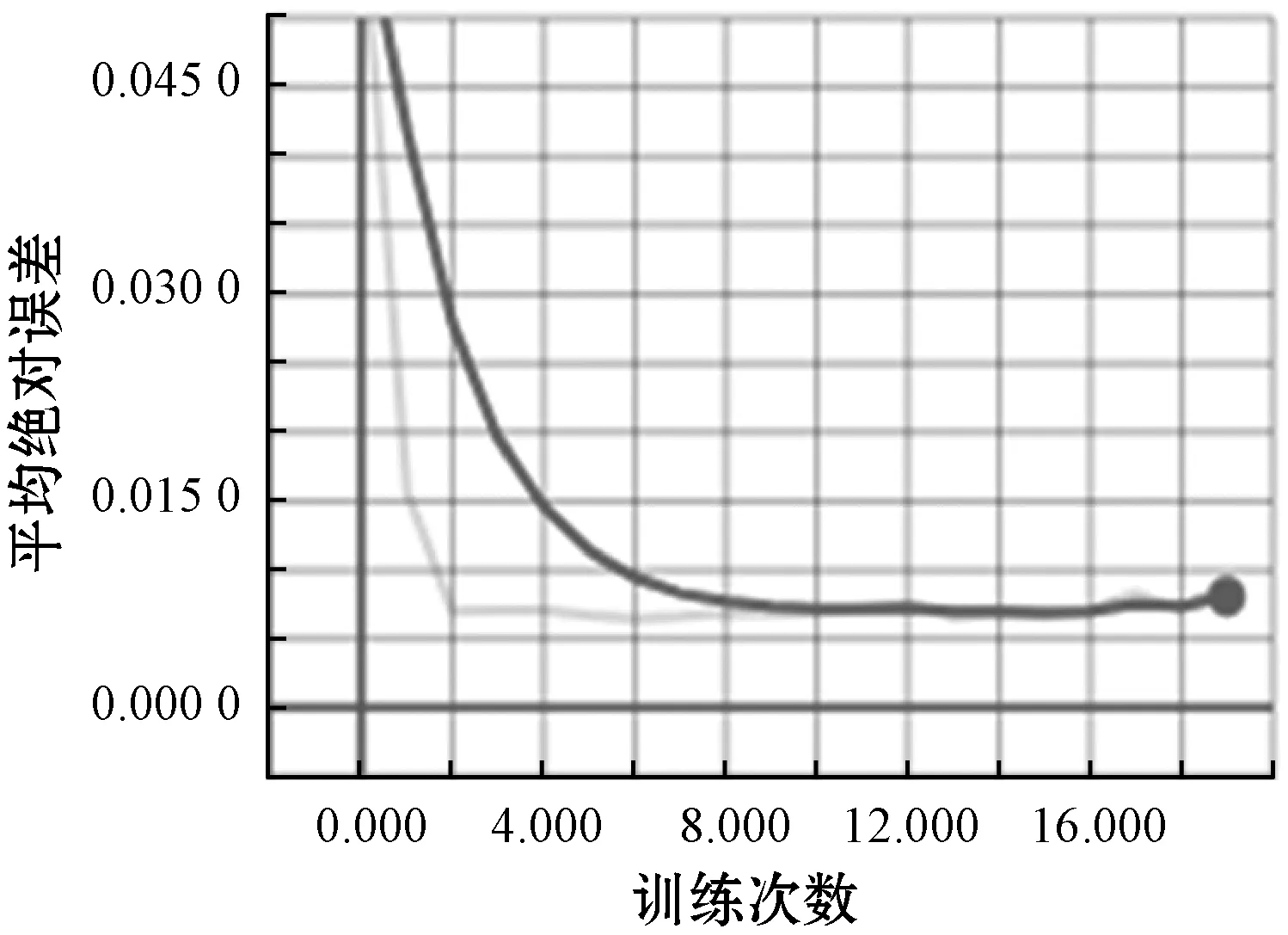
图8 平均绝对误差变化曲线图
4 结 语
本文利用类图像处理方法对访问流量语料库大数据进行词向量化处理,结合提出的智能算法实现了面向大数据XSS入侵智能检测。首先,基于流量语料数据的非结构化特点,巧妙地利用类图像处理方法进行数据获取、清洗、抽样及特征提取等预处理;其次,设计基于神经网络的算法实现了语料大数据的词向量化;然后,通过理论分析和验证提出了多种不同的深层神经网络智能检测算法;最后,进行反复的实验,设计不同的超参数,取得了最大识别率、最低识别率、识别率均值、方差、标准差、识别率变化过程曲线图和平均绝对误差变化过程曲线图等结果,证明了本文研究的类图像处理面向大数据XSS入侵智能检测系统具有识别率高,稳定性好,总体性能优良等优点。为了更好地处理大数据,未来将继续探讨基于云计算集群并行化的入侵智能检测。
猜你喜欢
农业工程学报(2022年7期)2022-07-09
电脑知识与技术(2022年9期)2022-05-10
电脑知识与技术(2022年9期)2022-05-10
计算技术与自动化(2022年1期)2022-04-15
现代计算机(2021年33期)2022-01-21
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
