
基于序列标注的漏洞信息结构化抽取方法
2020-03-11 12:51陈钧衍陶非凡
计算机应用与软件 2020年2期
陈钧衍 陶非凡 张 源
1(复旦大学软件学院 上海 201203)2(上海通用识别技术研究所 上海 201114)
0 引 言
互联网的影响渗入现代生活的方方面面,运行在个人电脑与智能移动设备上的各类软件在其中扮演了重要的角色。这些软件在为现代生活提供了各种便利的同时,也成为了恶意攻击者的跳板。软件开发过程中的错误实现会导致安全漏洞,攻击者可以利用它们通过互联网窃取或篡改受害者的设备上的数据。
知名软件当中的已知安全漏洞在发布时会得到一个通用漏洞披露(Common Vulnerabilities and Exposures,CVE)号作为统一的称呼和引用方式。CVE数据库中除了CVE号和漏洞本身的描述,还包含漏洞的严重程度、攻击类型、目标平台、软件版本和攻击方式等信息。尽管其攻击原理已经被公布,但不够谨慎的开发者未必能及时为软件与设备部署安全补丁。与此同时,攻击者也常常利用已知漏洞的攻击原理来攻击新的软件与系统。为了深入理解已知漏洞的工作机制与原理,研究者常需要对它们进行分析与测试。为此,研究者首先需要在CVE数据库中筛选出满足条件的漏洞。其筛选条件往往是受影响软件、攻击效果等关键信息。在确定了待研究漏洞之后,还需要分析其主要特征,得到受影响软件、攻击方式、漏洞触发条件等信息。这样才能正确地测试与利用漏洞。
与研究者的需求相悖的是,现有的CVE数据库相当不完善。一个CVE的核心是它的描述文本,其关键信息以非结构化的形式包含其中,研究者无法简单地利用。此外,虽然目前的CVE数据库中已经附带了几项结构化的辅助信息,如CPE、CVSS等,然而有调研[2]指出:已有的辅助信息无法覆盖到所有CVE,且内容与形式也缺乏一定之规,甚至常有错漏。因此已有的辅助信息亦无法作为足够可靠的信息来源。
在CVE的数量有限时,安全研究者尚可人工筛查数据库给出的结果。然而随着互联网应用和用户数量的快速增长,网络安全问题受到了前所未有的重视。如图 1所示,从2017年开始,每年新增的CVE数量超过一万个,出现了一波爆发式的增长。效率较低的手工分析与不够精准的索引已经无法满足安全研究的需求。为了更好地分析研究CVE,本文将描述文本转换成结构化的形式,研究者能够凭借结构化的信息更好地分析与索引CVE数据。
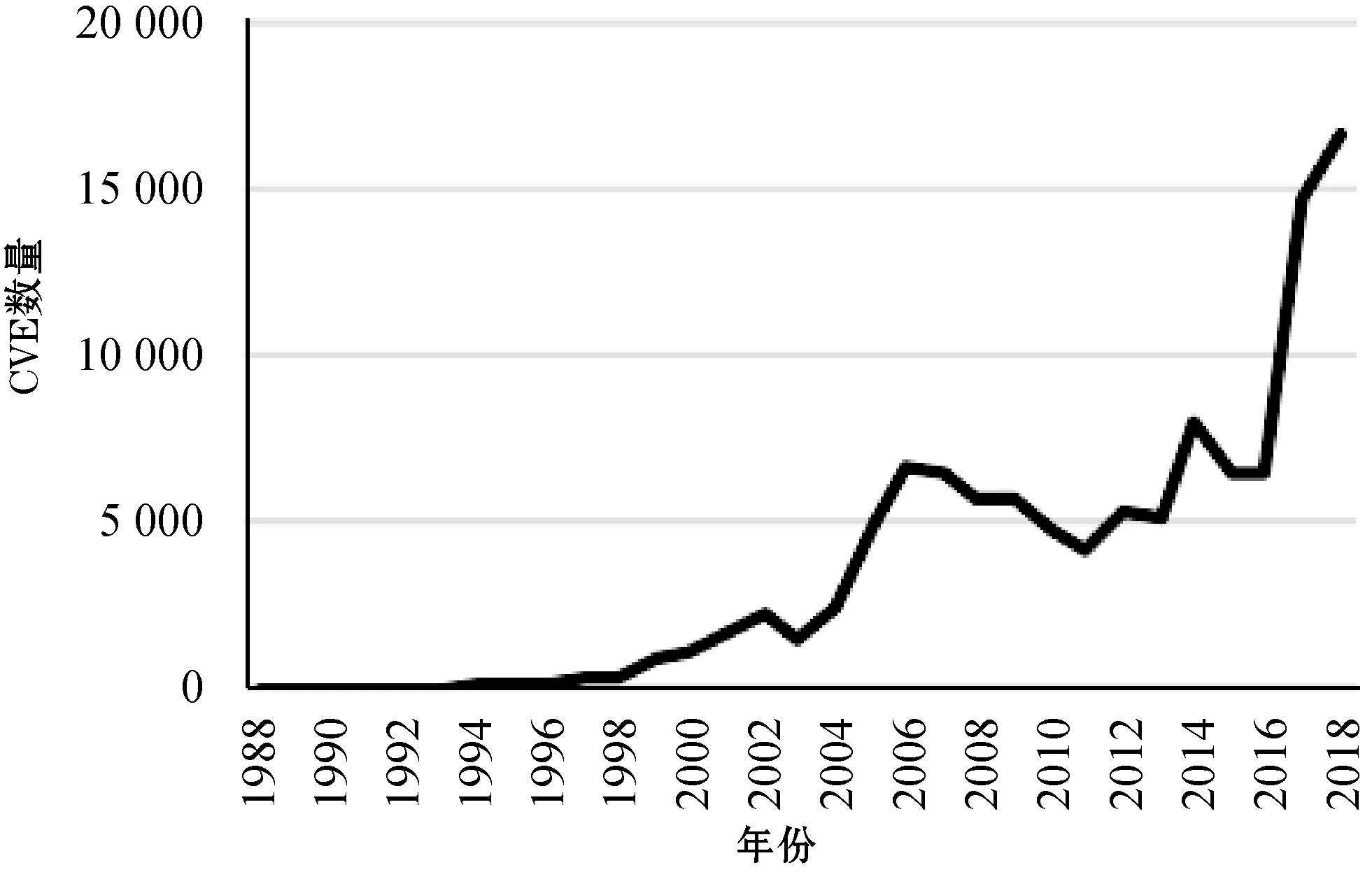
图1 历年CVE数量变化趋势
本文使用信息抽取技术从CVE的漏洞描述文本当中抽取结构化的信息。为此,本文首先对已有的大量CVE描述文本进行了研究,总结出漏洞描述的七个核心要素。之后,为了自动化地从描述文本当中提取出漏洞要素,本文引入了自然语言处理的技术。然而此类描述文本往往包含大量的安全领域专有词汇,已有的成熟句法处理模型并不能在漏洞信息抽取问题上给出优质的分析结果。因此本文选择引入机器学习的方法,训练领域专用的词向量和信息抽取模型。
在考察了机器学习与自然语言处理领域的新兴成果之后[6,8],本文将信息提取的问题转换为一个序列标注模型:将漏洞描述的文本视为一个序列,以单词为最小输入单元。而模型为每一个输入的单词输出一个标签,这个标签说明了该单词所属的漏洞要素。本文设计神经网络并在数据集上训练整个标注过程,最终实现对漏洞要素信息的结构化提取。
本文的主要贡献有:
(1) 提出了漏洞信息的结构化表示方案,以统一的形式对漏洞进行描述。
(2) 设计了基于序列标注的方案,解决了从非结构化的CVE描述文本中抽取结构化信息的问题。
(3) 构造数据集,训练模型实现上述方案,并设计实验验证了该模型的信息抽取效果。
1 相关工作
目前并没有直接从CVE当中抽取结构化的信息的工作。部分工作与本文的目标近似,试图补充CVE的结构化信息。而另一些工作与我们一样,在安全领域的文本上应用了机器学习与自然语言处理的技术。本文将对几种不同类型的工作分别进行讲解。
1.1 CVE信息的分析与利用
部分研究者试图从CVE构建攻击图(Attack Graph)[1],以此辅助安全系统的分析与建模。文中指出,已有的CVE数据库并不能提供形式统一的结构化信息。因此他们尝试从CVE的文本描述中提取信息,并以此完成攻击图的构建。但其信息提取策略仍然依赖于已有的CVSS、CPE、OVAL等辅助信息,而没有充分利用非结构化的描述文本。文献[3]则将机器学习技术引入到CVE文本信息提取的领域,使用卷积神经网络从CVE文本直接生成CVSS数据。然而CVSS的格式仍然较为简单,其使用的技术不足以支持进一步的复杂结构化信息提取。
1.2 安全文本分析
部分威胁情报的工作[4-5]使用已有的成熟NLP句法依赖模型[10]处理安全文本。他们尝试从威胁指标(Indicators of Compromise,IoC)与网络威胁情报(Cyber Threat Intelligence,CTI)的自然语言文本当中提取信息。而Semfuzz[7]也使用了相似的处理手段,其分析目标是CVE的描述文本。但他们的技术仍然受限于已有的通用模型,在遇见安全领域的专有名词时,可能给出错误的解析结果。Igen[9]放弃了通用语言模型,转而使用卷积神经网络来从IoC中提取域名、IP一类的信息。不过它处理的仍然是特征较为明显且形式较为单一的内容,无法适用于本文所面临的问题。
现有工作所提出的方案都存在各自的缺陷,接下来本文将阐述所设计的方案如何解决这些问题。
2 方案概述
2.1 漏洞信息结构化表征
对CVE和漏洞本身的深入理解是结构化信息抽取方案的基础。本节将阐述对漏洞进行完备描述所必需的核心要素,以此为后续提供一个结构化的抽取模型。为此,本文调研了1999年-2017年间产生的七万余CVE,并对各类漏洞描述模式进行了总结,以覆盖所有可能情形。
对一个漏洞而言,最重要的信息是它所影响的软件与平台,以及它影响该软件的方式。漏洞影响软件的方式可以细分为漏洞类型(例如:SQL注入,缓冲区溢出)、导致漏洞产生的实现错误原因、漏洞触发环境(特定的配置或运行方式)、攻击要求(是否需要本地接入,是否需要认证)、攻击途径(例如:通过上传文件,通过定制参数)以及攻击所造成的结果。一个CVE的漏洞描述文本不一定会包含所有要素,但其中表述的重要信息总能被归于这些要素之一。
图2以两个真实的CVE文本为样例,说明七个漏洞要素的内容。本文将在此结构化方案的基础上继续阐述后续的信息抽取方案。
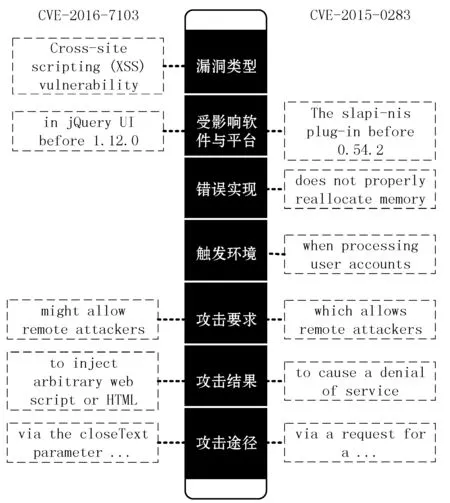
图2 漏洞结构化模型示例
2.2 漏洞信息结构化提取的挑战
从CVE的描述文本当中提取结构化信息并不容易,本文面临着若干挑战:
首先,CVE的描述文本以自然语言的形式存在,没有严格的书写规范。不同软件、不同时期或不同作者撰写的描述文本风格之间差异较大,且包含的漏洞要素种类也不一致。因而漏洞文本中的结构化信息无法简单地以固定的模板抽取。
已有工作[4-5,7]中引入了自然语言处理技术来提取安全领域的文本中的信息,然而它们仅凭借已有的通用NLP模型处理文本。无论是基于贝叶斯方法亦或者神经网络,这些模型都是从大量的普通文本训练而来,对安全领域专有名词处理能力较差。举例而言,一个漏洞的描述当中必然包含受影响的软件名称, CVE的文本中因而存在大量的软件名。当它们是一个不常见的单词(例如:Apache)时,已有模型尚且能够将其识别为一个专有名词;但当它们本身就是常用词(例如:ruby,curl)时,模型便会给出完全错误的解析结果。除此之外,描述漏洞时还常常使用一些安全领域的专有词汇(例如:stack, overflow, exploit),这些词的用法和词性与日常不同,常常会将模型的解析结果导向错误的方向。这就使得通用模型并不能在漏洞描述文本上给出较好的解析结果。
针对这些挑战,本文提出了自己的解决方案:引入机器学习的方法,在标注好的漏洞描述文本数据集的基础上训练领域专用的模型,并用此模型来完成文本信息抽取的任务。
2.3 基于序列标注的信息抽取方案
本文并非首个利用机器学习技术解析CVE描述文本的工作。曾有工作[3]尝试通过卷积神经网络来完成从文本到漏洞严重等级的映射。然而信息抽取这项任务上所需的输出并非一组简单的浮点数字,而是源文本当中的几个有意义的字符串,以及它们所对应的要素类别。这对模型的设计提出了更高的要求。为此,本文考察了自然语言处理领域的分词和实体名词识别等工作的研究成果,决定将信息抽取问题转换为一个序列标注问题。此模型接受一个文本序列作为输入,序列中的每一个元素都是一个单词。每输入一个单词,该模型都会为其给出一个标注值作为输出。以CVE-2016-7103为例,其描述文本中每个单词的标注结果如图 3所示。每一个单词得到了0~7之中的一个标注值。其中0为无用成分,而1~7分别对应漏洞描述中七种不同的要素。“Cross-site scripting XSS vulnerability”短语中的四个单词均被标注为“1”,说明模型将该短语判断为此CVE的漏洞类型。

图3 序列标注示例
3 双向LSTM+CRF序列标注网络
3.1 基于漏洞语料库的词向量构建
在讨论模型的架构细节之前,本文将先对输入数据格式转换的问题进行说明。大多数模型只能接收向量形式的输入格式,无法直接对字符串进行处理。因此,在使用模型对文本数据进行标注之前,首先需要将每个单词转换成对应的词向量。生成的词向量必须满足两个要求:具备较低维数,以避免拖慢计算效率;能够较好地在低维空间中体现出语义信息。
一种常见方式是将每个字符转换为one-hot向量,即一个长度等于字典大小,且除目标字符对应位置为1外,其他位置全为0的向量。这种编码方式的实现较为简单,然而缺陷较大,通常无法在训练中获得比较好的效果。首先是计算效率上的考虑,此方式生成的词向量过于稀疏,信息密度极低。且由于本文的模型中,字典大小等于所有可能出现的单词数量,生成的词向量长度过大,会严重拖慢计算速度。与此同时,不同的one-hot词向量之间均为正交关系,无法体现出字面不同但含义相近的词向量之间的联系。
为满足上述要求,本文采用了word2vec词嵌入模型[15]来将每个单词转换为词向量。该算法用语料库训练了一个能对上下文中的某个单词做出预测的神经网络。而训练完成的网络的隐藏层便是每个单词所对应的词向量。该算法能够在保留主体信息的同时将单词嵌入到低维空间,生成较小的词向量。同时对于语义相近的单词,其生成的词向量在空间中也会具有较近的距离。这便能充分反映单词之间的语义关联。而为了让所得词向量充分体现该单词在漏洞描述文本中的语义,本文以CVE的描述文本作为语料库来训练word2vec模型。
3.2 模型设计
为序列(文本)当中的每一项元素(单词)给出一个输出并不简单。与为每一个单词给出一个特定的输出不同,单词的词性和含义与上下文单词相关,对一个单词的标注并非孤立的过程。每个标注结果都必须依赖其上下文的内容,同时也要考虑其上下文中其他单词的标注结果。
联系上下文给出输出的一个可行选择是:带有记忆单元的循环神经网络。然而普通的循环神经网络无法很好地处理长期依赖问题。它能够正确处理序列中邻近的上下文,但却会在多次迭代之后稀释远距离信息。而在漏洞文本当中,上下文关联并非是局部的,例如句末的代词便可能直接与句首的主语相关。对此,缺乏足够区分度的循环神经网络无法很好地处理。
为了获得更好的序列标注效果,本文选择了LSTM(长短期记忆)网络[11]。相较普通的循环神经网络,LSTM网络额外包含了输入、输出与遗忘的门限控制单元,能够在训练中获得筛选重要数据的能力。经过合理训练的LSTM网络能够充分利用远距离的上下文的信息。另外,一个LSTM网络仅能将序列前部的信息单向向后传递。但在文本当中,后文的内容也会影响对前文的理解,单向的记忆不足以对此做出处理。为此,本文添加了一个结构相同、但接受相反方向输入的LSTM单元,共同构成双向的LSTM网络。这个双向的网络能综合上下文的信息,为序列中每个元素给出更准确的标注结果。
在确定了基本的网络结构后出现了另一个问题:当前的模型并未约束输出格式,也没有使用模型对标注序列本身的特征进行学习。因此,尽管神经网络在训练的过程当中确实能够学习到原始文本的特征,却时常给出对人类而言并不合理、甚至并不合法的标注结果。为了让模型学习到输出格式的分布特征,本文在双向LSTM之后添加了一层CRF[12]单元。CRF是一个基于条件概率的模型,它能够在训练过程中学习到训练集的标注结果本身的分布特点。CRF单元会在双向LSTM给出的结果基础上,推导出一个拥有极大似然概率的序列标注结果。
综合上述的内容构建而成的网络如图 4所示。
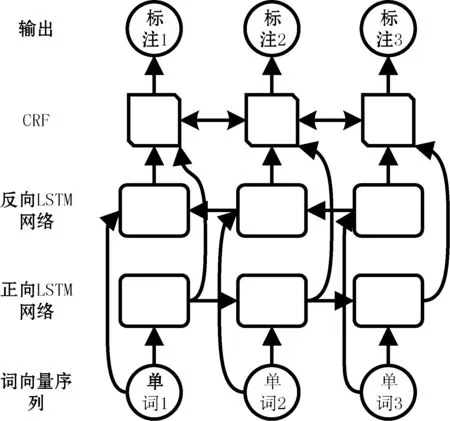
图4 LSTM+CRF神经网络结构
4 实验设计
4.1 数据集构建
在讨论实验过程之前,本文将先对各种数据的来源进行阐述。训练上述的神经网络模型需要一批已经经过标注的数据。然而按照前文所述,为标注一条数据,标注者需要在漏洞描述文本中找出可能存在的要素,并为每个单词逐一标注对应的序号。这种标注方法较为复杂,要求标注者具备漏洞安全领域的知识,难度较大,且耗时较长。为了快速获得大量的已标定数据,本文采用了人工标注与自动生成相结合的方式。
首先,两个安全专家手工为随机选择的634个CVE的文本进行完整的标注,这些文本构成了人工标注数据集。这些数据随后被平分成两部分:一半作为检测模型效果的测试数据集,而另一半则成为生成训练数据的原型数据集。原型数据集的规模较小,并不能直接用于神经网络的训练。因此,本文复用了已标注文本当中的漏洞要素,人工添加部分内容,按照一系列的模板生成了训练所用的数据集。
具体而言,本文根据用于训练的已标注文本,为漏洞结构化描述中的每个要素都生成了一个可选列表,并对此列表加以人工拓展。列表当中的每个要素都已经过人工标注。之后,本文根据已有的CVE,制定了30种不同的描述文本模板,如图5所示。
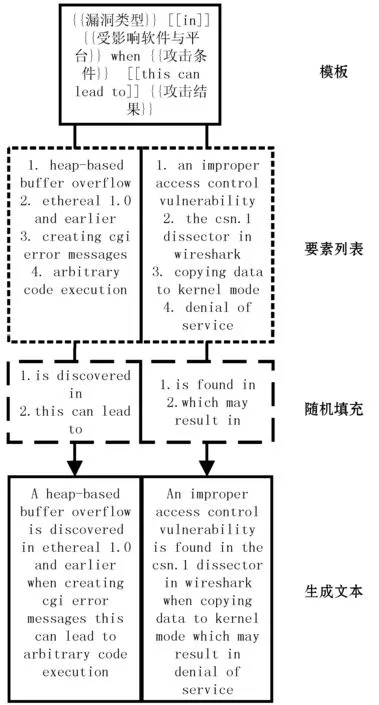
图5 模板生成示例
一个模板中有两个关键内容:待生成的描述文本的基本句式,以及其中出现的漏洞要素种类。模板当中,用双花括号包围的便是待填充的要素。数据生成时从对应类型可选要素列表中各任取一项,并整体替换对应要素。另外,为了保证生成的文本的多样性,模板中的介词和连词(用双方括号包围)也会进行随机化处理。本文针对不同句式分别设计了可选填充短语列表,在漏洞要素确定后,使用随机选取的词汇填充双方括号部分。这样就完成了文本生成的过程,本文按上述流程生成了总共十万条已标注的描述文本数据。这些数据构成了模板数据集。
4.2 模型训练
使用word2vec将输入文本转换为词向量,需要先对其进行预处理。预处理的目的是去除文本当中无特定含义,不影响实际的标注结果的功能性内容,并对一些不合法的输入内容做转换。
首先是各类停止词,例如:“the”,“is”,“at”,“which”。它们在文本中较为普遍,且通常不包含实际的含义。另外是各类标点符号,包括逗号、括号、引号等。它们会被对应的短语替换(如用LRB替换左括号,DQM替换引号)。最后一类是数字和符号,在CVE的描述文本当中常见如“3.1.3”或“4.0.1a”一类由数字字母和连接符号构成的版本号。它们的具体内容与标注结果并无关联,因此本文对其进行了统一的替换,全部用“UNKN”代替。完成预处理之后,本文使用Gensim[13],通过word2vec词嵌入算法将所有单词转换为300维的词向量。
神经网络使用Tensorflow[14]构建,该工具直接提供了封装好的LSTM和CRF单元以供使用。本文在网络中设置了3层双向、总计6个LSTM单元,其隐藏层维数均为300。其中每个LSTM单元之后都附带一层设置为0.1的dropout(丢弃层),以防止过拟合。三层双向LSTM之后,是一层学习标注特征的CRF单元。而前面的输出最终会通过一个逻辑斯蒂函数转换为最终的标注结果。本文在训练数据集上,使用交叉熵算法作为损失函数,以Adam优化算法和128的batch大小,对模型进行1 000轮训练,得到了最终的训练结果。
4.3 实验结果
上一节叙述了如何在包含十万条漏洞描述文本的模板数据集上完成对模型的训练。本节将在人工标注数据集的另一半,也就是测试数据集上验证其信息抽取的效果。
在展示结果之前,本文需先对结果评估的策略进行说明。训练过程中使用较为简单的方式计算损失函数:对比模型和测试集对每一个单词的标注结果,并据此计算交叉熵。尽管在此评估策略下,模型能给出95%以上的准确率,但该结果并不能完全肯定模型的效果。本文要达成的目标是信息抽取,而非序列标注本身,每一个单词的标注错误都可能导致整个漏洞要素含义不明。因此,本文在对模型的信息抽取效果进行自动化评估之时,仅当一个漏洞要素当中的每个单词均标注正确时,才认为得到了一个正确的结果。
然而,严格的策略会错过一些可能的正确结果。因为待提取的要素边界有时是模棱两可的。额外包含的谓语、介词或者补充说明并不会妨碍人们对这些短语的准确理解。为此,除按照严格策略下的自动化评估之外,本文还人工核查了每一项信息抽取的结果。实验结果如表 1所示。
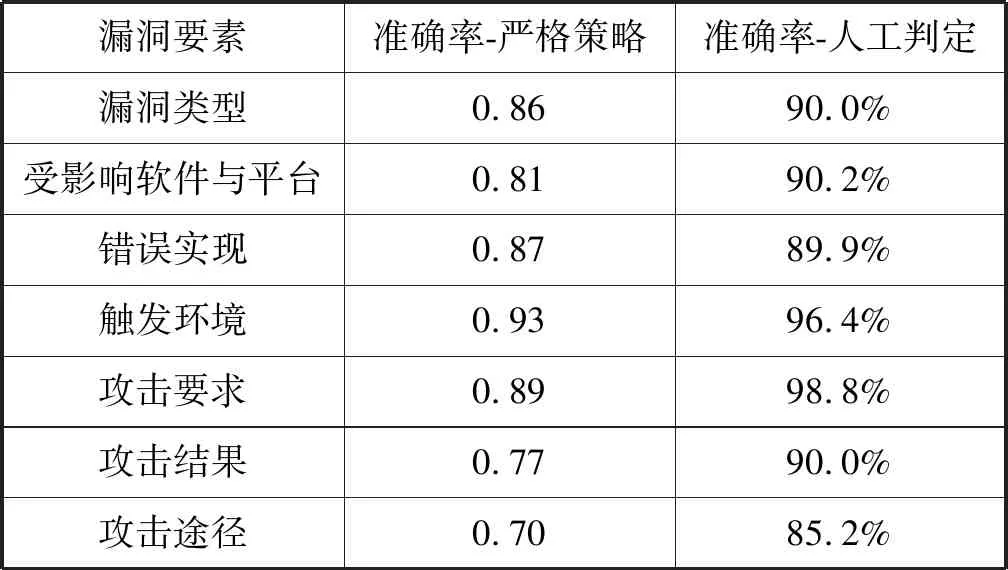
表1 CVE文本信息抽取结果
从表中可以看出,严格策略和人工判定下准确率均较高,且人工判定总是会给出更高的准确率。根据观察,这种偏差主要有以下两类情况: (1) 存在多余的不影响短语理解的介词和谓词短语;(2) 部分漏洞要素包含冗余的补充解释。总体而言,这两类情况都不会阻碍对抽取出的漏洞要素的理解。因此,本文认为训练所得的模型确实能够以较高的准确率完成漏洞要素的信息抽取任务。
5 结 语
本文针对从CVE漏洞描述中抽取结构化信息的问题,分析了面临的技术挑战,提出一个通用的漏洞信息结构化表征方案。为实现信息的结构化抽取,本文将此问题转换为一个序列标注模型,通过设计双向LSTM和CRF的多层神经网络模型实现了对CVE描述文本的结构化信息抽取。本文构建了大规模数据集来完成该神经网络的训练,并在人工标注的数据集上验证了其效果,结果表明本文提出的方案可以实现较好的漏洞要素抽取效果。本文的工作实现了将CVE漏洞描述文本进行结构化抽取的第一步。
猜你喜欢
今日农业(2022年13期)2022-09-15
新高考·高一数学(2022年3期)2022-04-28
课堂内外·好老师(2022年3期)2022-04-25
学习与科普(2022年17期)2022-04-23
云南教育·小学教师(2021年12期)2021-03-23
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
福建基础教育研究(2020年3期)2020-05-28
阅读(低年级)(2018年2期)2018-05-14
儿童时代(2016年6期)2016-09-14
高中生学习·高三版(2016年9期)2016-05-14
