
MobiWay应用中基于Hadoop的多目标多任务调度算法
2020-03-11 13:16陈家宇胡建军
计算机应用与软件 2020年2期
陈家宇 胡建军
1(郑州财经学院信息工程学院 河南 郑州 450000)2(广东财经大学信息学院 广东 广州 510320)
0 引 言
在多核处理器、虚拟化、分布式存储、宽带互联网和自动化管理等技术飞速发展的今天,云计算应运而生,并得到长足的发展和应用。凭借其能够按照用户的需求合理分配系统资源,且用户只需对所用资源付费等优点,云计算已受到IT商业巨头和专家学者的高度关注。但随着信息数据化进程的加快,利用有限的资源与成本存储及处理海量的数据成为云计算技术发展亟需解决的问题[1-2]。
目前,MapReduce框架作为云计算技术的典型,为处理海量数据提供了可行的解决方案[3]。Hadoop是MapReduce框架的开源实现平台,不仅能够高效可靠地存储处理海量数据,而且在并行化技术方面对应用开发者实现了透明处理[4],为海量数据的并行处理提供简单的编程框架。Hadoop作为一个新兴的平台,很多技术细节仍需完善,例如MapReduce调度器的工作效率不高与对异构环境适应能力差等问题。而任务调度技术是Hadoop平台的核心,其技术优劣直接影响到平台整体执行性能和系统资源利用效率的高低,因此针对调度算法的研究已有大量成果[5]。
文献[6]提出了一种基于小位置值规则的粒子群算法(Particle Swarm Optimization,PSO),基于优化传输和处理时间的想法,其主要目标是减少总处理时间。文献[7]提出了一种基于具有动态作业优先级的贪婪背包单一队列算法,不需要用户干预就能建立特定的作业优先级,系统通过穷举参数搜索来计算作业优先级,但该算法计算时间较长,不适用于多目标条件下的多任务调度。文献[8]提出了一种基于动态优先级的混合调度器(Hybrid Scheduler,HybS)算法。其目标是减少可变长度和延迟,同时保持数据局部性。算法将分数背包算法应用与处理器分配,以使动态优先级适用于不同规模、不同任务长度或等待时间的各项任务。文献[9]提出的应用特征的PaaS弹性资源管理机制能够有效减少云计算请求过程中弹性操作的次数,降低了弹性操作带来的资源开销,提高了各种系统资源的用率,但在获取请求率变化时的请求预测精度还有提升空间,以便更好地指导弹性资源分配。文献[10]提出的FIFO调度程序是第一个Hadoop调度程序,它遵循FIFO模型:实现任务队列,并通过到达顺序将任务分配给主服务器。它是基本的调度算法,并不受任何条件约束。对于节点的分配,它使用了Torque资源管理器,并在每个节点上启动两个守护进程:Hadoop MapReduce和HDFS。此调度程序的主要问题是在处理大量任务时资源拥塞。Hadoop环境中的多目标调度需要考虑MapReduce调度机制的扩展,具体体现在以下几个方面[11]:优化设置和清理任务,减少作业初始化和终止阶段的时间成本,瞬间消息传递通信机制以及用于加速对性能敏感的任务调度和执行。
针对以上问题,提出了一种适用于多任务多目标的Hadoop调度算法(MOSMT)。MOSMT算法从用户给定的服务等级协议(service-level agreement, SLA)约束中提取其服务质量偏好权重信息进行预处理,通过选择唯一的优化目标,并将其他目标参数通过权重所体现的相对重要性转化为约束条件来解决多目标问题。MOSMT算法思想总结如下:
(1) MOSMT算法同时考虑与用户、资源相关的目标函数以及约束,其中,将截止日期和预算作为算法的优化目标,将避免资源争用和集群的最佳工作量作为约束,通过优化目标与约束选取有效实现使用最小资源、最低花费处理最多数据量的目的。
(2) 通常来说,新设计调度算法难以应用于现实的Hadoop集群中,且应用过程需要耗费大量的时间和金钱。而提出的算法使用负载调度模拟器能很好地解决这一问题,因为SLS易于为调度程序设置各种相应的功能。
(3) MOSMT算法具有普适性,从而更好地适用于更多的应用场景。
为了验证算法的可行性,采用MobiWay应用程序、以不同的度量进行评估,并将MOSMT算法与FIFO[10]、Fair调度程序[11]作对比,结果表明,MOSMT算法能够实现类似的性能,并且在一些方面表现得更为优越。
1 MOSMT调度算法
1.1 算法建模
每个将要在Hadoop集群中执行的工作J都有一个已知映射任务数量Nmap和约简任务数量Nreduce[12],其数学表达为:
J={Ti|Ti∈Map∨Ti∈Reduce} |J|=N
(1)
式中:N为任务的总数,N=Nmap+Nreduce。
每个工作都有一个到达时间A、截止时间D和分配的预算Y。对于每项工作,从一开始就会明确待处理的数据量In。约简任务需要处理的数据量是未知的,但可以使用之前的工作进行估算。此外,此处将输入数据量的比率定义为r,其数学表达式为:
Out=r×In
(2)
假设每项工作都有一个所有者,它能够处理工作并且给出关于执行的等级Π。因此作业J的属性可以表示为:
Prop(J)=(A,D,B,In,r|Out=r×In,Owner)
(3)
每项工作J都会分配到特定数量的槽,其中,用于映射的槽称为SLmap,用于约简的槽称为SLreduce,同一个槽可以同时用于映射和约简[13]。因此在这种情况下,槽的总数SL≤SLmap+Slreduce。
每项任务Ti可以通过下列属性进行关联:
(1) 处理时间Pi,先验评估映射任务或约简任务,它用于计算作业的总时间:
(4)
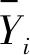
(5)
(3) 截止时间di,其由集群资源管理器为每项任务设定,用于处理任务执行间的同步问题:
(6)
(4) 权重wi,其取决于资源消耗,与处理时间Pi和分配给任务的预算Yi的乘积成比例,即:
(7)
式中:α为比例常数,如果α≤1,则任务调度和执行将服从于总预算;否则,总开销可能超过分配的预算。考虑到预算估计的性能,有:
(8)
(9)
(5) 拥有者的反馈πi,拥有者可以使用相同的值评级所有的任务,全局评级矢量Π可以表示为:
Π=[πi]Ti∈J
(10)
式中:π值可以通过计算测量任务执行的表现得到。例如,可以考虑实际执行时间coste(Ti)和任务完成度Ci来估计评级值,即:
(11)
上述定义的参数值和权重均可根据任务属性和拥有者生成任务后动态分配。因此,任务Ti的属性表示如下:
Prop(Ti)=(pi,Yi,di,fi,πi,type=map|reduce)
(12)
MOSMT解决的是多目标优化问题,则需要满足多个约束条件和尽可能多的目标。因此,MOSMT算法考虑如下多重优化问题:
(13)
此外,MOSMT模型中考虑目标与用户想要获得的内容相关,最大目标与用户反馈有关,并且用户设定截止时间和预算的值。为了实现上述约束,需要了解关于映射任务与约简任务的信息、处理节点的信息以及了解CPU内存、IO传输速率等信息[14]。
1.2 调度策略
在所提调度算法中,采用在每个步骤中的工作和资源间的最佳匹配来满足。但最理想的方式是全面了解所有集群,找到需要在特定时刻运行的所有作业与可用资源之间的最佳匹配。
集群中任务执行顺序匹配算法详见算法1。每个节点会把预测信息通过heartbeat发送给RAM,RAM把这些预测信息合并起来会产生一个全局的视图,通过该视图了解到最早结束任务的信息,把该任务对应的节点作为被选中的节点,把任务完成之后释放的资源加上节点本身剩余的资源作为节点的空余资源继续调用作业选择算法与任务选择算法,最终选择一个与节点最匹配的任务。但是,由于该节点的资源需要在最早结束任务完成之后才能把资源分配给选择出的任务,因此可以提前把选择出的任务的数据提前传输到最早结束任务所在节点,以达到任务数据本地性,减少数据传输时间,从而减少作业完成时间。
算法1集群中任务执行顺序匹配算法
输入:作业队列J,作业配置信息Conf,预测模型结果
输出:任务执行序列AssignedTask
1: Receive pieces of information through a heartbeat
2:ifnot exist free resourcethen
3:sort(NM,NMtasktimeremain)
4: selectNMof task first end time
5:endif
6:job=SelectAssignJob(J,NM)
7:length=Conf.GetMapTaskSize(job)
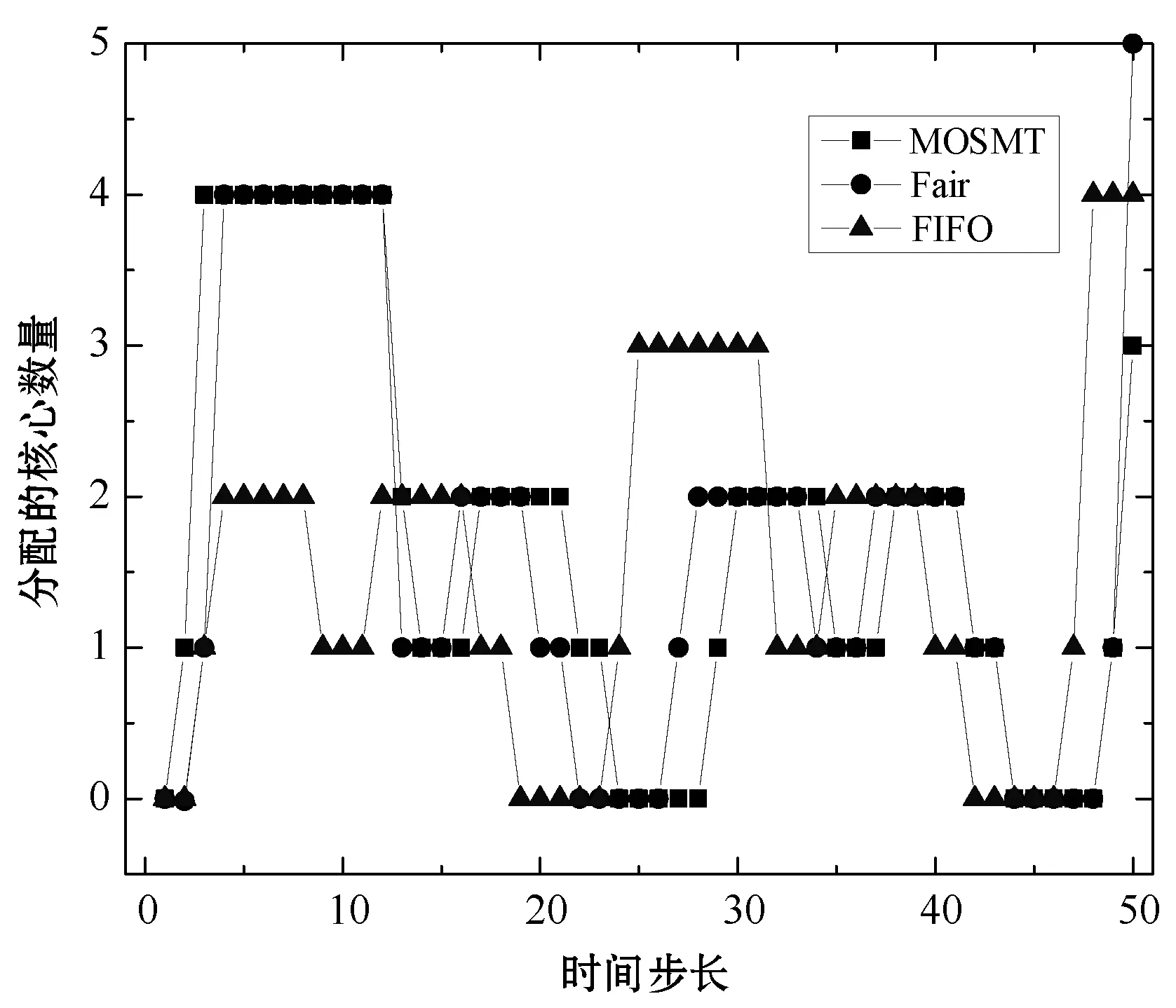
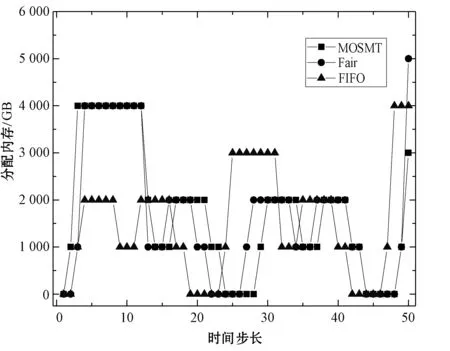
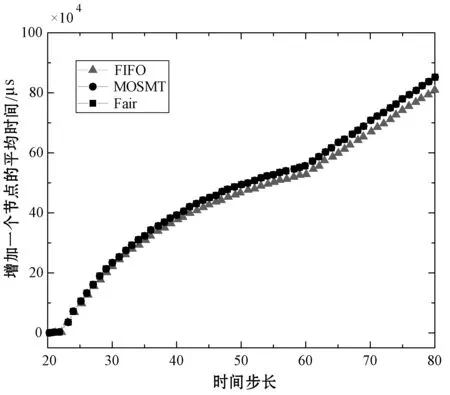
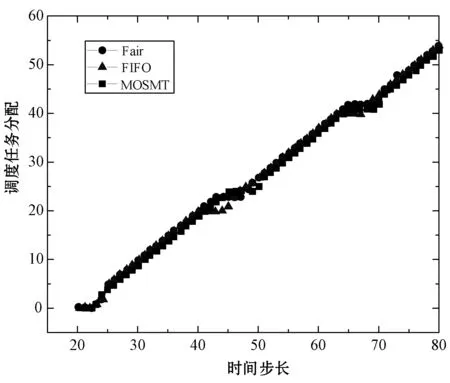
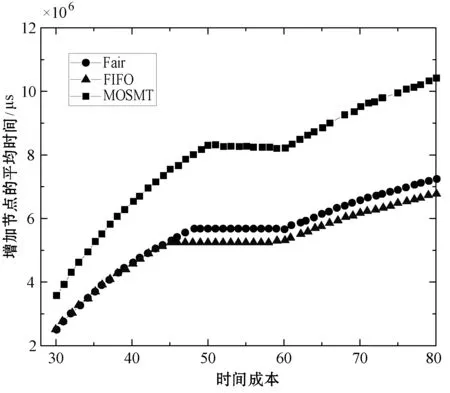
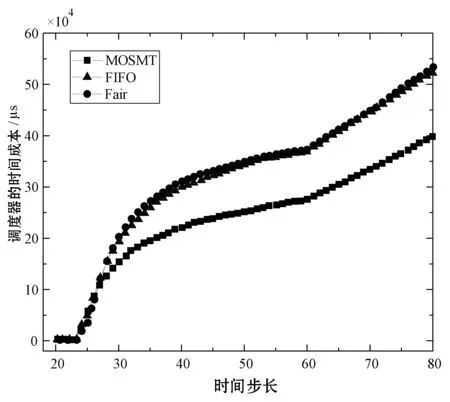
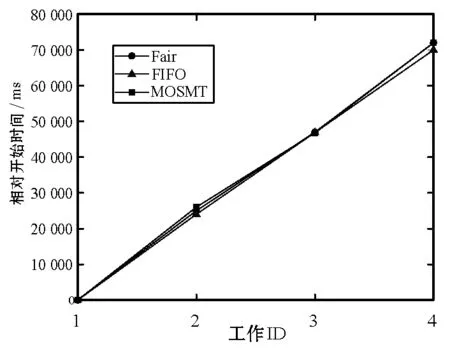
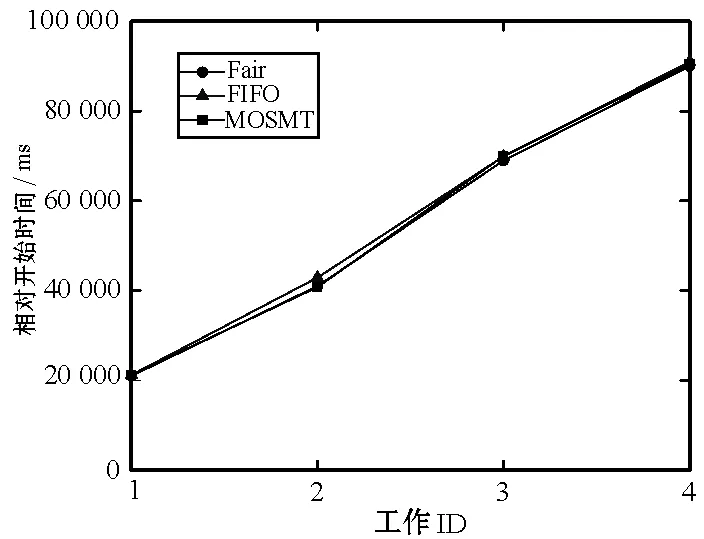
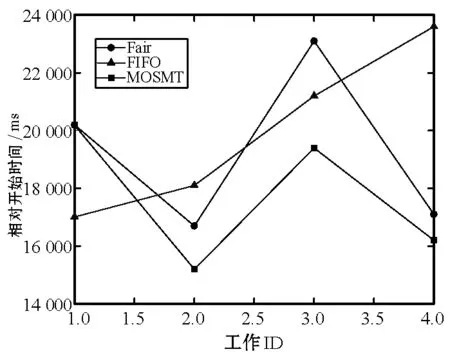
8:fori=0;i 9:score[i]=SelectAssignTask(NM,taski) 10:endfor 11:task=Maxscore(score) 12:AssignedTask.add(Task) 13:ifexist delay resourcethen 14: wait for the node to release the resource and move the date of task to NM in advance 15:endif 16:returnAssignedTask MOSMT算法遵循最佳使用作业资源策略,详见算法2。如果有足够的槽用于映射任务与约简任务,便能够在指定的预算中完成作业并且直到截止时间结束,则服务函数返回正值。算法2验证了每个服务中工作和资源之间的分配,然后通过每个服务结果的总和来判断哪种分配方式更好。 算法2MOSMT 调度算法 要求2:taskQueue一个属于工作J的所有任务Ti的队列 要求3:assignedTasks分配到每个工作者节点的任务队列 1:foreachworkernode∈Rdo 2:maxService←service(workernode) 3:F←0 4:foreachassignedTask∈workernode.assignedTasksdo 5:newAssignedTasks←workernode.assignedTasks-assignedTask 6:whiletaskQueue≠∅do 7:task←taskQueue.edq() 8:fi←weight(task) 9:newAssignedTasks←newAssignedTasks∪task 10:ifservice(newAssignedTasks)>maxServicethen 11:maxService←service(newAssignedTasks) 12:F←F+fi 13:endif 14:endwhile 15:endfor 16:workernode.assignedTasks←newAssignedTasks 17:endfor 为了计算服务结果,还需找出Slmap和Slreduce是否可由特定的资源集群提供。 将cost(map) 和cost(reduce)分别定义为通过映射任务和约简任务处理数据的时间成本。此外,将budger(map) 和budgerI(reduce)分别表示映射任务和约简任务的预算成本。除上述成本以外,仍需考虑当数据不在约简任务中运行的节点上时所支付的成本(仅适用于集群中存在的数据)。因此,还应该确定数据传输和处理的时间成本cost(data)和预算成budget(data)。 将start(map)和start(reduce)分别定义为映射任务和约简任务的开始时间,当start(map)为定值时表示所有映射任务均在一项工作到达内部队列时开始,即start(map)=A。为了计算工作J所需要的映射槽的数量,需要掌握start(map) 的最大值start(max)(map),则SLmap和SLreduce最小值的数学表达式如下: (14) (15) 基于时间处理成本的考虑,使用预算Bused定义为是时间成本和资源数量之间的乘积,即: (16) MOSMT算法能够集成在Hadoop平台中。由于JobTracker是一个独立的组件,因此新的调度程序应该扩展为TaskScheduler,并且定义其属性和方法。完成扩展后,新调度程序需要插件。在MapReduce的配置文件中,有一个变量指示使用的算法,默认情况下变量为Fair Scheduler,如果用户想使用新的算法,只需修改配置参数并指定它。 城市交通是现代城市生活的伴随,其可持续性在很大程度上取决于不同资源的消耗,如电力和燃料。因此,它表现为二氧化碳(CO2)和当地污染物排放,直接影响公民的生活质量。城市交通造成40%的二氧化碳排放和70%的道路运输产生的其他污染物排放公路运输占整个运输产业温室气体排放量的70%以上,占所有排放总量的13%(运输产业占排放总量的近20%)[18]。智能交通系统(Intelligent Transportation Systems, ITS)旨在通过结合专业基础设施,通信技术和创新服务的解决方案来克服此类问题,以提高交通和移动管理、多模式或道路交通解决方案的质量[15]。 然而,为了开发准确的交通模型,能够理解交通现象并从交通流量在现实世界城市中表现的统计模型做出决策,需要大量的数据。感应移动设备和各种移动应用,其目标是提供一个生态系统框架,使城市社区能够利用移动的共享价值,这些价值可以超越社会网络的经典观点,分别是当前的服务创造趋势。为了促进协作,该框架旨在在由应用提供商组成的服务云中分发不同的信息源(来自最终用户或ITS服务,例如出租车公司、交付网络等)。由于移动用户将提供各种类型的传感器数据,因此必须在数十万参与者的网络和具有不同兴趣的共存服务之间保证智能数据收集、处理和共享。该框架构建了一个集成服务和应用程序的生态系统,灵活且可重新配置,提供给用户多个包[16]。MobiWay的架构如图1所示。 图1 MobiWay 理论架构 该体系结构中的一个重要组成部分是数据聚合,旨在处理大量的流量数据,以便在城市级别提供准确的流量数据模型。这意味着需要收集来自城市数百万辆汽车的数据,并持续存储更长时间。进一步定期处理这些数据,得出流量可能性的统计和概率模型,取决于诸如一天中的时间、天气状况、预定事件等参数。所提出的算法可以处理不同粒度级别的数据在聚合、清理、统计分析等过程中出现的问题。通过分析城市不同区域的宏观流量进行预处理,进行微观层面和细粒度层面的条件评估。 处理应用程序使用MapReduce范例,Apache Hadoop和Spark作为支持技术。顾名思义,MapReduce有两个重要的任务类型:map和reduce。从输入接收的数据被分成块,因此映射任务仅接收整个数据的一部分,并在许多地图任务中并行运行[17]。所有映射任务的输出都会进行排序并重定向到reducer。数据存储在文件系统中,因此Hadoop为此部分使用HDFS(Hadoop分布式文件系统)。调度程序负责计划如何将作业分配给映射或约简器。实际应用中期望节点能够负责计算和存储,在节点上调度计划安排的任务,以减少网络中的流量。但是为了实现这一点,调度程序需要一种改进的算法[18]。因此,对于MobiWay,需要使用可提供优化性能的适当接口来实现map和reduce功能(希望获得成本和时间最优的解决方案)。 本节介绍了MOSMT算法的比较结果,开发并测试新Hadoop调度程序的所有设置步骤。首先介绍Hadoop框架所需的配置,然后设置调度程序负载模拟器,最后解释了第一个Hadoop应用程序,其目标为了解场景背后的范例、工作性质和任务。 Hadoop集群设置考虑了如下的配置参数: (1) Hadoop集群,在64位架构的Ubuntu计算机上进行实验,包含maven、libssl-dev、cmake和protobuf库; (2) HDFS配置,dfs.replication设置为支持容错; (3) 调度负载模拟器(Scheduling Load Simulator,SLS)设置(整个模拟器内存或每个容器的内存,虚拟内核的数量等); (4) Rumen工具用于信息转换并将信息添加至作业历史记录中,其输出将是json文件。这个json文件将进一步用作SLS的输入。 当新的调度算法实现后,很难将其部署在真实的集群中,并且消耗大量的计算资源。但是使用SLS能够很好地解决这一问题,因为SLS更容易为调度程序部署各种不同的功能,但只能使用一台计算机完成SLS的配置。采用该方式,不仅节省了大量时间,而且降低了成本。 图2所示为SLS的体系结构。正如前文所述,SLS的配置均在一台机器上运行,这意味着所有Hadoop组件应该在没有网络组件的同一台机器上运行。由于调度程序是资源管理器的主要组件之一,因此其便是SLS中需要更改的主体。通常而言,SLS可看成是主调度程序的包装器,如图2中的灰色部分所示。在仿真器中,SLS模拟每个节点管理器和每个应用程序管理器。 图2 调度负载模拟器架构 当作业执行映射任务和约简任务时,JobHistory程序将保留所有历史记录。但这个历史记录并不是完全按照SLS指标显示的,因此模拟器使用不同的输入。 数据信息转换过程包含两个步骤:TraceBuilder和Folder。第一个步骤是处理数据以获得更好的格式,第二个步骤是根据一些统计运算添加其他信息。这两个步骤使用两个命令执行,该命令可以在Hadoop框架中的Rumen工具目录中找到,如需了解该命令的其他信息、参数和选项可以参考文献[4]。 调度负载模拟器使用Metrics库来评估调度算法的性能。通过SLS使用量来进行具体量化。选取以下侧重于时间成本和资源使用方式的度量指标与目前广泛使用的Fair、FIFO算法进行对比实验。 度量指标如下: (1) 应用程序和容器:在此期间运行的应用程序量和容量; (2) 资源:已被使用资源量与剩余资源量; (3) 每队列资源:每个队列所使用的资源量与剩余的资源量; (4) 时间:每个调度程序均有多个操作,比如添加、删除和更新节点,以及添加和删除应用,因此每个操作的时间都有很重要的意义; (5) 内存:了解模拟器内存使用量是必要的。 本节测试新调度算法主要是将其与文献[10]所提的FIFO调度程序和文献[11]所提的Fair调度程序进行比较,由于Fair、FIFO算法已在Hadoop框架中实现,无需额外的工作量。为了使用SLS,需要两个输入文件:带工作负载的json文件和带拓扑的json文件。 在Hadoop上运行5 000个任务,使用Rumen以模拟器所需的格式获取工作负载。为此,使用命令TraceBuilde,将历史记录作为输入,并生成作业跟踪和使用的拓扑。由于本算法创建了12个节点的拓扑结构,所以由TraceBuilde生成拓扑结构不是必需的。使用了具有不同输入数据的MobiWay应用程序,实验中有四种类型的输入,按其大小分类,划分为小型、中型、大型和超大型。 图3显示了群集中节点的已分配核心数。Fair和MOSMT调度程序的核心用法非常相似,均与作业执行时间相关。从图中可以看出,Fair和MOSMT具有最佳的核心分配方案。 图3 在Hadoop集群中一个节点的分配核心数量 当作业使用更多内存进行映射或缩减任务时,模拟器内存的分配数量将增加。从图4中可明显看出,当输入增多时,FIFO和FAIR使用了更多的内存。同时,这也表明了MOSMT不会执行超过截止期限、预算或两者的任务。 图4 在Hadoop集群中一个节点的内存分配 图5和图6显示了Hadoop集群中资源配置和资源重新配置/更新的性能。从中可以看出,MOSMT算法的时间成本与Fair、FIFO相似,不过性能优于两者,因为MOSMT算法会动态计算用于映射与约简任务槽的数量。 图5 Hadoop集群中的资源提供性能 图6 Hadoop集群中资源更新的性能 算法运行时作业提交的顺序是一定的,因此作业的执行顺序与提交时相同。不过调度程序重新排列作业时,即使有很多输入量也应能够访问资源。在MOSMT算法中最大的工作没有运行权限,因为输入规模太大,截止时间和预算将超过预期。 图7的结果表明,所有测试的调度算法在同一个工作中分配集群中的任务没有等待任务而长时间停留在队列中。 图7 任务分配调度 算法度量指标体现了每个操作的时间成本,具体操作包括:分配节点、添加节点、删除节点、节点更新、添加应用程序、删除应用程序以及容器过期等。由于条件限制,只完成了添加节点、节点更新以及添加应用程序并删除应用程序四个操作并进行算法性能测试,Hadoop集群中任务设置的性能测试结果如图8和图9所示。显然,在应用设置成本中MOSMT算法在不同步长下增加节点所需的平均时间最长,而在应用完成成本对比中所需时间最短。 图8 在Hadoop集群中的应用设置成本 图9 Hadoop集群中应用完成成本 调度器的时间成本如图10所示。由于MOSMT算法侧重于考虑时间成本,因此在这个方面表现得更具优势,而FIFO和Fair调度程序的结果相似。 图10 调度阶段的时间成本 调度器的时间成本与调度任务执行的时间相关,图11显示了所有计划任务的开始时间、完成时间和持续时间。可以看出相对时间比较接近,意味着我们可以使用多种优化算法获得相同的优化性能。 (a) 开始时间 (b) 完成时间 (c) 持续时间图11 调度任务的运行时间 针对Hadoop平台多任务多目标调度难题,提出了一种MOSMT算法。算法包括:Hadoop平台中最相关的约束:避免资源争用和集群的最佳工作量;与优化目标:截止日期和预算。应用于MobiWay评估MOSMT算法性能,测试结果表明,当工作存在成本和时间限制时,该算法相比于FIFO和Fair算法更为有效。在一定的资源和时间条件下,MOSMT通过使用调度负载模拟器配置不同的算法功能,从而降低时间成本和资源占用,实现多目标多任务的高效合理调度。 研究过程中假定MapReduce作业均是独立的,调度任务进行前或者期间节点均不会发生故障,但这会使该算法的应用受到很多局限。后期,将针对用于工作流程的迭代MapReduce以及基于过去迭代信息进行预测的调度策略作进一步研究。此外,所提算法的评估指标有待完善,以更好地呈现适用多任务多目标调度算法的重要性,当然,算法的可扩展性是不容忽视的。
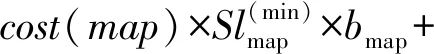
2 算法在MobiWay中的应用
3 实验与分析
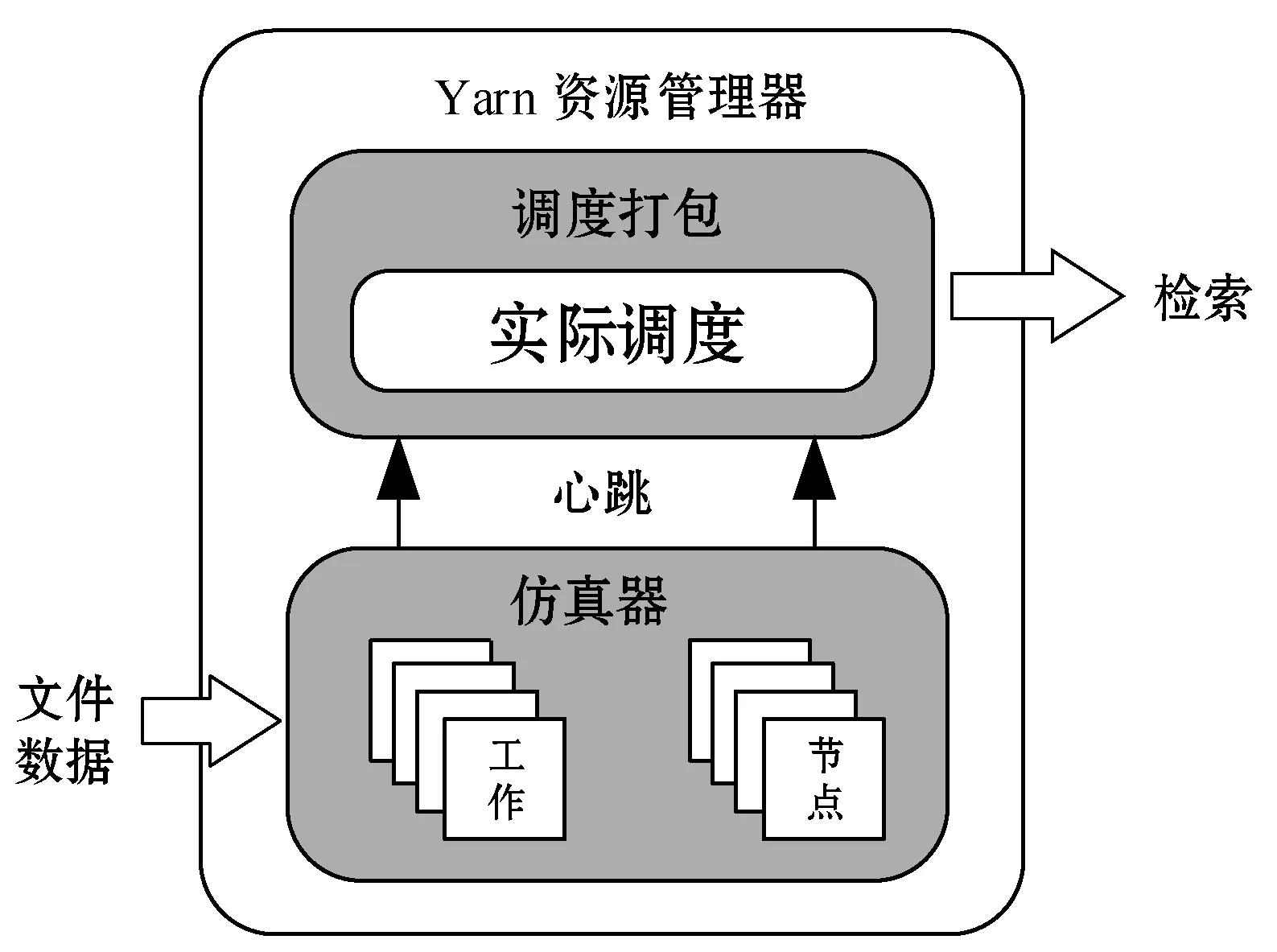
3.1 性能度量
3.2 实验结果分析


4 结 语
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
农业工程学报(2022年11期)2022-08-22
北京航空航天大学学报(2022年5期)2022-06-06
南方农业·下旬(2022年4期)2022-05-24
计算机应用(2022年2期)2022-03-01
北京航空航天大学学报(2021年4期)2021-11-24
计算机应用与软件(2021年11期)2021-11-15
北京航空航天大学学报(2021年6期)2021-07-20
计算机应用(2021年4期)2021-04-20
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
