
基于顺序遗忘编码和Bi-LSTM的命名实体识别算法
2020-03-11 12:51杨贺羽杜洪波朱立军
计算机应用与软件 2020年2期
杨贺羽 杜洪波 朱立军
1(沈阳工业大学 辽宁 沈阳 110870)2(宁夏智能信息与大数据处理重点实验室 宁夏 银川 750021)3(北方民族大学 宁夏 银川 750021)
0 引 言
随着互联网、大数据等技术的高速发展。非结构化的文本数据呈爆炸式的增长。在这些非结构化的文本数据中常常存在着大量的命名实体,这些实体对于理解文章语义以及构建后续的相关任务都起到了至关重要的作用,其识别的性能几乎奠定了每个自然语言处理任务的基础。
命名实体识别旨在识别出文本中的专有名词并加以分类。常见的命名实体包括人名、地名和机构名等。随着知识图谱、信息检索和智能问答系统等相关技术的高速发展,各种类型的命名实体相继涌现。如医疗领域的疾病、症状和身体部位等,军事领域的武器、部队和机构等。在面对新领域时,如何在仅有少量的相关领域先验知识的条件下,快速准确地识别出各领域的实体及实体类型成为近年来中外学者的研究热点。
传统的命名实体识别方法包括基于手工编织规则的符号方法和依赖于特征工程和统计模型的统计方法。其中,统计方法在实现命名实体识别的过程中展现出很好的效果,常见的方法有条件随机场[1](Conditional Random Field, CRF)、最大熵马尔科夫模型[2](Maximum Entropy Markov Models, MEMM)、隐马尔科夫模型[3](Hidden Markov Models,HMM)等。如Borthwick等[2]利用MEMM结合姓氏语料的方法来提高命名实体识别中姓名实体的准确性。孙晓等[4]提出一种深层CRF方法,通过增加层次来选择最优特征集,并在生物医学领域中取得了很好的效果。俞鸿魁等[5]利用层叠HMM分别识别中文的无嵌套和有嵌套的实体类型,有效提高了嵌套实体的准确率。但统计方法过于依赖昂贵的手工特征和特定任务的相关资源,并且建立好的模型在面对新的任务和领域时泛化能力不强、可移植性差。为了最大限度地解决统计方法中需要的昂贵资源,命名实体识别开始使用深度学习技术。如文献[6]提出了一种端到端的模型,利用卷积神经网络(Convolutional Neural Networks, CNN)和LSTM两种神经网络分别学习英文单词的字符级特征和句子级特征。文献[7]使用双向循环神经网络 (Bidirectional Long Short-Term Memory, Bi-LSTM)预训练一个语言模型,利用该语言模型训练得出的词向量来增强单词的信息表达能力。文献[8]提出一种偏旁部首特征结合LSTM的中文命名实体识别方法,通过LSTM学习中文的更小级别特征。
LSTM作为深度学习的一种重要神经网络,常被用来解决序列标注问题,但由于其在提取句子特征的过程中,对距离当前词较远的句子信息会出现获取能力变低甚至无法获取的问题。针对这一问题,本文提出一种融合顺序遗忘编码[9](Fixed-size Oradinally Forgetting Encoding, FOFE)和Bi-LSTM的命名实体识别算法,利用FOFE可以将任意长度的句子编码成固定大小表示的编码方式来增强LSTM对句子特征的提取能力。该算法在仅使用少量的有标注训练语料和未标注语料的情况下,在英文的标准命名实体数据集CoNLL2003和中文的1998年《人名日报》数据集中,F1值分别达到了91.30和91.65,证明了该方法的有效性和通用性。
1 融合顺序遗忘编码和循环神经网络的模型
本文提出的模型是一种多层结构的命名实体模型,结构如图1所示。该模型主要分为三部分:FOFE编码、特征提取和标签约束。首先对输入句子中的每个字分别进行向量化表示和FOFE编码表示。然后将向量化表示的每个字输入给Bi-LSTM进行基于上下文信息的特征提取,将得到的特征向量与相应的FOFE编码相结合,将结合后的特征向量输入给融合注意力机制的Bi-LSTM,得到包含不同重要度信息的特征向量。最后将特征向量输入给CRF学习标签序列的约束。

图1 基于FOFE的命名实体识别模型示意图
1.1 字向量输入层
字向量是一种可以定量地度量字与字之间关系的一种字表示方法。给定一串由n个字符组成的句子{x1,x2,…,xn},每个字符由一段固定维度大小的向量xk表示,该字向量会被预训练好的分布式字向量初始化。另外,对于英文可以将字符编码和字编码结合起来,形成新的字向量。
1.2 Bi-LSTM特征提取层
为了提取依赖于句子上下文信息的特征,将得到的字向量xk作为输入传送给Bi-LSTM。LSTM是由Hochreiter等[10]提出的一种利用门控机制来对历史和当下信息进行过滤的模型。该模型的基本单元包括一个或多个记忆单元和三个自适应的门控单元,门控单元分别为输入门、忘记门和输出门,在时间t更新LSTM单元的公式为:
it=σ(Wxixt+Whiht-1+Wcict-1+bi)
(1)
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf)
(2)
ct=ftct-1+ittanh(Wxcxt+Whcht-1+bc)
(3)
ot=σ(Wxoxt+Whoht-1+Wcoct+bo)
(4)
ht=ottanh(ct)
(5)
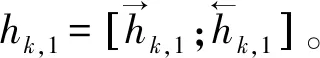
1.3 FOFE层
FOFE是一种序列编码方式,可以无损地将可变长度的序列编码成固定大小表示的编码。Jiang等[9]通过理论和实验证明,该编码几乎可以保证任何长度序列编码的唯一性。具体的编码方式如下:
给定一个词表,假设词表的大小为K,词表中的每一个字表示为一个K维的one-hot向量e∈RK,给定一串字符S={w1,w2,…,wt},每一个字符wt都由et表示,FOFE将基于一个递归公式(z0=0)对每个部分序列进行编码:
(6)
式中:zt表示直到wt的部分序列FOFE编码;α(0<α<1)是控制历史对当前位置影响的常数遗忘因子。
根据FOFE的编码方式,可以通过两个矩阵相乘的方式得到相应的编码。
(7)
将得到的FOFE编码通过投影矩阵U映射到一个更低维度的空间MVU,最终的编码向量由H=M(VU)W+b得到。
FOFE利用遗忘因子α(0<α<1)来控制历史对当前位置的影响程度,但这种方法仅考虑了距离对于遗忘的影响程度,并且这种影响程度是固定的。为了动态地学习不同字对当前字的不同影响程度以及根据字的其他特征学习历史信息的遗忘程度,在FOFE编码后又为其连接一个Bi-LSTM,学习基于FOFE编码的特征向量fi。
1.4 融合Bi-LSTM和FOFE层
将基于字向量得到的特征向量h1,i和基于FOFE编码得到的特征向量fi相连,使其形成包含全局位置特征的新的特征向量[h1,i;fi],然后通过Bi-LSTM进一步提取特征,形成新的特征向量h2,t。
1.5 注意力机制层
为了学习每个特征向量的不同重要度,注意力机制可以使识别模型更多地关注对标记有利的信息。根据Bi-LSTM隐层节点的特征H=[h1,h2,…,hn]产生注意力重要度矩阵α和特征表示v,具体计算过程如下:
ui=tanh(Wuhi+bu)
(8)
(9)
v=αhi
(10)
1.6 投影层
为了得到标签个数大小的得分矩阵,首先将得到的特征矩阵进行非线性的映射:
y=tanh(h2,t·w1+b1)
(11)
然后将特征矩阵投影到标签个数大小的得分矩阵,得到每个标签的分数矩阵。
g=y·w2+b2
(12)
1.7 CRF层
由于序列标注任务中连续标签之间会存在依赖性,如在每句话的最开始只可以是B、S、O标签,而不可以是I和E等。为此,又将得到的标签分数矩阵输入给CRF以学习连续标签之间的约束。CRF是一种无向的概率统计图模型,线性链条件随机场由于它的线性结构被广泛用来处理线性序列标记问题。其中CRF损失函数由真正路径分数和其余所有可能路径的总分组成。并且在所有可能的路径中,使得真正的路径具有最高的分数,在进行最优路径选择时可以使用维特比算法。
2 实 验
2.1 实验数据
为验证本文提出的命名实体识别模型有效性,做了四种模型结构的对比实验,分别为:(1)基线模型;(2)基线模型+注意力机制;(3)基线模型+FOFE编码;(4)基线模型+注意力机制+FOFE编码。其中基线模型为不包括FOFE编码、注意力机制和L2(如图1所示)的Bi-LSTM的模型结构。为了验证该模型的通用性,在中文和英文两种语言的数据集中进行对比实验,分别为英文的CoNLL2003命名实体数据集和中文的1998年《人民日报》数据集。CoNLL2003数据集包含四种实体类型:人名、地名、机构名和待定,实体分布见表1。《人民日报》数据集包含三种实体类型:人名、地名和机构名,实体分布见表2。两种数据集均为新闻报道数据并且采用的标注策略均为BIOES,分别表示为:B(Begin),实体的开头;I(Inside),实体的中间;E(End),实体的最后;S(Single),单个字表示的实体;O(Other),其他非实体字符。
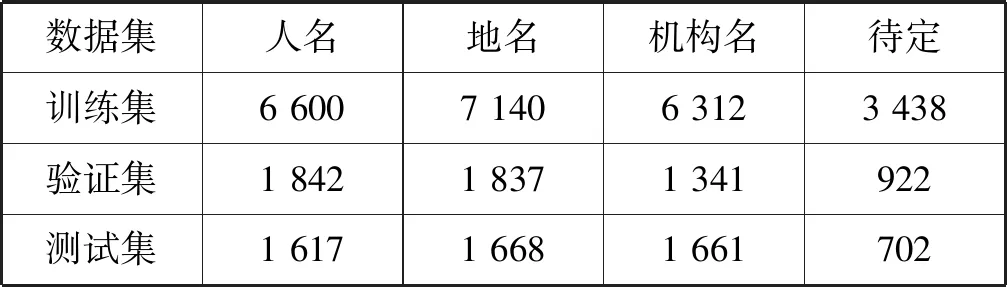
表1 CoNLL2003实体分布
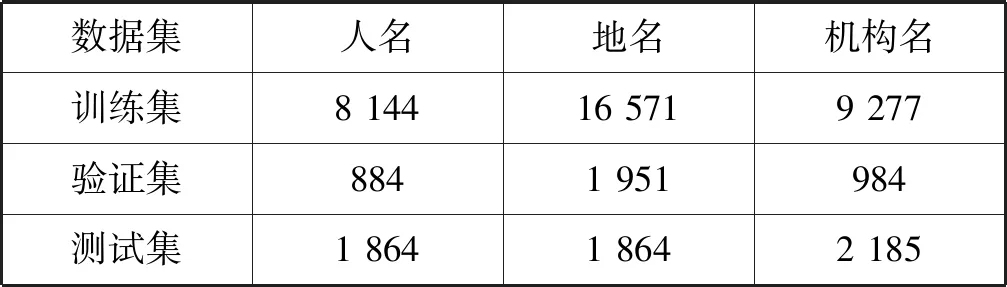
表2 《人民日报》实体分布
采用的评价标准为准确率P、召回率R和F1值F1。具体计算公式为:
(13)
式中:T1是标注正确的实体数;T2是标注的实体数;T3是实际的实体数;β是用来衡量准确率和召回率的相对重要性,本文中取β=1。
2.2 训练及分析
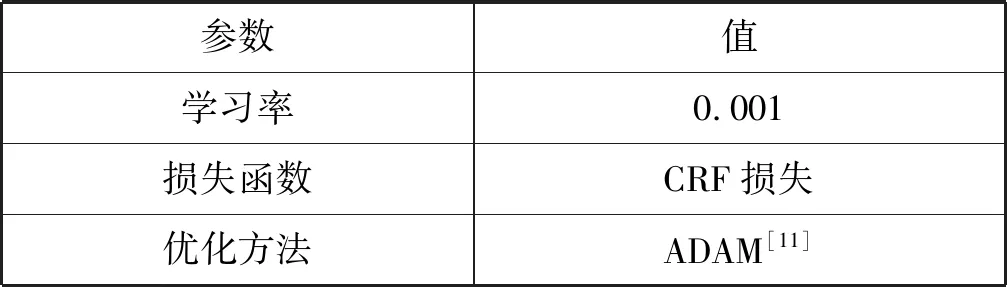
(1) 英文数据集:首先将英文数据集中的所有数字都转化成0,并且保留原字母的大小写。其余参数见表3。
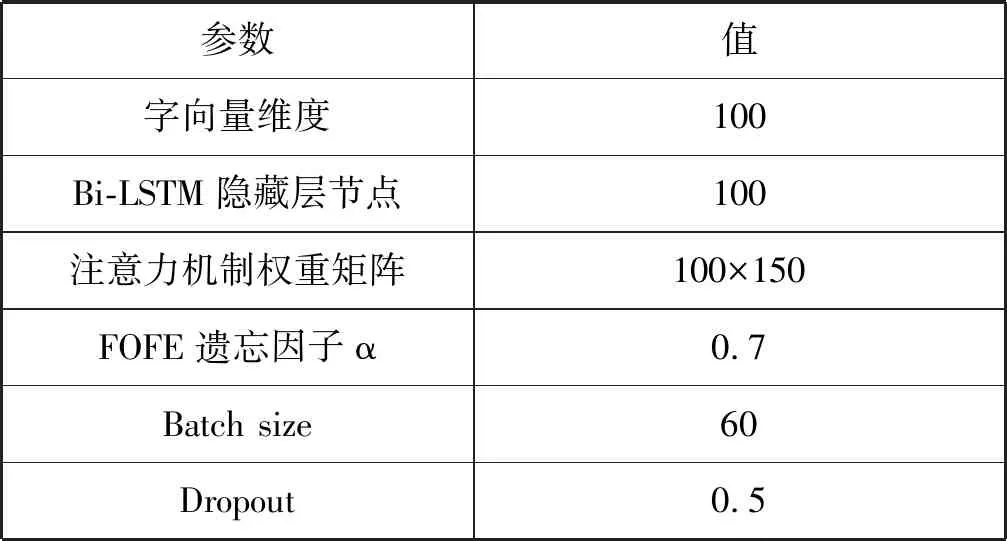
表3 实验训练参数
续表3
表4中列出了不同模型结构在CoNLL2003数据集中的实验结果。
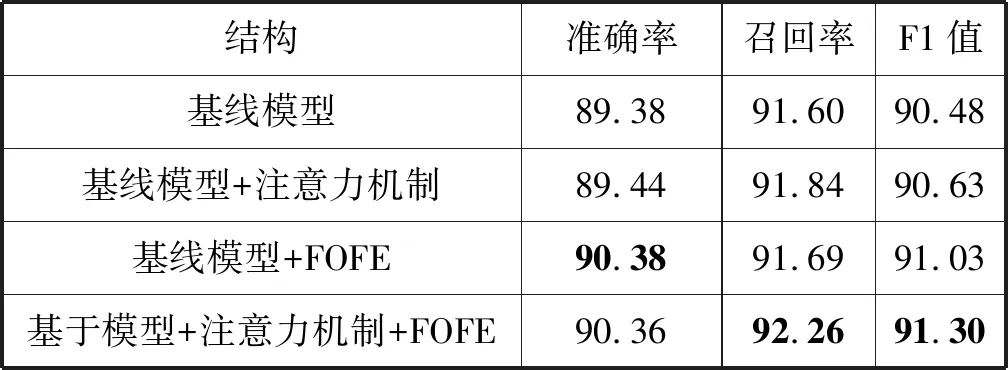
表4 CoNLL2003实验结果
从表4中可以看到,与基线模型相比,加入注意力机制的模型结构,在识别的准确率和召回率方面都有了小幅度的提升,而单独加入FOFE结构以后,准确率有了大幅度的提升。这是因为FOFE编码为LSTM提供了全局的位置特征,在LSTM仅有前向或反向信息的情况下,提供额外的补充信息。而结合注意力机制和FOFE编码的模型结构,其识别的召回率有了明显的提升,达到92.26,并且在召回率有了很大提升的情况下,准确率仍然保持很高的水平。
图2显示了CoNLL2003数据集在不同模型结构的训练过程中F1值随迭代次数的变化情况。
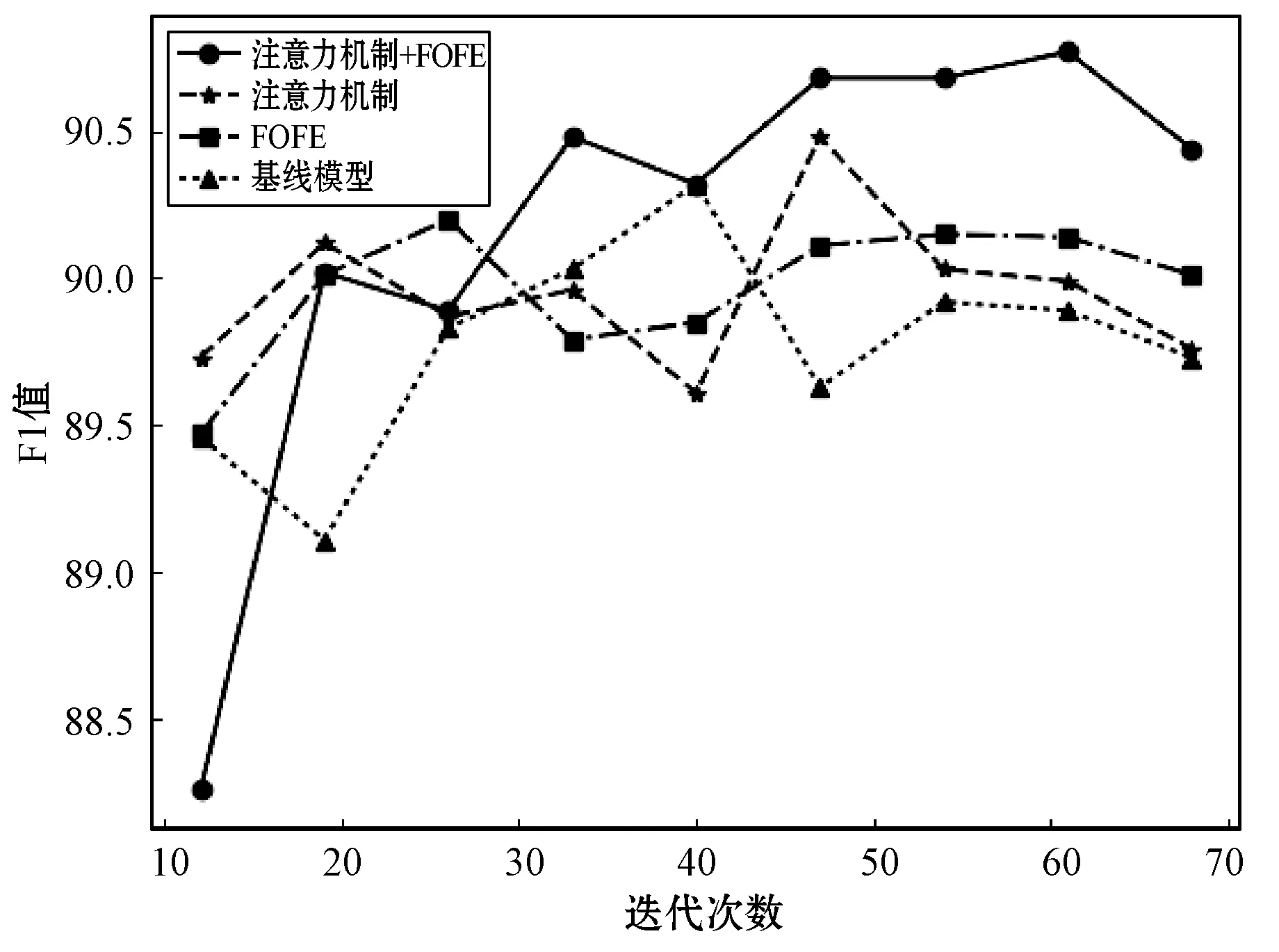
图2 CoNLL2003不同模型F1值随迭代次数变化情况
从图2中可以看到,在前50轮迭代的过程中,各个模型的识别能力相差不多。经过深层次的迭代后,基线模型相较于其他模型的识别能力明显变弱。注意力机制和FOFE的模型虽然稍好,但仍没有升高的现象,甚至有下降的趋势。在加入注意力机制和FOFE结构之后,模型的识别能力明显高于其他模型,并且随着迭代次数的增加,识别能力仍旧保持在比较高的水平,但仍有下降的趋势,这是一种过拟合的现象。
(2) 中文数据集:实验中对中文数据直接采用字向量,并且将所有的数字都替换成0,所有的英文字母都替换成了对应的小写,其余参数与英文数据集参数一致。本文同样对中文数据集做了上述四种模型结构的对比实验,具体实验结果见表5。
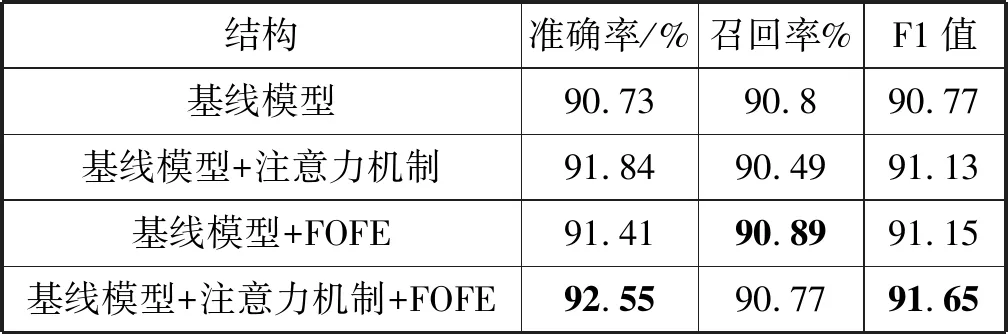
表5 《人民日报》实验结果
由表5可以看到,同时加入注意力机制和FOFE结构的模型在中文数据中的表现与英文数据集中的表现正好相反。在中文数据集中,模型的准确率有了很大幅度的提升,在英文数据集中,则在召回率上有了比较大的提升,而F1值在两个数据集均有较大提升。由此可见,FOFE提供的全局位置信息对于模型在识别的准确率和召回率方面都有所帮助。
图3是《人民日报》数据集在不同模型结构的训练过程中F1值随迭代次数的变化情况。
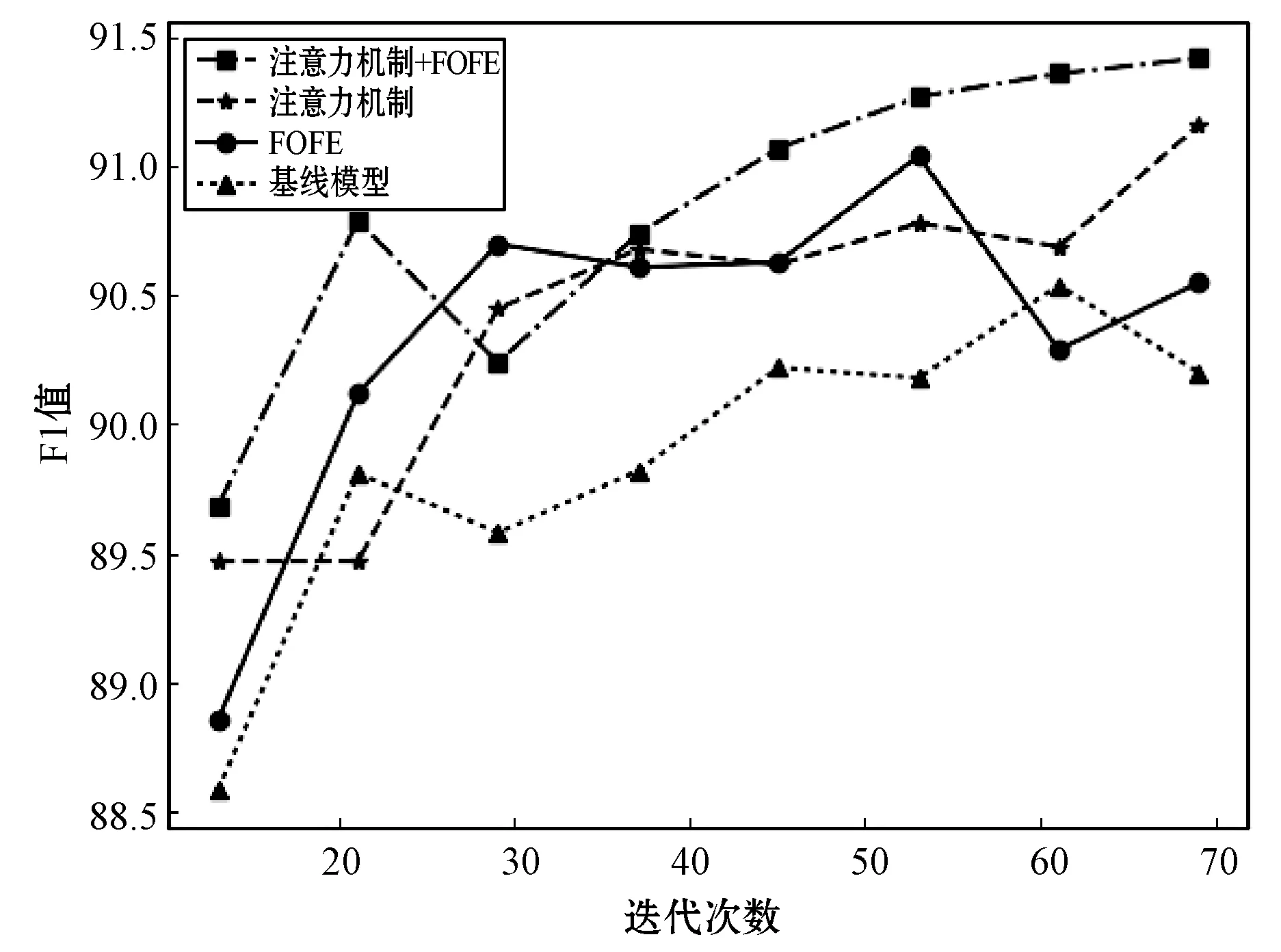
图3 《人民日报》不同模型F1值随迭代轮数变化情况
从图3中可以看到,与英文数据集的实验相比。基线模型在更早的20次左右迭代时就开始呈现出比较弱的识别能力。同时融合注意力机制和FOFE的模型在迭代40次左右时,其识别能力已经明显高于其他模型。
3 结 语
本文针对LSTM对较远的句子信息进行特征提取时能力会相对变低甚至无法获取的问题,提出一种新的命名实体识别方法,通过FOFE这种可以保留任意长度句子信息的编码方式与LSTM网络相结合来增强其特征的提取能力。分别在中文和英文的数据集中进行实验对比,结果表明,该方法是有效的且具有一定的通用性,为命名实体识别在通用领域中做了一定的贡献。
本文提出的命名实体识别方法只是在两种语言的人名、地名、机构名这些实体中进行了实验分析,对于其他领域的不同实体类型还没有涉及,对于不同领域的不同实体类型的识别还需要进一步验证。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中国典型病例大全(2022年7期)2022-04-22
保定学院学报(2022年2期)2022-04-07
小学生学习指导(中年级)(2021年12期)2021-12-30
中学生理科应试(2021年11期)2021-12-09
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
华人时刊(2020年21期)2021-01-14
数学学习与研究(2018年15期)2018-11-12
东方女性(2018年3期)2018-04-16
中国诗歌(2017年12期)2017-11-15
