
基于深度学习的相似语言短文本的语种识别方法
2020-03-11 12:51张琳琳杨雅婷陈沾衡潘一荣
计算机应用与软件 2020年2期
张琳琳 杨雅婷 陈沾衡 潘一荣 李 毓
1(中国科学院新疆理化技术研究所 新疆 乌鲁木齐 830011)2(中国科学院大学 北京 100049)3(新疆理化技术研究所新疆民族语音语言信息处理实验室 新疆 乌鲁木齐 830011)
0 引 言
随着移动互联网的普及和社交媒体的兴起,跨国家的语言交流日益频繁,导致多语言特别是相似语言共现的现象在网络社交语境中频繁出现。语种识别特别是相似语言的识别需求也愈加迫切。语种识别作为机器翻译、跨语言检索等众多自然语言处理领域的基础环节一直是研究热点,学术界普遍将语种识别视为一种“基于某些特征进行文本分类”的特殊文本分类(text categorization)问题[1]。Cavnar等[2]提出了N-Gram词频排序的语种识别方法,基于该理论,Frank[3]设计了使用广泛的语种识别工具Textcat,能对74种语言进行识别。Campbell等[5]采用支持向量机(Support Vector Machine,SVM)进一步提升语种识别的效果。
随着语种识别的细分,针对短文本的识别也有很多。Vantanen等[6]利用N-Gram模型结合朴素贝叶斯分类器的方法对5至21个字符的短文本进行识别。Tromp等[7]同时采用文本中的词本身的信息和词与词之间的信息,构造了一种基于N-Gram的图结构模型来进行语种识别,有效提高短文本的识别效率。Lui等[8]获取文本的N-Gram特征,以多项式朴素贝叶斯分类器构造了语种识别工具Langid。郝洺等[9]通过修改特征词和共同词的权重对基于N-Gram频率的短文本语种识别方法进行了改进。
近年来,随着神经网络的重新兴起,深度学习也开始应用在语种识别上,尤其在语音的语种识别方面已取得不错效果。在文本处理方面,尤其对短文本分类已经有基于词级和基于字符级的神经网络文本分类的研究基础。如Zhang等[10]利用基于字符的卷积神经网络(Convolutional Neural Network,CNN)对短文本的识别已经达到不错的效果。
由于社交媒体的兴起,Carter等[11]结合用户信息等对推特信息进行语种识别。在社交媒体中,常出现相似语言共现的现象,相似语言的语种识别也成为研究热点。在VarDial 2016会议发布的区别相似语言(Discriminating between Similar Languages,DSL)的任务中,Malmasi等[12]用SVM和逻辑回归等传统机器学习方法在参与队伍取得第一。Cianflone等[13]则用了基于N-Gram和神经网络的两种识别方法。之后,Marcelo等[14]在DSL2017上用基于词的CNN模型实现相似语言的识别,Belinkov等[15]用基于字符的CNN模型在DSL2016上实现了整体83.0%的正确率。
文献[16]研究表明,虽然语种识别整体研究成熟,但文本长度越短,语料越小,语种识别难度越大。同时,语言相似度越高,识别难度也越大。
本文提出了一种针对相似语言短文本的语种识别方法,以字符为输入,构建包含CNN和长短期记忆(Long Short-Term Memory,LSTM)的神经网络模型。此模型能同时获取词中的字符组合信息和词与词之间的信息,并且采用字符级输入能解决大部分未登录词的问题。该方法在维吾尔语和哈萨克语、波斯语和达里语等相似语言上取得不错的效果。
1 相关工作
1994年Cavnar等[2]提出的基于N-Gram语言模型的语种识别方法在400字以上长文本语料上能达到99.8%的准确率。但在社交媒体中更多的是150字以内的短文本,论坛、移动社交应用中的口语文本很多是在20词以内,有效提高短文本的语种识别效果成为关注的焦点。同时,由于地域文化因素,往往地域相近地区所使用的语言也很相似,如在新疆地区维吾尔族和哈萨克族公共居住,所使用的维吾尔语和哈萨克语很相似,所以有识别相似语言的需求。
1.1 N-Gram语种识别模型
N-Gram是指一段给定的文本中包含N个最小分割单元的连续序列[17]。最小分割单元是根据具体应用需要而自定义的基本对,在语种识别时一般是字符、字或词(针对汉语、日语等语言时一般是字,英语等语言一般是词)等。
N-Gram就是N-1阶马尔可夫语言模型的表示。假设在一段随机变量序列S1,S2,…,Sm中,如果序列中任何一个随机变量Si发生的概率只与它前面的N-1个变量Si-1,Si-2,…,Si-n+1有关,即:
P(Si|S1,S2,…,Si-n+1)=P(Si|Si-1,Si-2,…,Si-n+1)
(1)
在语种识别中,需要统计每个N-Gram频率作为词频。N-Gram模型把语料中连续的长度为N的字符或词序列看作一个计算单元,其中第N个位置出现某个字符或词的概率只与前面N-1个位置上的字符或词有关。
基于N-Gram的语种识别方法的主要思想是Zipf定律[18]:在人类语言中,一个字或词出现的次数与频率表中它的排序成反比。
当以字符作为最小切割单元时,能够获得字符间组合信息,但无法获得词与词之间的信息。反之在Cianflone等采用的N-Gram模型中[13],以词作为最小切割单元,虽然可以获得词与词之间的信息,但无法获取词中字符间的信息。N-Gram模型往往不能很好兼顾词本身的信息和词与词之间的信息。同时,像在法语、维吾尔语中很多词只是词缀不同但词根相同,如果是选择词作为分割单元,就无法识别这些相似的词,从而会出现未登录词的问题。
1.2 神经网络模型
语种识别发展一直受到文本分类研究的影响。近年神经网络广泛应用到文本分类。Kim等[19]用CNN网络实现了对句子文本的有效分类。Zhang等[20]利用基于字符的CNN模型对不同文本进行分类,表明在不同数据集上基于字符的CNN网络可以实现不错的效果。Kim等[21]构建的基于字符的神经网络语言模型很好地结合了字符信息和词之间的信息。
同时在相似语言的识别中,研究人员尝试了基于字符和基于词级别的CNN神经网络。Cianflone等[13]在DSL2016任务中应用基于字符的CNN结合双向长短期记忆网络可以达到87.5%的正确率。
但单纯基于字符或基于词级别的神经网络在文本语种识别中一般不便于同时兼顾文本中词本身的信息和词与词之间的信息。
2 模型设计
本文将文献[12]构建的神经网络语言模型进行改进并用于语种识别的分类模型。同样以字符作为输入,通过CNN、LSTM以及一个全连接层实现语种分类。CNN在字符级上对模型进行训练后,可以获得每个单词的词向量,该向量包含词本身的信息。LSTM以上层的词向量作为输入,处理后能获取词与词之间的信息。构建的模型如图1所示。相较于传统的模型,本模型的优势在于一个神经网络中兼顾了字符级和词级的信息。
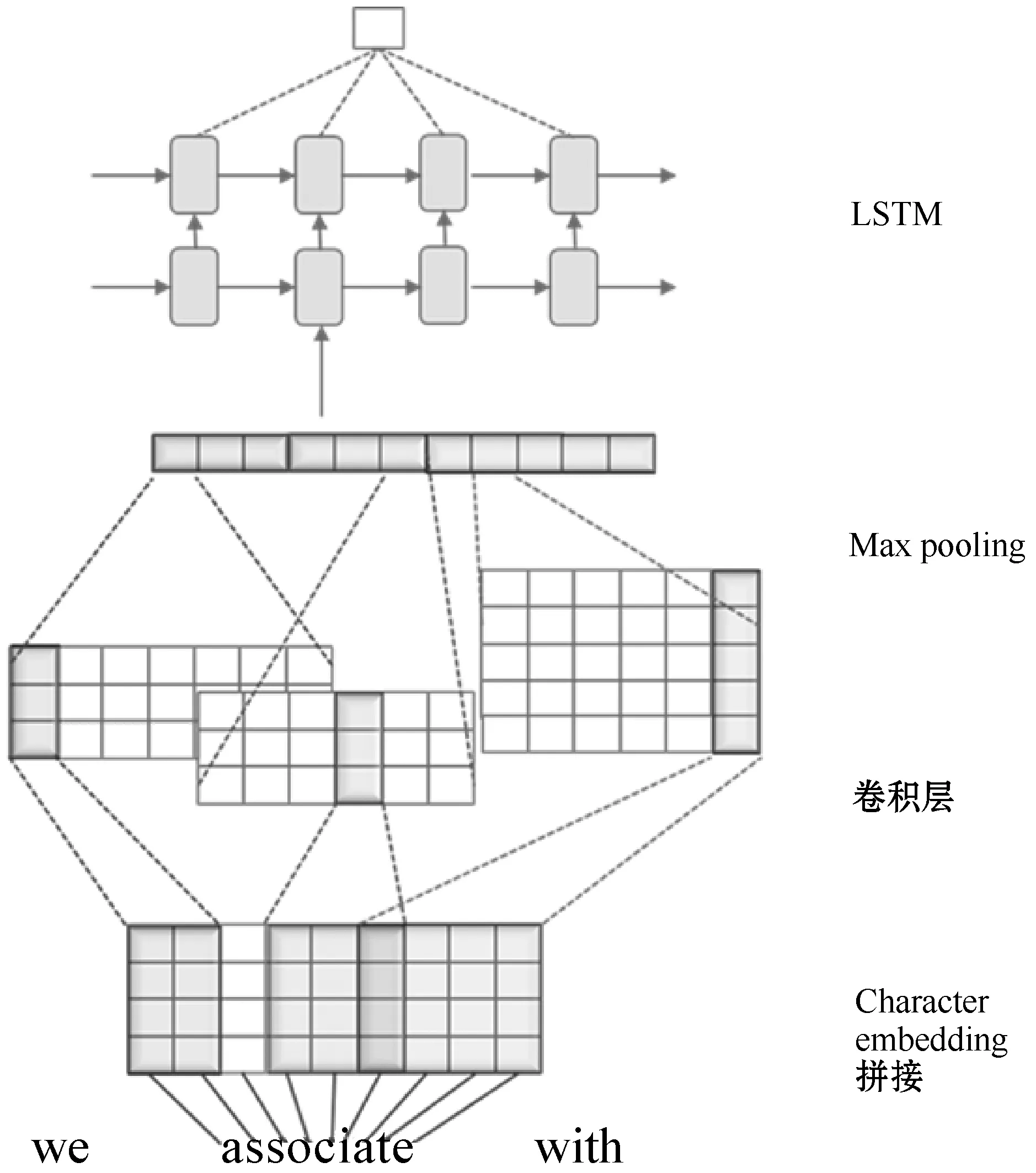
图1 模型结构图
2.1 字符级卷积神经网络
与文献[21]构建的基于字符的神经网络语言模型一样以字符向量作为输入。首先,对文本中包含的所有字符进行字符向量封装,生成一个字符向量表。字符表是一个以总字符数为列数的矩阵,每一列对应字符向量ci,维度是d。在输入时,以每个词中的字符向量输入卷积神经网络。假设单词w是由n个字符[c1,c2,…,cn]组成,则词w是一个n×d的矩阵。
在卷积层中,包含一组可学习的滤波器(filter)或内核(kernels),参数初始值可随机设置。假设一个内核的宽度是k,个数是f,则内核是一个d×k的矩阵。按照CNN原理,词w经过内核k卷积后,会生成一个f×(n-k+1)的矩阵,矩阵中位置为(fi,j)的点是由第i个内核与词w中列向量[cj,cj+1,…,cj+k-1]对应位置数乘之和加上一个偏差bi得到。卷积完后再经过池化层,本模型中采用最大池化。对这个f×(n-k+1)的矩阵的每一行取最大值,就变成一个长度为f的向量。由于有不同宽度的内核,每个宽度f取值不同,得到的向量长度不同。最后将这些不同内核的向量拼接成一个向量。如图1所示,第一组内核的宽度k取2,个数f取3,经过卷积和池化得到一个长度为3的向量。最后拼接得到一个长度为11的向量。
经过CNN每个词都会得到一个向量。在文本分类领域,CNN展现了不错的性能。由于语种识别很大程度上受到文本分类的影响,所以模型采用了CNN。本模型中每个词以n×d矩阵为输入,由于CNN局部感知的特性,能很好地提取词本身的信息。内核在矩阵上滑动进行卷积的过程可以模拟成基于字符生成一个N-Gram单元,内核宽度k,类似于取k-Gram。所以本模型能很好地提取词本身的信息。
2.2 循环神经网络
循环神经网络(Recurrent Neural Network,RNN)相比于CNN,它在处理序列问题方面有很好的优势。比如基于时间序列:一段连续的语音序列,一段连续的文字序列等。由于RNN采用时序反向传播算法,如果训练文本的长度较长或者时序t较小,会出现长期依赖问题。而LSTM通过引入门控单元和线性连接,能解决RNN中出现的梯度消失问题。鉴于此,本模型在构建时选用了LSTM替代循环神经网络。LSTM在时序t的输入是Xt,ht-1是前计算单元的隐藏层的输出,ct-1是前计算单元的历史信息,输出是ht和ct,而it、ft和ot分别对应t时的输入门、遗忘门和输出门,gt是实际加载当前单元的信息,ct是在t时更新后的信息。计算过程如下:
it=σ(WiXt+Uiht-1+bi)
(2)
ft=σ(WfXt+Ufht-1+bf)
(3)
ot=σ(WoXt+Uoht-1+bo)
(4)
gt=tanh(WgXt+Ught-1+bg)
(5)
ct=ft×ct-1+it×gt
(6)
ct=ot×tanh(ct)
(7)
式中:W、U是神经网络的权重系数;b是偏移系数;σ和tanh都是神经元激活函数。在实验时可以根据效果调整LSTM层数,如果是双层LSTM,那么第二层的输入it就是第一层的输出ot。
模型中,前面CNN的输出作为LSTM的输入,由于每个词经过CNN后都有一个对应的向量(可看作经过CNN可以生成对应词的词向量)。故LSTM实际上是以词作为输入,能很好地获取句子中词与词之间的信息。
2.3 全连接层(分类模型)
在本模型中,考虑到语种识别相当于一种特殊的分类问题,所以LSTM层后接了一个全连接层。LSTM每个神经元的输出将作为全连接层的输入,全连接层可以把通过CNN和LSTM提取到的信息综合起来。全连接层在神经网络中相当于一个分类器,对之前的卷积层、池化层、激活函数、循环神经网络的结果进行总结,再次进行类似于模板匹配的工作,抽象出神经元个数的特征存在的概率大小,得到各个特征,最终得到最后一层的神经元个数的特征。当然也可以认为是对于之前的卷积层和池化层,循环神经网络之后得到的特征进行加权和。在神经网络中加入全连接层,可以使得网络的容错性增加,同时加入全连接层带来了计算量的增加,所以全连接层的输出值被传递给下一层,最后采用逻辑回归(softmax regression)进行分类:
(8)
式中:yi是上层的输出;j是总的语种识别类别中任意一个类。
在本模型中类别由相似语言的语种个数决定。由于数据集选取的都是区分两种相似语言,所以本模型在实验中要解决的问题是二分类问题。
3 实验设计和分析
3.1 实验平台
为了验证该模型在相似语言短文本的语种识别效果,使用了两个数据集对相应模型进行了对比实验。第一个数据集是相似语言维吾尔语和哈萨克语语料,基线是N-Gram模型;第二个数据集是DSLCC v4.0中的两组相似语言,基线是CNN文本分类模型。
3.2 维吾尔语和哈萨克语语料
本模型主要针对的是相似语言短文本的语种识别应用,所以要选择相似语言的语料。相似度越高,识别难度越大,而且训练语料越大效果越好,所以最好选择活跃的相似语言。在新疆地区,维吾尔族和哈萨克族等少数民族聚居,在日常生活中经常发生两种语言共现的情况。维吾尔语和哈萨克语都属于阿尔泰语系,共用很多字符和词,相似度高,且使用频繁方便大量获取。在新疆地区和同属于阿尔泰语系的一带一路沿线地区,实现基于维语和哈语的语种识别具有很大的现实意义。所以本文选取维语和哈语作为一组对照试验语料。
通过网站爬取实验语料,主要选择两种语料:新闻语料和论坛语料。新闻语料是规范文本,论坛语料则更接近口语文本。经过爬虫在两种语料中分别获取了相对均衡的维语数据和哈语数据。其中,文本中的一个句子表示一个样本。
爬取文本后,考虑到可能出现乱码和错误的没有含义的字符,统一对语料进行预处理,删除了句子长度小于7个字符的样本。
由于文本越短,识别准确率越低。在模型LSTM层实际是以句子中的词作为输入,LSTM长度也是以样本中最长句子数为长度。本模型主要针对的是短文本,所以在语料预处理时删除了长度大于20个词的句子。考虑到文本长度的影响,对语料每个句子中的词数做了统计,如图2和图3所示。

图3 论坛语料句子词数的箱型图
图2是新闻语料的句子词数的箱型图,可以看出新闻语料中75%的句子的词数都不大于16,一半句子的词数都不大于14。图3是论坛语料的句子词数的箱型图,可以看出论坛语料中75%的句子的词数都不大于12,一半句子的词数都不大于8。整体上,新闻语料的句子长度大于论坛语料。从表1的实验结果也可以看出句子较长的新闻语料识别准确率更高。
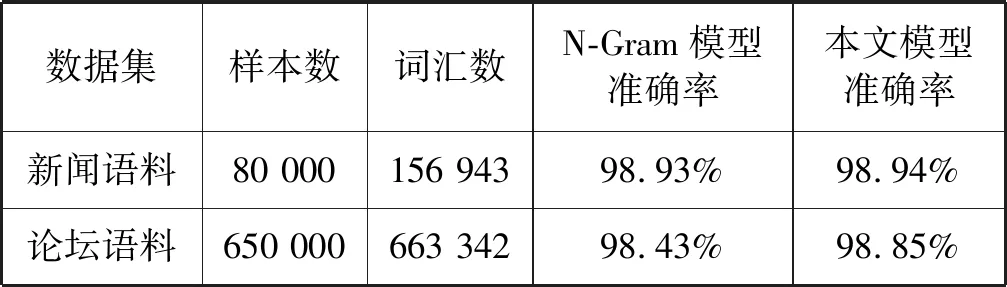
表1 在维吾尔语和哈萨克语语料上的实验结果
语料预处理时,会将标点、数字这些无效的字符用空格字符代替。并且每个词的开始结尾部分添加“#”字符向量标明字母开始结束位置。同理,每个句子的结尾添加“#”的词向量标明句子结束。LSTM为定长,句子词数不足时用空格词向量补齐。
作为对比实验,表1中的N-Gram模型是根据Langid原理,字符级的基于N-Gram语言模型和多项式贝叶斯分类器实现的语种识别模型。一般N-Gram语言模型中的N越大,结果越好,但训练时间越长,系统消耗也越大,综合效果与效率,在新闻语料中当N=7时准确率已经没有明显提升,在论坛语料中当N=5时准确率已经没有明显提升。为了保证准确率,选取较大的N时,N-Gram模型将比神经网络模型消耗更多(包括计算空间和时间),且如果出现字符数小于N的未登录词时,传统的N-Gram可能无法识别,但神经网络模型却不会有未登录词问题(类似N-Gram语言模型的平滑问题)。
从表1中可以看出,在维语和哈语的识别上,对新闻语料和论坛语料,本文模型相对于传统的N-Gram模型准确率都有提高。且本文模型结构简单,对语料无论句子长短都有效果,可用于短文本语种识别。
3.3 DSLCC v4.0语料
DSL2017是相似语言和方言自然语言处理会议(Proceedings of the Fourth Workshop on NLP for Similar Languages,Varieties and Dialects,VarDial 2017)公布的比赛任务,针对不同任务均提供了语料。DSL2017的语料包含6组相似语言或方言。提供的语料是新闻文本的小节选。DSLCC v4.0是DSL2017的语料。
鉴于本文模型主要是对相似语言的识别,所以没有选取方言,选了印度尼西亚和马来西亚语(Indonesian,Malay)、波斯和达里语(Persian,Dari)这两组相似语言。由于这6组语言语料混合,所以需要通过标记挑选出实验需要的两组语料。
从DSLCC v4.0挑选出的两组相似语言因为都是新闻语料,是规范文本,所有没有删除7字符以下可能的乱码样本,且这些语料都是短小的新闻节选。从图4和图5中也可以看出,句子词数都不超过20,符合短文本的要求,故不需要删除长样本,其他处理和维哈语料相同。
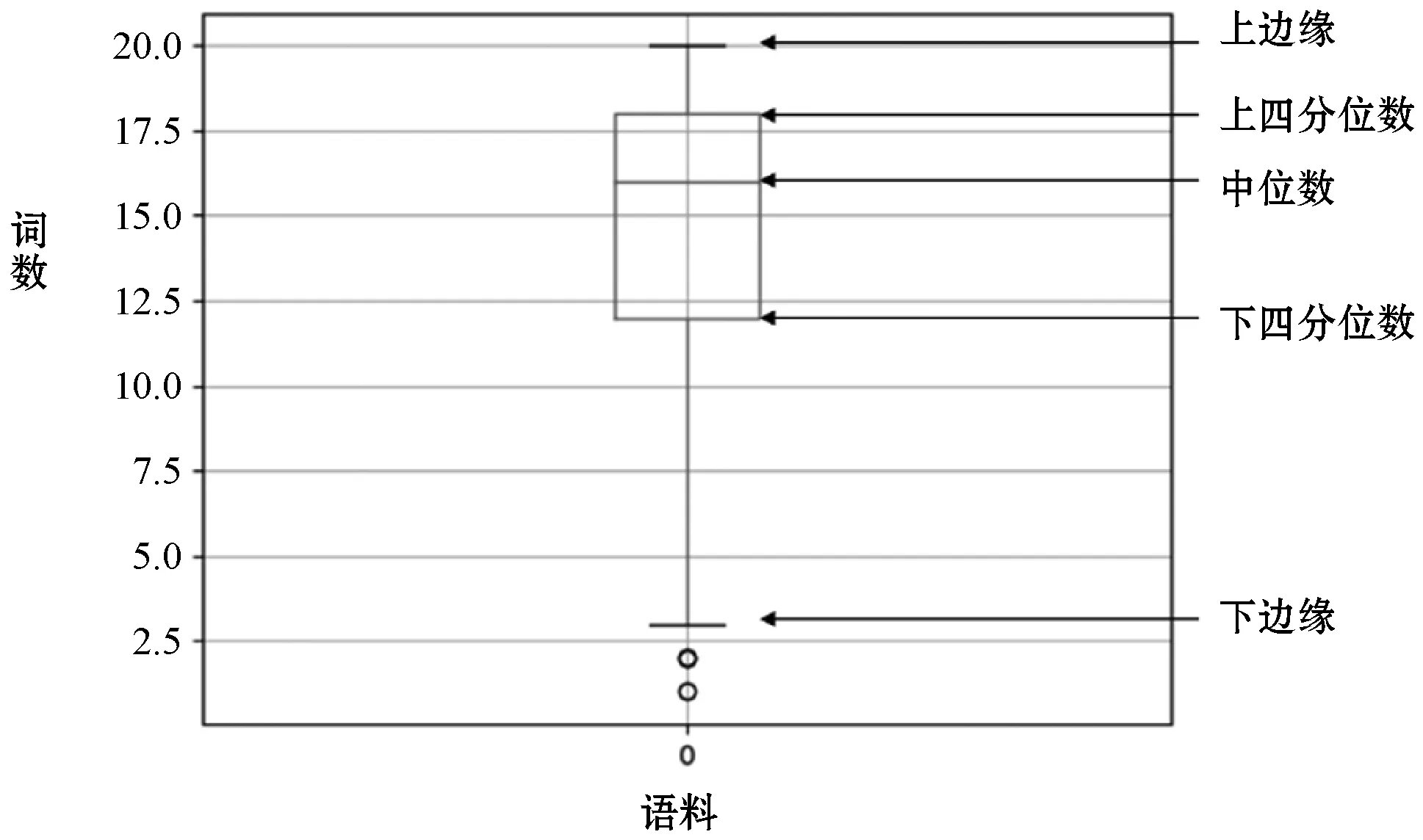
图4 印度尼西亚和马来西亚语料词数箱型图
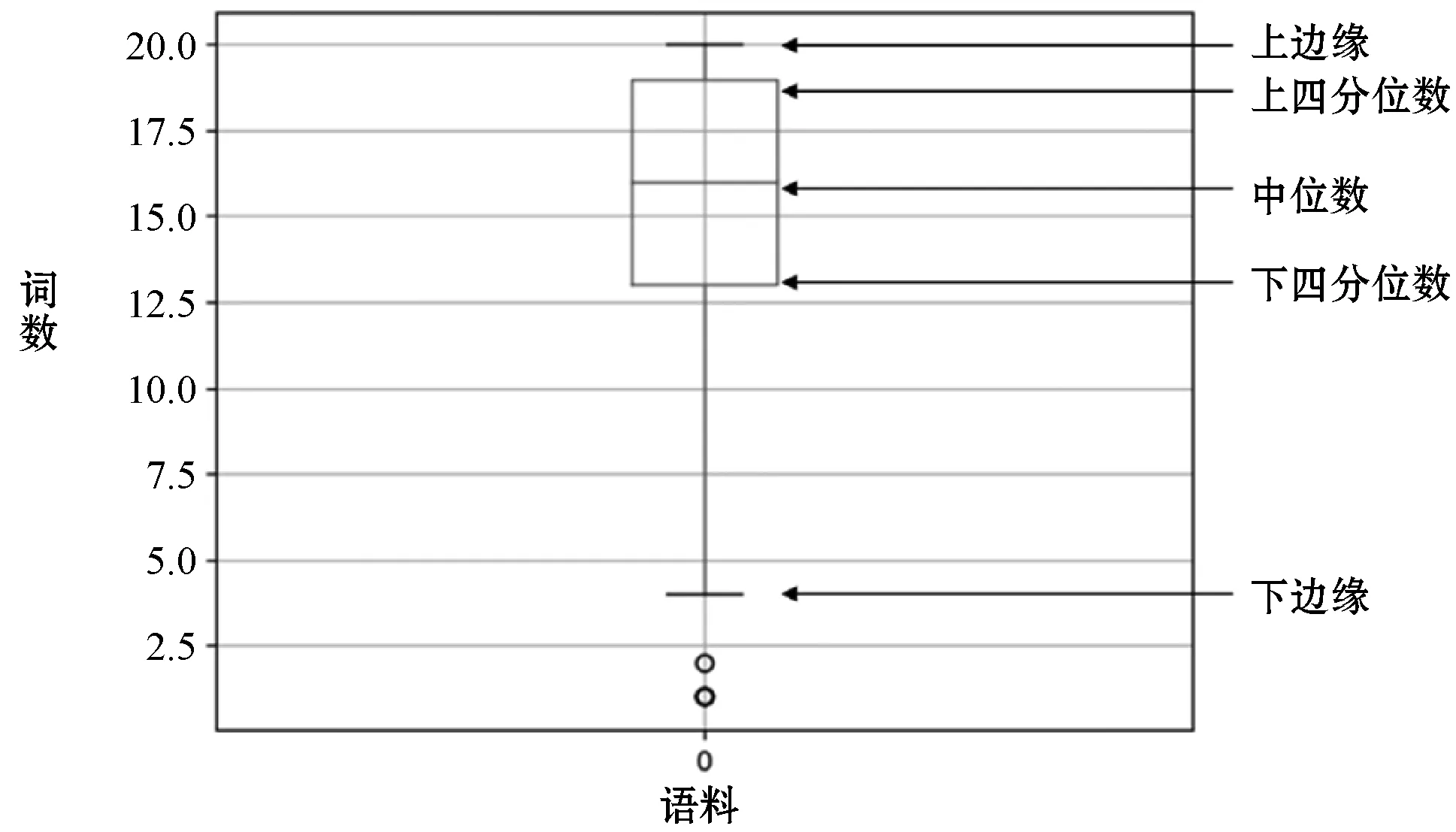
图5 波斯语和达里语语料词数箱型图
对比实验时,表2中的CNN模型是以Kim(2014)对句子分类的卷积神经网络文本网络[21]为原型的简单复现模型。实验结果表明:针对印度尼西亚和马来西亚语(Indonesian,Malay)、波斯和达里语(Persian,Dari)这两组相似语言,且语料较小时,相比于CNN模型,本文模型能得到更高的准确率。因此,本文模型在相似语言短文本的小语料上仍然有效。
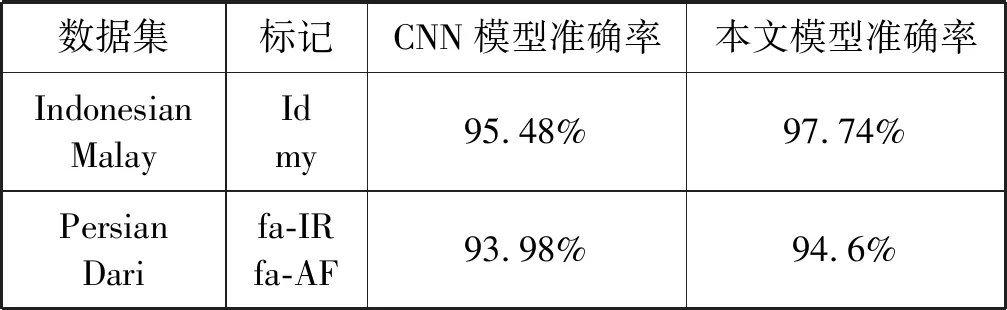
表2 DSL语料上的实验结果
3.4 实验结果分析
不同语言在两个数据集上的实验结果表明:相比传统的N-Gram语种识别方法和神经网络方法,本文提出的方法对相似语言短文本的语种识别性能更好。由于本模型的最小粒度是字符,比基于词级别的语种识别方法能更好地识别未登录词,而且模型对语料有一定依赖性,在大规模语料上效果更好。另外,LSTM采用定长的神经元处理句子,如果语料中样本句子词数很小,则利用空格补齐,在一定程度上会影响实验性能。
4 结 语
本文针对相似语言短文本,提出了一种基于神经网络的字符级语种识别方法。首先,利用CNN提取字符组合的特征信息,可以更好地处理未登录词,并生成每个词的特征向量。然后,将生成的词向量输入到LSTM网络中,即可获得词与词之间的信息。最后,在两组语料上进行实验,结果表明本文方法可提升相似语言短文本的识别准确率。但由于神经网络往往需要大规模语料保证效果,因此语料较大时训练时间较长。下一步将考虑加入语言语法信息,从而进一步优化完善模型。
猜你喜欢
现代计算机(2021年33期)2022-01-21
电脑报(2021年41期)2021-11-04
电脑知识与技术(2019年29期)2019-12-16
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
电脑爱好者(2019年8期)2019-10-30
未来英才(2017年24期)2018-01-23
农机使用与维修(2014年10期)2014-10-23
高中生·天天向上(2009年11期)2009-12-17
教学与管理(理论版)(2009年9期)2009-11-04
