
结合通信重排和消息合并的通信调度方法研究*
2020-03-04 08:20彭晋韬刘青凯
计算机工程与科学 2020年2期
彭晋韬,杨 章,2,刘青凯,2,张 倩
(1.北京应用物理与计算数学研究所,北京 100088;2.中国工程物理研究院高性能数值模拟软件中心,北京 100088)
1 引言
大规模数值模拟在武器物理、激光聚变等重大领域有着重要的作用。当前高性能计算机即将进入E级计算时代,更大的计算规模和更加复杂的网络通信对数值模拟应用形成了新的挑战。大量并行应用可能会由于网络拥塞的发生而使通信性能下降[1]。所以,如何通过调度算法来减少拥塞从而提高网络资源利用率,对并行应用有着重要意义。
有一种避免拥塞的通信优化方法是基于通信重排调度来实现的[2]。通信重排是通过重新排列每个通信请求的发出顺序来达到改善网络拥塞的效果。文献[3]通过重排RDMA(Remote Direct Memory Access operations)通信请求的发出顺序来改善网络通信性能。这一工作研究了2个不同消息大小且不同目的地的RDMA请求的最佳排列顺序,以更好地重叠通信初始化和网络传输过程,并将其应用到多个通信请求的重排列算法中。而从预防拥塞角度来看,通信重排在2D-stencil通信模式中可以达到10%~50%的性能提升[4]。但是,通信重排对于小消息主导的通信的作用几乎可以忽略,而且大量的小消息带来的算法开销此时又不可忽略,这成为了重排技术的重要缺陷。除了通信重排以外,在应用层缓解网络拥塞的办法还有限制节点同时传输的消息数量和正在通信的CPU核数。实验表明,对于all-to-all模式的通信模式能达到2倍的通信性能提升[5]。
消息合并是一种经典的网络通信优化方法。其主要原理是通过将细粒度的消息合并成1个大消息来减少网络延迟对通信的影响。消息合并已经有了非常广泛的应用并且很多应用取得了很好的成效[3,6 - 10]。文献[7]在其PGAS(Partitioned Global Address Space)语言上对小消息的远程内存访问请求进行合并。但是,消息合并在大消息方面难以取得成果。因为一方面,当大消息主导通信时通信延迟的占比往往很低,所以使用消息合并优化延迟的意义不大;另一方面,对大消息进行消息合并带来的合并开销不可忽略,会占用很大的内存带宽。

Figure 2 Technical route图2 技术路线
所以,结合通信重排和消息合并的方法不仅可以解决重排技术对于小消息的无奈,而且还可以解决消息合并难以对大消息产生效果的困难。本文从通信调度的角度提出一个针对异步点对点通信的新的调度算法。该算法结合消息合并与通信重排来达到减缓拥塞和降低延迟的目的。基于“天河二号”超级计算机验证了该算法对于几个数值模拟应用的优化效果,实验表明,本文算法最高可以提升41%的通信性能。
2 问题描述和技术路线
如图1所示,本文的问题是给定1个点对点消息的集合,如何通过消息重排和消息合并减少该组消息的通信时间。点对点通信是并行应用中使用最广泛的通信方式,在典型的BSP(Bulk Synchronous Parallel)模型中,进程在每个超级步都需要操作远程数据,每个超级步都会产生一批异步点对点通信集合。本文的调度算法就是针对这样的消息集合进行优化。

Figure 1 Problem description图1 问题描述
图2展示了本文算法采用的技术路线。本文算法分为2部分。第1部分为重排算法。即对于1组有序消息集合M=〈m1,m2,m3,…,mn〉,其初始顺序为这组消息原本的调用顺序。本文首先通过1个重排双射映射f(x):{1,2,…,n}→{1,2,…,n}将原本的有序消息集合M转化为M′=〈mf(1),mf(2),mf(3),…,mf(n)〉。第2部分为消息合并,即通过1个负责消息合并的满射映射g(x):{1,2,…,n}→{1,2,…,m}(m≤n)将n个消息映射到m个消息,以完成合并。最后,在运行时进行流水线式消息合并,以掩盖合并的开销。
3 通信重排算法
本文的通信重排算法基于下述几点启发:
(1)关键通信应当尽早完成。
(2)更早发送的消息在通信竞争中占有优势并且受到网络拥塞的影响更小。
(3)短通信距离的消息有更高的优先级。
基于以上3点启发,设计1个排序函数,从而决定消息发送的先后顺序。
对于关键通信,如图3所示,我们用有向图表示进程通信图,其中V为进程集合,E为消息集合。类似地,我们使用G′(V′,E′)表示节点间的通信集合,其中V′为节点集合,E′为节点间通信的集合。有向边e(e∈E′)的权值为其连接的节点之间的总通信量。图3为进程通信图和节点通信图的复合视图。基于G和G′可以定义节点对NPs(Node Pairs)和进程对PPs(Process Pairs)表示1对有序节点/进程。关键通信在本文中是1个进程对PPmax(s,e),其定义为在某一节点对内开始节点的总发出消息大小和接收节点的总接收消息大小的最大值。

Figure 3 Communication graph图3 通信图
结合启发(2)和(3),设计1个评估节点对的权重函数用于将短距离通信放在更高的优先级,并组合进程对间的权重函数形成排序所用的比较函数。对于1个节点对〈A,B〉,该节点对的通信距离定义为|A-B|。
基于关键通信和通信距离的定义,开始介绍算法的具体细节。本文算法伪代码如算法1所示。
算法1通信重排算法
输入:节点间通信图G′,进程间通信图G。
输出:有序进程对排列OdrArr。
1. functionReorder(G,G′)
2.OdrArr=InitInternodeProcessPairs(G);
3.SORT(OdrArr,ProcPairCmp);
4. returnOdrArr
5. end function
6. functionProcPairCmp(PP1,PP2)/*PP1,PP2是进程对,ProcPairCmp为排序的比较函数*/
7.NP1=GetNodePair(PP1);/*获取该进程对所在的节点对*/
8.NP2=GetNodePair(PP2);
9.W′1=NodePairWeight(NP1);
10.W′2=NodePairWeight(NP2);
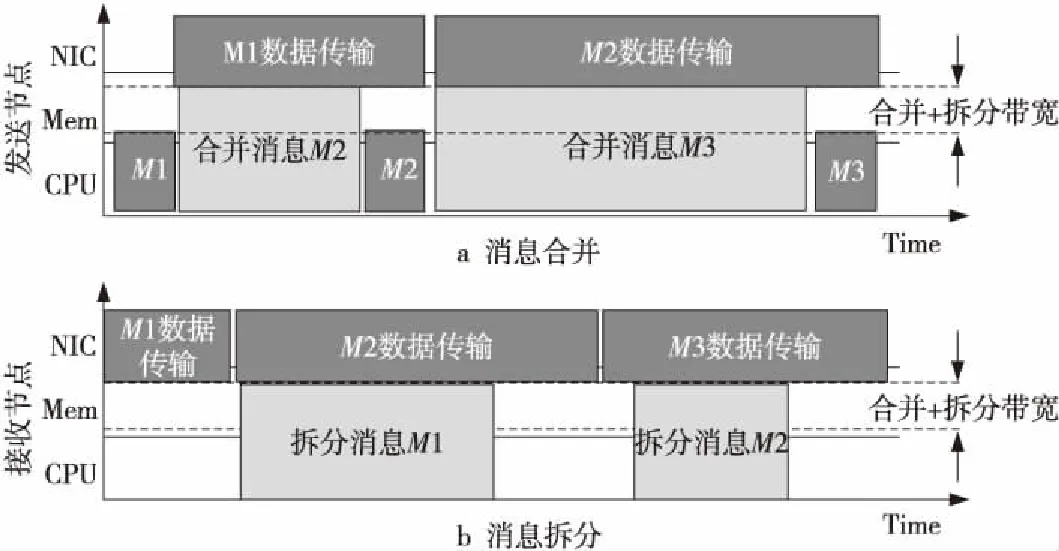
11. ifW′1 12. return False; 13. else ifW′1>W′2then 14. return True; 15. else//当W′1=W′2时 16.WP1=ProcessPairWeight(PP1); 17.WP2=ProcessPairWeight(PP2); 18. end if 19. returnWP1≥WP2; 20.end function 21.functionProcessPairWeight(PP)/*进程对的权重函数*/ 22.out=TotalSendMsgSize(PP.StartProcess); 23.in=TotalRecvMsgSize(PP.TargetNode); 24. returnMAX(out,in); 25.end function 26.functionNodePairWeight(NP)/*节点对的权重函数*/ 27. return |NP.TargetNode-NP.StartNode|; 28.end function 图4所示为本文算法流程图。算法先利用消息集合初始化节点间通信图和进程间通信图。接下来则是排序过程。排序的核心是比较函数。从图4中可以看出,比较函数首先根据进程对所在节点对的通信距离来决定粗粒度的消息顺序,对于属于同一节点对的消息则以其进程对的权重决定消息最后的传输顺序。注意到排序之后属于相同节点对的消息在发送顺序上都是相邻的。这有利于后续的消息合并。 Figure 4 Flow chart of rearrangement algorithm图4 重排算法流程图 通过消息重排获得了消息的优先级顺序,该信息描述了进程发送消息请求的顺序。在这一节,会以流水线的方式动态地合并和拆分消息。 虽然高性能计算机网络经过了多年发展,但是网络提升速度却不及内存性能提升的速度,而内存提升的速度又落后于计算性能提升的速度。对于网络自身而言,带宽提升比例又高于延迟提升比例。对于一些在过去的高性能计算机上运行的并行程序而言,网络性能提升落后于计算性能提升会导致通信开销在应用程序开销中占比提高。而带宽提升速度高于延迟则会导致应用程序的通信开销中延迟开销占比提升。所以,消息合并的需求变得很重要。 传统的消息合并是利用网络延迟大小的时间来进行消息合并,以掩盖延迟。本文消息合并的基本原理是利用节点的总内存带宽和网络带宽的带宽差来合并消息。内存总带宽常常为网络双向带宽的数倍,所以在前1个消息传输的时候进行消息合并,可以合并出1个比上1个发送的消息更大的消息。这样做有2个优点:其一通过消息合并能降低延迟的占比;其二是进行流量整形,因为每次合并出来的消息大小都会等比地大于上次发出的消息,这使得消息大小呈指数型增长,越大的消息往往有着更高的网络带宽利用率。这种做法带来的缺点是消息合并和拆分的内存带宽占用会大于传统的固定大小的消息合并的内存带宽占用。 Figure 5 Diagram of message aggregation/restore space-time图5 消息合并/拆分时空图 具体而言,某一进程A的消息合并时空图如图5所示。进程A发送的第1个消息M1是按照优先级排列而来的第1个消息。消息M1的初始化需要部分内存带宽和CPU资源。当完成M1的初始化后,M1交由网卡负责消息传输。M1在传输过程中占用了网卡和部分内存带宽资源。此时CPU处于空闲,那么利用这段空闲的时间进行消息合并。按照排列好的消息顺序依次合并消息。由于内存带宽数倍于网络带宽,所以在M1传输期间能够利用剩余的内存带宽合并比M1大的消息。当消息M2合并完成时则开始M2消息的初始化。为了让M2消息的合并和初始化过程充分与M1消息的传输过程重叠,M2的合并消息大小需要谨慎选择,合并的消息太小会影响消息合并的效果,而合并太多的消息则会带来过高的内存拷贝开销。最合适的消息合并大小是能使得M1的传输时间和M2的合并以及初始化时间之和相等。本文采用的方法是指数级增大消息合并窗口。这里消息合并窗口即为图5中浅灰色区域。如M2的合并窗口为|M2|,也就是消息M2的消息大小。对同一节点对〈i,j〉内连续合并后的2个消息满足αij=|Ma|/|Ma-1|。其中αij为节点i和节点j之间的消息合并增长因子。Ma,Ma-1属于节点对〈i,j〉之间的消息,或者Ma-1为节点对〈i,j〉间的第1个消息(注意到消息经过重排之后来自相同节点对之间的消息在发送顺序上是相邻的)。αij满足以下公式: αij=1.5+log2Max(NDOuti,NDlnj) 其中,NDOuti为节点i在节点间通信图上的出度,NDlnj为节点j在节点间通信图上的入度。可以看到,当节点i对外的出度或者节点j的入度很高时,由于更多的通信竞争,所以通信时间会变长,此时可以合并更多的消息。接收方对接收到的消息也进行流水线式拆分。当接收到第1个消息M1之后,经过一小段时间间隔接收节点开始拆分M1。与此同时,网卡仍然在接收消息M2,其流水线过程与发送消息类似。 使用基于胖树网络的“天河二号”超级计算机作为实验平台。天河2的每个节点上有2颗Intel Xeon E5-2692 v2处理器并配备8通道DDR3内存,使用TH Express-2 互连网络,该网络能提供16 GB/s的双向带宽。 在通信负载的选择上,基于几个真实应用并收集它们的节点间点对点通信。这些收集而来的通信作为本文算法的输入。本实验使用的应用信息如下所示[11]: (1)Ascent 软件是1款PIC(Particle-In-Cell)软件。它用于模拟惯性约束聚变黑腔中激光等离子体相互作用过程中的电子能量传输。 (2)Jems_td是1款三维时域全波电磁模拟应用。它主要应用于电磁环境模拟、电磁特性分析以及电磁兼容性分析等方面[5]。 (3)Jsnt 是1款三维中子-光子耦合离散纵标输运软件。这个软件被用于反应堆屏蔽计算和堆芯物理分析。 (4)Lap3d是1个激光聚变应用软件。该软件可以模拟激光在等离子体中传播造成的不稳定过程[5]。 (5)Lareds同样是1个应用在激光聚变模拟中的软件。主要用于模拟辐射流体力学界面不稳定性[5]。 (6)Moasp是1个分子动力学模拟软件。该软件已成功应用于反应堆包壳材料的辐照损伤模拟。 本文实验设置了1组实验组和对照组,如图6所示,对照组直接调用通信接口完成数据传输,而实验组则在重排之后使用基于优先级的消息合并进行数据传输。 Figure 6 Experimental group and control group图6 实验组与对照组 实验结果如图7和图8所示,当使用4个节点的时候,结合通信重排与合并的方法实现了平均12.59%的通信性能提升;而在使用16个节点时,对6个应用平均实现了11.27%的通信性能提升。 Figure 7 Performance improvement and time overhead on 4 nodes图7 4个节点上的性能提升和时间开销 Figure 8 Performance improvement and time overhead on 16 nodes图8 16个节点上的性能提升和时间开销 本文研究了基于消息聚合和通信重排的方法,该方法一方面通过对大消息进行重排以减缓拥塞;另一方面对消息进行合并以降低延迟,从而实现了应用通信性能提升的目的。 接下来,将扩展本文工作,通过1个点对点通信模型在不同平台上验证通信重排对于网络拥塞的影响。
4 基于优先级的消息合并
5 实验及结果



6 结束语
猜你喜欢
石油化工自动化(2020年1期)2020-03-05
中国外汇(2019年20期)2019-11-25
电脑报(2019年31期)2019-09-10
通信技术(2019年8期)2019-09-03
当代陕西(2019年13期)2019-08-20
中国外汇(2019年8期)2019-07-13
中国循证儿科杂志(2019年2期)2019-06-04
电脑爱好者(2015年21期)2015-09-10
浙江理工大学学报(自然科学版)(2015年7期)2015-03-01
民主与科学(2014年3期)2014-02-28
