
基于神经网络的自然场景方向文本检测器*
2020-03-04 05:12周铂焱
计算机与数字工程 2020年1期
周铂焱 杨 鹏
(南昌航空大学信息工程学院 南昌 330000)
1 引言
场景文本检测是自然场景中最普遍的视觉对象之一,经常出现在路牌、车牌和产品包装袋等上。虽然和传统的OCR相似,但由于前景文本和背景对象的多样性,任意方向和长宽比,以及不可控的光线条件等,场景文本阅读更具挑战性。如文献[1]中总结的一样,由于这些不可避免的挑战和复杂性,传统的文本检测方法通常包含多个处理步骤,例如候选字母或单词的产生[2~4],候选词的滤波[4]和分类[5]。它们通常很难使得每一个模块恰当的工作,微调参数和设计优化规则需要花费更多的努力,同时也降低了检测的速度。
本文主要受最近目标检测SSD[6]和场景文本检测 TextBoxes[8]的启发。TextBoxes[8]是一个可进行端到端训练的全卷积神经网络。根据SSD[6]中的匹配策略,将预先设定的一系列不同长宽比的水平矩形默认框与真实目标框进行匹配,通过Text-box层[8]同时预测文本存在和 anchor boxes[7](也叫默认框[6])的坐标偏移,将Text-box层所有输出合并后进行非极大值抑制(NMS)处理,从而输出最终的文本检测结果。

图1 示例图
TextBoxes[8]是一个快速、有效的的场景文本检测器。但存在两个不足:1)TextBoxes[8]只能有效检测水平方向的场景文本,然而现实中由于拍摄角度的问题,图像中的文本通常呈现出任意的方向性,如图 1(a)。针对这类图像中的文本,TextBoxes[8]则不能进行有效检测,如图1(b)所示的预测框不能很好的覆盖文本区域(实线框区域为真实文本框区域,虚线框为预测框)。文本检测的目的是为了识别,这将大大降低后期的识别率;2)TextBoxes[8]中一系列不同长宽比的默认框是通过手工精选预先设置的,不能很好地表示真实文本先验,一些长宽比的文本框不能和任何默认框进行匹配,导致场景文本召回率偏低和漏检。
本文主要在 TextBoxes[8]的基础上,针对以上两个方面问题进行改进:1)设计默认框四边形的表示,将水平文本检测器改进为任意方向文本检测器;2)对默认框的先验维度进行聚类,使网络更容易学习到准确的预测位置,提高召回率。
2 面向任意方向的四边形默认框
2.1 垂直偏移的默认框
Text-box层是OSTD主要的部分。Text-box层同时预测特征图中文本的存在和边界框的坐标偏移。通过预测每个位置上预先设计的水平默认框的偏移回归,OSTD的输出包含方向边界框{q},以及包含方向边界框的最小水平边界框{b}。


图2 一个与真实目标框(白色)匹配的默认框(虚线)在3×3的网格上的回归(箭头)示意图
在图像的每一个位置,以卷积的方式输出分类得分和每个表示为的相应默认框的偏移量。对于四边形表示的方向文本,文本框层预测值(Δx,Δy,Δω,Δh,Δx1,Δy1,Δx2,Δy2,Δx3,Δy3,Δx4,Δy4,c),表明一个水平矩形b=(x,y,ω,h)和一个检测置信度为c的四边形表 示 如下:

在训练阶段,根据文献[6]中匹配方案的框重叠区域,将真实单词边界框和默认框进行匹配。如图3中所示,一个四边形的最小边界框矩形和默认框进行有效匹配。在每一个位置,有一些不同纵横比的默认框。用这种方式,我们可以根据纵横比来有效地划分单词,允许OSTD学习特定的回归和分类的权值,这些权值可以划分相似纵横比的单词。
文本在某些区域通常是密集的,所以每个默认框都设置了垂直偏移[8],以更好地覆盖所有文本,这使得默认框在垂直方向上是密集的。
2.2 任意方向四边形预测框的表示
对于四边形表示,我们改变真实目标的方向文本表示如下。对于每一个方向文本真实目标四边形边界框T,设水平矩形真实目标为h~b0)(即T的最小水平矩形包围),其中的中心点,ω分别是G的宽和高。根据等式b(1)这个矩形真实目标也可以表示为b3,b4),其中 (b1,b2,b3,b4)是 Gb顺时针顺序的四个顶点,b1为左上方的顶点。我们用方向文本真实目标T的四个顶点来表示T,对于一个一般的四边形 文 本 边 界 框 可 表 示 为四个顶点 (q1,q2,q3,q4) 也按顺时针顺序排列,使得四个点对 (bi,qi),i=1,2,3,4之间的欧式距离之和最小。更准确地说,让顺时针方向顺序的表示同一四边形文本边界框,是顶部的点(如果Gq是矩形,则为左上方的点)。然后,q和之间的关系如下:
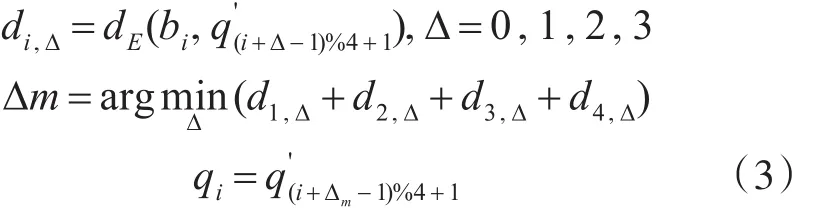
其中,dE(b,q')是两点间的欧氏距离,Δm是Gb和Gq之间对应的四个点对的最小距离和的位移。
3 默认框维度聚类
TextBoxes[8]中的预设默认框尺寸是手工挑选的,根据YOLOv2[9],我们不是通过手工精选先验框,而是通过k-means聚类得到。
由于卷积神经网络具有平移不变性,且默认框的位置被每个网格固定,因此我们只需要通过k-means计算出默认框的width和height即可。将默认框的width和heigh转换为相对于网格边长的比例。转换公式如下:

其中ωd和ωi分别是默认框和输入图像的宽,ha和hi分别是默认框和输入图像的高,dsr为网络的降采样率。
因为使用欧氏距离会让大的边界框比小的边界框产生更多的错误,而我们希望能通过默认框获得好的IOU得分,并且IOU得分与box的尺寸无关。
为此,我们采用新的距离公式:

我们对k的不同值运行k-means,并绘制最接近质心的平均IOU,参见图3,只有6个先验的质心类似于9个手动精选质心,平均IOU为63.1,而9个手动精选质心为61.8。如果我们使用9个质心,我们看到一个高得多的平均IOU。这表明使用k-means生成边界框以更好地表示开始模型,并使任务更容易学习。我们选择k=6作为模型复杂性和高召回率之间的良好权衡。
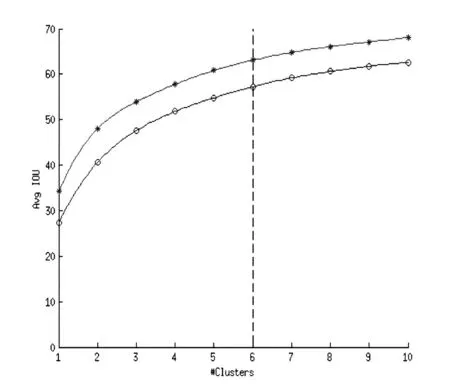
图3 手工精选与聚类对比图(其中*表示K-means聚类的结果,〇表示手工精选的结果)
4 实验
OSTD可以检测任意方向的文本。我们在ICDAR2015 Incidental Text数据集[16]上测试它的性能。此外,SynthText[10]数据集被用来预训练我们的模型。
我们在ICDAR2015 Incidental Text数据集上,将OSTD和当前最先进的方法之一EAST[13]和另一个最相关的方法DMPNet[14]等进行了对比,以评定它处理自然图像中任意方向文本的能力。
表1中给出了标准评估协议的定量结果。由于使用了先验聚类,除了 Shi et al.[12]外,OSTD的召回率优于所有先进的结果,且综合性能比[14]提升了2.8%。
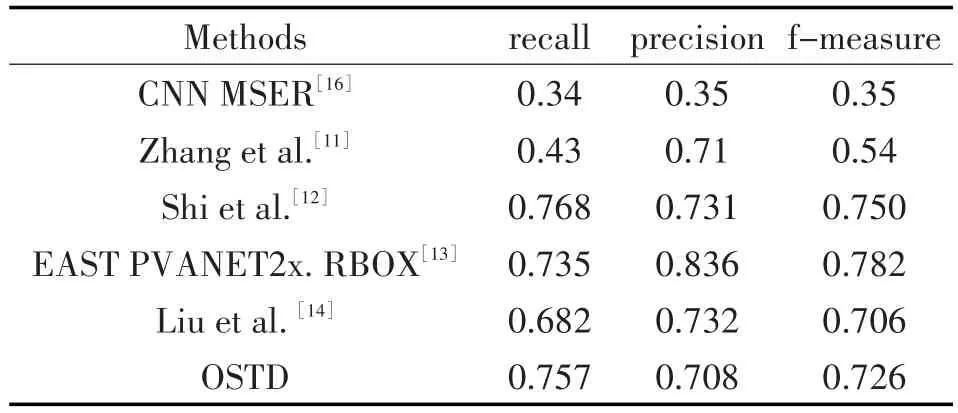
表1 基于ICDAR2015 Incidental Text(IC15)的性能评估对比
OSTD不仅准确而且高效。我们在ICDAR2015 Incidental Text(IC15)数据集上,就运行速度和其他先进方法进行了对比。如表2所示,OSTD获得了0.726的f-measure和10.3FPS的成绩。相比于其他方法,在性能和速度两方面取得了更好的平衡。在图4中展示了一些OSTD的检测结果。

表2 基于ICDAR2015 Incidental Text(IC15)的检测速度和性能对比

图4 OSTD检测结果
5 结语
本文提出了可以用于任意方向文本检测的端到端全卷积网络OSTD,其可以在杂乱的背景下,十分高效和稳定地进行文本检测。该方法通过一种新的、四边形表示的回归模型,直接预测任意方向的词边界框。通过在ICDAR2015 Incidental Text数据集上的综合评估和对比,明确表明了OSTD的优势。将来,我们计划研究几乎所有先进文本检测器所面临的常见失败案例(例如,大字符间距和垂直文本)。
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
测控技术(2022年4期)2022-04-27
北京航空航天大学学报(2021年4期)2021-11-24
中学生数理化·八年级数学人教版(2020年4期)2020-10-29
电子技术与软件工程(2019年8期)2019-07-16
中学生数理化·教与学(2019年5期)2019-06-06
科技风(2018年15期)2018-05-14
中学生数理化·八年级数学人教版(2017年4期)2017-07-08
福建中学数学(2016年4期)2016-10-19
