
基于神经网络机器翻译模型的英文分词研究*
2020-03-04 05:12陈祖君
计算机与数字工程 2020年1期
陈祖君
(西安培华学院国际教育学院 西安 710000)
1 引言
由于神经网络被发现可以进行语义的理解和分析,其在自然语言处理领域得到了广泛的应用。由循环神经网络演化而来的神经网络机器翻译模型(Neural Machine Translation,NMT)可以综合语言的语法、语义以及连贯性等方面进行机器翻译、语义提取、文本摘要等任务[1]。神经网络机器翻译模型是一种基于循环神经网络的机器翻译模型。文献[2]提出了一种新的利用循环神经网络进行序列到序列处理的模型,并把这个模型应用到英语-法语翻译任务之上,取得了比基于短语的机器翻译模型更高的BLEU分数。模型主要通过利用长短期记忆循环神经网络(Long Short-Term Memory Recurrent Neural Network,LSTM RNN,本文中将简称为LSTM)生成消化和生成序列的方式完成序列数据处理[3]。在读入相同或相似语义的句子时LSTM网络隐含层的状态向量也相似,据此推导出神经网络可以抽象和处理语义相关的信息。Bahdanau等在论文[4]中对Sutskever等的模型进行改进,加入了注意力机制(Attention Mechanism)和双向循环神经网络,改善了原本模型在处理长句子时性能会出现明显下降的问题,并且通过注意力机制可以获得原始语言和目标语言词汇之间的对应情况。
现代英文的基本语素表达形式是词,一个词可以具有多个字,因此如果希望描述一个句子的语义,需要先将句子分词分为表达单一含义的词。分词任务本身可能产生歧义,分词就是具有动词及形容词二者特征的词,尤指以-ing或-ed,-d,-t,-en或-n结尾的英语动词性形容词,具有形容词功能,同时又表现各种动词性特点。并且因为之后的处理结果都会以分词结果为基础会造成分词错误传播,所以英文分词的效果会对NMT模型最终的结果产生很严重的影响。
本文利用和Bahdanau论文相似的模型构建NMT自动编码器[5],通过实验研究了不同的英文分词方法对于NMT自动编码器文本还原能力和语义提取能力的影响。分词选择包括Google在处理英文时使用的一元分词方法以及当前英文分词领域普遍使用的隐含马尔科夫模型(Hidden Markov Model,HMM)。
2 LSTM神经网络
长短期记忆循环神经网络(LSTM网络)是一种循环神经网络(RNN)[6]。其出现是为了解决普通RNN网络在迭代次数上升之后出现的梯度消失问题。LSTM网络设计了一个在迭代过程中可对状态进行选择处理的“记忆”机制,其结构如图1所示。
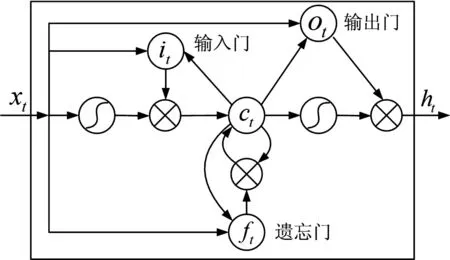
图1 LSTM结构示意图
LSTM神经网络可以分成遗忘门(Forget gate)、输入门(Input gate)、输出门(Output gate)和输入输出神经网络几个部分,各部分的作用可以表达为下式:

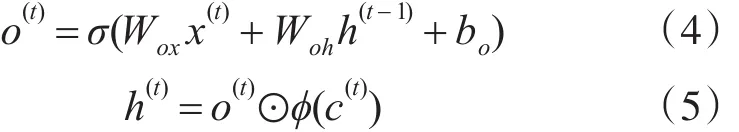
其中,i(t)表示t时刻的输入门输出、f(t)表示t时刻的遗忘门输出、c(t)表示t时刻的细胞状态、o(t)代表t时刻输出门输出、h(t)表示t时刻隐含层的输出数据、φ表示网络神经元激活函数、⊙表示元素乘法(Element-wisemultiply)。
3 神经网络机器翻译模型
3.1 文本预处理
由于采用mini-batch的方法进行神经网络的梯度下降,为此必须要将样本进行batch划分,为了避免填充机制造成短句子进行很长填充干扰编码的问题,本实验采用分桶(bucketing)[7]的方式先将长度相近的句子归于一个桶中,然后每个桶分别产生定长的训练batch。填充机制需要显式使用序列结束符标记序列的结尾。并且在编码器的输入序列最后需要加入解码起始符号,指导解码器开始进行第一个解码位置的输出。
此外,由于英文语料出现相同数字的概率非常小,如果直接保留数字也几乎无法进行准确的输出,因此将语料中出现的所有数字内容统一处理为同一个数字标签,防止由于数字文本的词向量训练不佳导致解码性能下降。
3.2 编码器
编码器负责将输入序列进行编码在网络的LSTM网络的隐含层中。
图2中xi表示输入序列,hi表示编码器输出,对于某一个输入序列,首先通过词嵌入网络将词转换成神经网络词向量。然后,使用LSTM神经网络对词和词周围的上下文内容进行归纳总结,使神经网络可以利用到更多的上下文特征。由于单向LSTM对数据的读取是顺序的,其在读取到某一位置时只接触到单向信息,因此本文采用双向LSTM神经网络进行上下文特征提取。并且由于神经网络深度的增加可以大大降低拟合所需要的时间并提高网络的抽象程度[8],本文使用3层双向LSTM网络作为编码器网络。
编码器网络在每一个序列位置会产生一个对应的输出,在解码时用于编码对应位置的信息参考。此外,整个序列输入完成后产生的LSTM隐含层状态可以认为含有整个序列的相对语义信息,作为解码器网络的初始状态传送给解码器部分。

图2 编码器结构示意图
3.3 解码器
解码器利用RNN的序列生成模型[9]生成序列。RNN序列生成模型根据之前若干时刻的网络输出产生下一时刻的输出。解码器使用单向LSTM神经网络结构。对于单向LSTM编码器而言,将输入序列反向输入会使解码器提供更好的结果[10],因此本文将编码器双向LSTM神经网络中的反向部分隐含层状态作为解码器的初始状态,如图3所示。
解码器序列生成模型可用下式表示:
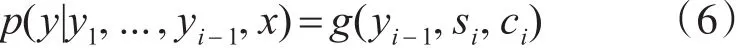
其中,yi代表i时刻RNN解码器的输出向量,x代表原始语言序列,si代表RNN解码器在第i时刻的状态,ci代表i时刻反应在原始语言上下文向量。ci是所有编码器提取的原始序列每一个位置的上下文信息对解码器输出序列位置i造成的影响之和。

图3 解码器结构示意图

式中,Tx代表输入序列的总长度,αij是输入序列第 j位置的上下文对输出第i位置造成影响的权重,hj是编码器产生的对应输入序列第 j位置的上下文向量。

其中,eij代表输入序列的第 j位置对输出序列第i位置的影响分数,a是计算该分数使用的模型。本文使用一个简单的前馈式神经网络作为模型a。αij在得到所有影响分数之后通过对全部分数计算softmax的方式归一化得到。
在NMT模型中加入注意力机制有助于提高系统的性能[11],同时也可以源语言和目标语言词汇在翻译时的对应情况。解码器的输出通过和词库中的词向量进行softmax运算得到,本实验使用贪婪算法作为解码输出算法,即当前的解码仅取决于词库中和当前解码器输出的softmax概率最大的词。
4 实验配置
4.1 模型参数
本实验中将NMT的输入序列和输出序列统一为同一序列,构成基于NMT的自动编码器。词向量采用300维神经网络嵌入词向量,词嵌入模型使用单层前馈式神经网络,在NMT模型的训练过程中一并进行词嵌入神经网络的训练。编码器采用双向3层GRU神经网络,每一方向的神经网络拥有500个GRU单元,且独自向上堆叠,在向上堆叠的过程中不会和反向的神经网络进行数据交换。在顶层直接将双向神经网络的输出粘连作为注意力机制使用的上下文向量。
解码器采用单向3层GRU神经网络,初始状态选择编码器中的反向RNN网络。解码时将上一时刻产生的词的词向量输入解码器,输出时采用Sampled Softmax算法[12]进行输出,以防止由于词库过大时输出需要针对词库中每一个词做softmax运算导致速度过慢的问题。
训练的目标函数采用softmax交叉熵,梯度下降采用ADADELTA算法[13],batch大小为 128。为了防止梯度爆炸,如果网络梯度的2范数超过5,则将梯度标准化到2范数为5。模型初始学习率0.1,并在每一次迭代完整个语料库后降低学习率到原来的一半。如果使用NMT模型生成词嵌入向量,则应尽可能避免在第一次迭代语料库的过程中降低学习率,或者在每次训练之前打乱语料库的排列顺序,否则可能导致语料库靠后位置出现较多的词对应的词向量训练不足,干扰正常的解码过程。
此外,为了防止网络出现过拟合现象,本文将编解码器中所有的神经元输出连接进行了0.3概率的 dropout[14]。
4.1.1 带有英文分词的自动编码器实验
针对英文分词的NMT自动编码器模型采用jieba分词用作英文分词器。jieba分词采用有向图构建分词路径,然后通过动态规划算法[15]寻找基于词频的最大切分组合。对于新词发现,采用了HMM模型进行词性标注的方法解决。语料库的预料首先经过数字和特殊符号过滤,然后进行英文分词并截取词频最高的50000个词训练向量,超出词库的词以特殊的符号(UNK)统一标记。UNK符号数量占比超过10%的句子会被自动丢弃。模型以一个句子作为一个序列,分桶时分为四个桶,最大序列长度分别为10,30,50,70。这种设计可以覆盖语料库中98%的句子。
4.1.2 基于单字的自动编码器实验
基于单字的NMT自动编码器模型中直接将语料库英文本做完数字和符号过滤之后进行单字切分,统计每个符号的出现频率。由于英文实际出现的字相比词而言少很多,只需要保留符号库(包括字、标点符号、英文单词)中频率前10000的符号便可基本覆盖语料库中的所有符号。和带有英文分词的自动编码器一样,超过的符号会以UNK符号代替。
由于一个句子的字数量会比词多很多,因此将四个桶的最大序列长度更改为50,70,90,110。在这种设计下可以覆盖语料库97%的句子。
4.2 实验数据和环境
本文采用新浪2009年到2017年的国内新闻作为语料库。数据总计新闻310327篇,句子7351017句。实验同时将标题和内容作为训练数据,标题作为一个独立的序列样本。
训练采用单张NVIDIA GeForce GTX 1080 Ti显卡。每次语料库的整体迭代训练大约需要4天,平均每个batch的训练时间大约在3s左右。
5 实验数据和分析
5.1 基于一元分词的NMT自动编码器

表1 基于单字的NMT自动编码器输出结果

5.1.1 文本还原情况
基于一元分词的NMT自动编码器表现出了潜在的分词趋向,会将同一个词的几个字变成词首字。但从注意力机制提供的数据中不能看出这个趋向的存在。原因可能是字符进行词嵌入时,没有足够的样本可以分开两个不同的文字,而导致贪婪解码时始终出现的是某个词的第一个字。此外,这个自发产生的分词很容易受到周围字的影响,错误较为常见,原因推测为贪婪输出选择了的非最佳输出再输入解码器时,影响了下一个输出的向量。
短句(30字以下)中出现了句首部分混乱,以及提早出现句子结束符号(End of Sentence,EOS符号)的问题。这种情况只有在需要填充的长度在三分之一以上的情况出现。因此推测可能的原因是相对最大长度最小的桶(本实验为50字)中,句子仍然过短导致填充字符大量存在,干扰句子原本的语义。
5.1.2 语义提取情况
由于字编码的限制,句子含义必须从字嵌入向量提取,而英文中字在不同的词中间可能存在不同的含义,导致编码器提取的语义和句子真正表述的语义有所差异,造成字解码时出现难以理解的错误。例如例句1中的“non-linear”变成了“nonlinear”。此外,针对音译词、外来语、一些缩写词等,基于单字的NMT模型不能给出很好的结果。
总体而言,在文本的还原上,基于单字的自动编码器可以得到相对较好的结果,在处理某些实体名称的情况下会发生错误,尤其是当名称是音译或者简称等不符合语义规则的词汇所表示。
5.2 基于jieba(HMM)分词的NMT自动编码器

表2 基于jieba分词的NMT自动编码器输出结果
5.2.1 文本还原情况
相比基于一元分词的NMT自动编码器,基于HMM分词器的自动编码器的在文本还原上结果不尽如人意,很多关键词和信息的处理均出现了错误。造成这个结果的原因有两个:
1)英文分词器趋向于将一个实体划分成单一的词。如第 2 个例子中,“non-financial”、“ management of the business”这些词均被划分为一个词,然而由于本身在语料库中出现的次数不多,导致这些词没有得到充分的训练,进而造成语义上的模糊,将这些词变换为意义不同的其他词汇,如例子中的“organization”和“institutions”。
2)由于传统的基于HMM或者CRF的英文分词器一般可以进行新词识别,而这些新词在词库中没有对应的词向量,导致输入模型之前被替换成特殊符号(UNK)。因为UNK本身在词库中作为一个独立的词只具有单一的词向量,这种变换会对文本还原能力产生比较严重的影响。
5.2.2 语义提取情况
相较于一元分词NMT自动编码器,基于jieba分词器的NMT自动编码器在语句结构的保留情况更好。如果去除掉错误的关键词,大部分的句子语义和语法结构是正确的,这意味着本模型很好地掌握了原句的语义语法结构,仅仅不理解关键词的含义出现文本还原错误的问题。
实验中也可以看出,一些所有词向量均训练得当的句子产生了很好的结果,如原句1。这意味着只要能解决好词汇的语义嵌入问题,NMT模型就能在英文上产生很好的结果。
6 结语
本文通过NMT自动编码器实验研究了现有的一元分词和HMM分词器在NMT模型上的文本还原和语义提取情况。实验表明,一元分词和传统的英文分词系统不能满足英文在NMT模型上的适配要求,前者由于单字模型很难准确表达句子语义,后者由于新词构造、整体分词趋向的问题影响模型的训练。在两者之中,一元分词模型的表现相比而言较好一些,但相比中文在NMT模型中的适配程度仍然有较大距离。Google在自己的NMT方案GNMT(Google's Neural Machine Translation)的相关实验中也发现,中译英系统相比于英译中的系统BLEU分数表现更差。根据NMT模型的特点,适用于其上的语言需要满足两点:1)可以较为准确清晰地表达语义;2)词汇以最基本的含义为单一词,不应存在可再分的复合词。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
传感器世界(2022年4期)2022-08-05
传感器世界(2022年3期)2022-05-24
数字技术与应用(2021年1期)2021-03-24
校园英语·月末(2021年13期)2021-03-15
现代信息科技(2019年18期)2019-09-10
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
科技创新与应用(2017年26期)2017-09-12
中国信息技术教育(2016年13期)2016-09-10
