
基于改进位置社交的近邻知识推荐算法*
2020-03-04 05:12王槐彬
计算机与数字工程 2020年1期
李 月 王槐彬
(广东交通职业技术学院信息学院 广州 510650)
1 引言
推荐系统是随着互联网应用的不断发展及互联网数据内容不断扩大而产生的一种系统,该系统的主要目的是从海量数据里筛选出用户感兴趣或者有价值的信息对用户进行推荐。目前常用的海量数据检索系统主要为搜索引擎,如Google、Baidu等。搜索引擎虽然具有应用范围广泛、满足大部分用户的信息检索功能等优点,但是对于一些特定应用领域,如电子商务应用、在线学习系统、特定兴趣范围检索(如影片、书籍、音乐),却无法满足用户个性化、多样化、内在需求复杂化的现状。在特定内容的应用上,利用推荐算法构建个性化推荐系统,能有效发掘用户潜在的隐性需求,将用户真正需要或感兴趣的内容推荐给用户,从而提升用户体验,增强用户对系统的粘性。
2 推荐系统
Resnick[1]等于 1997 年给出了推荐系统的定义。一个完整的推荐系统由用户模型、产品模型与推荐算法3部分组成,称为模型三元组。用户模型用于获取、表示、存储用户的浏览行为与购买历史数据,这些数据可以通过显示与隐式2种方式获取。显式获取是通过用户行为,如对产品的评分、喜欢或不喜欢某个产品等来表达对产品的偏好程度,直接得到数据;隐式获取是通过系统对用户行为,如网页浏览、购买日志等进行自动追踪来获取用户对产品的兴趣偏好,间接得到数据。产品模型用于表示、存储产品的特征属性。推荐算法作为推荐系统的关键环节,主要通过挖掘用户历史数据中蕴含的规律来获取用户的兴趣偏好与消费习惯[2]。不同推荐算法侧重的领域不同,当前主流的推荐算法包括基于内容的推荐、基于协同过滤的推荐、混合推荐算法、基于社交网络的推荐以及随着网络技术及GPS技术发展而兴起的基于兴趣点的推荐等。
3 社交网络与LBSN
社交网络是近年来随着人与人之间沟通方式的变化而产生的一种新型交流方式,主要指不同年龄、不同职业、不同地区和不同兴趣爱好的人通过网络汇集起来,构建出的一个庞杂的交流圈。基于社交网络的推荐算法核心思想为利用社交网络数据捕捉用户兴趣偏好及好友信息,并根据获取的数据为用户进行个性化产品推荐、好友推荐与信息流的会话推荐[3]。基于位置社交的网络(location-based social network,LBSN)属于社交网络的一个变种,主要通过采集用户的位置信息建立与其他用户的社交联系。LBSN的签到数据包含了丰富的用户隐式信息,可以用这些位置签到数据、社交关系、评论数据等内容挖掘用户感兴趣的内容,实现有价值的推荐[4]。
为用户推荐可能感兴趣的地理位置的任务称为兴趣点(point-of-interest,POI)推荐。基于LBSN算法的兴趣点推荐与传统的社交网络推荐存在区别。LBSN兴趣点推荐在模型上主要构建从用户到地理位置的交互模型,通过挖掘用户在签到兴趣点上的显式数据和隐式反馈数据,经过算法计算,得到用户有可能感兴趣的兴趣点进行推荐。根据融合因素不同,LBSN中的兴趣点推荐算法主要分为四大类[5]:基于签到数据的兴趣点推荐算法、基于地域影响力增强的兴趣点推荐算法、基于社交影响力增强的兴趣点推荐算法以及基于时域影响増强的兴趣点推荐算法[6]。
4 学习网络与LBSN
学习网络指各类以知识传播和用户学习为主要目的的网络。随着信息化技术的不断改进和数字化学习需求的不断增长,各类学习网络也越来越普及。因为学习网络中也存在用户、学习产品等组成要素,可将其看做社交网络的一部分。学习网络和社交网络相比,具有一定相似性,但由于学习网络独特的用户目标,二者之间也存在明显不同[7~9]。社交网络中,用户对产品的评价信息具有明显的情感极性,会通过不同表述方式表达喜欢、不喜欢、一般等喜好程度,在学习网络中用户往往表达的是负面情感倾向,比如对于某个知识点不了解,那么用户的评价可能多表现为提问、疑问、表达不理解等偏负面的评价,而对于那些已经掌握的知识点,用户往往会进入下一个内容的学习而不予评价。在社交网络中,推荐内容主要为用户感兴趣的产品,属于用户正面情感表达下得出的符合其爱好的正面情感产品[10]。在学习网络中,如需要向用户推荐产品,该产品应当为用户表达困惑或不理解时与该知识点相关联的知识点,通过关联知识点的学习解决用户当前学习中的疑难问题,二者的推荐目标是完全不同的。
与基于兴趣点的LBSN推荐系统相比较,学习网络中的知识推荐系统构建更接近LBSN系统的模型和算法[11]。LBSN推荐系统中,用户通过签到数据表达对该兴趣点的正面情感评价,而用户不喜欢的地点也不会签到,负面情感评价数据会被忽略。这一点正好与学习网络中用户对知识点只表达负面情感数据而忽略正面评价数据相反。基于兴趣点的LBSN中用户的签到次数隐含了用户对该点的兴趣评分[12],而在学习网络中用户对知识点的点击次数和时长蕴含了该用户对该知识点的不理解程度(对于易于理解的知识点用户不会多次学习或学习较长时间)。因此,对于以学习推荐为目的的学习网络推荐系统,可参照基于兴趣点的LBSN模型构建,通过改进LBSB推荐算法,达到学习网络中的推荐目的。
5 改进LBSN算法的近邻知识推荐
5.1 问题描述
学习网络推荐的目的是利用用户已有的访问数据和学习网络中的其他数据信息对用户下一步需要访问的知识点进行预测,并将预测结果推荐给用户作为其学习推荐列表。将学习网络中的知识点看做LBSN推荐系统中的兴趣点,可采用经典LBSN模型中的用户-地点模型。在学习网络中,先构建包含2种实体的集合关系:用户集合与知识点集合[13]。学习网络包含 m 个用户,集合 U={u1,u2,…,um};包含N个知识点集合K={k1,k2,…,kN}。
5.2 学习网络中的改进LBSN算法
5.2.1 构建用户-知识点学习情况矩阵
用户u点击学习过的知识点k集合表示为Ku。每个知识点给予唯一标识编码,并将用户的学习行为记录抽取出来,构成用户-知识点学习评分矩阵F∈RM×N,学习情况矩阵F中每个元素fij表示用户i在知识点j上的学习情况评分,用户-知识点评分矩阵如表1所示。

表1 用户-知识点评分矩阵
由于学习网络中用户大多不愿花时间去对已学习过的知识点作出评价,故学习网络中无法收集到足够的显式评分数据。需将用户对知识点的访问次数或访问时长或访问行为方式等数据提取出来,转化为显式评分。如用户点击的次数反映了用户对该知识点理解的难易程度隐式信息,次数越高或停留时间越长,表明该知识点对该用户而言难度越高。对于学习行为中的隐式数据,首先对其进行预处理转换为评分数据,评分范围设置为1到5。如果某项知识点在某个用户上获得的评分为5,表示该用户对该知识点感兴趣或认为该知识点难度较高。如果评分为1则表明该用户对该知识点不感兴趣或认为该知识点非常简单。在系统初始情况下,用户对知识点的访问是随机的,可能会有大量知识点学习情况评分存在缺失。
5.2.2 构建用户-知识点短路径集合
在LBSN推荐算法中,认为任何事物都是相关的,但是相对于距离远的事物,距离近的事物之间更加相关[11]。在学习网络中,用户在学习当前知识点A后最先访问的知识点B往往是用户认为和知识点A逻辑联系最密切的内容,因此,在学习网络中,知识点之间也存在类似LBSN系统中的兴趣点距离概念。对于学习网络中的知识点距离,可将从一个知识点A直接跳转到另一个知识点B距离标记为1,从B再跳转到知识点C则标记A到C的距离为2,依次获取知识点网络中节点的距离值,构建知识点距离矩阵。考虑经历多次跳转后的内容关联紧密程度,结合三度影响力理论[14],将不同知识点间的距离最大标记为3,也就是说从一个知识点到另一个知识点如果经历了3次以上的跳转那么则认为这两个知识点间的距离非常远,不存在强逻辑联系。在知识点距离矩阵上融合用户信息,并将用户i在知识点集合K上所有低于3次的知识点跳转提取出来,即构成了用户-知识点之间的路径集合。Pi表示用户i在学习网络中知识点学习路径跳转小于3次的路径集合,则学习网络中m个用户在n个知识点上的用户-知识点路径集合M={P1,P2,…Pm-1,Pm}。
5.2.3 推荐算法
在学习网络中,相似的用户对于知识点的学习需求也是相似的。常见的计算用户相似度算法为余弦相似度计算,首先采用余弦相似度进行用户相似度计算[15]。
定义用户U和用户V共同评分的学习知识点集合用 RU,V表示,ru,i和 rV,i分别表示用户 U 和用户 V对学习知识点i的评分,RU和RV则分别代表了用户U和V对学习知识点的平均评分。用户间的相似度通过向量间的余弦夹角度量,将用户对项目的评分看做n维项目空间的向量,则用户U和用户V的相似度SUV,可按照余弦相似度公式计算:
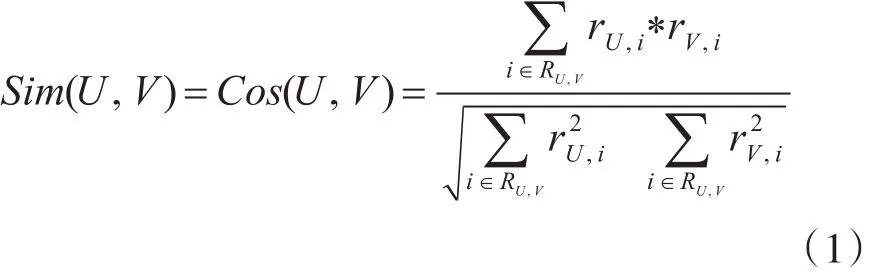
由于学习网络中用户对知识点评分稀疏性的问题,为构建更为全面、有价值的推荐知识点,应根据用户相似度扩大选取当前用户的n个相邻用户[16],并将相邻用户的知识点学习路径合并构成候选路径集合M′。根据之前确定的用户-知识点之间的短路径集合M′,任意用户i与知识点l之间的(ui,kl)都可通过用户-知识点路径集合的特征值计算特征值向量:

根据逻辑回归公式可知,用户i需要去到知识点l进行学习的概率为

其中为特征向量中的特征权值,可通过训练数据得到。根据计算到的概率ρ进行排序,依据概率从大到小选取合适数量的知识点进行推荐即可。
6 实验与分析
本文采用超星慕课学习平台上的学习数据作为实验数据来源,目前超星慕课平台上已构成一个相对完善的学习网络,学习者之间的关联关系包含好友关注、点赞、讨论、聊天、学习者自行组建学习小组、学习者共读书籍、共同加入同一直播或在线公开课等多种社交行为。系统中可采集学习者时间记录空间数据,通过学习者时间记录空间的数据解析可绘制学习者在学习空间完整的学习轨迹,如果将该轨迹上的不同知识点看做LBSN网络中的兴趣点,则完全可构建出学习网络中的类LBSN网络。实验抽取超星慕课平台某一课程学习者共计223人的学习行为记录数据,该数据记录的是学习者在40个知识点上的学习行为数据以及学习者之间的社交关系数据及行为数据,其中社交关系及行为数据为3699条,学习行为数据12188条。因为目前在学习网络领域无权威算法对比推荐的效果,故该算法通过人工标记形式检验推荐的质量。实验采集了160个学习网络中参与了同一门课程学习的自愿者人工打分标记推荐效果。根据当前学习的知识点给出推荐学习的相关知识点,实验参与者依据相关程度给出评分。
6.1 相似邻居数量对推荐结果的影响
根据用户相似度选择一定数量的邻居扩大候选学习路径集合是改进LBSN算法中的一部分。实验中通过调整候选邻居参数生成不同的推荐结果,从实验数据可以看到,当候选邻居数递增分别为1至10个相似邻居时,160个人工标记对推荐效果满意度的评价平均值整体呈上升趋势(实验采取5轮标记打分,分别记为实验1到实验5)。同时从实验数据分析可知,当候选邻居数为4或5时能取得较为满意的推荐效果,但推荐质量并不会随着候选邻居数的增加而无限上升,即候选邻居数存在一个最佳范围,超出此范围既增加了推荐计算的开销又不会取得更好的推荐效果。
6.2 推荐对学习效果的影响
在学习网络中加入推荐,能有效提升学习对象获取有价值信息的效率,取得更好的学习效果。实验选取160个学习网络中参与了同一门课程学习的学习者在10个知识点上的学习数据进行对比,将160名学习者分为学习过程中有知识点推荐及无知识点推荐组,人数各为80人。分别采集一个星期内10个知识点下两组学习者的平均学习时长、学习者在单个知识点上的反复学习次数、为理解单个知识点而跳转到其他知识点进行学习的相关知识点平均学习数量以及对10个知识点进行考核的平均测验成绩进行对比,具体数据如下图2所示。

图2 学习效果对比
通过数据对比可知,有推荐组在平均学习时长上明显低于无推荐组,表明学习推荐可缩短学习者对单个知识点学习理解的时间,提升其学习效率。同时,有推荐组相较于无推荐组在学习效果上能取得更好的平均成绩,表明学习推荐能帮助学习者更加深入的理解所学知识点内容。
7 结语
为解决学习网络中信息过载的问题,本文提出了一种改进LBSN算法的学习推荐算法。将学习网络看做社交网络及LBSN网络的融合,通过用户相似度计算及知识兴趣点路径计算,为用户推荐有价值的知识点作为辅助学习的手段。实验证明该算法能有效提升学习者的学习效率和质量。后续研究中还可深入研究学习网络中专家用户对学习推荐的影响因子问题以及通过挖掘学习网络中的兴趣组信息提高推荐准确性等。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
电脑知识与技术(2022年11期)2022-05-31
意林彩版(2022年2期)2022-05-03
昆明医科大学学报(2022年2期)2022-03-29
好日子(2021年8期)2021-11-04
中国药学药品知识仓库(2021年18期)2021-02-28
学生天地(2020年15期)2020-08-25
第一财经(2020年4期)2020-04-14
意林·少年版(2020年2期)2020-02-18
现代职业教育·职业培训(2019年6期)2019-10-09
