
基于深度学习的新疆热门微博评论的情感分析
2020-02-04 07:43黎洁君
现代盐化工 2020年5期
黎洁君
摘 要:加强互联网舆情管理是国家治理体系和治理能力现代化发展的重要内容。基于深度学习,以微博上关于新疆的热门评论为样本,通过构建长短期记忆网络(LSTM)模型对每条评论进行评分,分析其正负性。情感分析结果对舆情治理具有一定的现实意义。
关键词:深度学习;长短期记忆网格;情感分析
微博是我国时下非常流行的社交、信息分享平台,日访问量上亿,居于全球社交平台的首位。微博上有海量信息,这些数据中包含网民的情感信息资料以及对于各种事件的舆情偏向,具有可挖掘的价值。依托数据挖掘和自然语言技术,情感分析对相关领域都有一定的战略价值,企业可以根据情感分析发现网友的情感倾向,从而制定相关策略;过去许多社会热点事件都在微博中引起大讨论,网友各抒己见,使各种大小事件得到公平解决,政府也可以从中获知舆情倾向。所以,分析微博相关热点问题或事件具有一定的现实意义[1]。
基于深度学习的分析方法的主要思想是预先对训练文本语料进行定性分类且标注,以统计理论信息等作为分类特征,训练出一个较好的分类模型[2]。利用得出的最优模型进行情感分类,得到相关的情感分析数据,从而得到情感倾向的分析结果。如今,新疆安定繁荣,加上其独特的西域风光,引来了各地游客,来疆旅游人数攀升,在微博引起了热议。本研究基于Python中的Pytorch深度学习框架,利用长短期记忆(Long Shot-Term Memory,LSTM)网络对微博上关于新疆的评论进行采集以及情感分析。
1 数据来源
Python拥有大量的库,且易于学习,可以用来高效地开发各种应用程序。Python语言目前广泛应用于网络爬虫、计算与数据分析、人工智能、自动化运维、云计算等领域。本研究通过网络爬虫技术来获取有效的微博评论数据。网络爬虫是一种程序或者脚本,能够按照一定的规则对互联网信息进行自动抓取。网络爬虫被广泛应用于互联网搜索引擎或类似的网站,从而对这些网站的内容和检索方式进行获取、更新,对于访问到的页面内容能够自动收集获取,然后提供给搜索引擎进一步处理,进而方便用户对所需要的信息进行更快的检索[3]。本研究通過requests,re,pandas,json等库[4]对统一资源定位符(Uniform Resource Locator,URL)“https: //m.weibo.cn/comments/hotflow?id=4446534093 056573&mid=4446534093056573&max_id_type=0”进行爬取,得到的评论一共有14 761条。
2 模型介绍

3 实验与结果
3.1 数据集
本实验使用到的数据集,第一个是训练模型所需要的训练集,其中都使用label标签来标记其语言情感的正负性,数值取在0~1,其中1表示正面影响,0表示负面情绪,根据数值的大小来分辨其正负情绪的比重大小。训练集包括9 000条情绪,其中有4 500条负面情绪和4 500条正面情绪。验证集包括1 000条情绪,其中正面情绪有500条,负面情绪有500条。测试集中有500条正负数量不同的评论。
3.2 数据总览及预处理
分词是自然语言处理(Natural Language Processing,NLP)中文本处理的基础环节和前提。与以英文为代表的拉丁系语言相比,中文分词要复杂得多、困难得多,因为自古以来中文的词语之间均没有自然分隔,并且组合多变[8]。对于分词,在Python中需要导入pandas库和jieba库。Pandas的主要用途是进行数据分析,jieba库则是专门用来进行中文分词的一个库。导入成功后进行分词,分词得到两个新的变量,分别为token_count(单个评论词组数量),text_lengths[9](单个评论长度),再对训练集、测试集和所采集的微博评论进行分词。此时,导入Word Cloud库(词云图),进行数据词云可视化,如图1所示。
词云呈现主要是看词组所占比重,词组比重越大,在词云中的字体越大,可以看到“越来越”“稳定”“人民”等词的比重较大。
3.3 实验参数
实验参数训练设备为CPU,其中batch size(单次训练用的样本数)选择64,学习率为0.01,dropout rate选择0.5,LSTM堆叠的层数为1,隐藏层节点的个数为100,epoch选10,评论字典共25 002个,labal(评价1,0)有两个,词向量维数为300。
3.4 模型训练及效果评估
实验参数设置好后就开始进行模型训练,得到最优模型后,进行效果评估,导入所需库,然后将测试集代入,进行分词操作,再加载模型进行效果评估,结果如图2所示。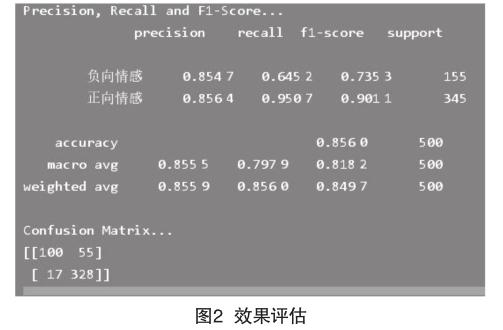
由以上结果可得,模型效果精确率在85%以上,正面情感总体准确度较高,负面情感召回率欠缺,在实例预测中负面情感预测准度难控制。总体上,训练出的模型可用。
3.5 模型使用及结果
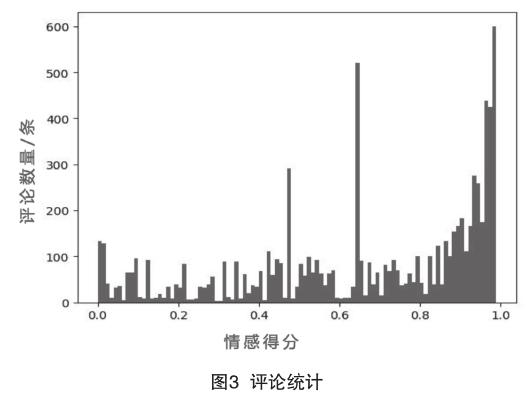
首先加载模型,其次导入爬取的微博评论,最后进行评论的情感分析,得到每句评论下的评分。负面情绪主要是一些不相干的评论或者带个人主观情绪的评论。得到全部评论的得分后,进行数据的可视化,将所有评论的得分及个数做成直方图,如图3所示。
4 结语
基于深度学习,对关于新疆的热门评论进行情感分析,主要使用Python语言。本次实验主要使用LSTM网络进行建模,由于RNN网络训练时只能将信息传递给相邻的后继者,在实际中训练RNN是很难实现的,根本原因在于梯度消失和梯度爆炸问题,这时LSTM网络的引出有效地解决了这一问题。LSTM网络的核心是其独特的细胞状态,细胞状态好似传送带,直接在整个链上运行,使线性交互变少,因此,信息在其上流传时不容易变化;此外,还具有独特的“门”结构来控制细胞状态。LSTM网络主要结构为:(1)决定细胞状态;(2)细胞状态的更新准备;(3)更新状态;(4)基于状态输出信息。本实验主要依靠Pytorch(深度学习库)进行建模。训练模型成功后进行效果评估,得到可行的模型效果,得到效果评估模型精度达85%。最后对相关评论使用模型进行评分,分析网友的情感偏重。由实验结果可知,此次网友对新疆有很多感想,其中通过词云图可知“越来越”“稳定”“人民”“爱”等词语的比重很大。评论统计中情感评分区间为0—1、0—0.5代表负面情绪,越接近0负面情绪越大,0.5—1代表积极情绪,越接近1正面情绪越大。总体上,本次情感分析中,微博上的网友有新疆本地的,也有国内其他各省的,情感分析中正面情绪比重很大,这也说明新疆的确在旅游、治安等各个方面发展得都越来越好。所以,加强互联网舆情管理是国家治理体系和治理能力现代化发展的重要内容,不仅能有效了解民情,而且对舆情治理也有一定作用。所以,在特定方面进行情感分析具有一定的现实意义。
[参考文献]
[1] 关鹏飞,李宝安,吕学强,等.注意力增强的双向LSTM情感分析[J].中文信息学报,2019(2):105-111.
[2] 胡朝舉,梁宁.基于深层注意力的LSTM的特定主题情感分析[J].计算机应用研究,2019(4):1075-1079.
[3] 郭丽蓉.大数据环境下的网络爬虫设计[J].山西电子技术,2018(2):50-52,94.
[4] 李培.基于Python的网络爬虫与反爬虫技术研究[J].计算机与数字工程,2019,47(6):1415-1420,1496.
[5]SUNDERMEYER M, SCHLüTER R, NEY H. LSTM neural networks for language modeling[EB/OL].(2014-02-10)[2020-10-20]. http://www-i6.informatik.rwth-aachen.de/publications/ download/820/Sundermeyer-2012.
[6] 伍行素,陈锦回.基于LSTM深度神经网络的情感分析方法[J].上饶师范学院学报,2018(6):16-20.
[7] 陈再发,刘彦呈,刘厶源.长短期记忆神经网络在机械状态预测中的应用[J].大连海事大学学报,2018(1):85-90.
[8] 严明,郑昌兴.Python环境下的文本分词与词云制作[J].现代计算机(专业版),2018(34):86-89.
[9] 祝永志,荆静.基于Python语言的中文分词技术的研究[J].通信技术,2019(7):1612-1619.
猜你喜欢
电脑知识与技术(2017年3期)2017-03-27
智能计算机与应用(2017年1期)2017-03-23
物联网技术(2016年11期)2017-01-12
电子技术与软件工程(2016年22期)2016-12-26
预测(2016年5期)2016-12-26
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
