
基于口腔全景曲面体层摄影新编码方法的法医学个体识别
2020-02-03 01:35刘猛范飞孙澈裘诗文刘媛媛郭晓莉邓振华
法医学杂志 2020年6期
刘猛,范飞,孙澈,裘诗文,刘媛媛,郭晓莉,邓振华
(1.四川大学华西基础医学与法医学院,四川 成都 610041;2.四川大学计算机学院,四川 成都 610041;3.四川大学华西口腔医院放射科,四川 成都 610041)
个体识别一直都是国内外法医工作者重要的任务之一[1]。目前,国际上常规使用的个体识别方法包括齿科比对、DNA比对和指纹比对。牙齿作为人体最为坚硬的器官,相对于DNA、指纹具有更高的稳定性,甚至有时成为特殊案件(如火灾、高度腐败、尸体白骨化等)中仅存的生物检材,而齿科比对技术可为此类案件的个体识别提供可行路径。口腔全景曲面体层摄影片(简称“口腔全景片”)能够清晰反映口腔颌面部及牙齿特征[2],且该技术已被广泛应用于口腔医学临床诊疗[3],其特征反映全面、易获取和保存的特点,使之成为法医齿科学个体识别的有效技术手段。目前,包括美国、澳大利亚及国际刑警组织(International Criminal Police Organization,INTERPOL)在内的多个国家和组织已有成熟的法医齿科学影像个体识别系统,而我国在该领域仍处于探索阶段[4]。
本研究基于口腔全景片中牙齿及颌骨特征提出编码方法,并对其编码进行验证,分析非同源影像片不同模块的多样性和同源影像片编码的一致率以及编码指标匹配率,以评估不同模块在个体识别中的应用价值及同一认定所需的指标匹配率范围。
1 材料与方法
1.1 研究对象
回顾性收集四川大学华西口腔医院1000例患者的口腔全景片,每例包括先后两个时间点拍摄的两张口腔全景片,共计2000张。口腔全景片均按照规范体位[5]进行拍摄。
纳入标准:(1)已完成恒乳牙交替[6];(2)图像清晰,既往拍摄过两张口腔全景片。收集过程中隐匿患者的个人信息,仅采集无信息的全口曲面断层片,以“拍片日期-出生日期-性别”对影像资料进行命名。排除标准:(1)影像片模糊不清晰;(2)乳牙列和混合牙列。
本研究所纳入的样本均为回顾性收集临床诊疗过程中的口腔全景片,符合医学伦理要求,并征得四川大学医学伦理委员会审查同意。
1.2 仪器
PaX-400C型全景口腔和头颅X射线成像系统(PaX-i,上海怡友医疗器械有限公司),管电压65~73kV,管电流8~10mA。X550型口腔X射线机[Veraviewepocs,森田医疗器械(上海)有限公司],管电压65~70kV,管电流6~8mA。
1.3 方法
1.3.1 编码指标
本研究根据口腔全景片所反映出的牙齿及上下颌骨的生理特征、病理特征及临床治疗方式特征,参照INTERPOL齿科命名方法[7-8]命名记录,共形成62项指标。生理特征主要涉及牙齿及颌骨先天性特征及异常;病理特征包括口腔临床常见疾病特征;临床治疗方式主要包括目前口腔临床治疗所采取的措施,筛选前提为均可以在口腔全景片中显示。根据口腔全景片所反映的口腔颌面部解剖特点,将编码指标划分为10个模块,分别为牙齿整体变化、右上颌牙齿、左上颌牙齿、左下颌牙齿、右下颌牙齿、上颌特征、下颌特征-1、下颌特征-2、唇腭裂、颌骨整体特征,如表1所示。

表1 编码模块和所包含的指标Tab.1 Coding modules and indexes
1.3.2 操作步骤
首先,根据编码指标设计编码表格及划分模块,表格牙位序列采用国际牙科联合会(Federation Dentaire International,FDI)系统牙位记录法。
其次,进行人工阅片,按照编码指标将每张口腔全景片的牙齿及颌骨特征记录在表格内,每张影像片形成一张独立的编码表,本研究共形成2000张编码表。抽取每个个体拍片时间靠前的1000张编码表归为早期库,而拍摄时间靠后的1000张归为后期库[9]。同一个体前后两张影像片称为同源影像片,同源影像片所形成的两张编码表称为同源编码表,分别分布在早期库和后期库中。
最后,通过计算得出两个数据库中不同模块的多样性和同源编码表相对应模块的一致率以及编码指标匹配率,并对研究样本的一般性信息进行统计,包括年龄、性别、拍片时间间隔。多样性的计算方法为早期库或后期库中某一模块中编码形式类别数占各库样本总量(1000例)的百分比。同源影像片编码模块一致率的计算方法为某一模块中同一个体前后两张影像片编码一致的样本量占总样本量(1000例)的百分比,比值的高低反映其稳定性,比值越高说明模块特征稳定性越好。编码指标匹配率的计算方法为同源编码表中所有指标前后匹配的数量与指标总数量(62项)的百分比。
1.3.3 数据处理分析
利用Python语言编写格式匹配代码,将人工编码表格转换成MySQL(关系型数据库管理系统,瑞典MySQL AB公司)中的数据格式存储在MySQL数据库中,编写代码读取MySQL数据库中的数据。统计样本的性别信息、每张编码表的年龄信息和年龄均值以及同源编码表拍片时间间隔信息。其中年龄计算公式:实际年龄=(拍片日期-出生日期)/365.25(岁);拍片时间间隔=(后期库编码表记录的拍片时间-早期库对应的同源编码表拍片时间)/365.25(年)。结果精确至小数点后2位。比较同源的两张编码表相对应指标的匹配率和相对应模块的一致率,以及早期库和后期库各自数据库内的编码表格相对应模块的编码不同表现形式,将结果以Excel表格的形式输出。采用Microsoft Office Excel 2010软件将输出的Excel表格中的数据进行分类、排序和频率统计,并将经Excel软件整理好的表格导入Origin Pro 8.0作图软件形成可视化图表。
应用Kappa检验方法对同一观察者和观察者间的编码一致性进行分析,前期阅片由1名经过口腔解剖学、影像学等系统培训的法医学硕士研究生完成。间隔2个月后由同一观察者对样本中随机抽取的30张口腔全景片再次编码,进行同一观察者的一致性检验。同时,由1位经验丰富的法医学博士按同一编码方法对选取的30张口腔全景片进行编码,将编码结果与前一观察者的初次编码结果比对,进行观察者间的一致性检验。Kappa检验采用SPSS 20.0软件完成。
2 结 果
2.1 一般资料描述及一致性检验结果
一般性资料分析结果显示:1000例样本中,女性659例,男性341例,年龄分布在15~90岁,其中以20~40岁年龄段人数居多(早期库:44.7%;后期库:51.7%)。第一次拍摄口腔全景片的平均年龄为(30.98±16.54)岁,第二次拍摄时的平均年龄为(32.56±16.25)岁,两次拍摄的时间间隔为(1.58±1.27)年。
一致性检验结果显示:同一观察者的编码一致性为0.941,观察者间的编码一致性为0.875。这提示该编码方法在同一观察者和观察者间的编码一致性均较高。
2.2 非同源口腔全景片不同编码模块的多样性分析
对所划分的10个模块进行编码后,分别统计分析早期库及后期库内的编码表,得到两个样本库中每个模块的多样性,结果见表2。早期库所有模块中多样性最高的是右下颌牙齿,为78.30%,最低的是唇腭裂(0.20%)。后期库所有模块中多样性最高的是右下颌牙齿,为81.40%,最低的是唇腭裂(0.20%,仅3例)。由数据可见,反映牙齿特征的4个模块的多样性均高于65%,远高于同库其他模块的多样性。

表2 1000例患者不同编码模块的表现形式及多样性Tab.2 Represention and diversity of different coding modules in 1000 samples
2.3 同源口腔全景片不同编码模块的一致率
将同源的两张口腔全景片按照所划分的10个模块进行比对,得出不同模块前后两张影像片编码一致的数量,结果见表3,反映上下颌特征模块及唇腭裂模块的编码一致率较其他模块高。

表3 同源口腔全景片不同模块的编码一致率Tab.3 The coding consistency of different modules of homologous oral panoramic images[n(%)]
2.4 编码指标匹配结果
通过对1 000例患者的2 000张口腔全景片逐个编码并进行比对分析后发现,同源的两张口腔全景片的指标匹配数量最低为29,匹配率为46.77%,人数为1人;最高为62,匹配率为100%,人数为119人。其中指标匹配的数量在50个(匹配率为80.65%)及以上的人数为902人,占总人数的90.20%,具体结果见图1。
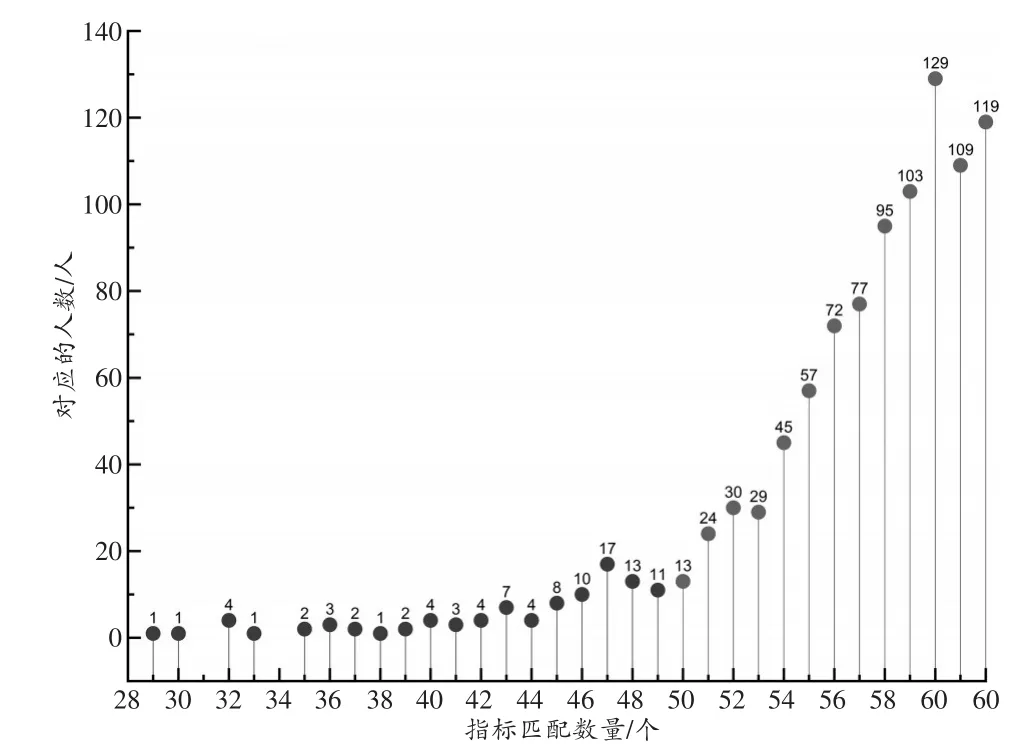
图1 同源口腔全景片的指标匹配情况Fig.1 The matching rate of the coding indexes of homologous oral panoramic images
3 讨 论
国外文献[3,8,10]报道,利用齿科放射学资料进行个体识别是法医学个体识别的有效手段,其中口腔全景片是重要的影像资料之一。本研究基于已有研究,筛选合适的编码指标,探索性地提出新编码方法,对1 000例患者的2 000张口腔全景片进行编码并验证分析。研究结果显示,不同模块的多样性呈现较大差异,且早期库和后期库样本的多样性分布表现出相同趋势。两样本库中,右上颌牙齿、左上颌牙齿、左下颌牙齿、右下颌牙齿这4个表现牙齿特征的模块,其多样性均远高于同库其他模块,且两样本库中多样性最高的均为右下颌牙齿,表明该模块的个体识别能力最强[11-12]。
同时,上颌特征、下颌特征-1、下颌特征-2和唇腭裂这4个模块在两张同源口腔全景片中一致的人数较其他模块多,表明这4个模块的特征稳定性较好,相较于其他模块更不易发生变化,即一致人数越多越具有同一认定的优势。但结合表2的结果可知,此4项的样本多样性较低,综合考虑,故认为此4项的实际应用价值较低。其余6项的一致人数所占比例差异不明显,综合考虑模块的多样性,认为右上颌牙齿、左上颌牙齿、左下颌牙齿和右下颌牙齿4个模块在个体识别中的实际应用价值较大。此外,对同源口腔全景片的指标匹配率计算分析可得,绝大部分个体(90.2%)其同源口腔全景片指标匹配率在80%以上,反映本研究提出的编码方法在齿科个体识别中具有较高的应用价值,该结果可为实际个体识别指标匹配率的范围界定提供参考。
本研究在纳入样本时,充分均衡了各个指标的特征。结果中反映牙齿特征的模块在同源影像片的一致率低于60%,结合实际样本情况,分析原因为:本研究纳入的样本均为医院拍摄过两次影像片的患者,此种类型的患者中较多经历了如正畸、正颌之类的手术治疗,如正畸治疗前和治疗后均要拍摄口腔全景片,造成部分同源口腔全景片的匹配率较低。故考虑在进一步的研究中优化计算机比对程序,将可能造成的变化作为影响因素加入程序中。同时完善指标评价体系,将指标赋予权重,稳定、不易产生变化的指标在同一认定中占较大比例,反之可随年龄增加产生变化的占较小比例,以期进一步提高研究中的同源匹配率。
此外,本次抽样的1000例患者中有3例唇腭裂,且同源口腔全景片中此模块均匹配一致。究其原因,考虑唇腭裂往往为先天性且基于目前医疗手段较难通过手术完全修复,故该模块表现出较强的特异性,但其发生率不高,在人群中缺乏足够的多样性,在后续研究中可对该指标赋予较大权重用于个体识别。
由于我国齿科个体识别技术尚处于起步阶段,故国内类似研究较少。2008年,高东等[11-12]对770例牙齿异常者和170例牙齿正常者分别设计了编码方法并进行了多样性分析;2012年,王尧等[13]对深圳地区200个对象的齿科多样性进行了研究;2015年,李冰等[14]对800例患者的口腔全景片进行牙列编码并分析了多样性及不同牙列区域对个体识别的价值。上述研究均形成各自的编码方法,但研究的侧重点不同,得出的结论亦略有差异。相较于以往研究,本研究纳入1000例患者的2000张口腔全景片,研究样本量更大,且没有牙齿完整无缺失等条件的限制,更具有普适性。另外,选用同一个体不同时间的两张口腔全景片进行编码并计算匹配率,使研究更贴近实际检案状况,可操作性更强。此外,本研究还将模块特征的稳定性纳入考虑范围,综合考虑了不同编码模块的多样性和稳定性。然而,由于非同源口腔全景片同一模块的比对计算量呈现指数级增长,故本研究的主要关注点在于探究可用于同一认定的指标与特征,在进一步的研究中,将优化计算机比对程序,并继续扩大样本量,探索同源影像片的比对和识别,以期初步建立适合我国人群的齿科编码指标和方法。
综上,本研究基于口腔全景片所反映的口腔颌面部特征建立了编码方法,对1000例患者的2000张影像片进行验证分析,发现反映牙齿特征的4个模块在个体识别中应用价值较高,其中右下颌牙齿最高。绝大部分同源口腔全景片的指标匹配率在80%以上,本研究的编码方法在法医学个体识别中具有一定的应用价值。
猜你喜欢
今日农业(2022年2期)2022-11-16
小学生学习指导(中年级)(2021年12期)2021-12-30
汉字汉语研究(2021年2期)2021-08-30
家庭影院技术(2021年6期)2021-07-28
家庭影院技术(2020年11期)2020-12-28
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
疯狂英语·新读写(2018年3期)2018-11-29
英美文学研究论丛(2018年1期)2018-08-16
新高考·英语进阶(高二高三)(2018年8期)2018-01-15
