
基于TM影像的单类分类算法比较研究
2020-01-18 06:26:42邵一杰
通化师范学院学报 2020年2期
邵一杰
单类分类问题是一种特殊的分类问题,是指在只有一种类别样本的情况下,只通过这一类样本训练分类器,再用训练出的分类器对未知类别的样本进行类别判断[1].传统分类问题通常需要两个或多个类别的样本[2],然而一些特殊情况下,获取多个类别的样本十分困难或者要付出极大代价,有时甚至根本无法做到,这时如果应用传统分类方法解决问题,就会由于样本数量差异过大导致分类结果不准确[1].单类分类(One-class classification)问题就是基于这种情况提出的.
遥感应用中,很多情况需要先对遥感影像进行分类.传统的分类方法中,图像中所有的类别都要事先有样本被标出,但是有些时候,有些类别的样本不方便获取或相对于其他类别数量太少,传统方法就不能很好地解决问题了[3];也有一些时候,我们只对图像中某种特定的类别感兴趣[4],比如,需要从遥感图像中提取道路信息,这时就不需要分辨图像中的森林和农田,这时如果利用单类分类方法,只通过目标类别的样本进行训练和学习,就可以有效节省用于获取其他类别样本的时间,从而提高工作效率.综上所述,在遥感应用中,单类分类器主要适用于以下两种情况.
(1)样本缺失或数量不平衡,只有一类样本可以用于训练分类器的情况,此时传统两类或多类分类器不能得到令人满意的分类结果.
(2)只需要从图像中提取某一种单一类别,此时使用单类分类器将可以提高工作效率,节约用于获取非目标类别样本花费的人力物力.
目前已有的单类分类方法根据原理大致可分为以下几类[5]:密度估计法[1]、基于神经网络的方法[6]、基于聚类的方法[7-8]、基于支持域的方法[9-11],除此之外,有些考虑未标定样本的分类方法也被应用于单类分类问题中[12-14].但这些方法也都有着各自的局限性,且单类分类方法在遥感影像分类问题中的应用也有待进一步研究.
鉴于研究用单类分类方法,通过不完全标定的训练样本提取单一类别的分类器对遥感应用有着十分重要的意义,本文基于Landsat TM 影像,针对典型分类方法进行实验,再根据结果分析讨论.本文涉及的分类方法主要包括单类高斯域(one-class Gaussian Domain Descriptor,Gaussian DD,GDD)方法、单类支撑向量(one-class SVM,OC-SVM)方法、Biased-SVM(BSVM)算法,以及传统二类支撑向量方法.
1 数据及实验设计
1.1 基本原理
实验中,将针对单类高斯域(GDD)、OC-SVM分类法、BSVM 分类法,以及传统的二类SVM 分类法,利用目标类别样本和未知类别样本进行分类比较实验.
传统二类SVM 分类是OC-SVM 和BSVM 的基础,单类分类问题中因为缺少非目标类别的样本,所以不能同时应用目标类别和非目标类别样本,但是却可以获取大量未知类别样本,在接下来的讨论中将二类SVM方法称为C-SVM.
基于密度估计的方法主要思想是由训练样本集估算出密度模型,并设定一个密度阈值,通过与该阈值比较来判断未知类别的样本是否属于目标类别[5].GDD 方法就是一种常用的密度估计法.
C-SVM 算法、OC-SVM 方法、BSVM 方法都以支撑向量和核函数的应用为理论基础,主要思想是寻找能够把类别区分开来的最合理界面,这个界面可能是一个边界,也可能是超平面等等[9-11].在单类问题中,这个界面需要在尽可能把目标类别样本包括在内部的同时尽量减少非目标类别被划分进来的概率.C-SVM方法以寻找两类样本的边界为目标,通过核函数表示高维空间的内积,利用Lagrange 函数求解判别函数[9].OC-SVM方法中,只有目标类别样本用于训练,所以把原点虚看作另一类,寻找使目标类别样本尽可能远离原点又包括足够目标类样本的边界[1].BSVM方法用目标类别样本和未知类别样本共同训练学习,在C-SVM方法基础上演化而来,因为未知类别样本中同时包括目标类和非目标类的样本,所以设置两个不同的惩罚参数,且让对应目标类的惩罚参数取较大值[13].
1.2 实验数据描述
本实验选用的遥感影像截取自陕西省2009年的一景TM影像,如图1所示,其中图1(a)为3、2、1 波段合成结果,图1(b)为4、3、2 波段合成结果.影像大小为1 000*1 000像元,覆盖范围30 km*30 km.包括TM 的6 个波段,分别是第1~5 和7 波段,自然地物覆盖清晰,无云层覆盖区域.区域地理位置处于35°1 ′ 1.26 ″ N~35°7 ′ 12.41 ″ N、109°1′41.57″E~109°4′38.52″E范围内,行政区划上主要处于陕西省铜川市南部,受大陆性季风气候影响,四季分明,土地覆盖类型以林地、农田、居民地、水体为主.
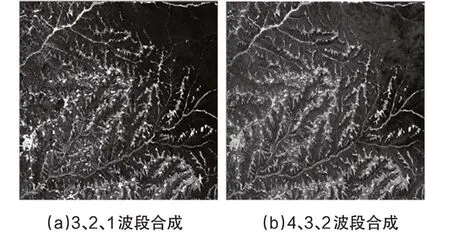
图1 待分类TM影像
由于遥感平台、传感器自身产生的噪声,以及天气状况的影响,获得的数据将不可避免地存在误差,这些误差的存在会降低遥感数据的质量.所以,在运行分类算法之前,有必要对获取的原始图像进行预处理.数据预处理包括辐射定标、大气校正、地形校正,选取软件ERDAS 的ATCOR模块完成辐射校正.地形校正时还需要利用到和TM图像空间上相匹配的DEM数据,实验中所采用的DEM 数据为ASTRER 的DEM 数据,经重采样到30 m*30 m.ATCOR3 的优势是可将地形与大气校正同时完成.
1.3 实验设计
(1)样本的选择.实验区土地覆盖类型以农田、林地为主,并有少量水体.实验中选取农田作为目标类别,其他所有类别为非目标类别.在选择样本时,首先要对遥感影像中的农田进行解译,解译时考虑农田的光谱特性和纹理特征.图像中的农田主要有三种,分别为:平原上的农田、收割后的农田、河谷中的农田.
平原上的农田在TM 影像432 波段组合下,由于农作物的存在,呈亮红色;在743 波段组合下呈绿色.平原上有作物的农田表现为典型的植被光谱特征:在第2 波段和第4 波段出现绿峰和近红外反射峰,在第3波段由于叶绿素吸收出现吸收谷,在近红外第4 波段出现反射最大,短波红外5、6 波段依次下降.由于农田人工耕作痕迹比较明显,行垄错落有致,因此在影像上表现出显著的纹理特征,大片农田内部呈现有序的行列变化.
平原上农作物收割之后的旱田,围绕居民地成片状分布,面积一般比较大.在TM 影像432 波段组合下,平原上收割后的旱田呈现亮白色,中间间杂暗色;在743 波段组合下,呈现为粉红色调.收割后的旱田呈现出裸地的光谱特征,波段3、4、5逐渐上升,短波红外6波段下降.由于收割后的旱田行垄依然存在,表现在影像上为弱纹理信息,横向、竖向或者斜向的条带状纹理间杂.
在TM 影像743 波段组合下,由于河谷中的农田为收割前后农田间杂分布,所以色调呈现绿色间杂粉红色;在432 波段组合下,呈现为红色间杂灰白色.河谷中农田沿着河谷分布,呈现条带状纹理,有规律分布.
实验中,GDD 和OC-SVM 都只需要目标类别的样本用于分类,BSVM和C-SVM则需要目标类别的样本和一部分未知类别样本.为完成以上方法的实验,首先要获取目标类别样本和非目标类别样本.更多的目标类别训练样本可能意味着更高的分类精度,但是这也会增加获取训练样本所需的成本.因此,本实验中选择4 000个像元作为样本,其中包括2 500个目标类别样本和1 500个非目标类样本,再在剩余的背景中随机选择5 000个样本作为未知类别样本.GDD和OC-SVM算法中,选择1 000 个目标类别样本作为训练样本,剩余的1 500个目标类别样本和1 500个非目标类别样本作为检验样本.标定类别的样本不超过全图总体像元数的0.4%.为了得到更为准确的结果,随机选取10 组训练样本进行实验.最终用全局精度OA和kappa系数对结果进行比较和评价.
(2)实验过程.在所有的方法中,均选取RBF高斯核函数.OC-SVM、BSVM、C-SVM 方法均采用林智仁(ChihJen Lin)博士等开发的LIBSVM软件包[15]实施.OC-SVM、BSVM和C-SVM的输出结果均是二值的,分别表示目标类别和非目标类别,所以不用选择阈值.
OC-SVM法需设定两个参数,分别为RBF核函数的宽度γ和预计训练样本中离群的比例υ.在(0,100]范围内以为公比变化γ,在(0,1)范围内以0.1 的步长变化υ.通过检验样本计算全局精度OA,计算每组参数变化对应的OA,选取最佳参数.除全局精度外,为评价计算成本,引入参数τ
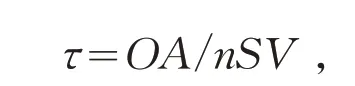
nSV表示支撑向量数,用支撑向量的数量来度量计算复杂度,τ为一个在全局精度和计算复杂度之间折衷的参数.为获得较高的精度,仍然选择全局精度作为参数γ和υ选取的依据.
BSVM 算法中有三个参数需要选取,分别是RBF核函数的宽度γ、目标类别和未知类别的误差权重Ct和C0,且Ct应该大于C0.γ在(0,100]范围内以为公比变化,C0在[0.001,1]范围内以为公比变化,Ct取值为{10,100,1 000}×C0.C-SVM算法中设计两个待定参数,分别是RBF核函数的宽度γ以及误差参数C.γ在(0,100]范围内以为公比变化,C在[0.1,1 000]范围内以为公比取值.
全部参数选定后,再代入模型中对训练样本进行学习,建立分类器,再对全图进行分类,最后用检验样本完成检验.在OC-SVM、BSVM 和C-SVM 方法中,为防止因尺度不同导致小的数据波动被忽略,把全部数据重采样到[-1,1]范围内.这也可以减小软件计算核函数时的数字难度.
GDD 方法用数据描述工具箱(data description toolbox,dd_tools)[16]实施.只有目标类别样本用于训练,实验中选择不加任何复合的简单高斯分布.模型中有两个参数,分别为阈值θ和正则化参数γ.θ和γ的范围均在[0.01,1].
以上方法的实施可总结为分三步进行:首先寻找优化参数,各方法对应的参数意义及实验取值情况如表1.然后通过训练样本训练学习,建立分类器.最后用分类器对全图分类,并检验精度.
2 实验结果及讨论
2.1 实验结果
实验需要用10 组样本,每种方法对应每组样本均需优化一次参数,以OC-SVM方法的一组训练样本为例展示参数选取结果:OC-SVM方法中有两个参数待选取,分别是:RBF 核函数的宽度γ和预计训练样本中离群比例υ.实验得到OA和τ随两个参数变化情况如图2,由此寻找极值,确定参数.
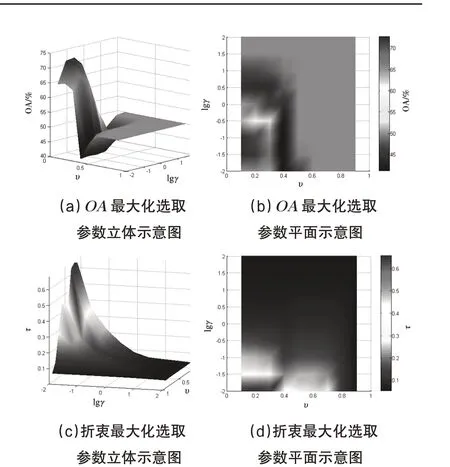
图2 OC-SVM方法中的参数选取
可以看出,通过精度(OA)最大化和精度计算成本折衷(τ)最大化选取的参数是有差别的,为了确保足够的分类精度,最终选取OA最大化得到的参数用于接下来的训练学习.实验中发现最优参数是随样本不同而变化的,而参数不同又对精度变化有很大影响,这符合SVM 方法对参数敏感的特点.选取参数之后进入训练学习阶段,最终对全图分类并计算精度,用混淆矩阵计算kappa系数,最终结果为10组样本的平均.

表1 待定参数及他们的意义、搜索范围和步长
为显示清晰,截取图像中如图3的13 km*13 km范围区域展示,图4为四种方法的分类结果.总的来说,以农田为目标类别,其他所有类别为非目标类别,BSVM 方法获得了最好的分类效果,他的分类结果与原始图像最为接近.C-SVM方法次之,GDD 和OC-SVM 提取出的农田较真实数量少,漏分现象较为严重,效果没有BSVM和C-SVM方法好.

图3 待分类TM图像截取
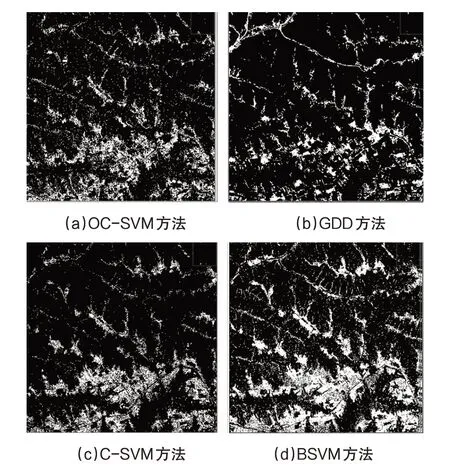
图4 四种方法分类结果图
图5为几种方法的OA和kappa系数在10组样本下的比较,BSVM方法的总体精度好于其他方法,GDD 和OC-SVM 方法精度较低.10 组样本下的OA和kappa 系数及其均值、均方差如表2所示.总的来说,BSVM方法分类效果好于其他方法,且稳定性更高.
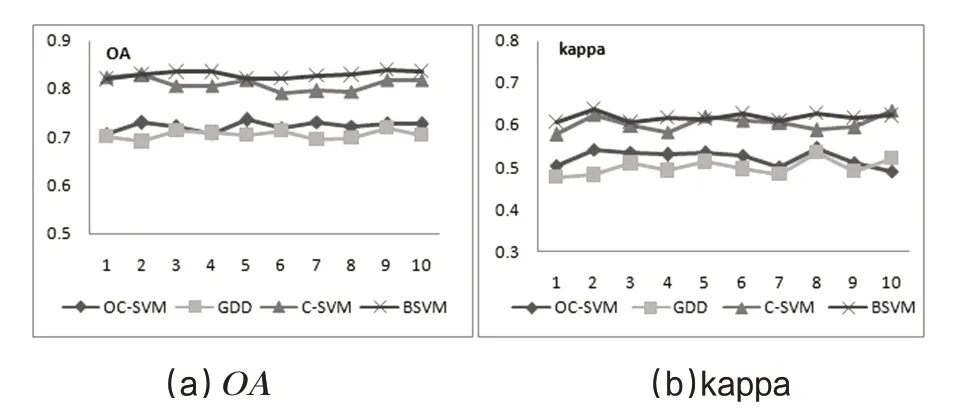
图5 四种方法10组样本下的OA 及kappa
2.2 结果讨论
有研究表明,OC-SVM在一些情况下可以得到较好的分类结果[4,16],有时甚至全局精度OA可超过90%.但也有一些情况,OC-SVM 方法的OA只能达到70%~80%[16].本研究中OC-SVM和GDD 方法都没有达到令人满意的分类效果,一方面因为农田类型的提取有其自身的复杂性,不容易达到较高的分类精度,另一方面也是受方法自身所限制.OC-SVM和GDD方法都只用目标类别的样本进行训练,而完全不考虑未知类别样本的信息.而BSVM方法和C-SVM方法则使用目标类别样本和大量未知类别样本共同进行训练,样本数量大大多于OC-SVM方法和GDD方法.而基于支撑向量的方法输出结果都对待定参数的选取十分敏感.此外,由于训练样本和检验样本都为人工选定,这将不可避免地带来误差.虽然我们可以人工设定训练样本中的离群比例,但是训练样本中的实际离群比例是无法得知的.
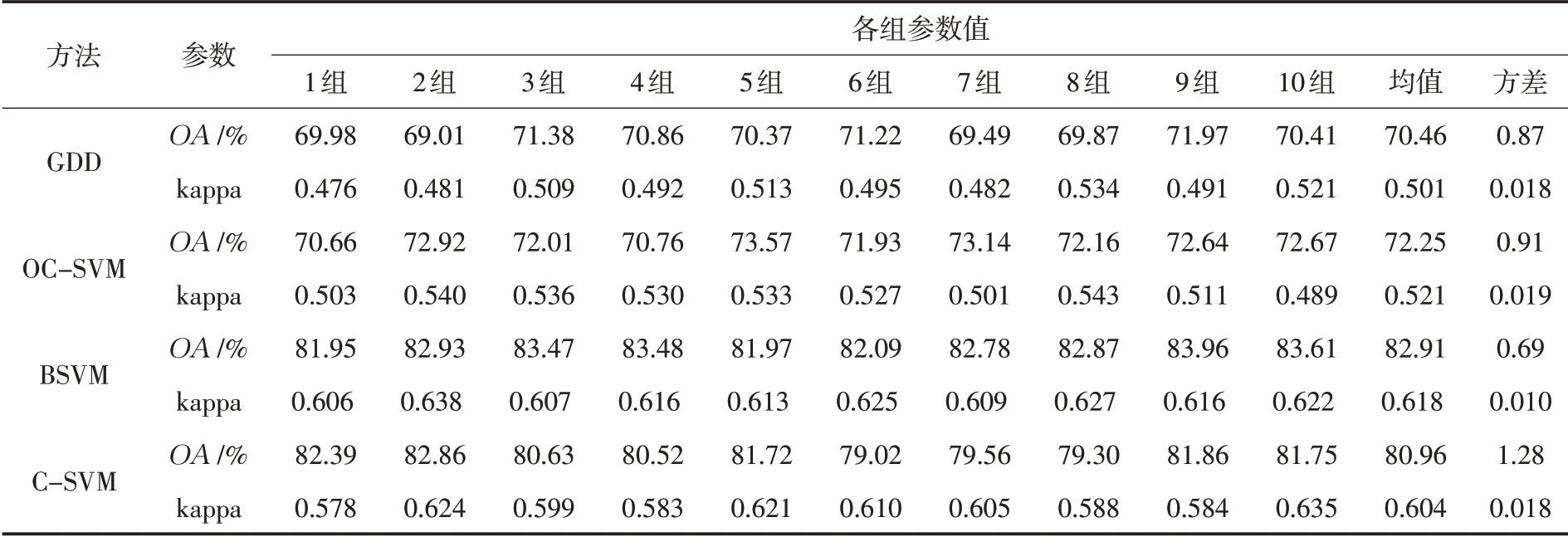
表2 四种方法10组样本下的OA 及kappa
在单类分类方法中,所有已知类别的训练样本都属于目标类,而未知类别的样本则既可能属于目标类别也可能属于非目标类别.所以对于一些单类分类方法就相当于用目标类别样本和未知类别样本来训练一个二类分类器,或者说,用不纯的样本训练二类分类器,如BSVM 方法和C-SVM 方法.而一些单类分类方法,如OC-SVM方法和GDD 方法,则根本不用未知类别的样本.实验证明,未知类别样本的信息可以帮助有效提高分类精度,利用了未知类别样本信息的BSVM方法和C-SVM方法比不用未知类别样本信息的OC-SVM方法和GDD方法效果更好.
比较C-SVM 方法和BSVM 方法的原理可以看出,二者的区别在于前者没有对目标类别和非目标类别分别设置惩罚参数,只是单纯用目标类别样本和一组未知类别的样本进行分类,将未知类别样本代表的类别训练成非目标类,样本不纯不可避免地给分类结果带来误差.而未知类别样本为随机选取,并不知道其中目标类和非目标类的比例.C-SVM方法的分类精度还和未知类别样本中非目标类所占的比例有关,理论上来说,这个比例越高,将得到越准确的分类结果.
BSVM 方法是利用未知类别样本分类的有效方法[13],但是他也存在一些不足.方法中有两个参数必须通过实验选取,而且最佳参数随训练样本的不同而显著不同.如果选用非线性函数作为核函数,参数的数量还将增加.
综上,在单类分类问题中考虑未知类别样本,增加训练样本数量,用目标类别样本和未知类别样本的信息共同训练分类可以有效地提高分类精度.利用未知类别样本的单类分类方法,如BSVM 方法,可以获得较好的分类结果,但是他依托于支撑向量分类理论,具有基于支撑域的单类分类方法的共同缺陷,参数多且输出结果对参数敏感.
3 结论
本文对几种典型的单类分类算法进行比较实验.包括高斯域(GDD)方法、二类支撑向量(C-SVM)方法、单类支撑向量(one-class SVM,OC-SVM)方法、以及Biased-SVM(BSVM)算法.基于支撑域的单类分类方法OC-SVM 和基于密度的方法GDD均可以完成对遥感影像的地物分类,BSVM 方法考虑了更多样本的信息,能够得到更好的分类结果.可见,在单类分类问题中,加入未知类别样本的信息,可以提高分类效果.且由于BSVM 方法针对目标类别和非目标类别样本设置了不同的惩罚参数,因此效果又好于将传统二类分类方法C-SVM 直接用于单类分类问题.这些方法的共同问题是参数多且需要人为设定,参数因训练样本的不同而不同,分类结果又对参数的变化较为敏感.这些问题都有待在日后的研究中进一步探讨.
猜你喜欢
科技创新与应用(2020年6期)2020-02-29 10:39:27
电子测试(2018年1期)2018-04-18 11:52:35
北京理工大学学报(2016年6期)2016-11-22 11:17:22
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
电视技术(2016年9期)2016-10-17 09:13:41
系统工程与电子技术(2016年7期)2016-08-21 13:59:00
新校长(2016年8期)2016-01-10 06:43:59
商事法论集(2014年1期)2014-06-27 01:20:42
电测与仪表(2014年15期)2014-04-04 12:05:20
