
大数据分析与计算系统设计
2020-01-16 10:50张启涛张洪瀚李俊玲
经济技术协作信息 2020年2期
◎张启涛 张洪瀚 李俊玲
一、系统概述
大数据分析系统,通过数据收集采集功能,将生产业务数据进行收集和清洗。按照资源前置库以及交易数据资源库进行数据收集和清洗。数据通过数据交换平台实现从各平台到中心前置库。
交易信息资源库主要包括交易平台运行过程中涉及到的各类数据信息,如交易信息库、主体信息库、专家信息库、信用信息库、监管信息库等。
数据采集、数据分类后实现统计分析、交易动态分析、专题分析和智能分析。
各业务应用系统提供基础的数据源,通过ETL过程实现数据源的抽取、转换、加载等进入ODS数据库中,基于ODS数据库中的数据进一步的进行ETL,数据进行数据仓库中进行数据的加工,实现数据集市、主题模型的建立等处理,最后以应用的形式进行对外的展示,如图1所示。

图1 系统设计图
二、结构设计
大数据分析子系统将数字化招采平台、其他业务系统、外部系统等进行统一的数据采集,建立共享资源目录,并提供统一的数据共享能力,使数据得到有效利用。再针对不同类型数据采用灵活的存储技术,搭建端到端数据治理体系,实现数据的全流程管控,按交易信息库、主体信息库、专家信息库、信用信息库、监管信息库等不同的主题整合数据采购数据仓库,支撑上层应用。结合业务需求,利用大数据技术对业务数据监控预警、建模和专题分析,为采购决策提供精准且有效的支撑,如图2所示。

图2 总体结构设计图
三、数据资源处理
1.数据处理。数据处理过程主要负责将数据采集后的数据抽取到数据源,然后对数据源进行清洗转换,同时对历史数据进行沉淀,形成基础数据层,再对基础数据层的数据进行汇总计算得到数据模型层和数据指标层的数据,总体流程通过统一流程调度模块进行调度和衔接,如图3所示。
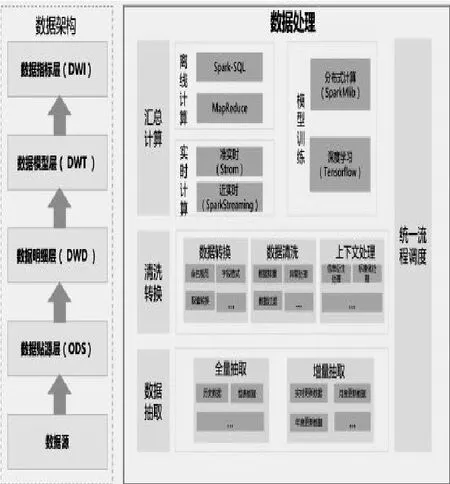
图3 数据处理示意图
2.清洗转换。数据清洗转换是对不符合标准规则的数据进行格式、取值、类型等方面的过滤或转换。例如对企业数据中的各个行业的单位进行统一转换,对从不同口径接入的企业数据中的名称进行清洗和统一,对爬虫数据进行过滤和去除重复。
数据清洗转换包括三部分:上下文信息处理、数据转换和数据清洗。
上下文信息处理:在数据源中存在大量的上下文信息,生产系统只有这类信息的原始信息,将原始信息内含的丰富的分析信息内容通过信息衍生处理和标准化处理,形成形成基础数据层的数据。
数据转换:通过对数据进行字段命名规范化、时间字段的统一和特殊字段的格式或取值转换等操作,形成基础数据层的数据。在通过对源数据信息的梳理,异常数据情况的识别,建立从源数据到目标数据的映射规则,做一定的计算、合并和拆分等转换操作。
数据清洗:通过对数据进行排重,异常字段处理和无效数据过滤等操作,形成基础数据层的数据,使基础数据层的数据更精确更有意义的过程。数据清洗是数据整合中的一个重要环节,数据清洗直接影响了数据装载到数据库中的清洁度与准确度,关系到前端数据统计分析的可靠性及可信赖程度,如图4所示。
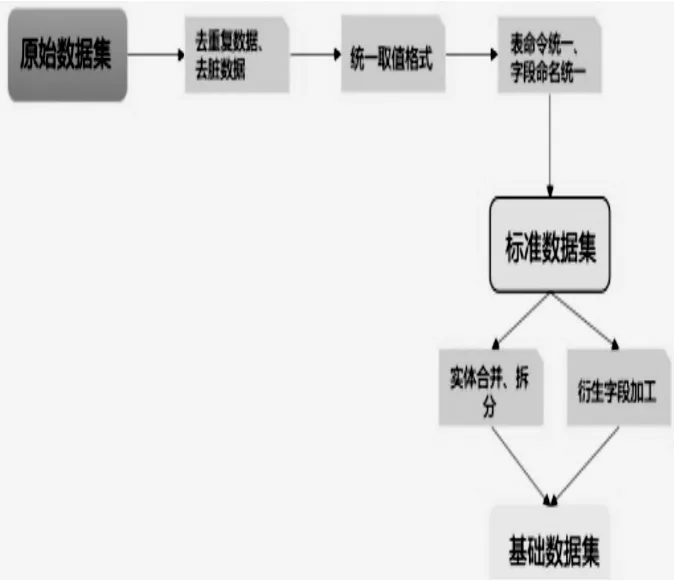
图4 数据清洗示意图
去重复数据、去脏数据:去掉原始数据集里的重复数据以及脏数据。例如某条记录里,如果年龄字段的值小于零,则该条记录就是脏数据,需要予以剔除。
统一取值格式:统一字段的取值格式。例如当字段为时间类型时,那么统一格式为YYYY-MM-DDhi24:mi:ss;如果字段是数值型,如收入数据,则统一保留六位小数。
表命名统一、字段命名统一:统一表的命名方式,表字段的命名方式。比如收入字段,原始数据集里可能命名为income、fee、charge等等,可统一为其中一种命名方法。
实体合并、拆分:实体合并,是将不同系统里相同的实体进行合并,形成统一的数据实体;实体拆分,是将同一个实体里,代表不同的业务或者范围的内容拆分成多个实体,比如,将操作流水表的内容进行拆分。
衍生字段加工:将用途范围广、使用频繁、基础性强的指标,加工到基础数据集里,从而提高数据的使用效率以及同一数据口径。
数据清洗转换通过配置进行管理,生成对应清洗、转换规则关系映射表,系统通过调用、匹配该关系映射表,实现对原数据的自动清洗和自动转换,生成标准数据集,从而完成数据清洗转换整体流程操作。
3.数据抽取。统一流程调度模块依据触发规则触发数据从数据装载层进行抽取。数据抽取过程是针对数据装载层中不同的数据源进行全量或增量的抽取的过程。全量抽取是针对历史数据,维表数据等需要一次性获取全量的数据的抽取方法;增量抽取是针对源系统每天产生的增量数据进行抽取,增量抽取以源系统记录的发生时间做为增量的标志,每次抽取之前首先判断记录最大的时间,然后根据这个时间取大于这个时间所有的记录。例如对采购信息相关数据等按照实时更新或按照月度更新的数据需要采用定时增量抽取的方式进行抽取。
四、数据计算
数据计算就是依据不同的数据模型,根据数据实效性要求和不同的计算复杂度采用不同的计算工具和方法对数据进行计算,最终得到主题模型所需的数据。根据主题模型可分为离线计算、实时计算、模型计算,如图5所示。

图5 数据计算示意图
1.离线计算。离线计算:主要是针对数据量较大,但实时性要求不高的数据,智慧采购系统中月度、季度、年度等数据需大量数据汇聚运算及信用评价等模型需要迭代式运算,可通过封装HQL/SparkSql语句,基于MapReduce/Spark分布式计算框架进行数据模型计算,通过azkaban任务调度工具对计算任务进行编排和统一调度管理,实现多种类型和数据体量较大的数据的批量运算。
2.实时计算。对于准实时应用,可采用开源Storm流式技术框架来实现。Strom可以方便的在一个计算机集群中编写与扩展复杂的实时计算,每秒可以处理数以万记的消息。基于其本身的技术特点和业务场景实效性要求,可以用来处理互联网爬虫数据,实时的计算处理爬虫获取的即时数据,不会出现大量数据积攒的延迟,保证整个系统向提供用户极好的应用体验。
3.模型计算。针对数据模型计算,可利用基于Tensorflow和SparkMlib等成熟的计算框架进行实现。其中SparkMlib已实现部分数据挖掘算法,已解决分布式计算问题。
总结:在实际应用场景中针对趋势预测,分类等需求,首先用历史数据进行模型训练和校准,训练好的模型存入模型库,在新的批次数据到来时,统一流程调度模块逐一调用模型库中的模型,对新的数据进行计算。从数据建模系统中提取对应的模型代码,应用于模型计算。
猜你喜欢
江苏科技信息(2022年16期)2022-07-17
新生代(2018年16期)2018-11-13
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
电脑知识与技术(2016年31期)2017-02-27
党政干部学刊(2015年7期)2015-12-24
图书馆建设(2015年10期)2015-02-13
新世纪图书馆(2014年7期)2014-09-19
图书馆建设(2014年3期)2014-02-12
中南民族大学学报(自然科学版)(2012年4期)2012-11-26
中国土地科学(2011年11期)2011-03-20
