
基于回溯法的中文分词技术
2020-01-16 05:57:04周寅黄鋆
电子技术与软件工程 2019年21期
文/周寅 黄鋆
1 引言
在海量文本数据处理的当下,多个领域运用到自然语言处理的技术,在多个任务处理中,任重而道远的关键技术—中文分词。在中文信息处理中,中文分词占据着重要的地位,然而在中文分词技术中,歧义词和未登录词是该技术的重难点。清华大学的黄昌宁老先生[2],总结出了中文分词存在的四个重难点:
(1)汉语切分的规范问题;
(2)分词和理解谁先谁后;
(3)中文分词出现的歧义消解;
(4)识别未登录词。
2 基于回溯法的中文分词技术的研究
对文本数据的标注大致分为三种:
2-tag:对中文文本进行标注I,O。I表示词首;O表示词尾。
例如:武汉船舶职业技术学院。
武 I 汉 O 船 I 舶 O 职 I 业 O 技 I 术 O 学 I 院 O
4-tag:对中文文本进行标注S,B,M,E。S表示字单独成词;B:表示词的第一个字;M:表示词的中间位置的字;E:表示词的位置位于词尾。
例如:武汉船舶职业技术学院。
武 B 汉 E 船 B 舶 E 职 B 业 E 技 B 术 E 学 B 院 E 。 S
6-tag:即对文本中词语进行S,B,M1,M2,M3,E标注。S:表示文本中的字单独成词;B:表示文本中的字所在词语中的首位;M1:标识词组首个字符;M2:标识词组第二个字符;M3:标志文本中词语的中间位置;E:标志文本词尾。由于在中文词典中,词语的最长极限就是六个字构成的词语。
根据字向量的技术,将文本数据中的有用信息进行学习,生成字向量。利用条件随机场,对文本数据中的生成的标签进行学习,产生最优解。
我们的方法,利用回溯法中的左剪枝法,将词标注的出现关联词相同的情况,将其剪枝;利用右剪枝法,将单独成词的后序文字剪掉,节省了时间复杂度,因此使得分词的技术达到最佳。回溯法模型中文分词如图1所示。
实验结果如图2。
根据图2而言,在准确率中,调剂随机场结合词向量的技术明显优于单纯的条件随机场技术的中文分词,然而相对于回溯法的中文分词技术,要明显的不足。在召回率方面,我们的技术明显优于前两者,并且F值也是要高于前两者。详见表1。

表1
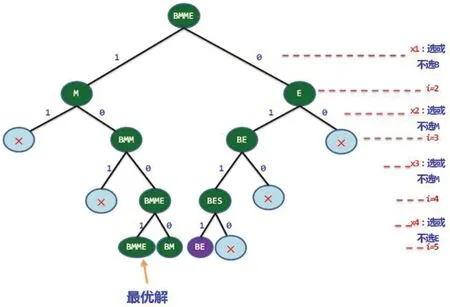
图1:回溯法模型中文分词
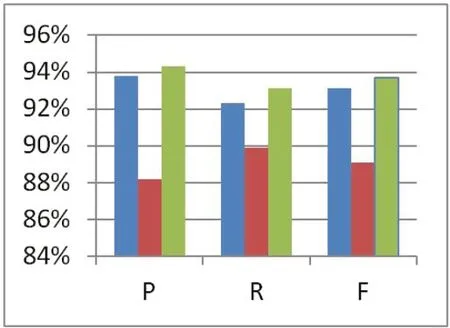
图2:搜狗语料库实验对比图
3 实验小结
实验中我们利用回溯法进行对文本的操作,发现用我们的回溯法改进的中文分词技术比传统的条件随机场方法中的准确率要高出5.9%,相对条件随机场与词向量的合作要高出0.6%。召回率也高出了条件随机场的3.3%,比条件随机场和词向量的要高出0.8%。在F值中也要明显的优于前两者。
4 展望与发展
今后的学习中,我们将进一步利用基础的算法分析案例,对中文分词进行改进与优化,使得我们的精确度和召回率都有所提升。
猜你喜欢
保健医苑(2022年5期)2022-06-10 07:47:22
成都信息工程大学学报(2021年6期)2021-02-12 03:00:54
考试与评价·八年级版(2020年5期)2020-10-29 05:42:35
鸭绿江·下半月(2019年7期)2019-11-05 05:32:22
小说月刊(2017年11期)2018-01-03 07:50:55
西南交通大学学报(社会科学版)(2017年4期)2017-12-02 19:02:02
东方教育(2017年14期)2017-09-25 16:53:37
天津诗人(2017年2期)2017-03-16 03:09:39
现代语文(2016年9期)2016-11-14 09:03:50
小学生时代·大嘴英语(2016年6期)2016-07-02 20:13:31
