
边缘学习:关键技术、应用与挑战
2020-01-15 06:19:42卢健圳伍沛然夏明华
无线电通信技术 2020年1期
吴 琪,卢健圳,伍沛然,王 帅,陈 立,夏明华∗
(1.中山大学 电子与通信工程学院,广东 广州 510006;2.中山大学 电子与信息工程学院,广东 广州 510006;3.南方科技大学 电子与电气工程系,广东 深圳 518055)
0 引言
随着移动通信技术和互联网应用的快速发展,智能终端及其产生的数据都经历着前所未有的爆发式增长。 美国思科公司的预测数据显示,到 2020 年全球范围内的智能终端数量将达到 750 亿台[1];国际数据公司(Internation Data Corporation,IDC)的预测数据显示, 到 2025 年全球数据量将达到 175 泽字节[2](ZB,1 ZB = 1021Byte)。 与此同时,人工智能(Artificial Intelligence,AI) 技术在经历60 余年的跨越之后正处于新一轮的发展浪潮。 越来越多的 AI 应用不断改变着人们的工作和生活方式,智能家居、自动驾驶、智慧城市等新兴应用也开始进行商业部署。 一方面,现象级的数据量为 AI 技术的发展带来新的机遇;另一方面,为了实现 AI,也需要庞大的通信资源和计算资源来支持海量数据的传输与处理。 常见的解决方案是将数据回传到云端的高性能服务器进行处理,即云计算。 然而,基于云计算的集中处理方式在数据传输过程中不可避免地消耗大量的通信资源并引起较大的时间延迟;而且,物理上受限的通信资源 (例如带宽) 将限制系统的可扩展性;最后,用户数据在公用网络中的传输也会带来较高的数据安全及隐私泄露风险。
为了解决云计算存在的上述问题,近年来研究人员提出了基于边缘计算的新型数据处理方式。 从原理上讲,边缘计算是指利用网络边缘的计算资源就近处理终端设备产生的数据,从而降低从终端到云端的通信开销和时间延迟。 为了进一步适应分布式大规模数据处理,将边缘计算与机器学习相结合,产生了“边缘学习”(edge learning)的思想[3-4]。 简言之,边缘学习是指一种将机器学习 (尤其是指深度学习) 部署在网络边缘形成的AI 实施架构。 换句话说,在边缘学习里,以前部署在云端的机器学习等算法下沉到网络边缘侧,更靠近用户终端设备,从而将网络架构分为了“云端-边缘端-用户终端”三级架构。 在实际系统中,边缘端可以由部署在蜂窝基站等网络接入点的边缘服务器组成。 通过整合用户终端、边缘端和云端上的计算资源,边缘学习能将深度神经网络(Deep Neural Network,DNN)等高级的机器学习算法灵活高效地部署在网络的不同物理实体上,完成模型的训练和应用。 相对地,将基于 DNN 等机器学习算法的云计算称为“云学习”(cloud learning)。
云学习和边缘学习之间的主要区别在于学习环境:在云学习中,海量数据被汇聚到单一的数据中心进行计算和分析;而边缘学习执行的是分布式数据处理,尤其强调将计算和处理能力从数据中心下沉到网络边缘,并利用智能实体(例如网关,执行数据的计算和分析任务)。 通过在边缘端提供内容缓存、服务交付、存储和终端管理等功能,可以显著减轻网络通信负荷并缩短网络响应时间。 相对于云学习,边缘学习的优势主要体现在传输时延、安全与隐私性、系统的可扩展性和通信开销等4 个方面。
(1) 传输时延
一般来说,处理数据花费的时间越长,数据与待执行任务之间的相关性就越差。 例如,对于自动驾驶来说,时延至关重要,可能短短几秒之后汽车收集到的有关道路和邻近车辆的大多数数据就已经变得毫无用处。 因此,许多时延敏感场景并不允许在终端设备和云之间来回传输数据。 而边缘学习则能够在靠近数据产生的位置进行数据处理,从而缩短响应时间,使数据更加有用和可操作,数据处理结果与待执行任务更加相关。
(2) 安全与隐私
当用户终端设备与云之间的数据传输不可避免时,依赖可操作数据的关键业务和运营流程将变得非常脆弱。 传统的云学习架构本质上是集中式的,这导致用户终端特别容易受到分布式拒绝服务(Distributed Denial of Service,DDoS)的攻击以及断电的影响。 相反,边缘学习将处理、存储和应用程序分布在广泛的边缘设备上,使得任何数据传输中断都不至于让整个网络陷入瘫痪。 而且,由于更多数据在本地设备上进行处理避免了在公用网络中传输,边缘学习还可以减少处于安全与隐私暴露风险中的数据量。
(3) 可扩展性
在云学习的架构中,一个庞大的数据中心不可或缺,但中心的建立和运营成本十分高昂。 而且,除了大量的前期建设成本和日常维护之外,数据中心还需要根据需求的变化不断进行升级和扩展。 而边缘学习提供了更灵活、更低成本的解决方案,可以将计算、存储和分析功能尽可能部署到更低廉且更便于部署的边缘设备中,同时这些设备位于更靠近用户的位置。 从而,企业可以利用这些边缘设备来灵活扩展企业内部网络系统的计算能力、覆盖范围和业务功能。
(4) 通信开销
因为不同数据的内容各不相同,它们蕴含的价值也不同,所以,将所有数据同等重要地传输到云端进行处理显然是低效的。 而边缘学习则可以对数据进行分类处理,并且在边缘位置保留尽可能多的数据,从而降低通信开销并节省传输数据所需的昂贵带宽。 值得注意的是,边缘学习并不是要消除对云的需求,而是要优化传输的数据流以最小化通信开销。
尽管边缘学习能够缓解云学习的数据传输和处理压力,但在一个复杂网络中实施边缘学习也面临诸多挑战。 首先,如何灵活地整合、调配和使用分布式的计算资源是边缘学习要解决的问题;其次,边缘学习系统中也包含了大量数据传输的过程,如何通过降低传输时延和提高通信质量等方法优化数据传输是高效实施边缘计算的关键。 最后,系统的物理实现、隐私和安全也都面临新的挑战,同时也带来新的研究与发展机遇。
1 关键技术
图 1 是一个基于边缘学习的网络架构,它包含一个云数据中心、多个边缘服务器和大量用户终端。用于实现AI 的机器学习算法(例如深度学习)可以分布式地部署在云端、边缘端以及用户终端。 为了开发高效、安全的边缘学习系统,本节首先阐述分布式训练策略和面向边缘学习的数据传输方法,这2 项技术分别聚焦于提高计算和通信的有效性;然后,为了优化系统的整体计算性能,还将讨论计算和模型卸载技术。
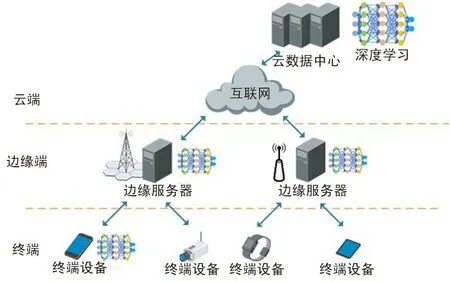
图1 基于边缘学习的网络架构Fig.1 Edge learning based network architecture
1.1 分布式训练
为了训练机器学习模型,传统上采用集中式训练方法并要求将训练数据汇聚到云端的数据中心。在机器学习技术发展之初,基于强大的数据收集和处理能力,集中式模型训练在众多大型 AI 公司(例如 Google,Facebook,Amazon)得到广泛应用。 但这种集中式训练方法会涉及用户数据的隐私问题。 例如,移动电话用户的手机终端通常保存着用户的隐私敏感数据,为了在这种集中式训练方法下获得更好的机器学习模型,移动电话用户不得不通过将存储在手机中的个人数据发送到 AI 公司的云上来交易自己的隐私。 与集中式训练不同,分布式训练是在靠近用户终端的多个边缘设备之间进行的,这样可以减少 AI 公司窥探用户隐私和数据传输过程中的数据安全风险。
实现分布式训练主要有 2 种模式:模型并行和数据并行。 在模型并行模式下,分布式系统中的不同设备负责某个复杂模型中不同部分的计算。 例如,可以将神经网络中的每一层运算分配给不同的设备,而在数据并行模式下,不同的设备拥有完整的学习模型,但每台设备仅持有部分数据。 相对于模型并行化,数据并行化在实现难度和集群利用率方面都存在优势,因此数据并行化是多数分布式训练的首选,也是本节讨论的对象。
从网络拓扑结构上看,分布式训练可以分为主从式结构和非主从式结构。 如图 2 所示,主从式结构可以实现终端设备与边缘服务器之间的模型交互。 近年来,Google 公司提出的联邦学习就是基于主从式结构。 以移动电话用户为例,手机每天都会产生大量数据,这些数据包含有关用户及其个人偏好的高价值信息。 例如,他们访问过哪些网站,使用过哪些社交媒体应用程序,以及经常观看哪些视频类型等。 利用这些数据,电信运营商可以构建个性化的机器学习模型以提供个性化服务,从而改善用户体验。 与传统的集中式训练方法不同,联邦学习允许用户终端独立构建自己的机器学习模型并将模型更新参数(不包含用户隐私信息的原始数据)上传给边缘服务器;边缘服务器利用收集到的多个用户的不同模型更新参数来更新一个全局模型,这个过程被称为“模型更新聚合”;最后,边缘服务器将全局模型的更新参数分发给用户终端。 显然,联邦学习既为 AI 开辟了全新的计算范式,又提供了一种用户隐私保护机制。 由于用户终端的计算资源变得越来越强大,尤其是随着专用 AI 芯片组的出现,AI 模型训练正在从云和数据中心转移到终端设备,运营商可以有效地利用终端设备内部的分散计算资源来训练机器学习模型。 考虑到全球有数十亿的高性能移动终端设备,这些设备累积的计算资源远远超过了世界上最大的数据中心。 因此,基于主从式结构的联邦学习将会极大地推动AI 的发展与应用。
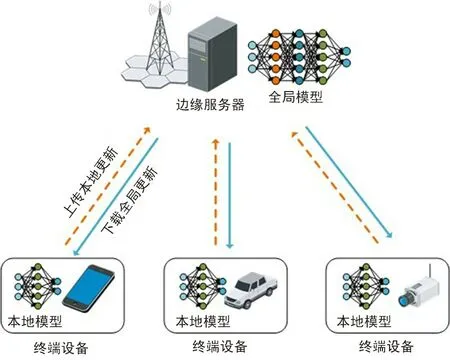
图2 主从式结构Fig.2 Master-slave structure
如图 3 所示,非主从式结构主要通过点对点交互本地模型更新参数来进行设备之间的模型更新,并最终收敛到一组统一的模型参数。 从网络架构上看,不同用户终端利用自己的训练数据进行本地模型参数更新,再将更新参数信息传递给邻居节点,最终使得不同终端的机器学习模型收敛到一组共同的参数。 该结构的优点在于具有较低的通信开销、可扩展性(甚至无需专门的边缘服务器参与)和潜在的隐私保护解决方案,但是模型收敛速度较慢甚至可能收敛到次优解。
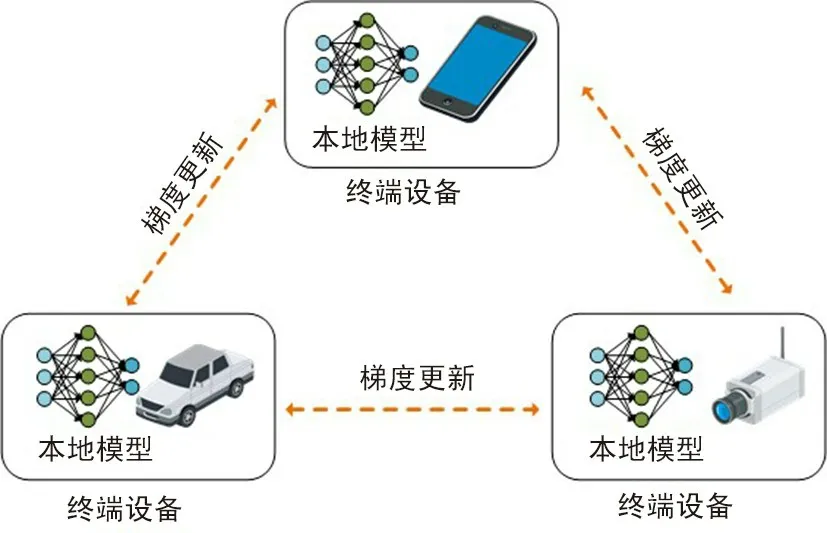
图3 非主从式结构Fig.3 Distributed structure
为了提高分布式模型训练的计算性能、降低通信负荷及提供更安全的数据保护,表 1 总结了主从式和非主从式模式的基本思路和对应的关键技术,包括聚合频率、梯度压缩、点对点通信和区块链技术。

表1 分布式模型训练Tab.1 Distributed model training
1.1.1 聚合频率
在主从式网络拓扑结构下,一般采用分布式随机梯度下降(Stochastic Gradient Descent,SGD)算法来更新本地或全局模型参数,其不仅是训练人工神经网络的标准算法,也是在现代数据分析平台上广泛实施的最流行的模型训练优化方法。 更具体地说,可将 SGD 分为同步和异步2 种方式。 同步 SGD 在优化的每轮迭代中,会等待所有的终端设备完成梯度计算,然后边缘服务器再对每个终端设备上计算的梯度信息进行汇总,待终端设备接收到全局模型的更新参数后,各个终端设备将同步更新其参数并进入下一轮迭代。 由于同步 SGD 要等待所有的终端设备完成梯度计算,因此同步 SGD 的计算速度会被运算效率最低的终端设备所拖累。 虽然同步 SGD 通常收敛较慢,但会收敛到更好的全局模型参数。 异步 SGD 在每轮迭代中,每个终端设备在计算出随机梯度信息后直接将参数更新到边缘服务器,不再等待所有的终端设备完成梯度计算。 因此,异步 SGD 的迭代速度较快。 然而,异步 SGD 虽然相较于同步 SGD 收敛更快,但是用以更新模型的梯度信息是有延迟,因此会对算法的精度带来影响,即通常会收敛到次优的全局模型参数。 设计分布式训练算法的关键通常在于如何使同步 SGD 收敛更快,或者如何使异步 SGD 收敛到更好的全局模型参数[4]。
在主从式结构中,模型聚合频率(终端设备与边缘服务器的通信频率)至关重要。 文献 [5] 提出一种用于分布式机器学习的延迟聚合梯度算法,其设计原则是对变化缓慢的梯度进行自适应重复利用,从而减少实现目标精度所需的通信回合。 文献 [6] 提出一种基于通信约束下并行计算环境中深度学习随机优化的弹性平均算法。 该算法的基本思想是对于每个设备执行更多的本地训练计算并在同步更新之前允许偏离全局共享参数,即设备与边缘服务器以弹性方式实现通信,从而降低同步和异步 SGD 训练方法的通信开销。 文献 [7] 提出一个称为协作 SGD 的统一框架,该框架包含了现有具有有效通信的SGD 算法,例如弹性平均算法和基本分布式 SGD 算法。 通过分析协作 SGD,为现有算法提供了新颖的收敛保证。 此外,该框架能够为设计新的实现有效通信的 SGD 算法提供思路,从而在减少通信开销和实现快速收敛之间达到最佳平衡。
训练数据的独立同分布(Independent and Identically Distributed,IID)采样对于确保随机梯度是整体梯度的无偏估计是很重要的。 但实际上,假设每个边缘设备上的本地数据始终为 IID 是不现实的。 针对这一问题,文献 [8] 证实,可以通过创建一个在所有边缘设备之间全局共享的数据子集来改善对非 IID 数据的训练精度。 文献 [9] 提出一种基于迭代模型平均的深度网络联合学习的 FedAvg 算法,核心思想是增加对设备端本地更新的次数。 通过对不同模型架构和数据集的广泛评估,实验结果表明该方法对于非 IID 数据分布是稳健的,且与同步 SGD 相比,通信开销大大降低。 文献 [10] 提出一个称为 FedProx 的新框架,证明在非IID 环境中,相对于 FedAvg,FedProx 表现出更加稳定和准确的收敛行为。
当客户端受到严格的计算资源约束时,增加设备端本地更新次数是不切实际的。 针对上述问题,文献 [11] 从理论角度分析分布式梯度下降的收敛边界,并在此基础上提出一种控制算法,该算法可以实现本地模型参数更新和全局参数聚合之间的最佳权衡,从而在给定资源预算下将损失函数最小化。文献 [12] 提出一种名为 FedCS 的更新聚合协议,可以根据设备的资源状况积极管理设备端,同时高效地执行联邦学习。 协议的具体操作步骤为:首先,边缘服务器要求随机终端设备参与系统当前的训练任务,收到请求的终端设备将资源信息反馈给边缘服务器;然后,待边缘服务器收到所选设备反馈的资源信息后,确定可以进行后续步骤的终端设备以在一定时间内完成任务训练。 该项协议允许边缘服务器聚合尽可能多的终端设备的参数,并加快机器学习模型的收敛。
1.1.2 梯度压缩
除了降低模型聚合频率之外,另一种减少通信开销的方法是梯度压缩。 在具体实施时,梯度压缩包括梯度量化与稀疏化2 个步骤,其中,梯度量化是通过将梯度向量中的每个元素量化为有限位低精度来执行梯度向量的有损压缩,而梯度稀疏化则意味着只传输部分梯度矢量[3]。
关于梯度量化,文献 [13] 提出一种基于 SGD 的梯度压缩方案:量化 SGD(Quantized SGD,QSGD)。 QSGD 平滑地权衡通信带宽和收敛时间,设备可以调整每次迭代发送的位数,从而实现最优的通信开销。 文献 [14] 提出TerGrad 的量化方法,将梯度量化为三元级 {-1,0,1} 以达到用低精度梯度代替参数信息进行同步的目的,从而减少通信开销。为了消除量化误差,文献 [15] 提出另一种新颖的自适应量化方法,其基本思想是仅对梯度信息的有限位进行量化。
关于梯度稀疏化,文献 [16] 提出了一种称为边缘随机梯度下降(edge SGD,eSGD)的新方法,可以将卷积神经网络(Convolutional Neural Network,CNN)训练模型所需的梯度信息压缩为原来的 90%,而不会降低收敛速度。 eSGD 包括2 种机制:首先,eSGD 确定哪些梯度坐标重要,并且仅将重要的梯度坐标传输到边缘服务器进行同步;此重要更新可以大大降低通信开销。 其次,动量残差累积用于跟踪过时的残差梯度坐标,以避免稀疏更新导致的低收敛速度。 通过上述操作,eSGD 可以改善边缘学习过程中基于随机目标函数的一阶梯度优化,仿真结果证明 eSGD 是一种具有收敛性和实际性能保证的稀疏方案。 随着边缘计算设备数量的增加,通信开销会进一步提高,针对这一问题,文献 [17] 提出了一种稀疏二进制压缩(Sparse Binary Compression,SBC)框架。 SBC 将通信延迟和梯度稀疏化的现有技术与新颖的二值化方法和最佳权重更新编码相结合,将压缩增益推向新的极限,以允许平滑地权衡梯度稀疏度和时间稀疏度来适应学习任务的要求,从而大幅降低分布式训练的通信开销。 文献[18]提出一种随机删除的思想,通过随机删除随机梯度向量的坐标,并适当放大其余坐标,以确保稀疏的梯度无偏。 该思想可以最小化随机梯度的编码长度,从而降低通信开销。 为了有效解决最优稀疏性问题,他们还提出几种简单快速的近似解算法,并为稀疏性提供了理论上的保证。 文献 [19] 提出一种适用于异步分布式训练的双向梯度稀疏化方法,通过压缩交换信息的方式来克服通信瓶颈。 该方法允许终端设备从边缘服务器下载全局模型和本地模型的差异(而不是全局模型),并且将模型差异信息稀疏化,从而减少交换信息的通信开销。
1.1.3 点对点通信
到目前为止,本文考虑的是基于多个终端设备与边缘服务器进行通信的主从式结构场景,边缘服务器的存在有助于确保所有设备都收敛于相同的模型参数,但同时通信瓶颈的问题也更为严重,特别是边缘服务器的带宽直接影响数据传输的能力。 为了克服这个问题,通过将边缘服务器移除,构成了在终端设备间交互信息的非主从式结构,即通过点对点交互信息来使得不同终端设备收敛到相同的模型参数。
文献 [20] 提出让终端设备异步训练并以对等方式通过网络进行通信,而无需任何边缘服务器来维护系统的全局状态。 文献 [21] 提出一种分布式学习算法,在该算法中,终端设备通过汇总来自单跳邻居的信息来更新其参数信息,从而学习一种最适合整个网络的模型。 文献 [22] 提出如图 4 所示的 Gossip 算法,其中,每个终端设备基于其训练数据计算自身的梯度更新,然后将其更新结果随机传递给相邻设备。 文献 [23] 进一步发现 Gossip 算法的平均时间取决于表征该算法的双随机矩阵的第二大特征值,于是利用问题结构设计出 Gossip 聚合算法,使得收敛更快。 文献 [24] 将 Gossip 聚合算法与 SGD 相结合,提出 Gossip SGD(GoSGD)算法并应用于深度学习中。 该算法中每个独立的终端设备处有一个相同的 DNN 模型,并交替进行梯度更新和混合更新2 个步骤。 考虑到分布式 SGD 的同步方法虽然在大规模场景方面能表现出最大性能,但梯度更新需要同步所有终端设备,这在边缘服务器出现故障或滞后时无法适应。 文献 [25] 提出一种 Gossiping SGD 异步算法,该算法用 Gossip 聚合算法代替同步训练中的 all-reduce 操作,以保留同步 SGD 和异步 SGD 方法的有利特性。 进一步,文献 [26] 将弹性平均算法和 Gossip 算法相结合,提出弹性 Gossip 算法。 通过使用跨多层感知器和CNN 结构对 MNIST 和 CIFAR-10 数据集执行分类任务,结果表明弹性 Gossip 算法与 Gossiping SGD 算法性能相当,但是通信开销大大降低。 文献 [27] 介绍另外一种基于 SGD 的 GossipGraD 算法,用于在大规模系统上扩展深度学习算法。 该算法可以在 SGD 的前馈阶段进行异步分布样本的混洗以防止过度拟合且能进一步降低通信开销。 文献 [28] 开发一种在网络计算中交换和处理神经网络参数信息的分布式系统,该系统把设备分为不同的组,并对每个组内的设备通过传统 Gossip 算法来更新模型参数。 然后,在组间通过增加聚合节点以使用联邦学习来共享参数,从而实现全局更新。
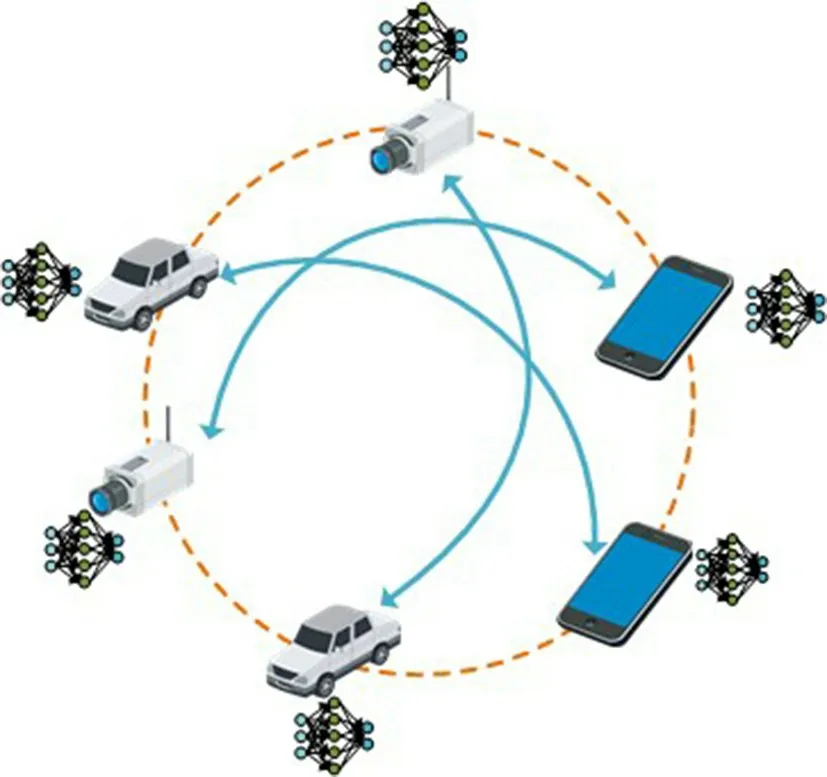
图4 Gossip 算法示意图Fig.4 Principle of Gossip algorithm
1.1.4 区块链技术
传统的主从式结构假设使用受信任的边缘服务器,学习系统的成功在很大程度上取决于边缘服务器的安全性,但其安全性容易受到攻击,甚至可能其本身就是恶意的。 区块链技术是通过去中心化和去信任的方式,利用块链式数据结构来验证与存储数据,利用密码学的方式保证数据传输和访问安全的一个集体维护可靠数据库的技术方案。 因此将机器学习与区块链技术相结合,可以更好地保护数据的隐私与安全。
文献 [29] 描述了一种分布式个人数据管理系统,该系统可确保用户拥有并控制数据。 具体来说,是通过实现一个协议,将区块链转变为不需要第三方信任的自动访问控制管理器。 文献 [30] 描述了一个新框架 ModelChain,以将区块链技术应用于隐私保护机器学习中。 每个参与设备都在不泄露任何私人信息的情况下为模型参数估计做出贡献。 文献 [31] 提出一种去中心化的隐私保护和安全机器学习系统,称为 LearningChain,不仅可以保护数据持有者的隐私,还能保证系统对恶意用户攻击(即拜占庭式攻击)的弹性。 具体来说,该系统包括区块链初始化、局部梯度计算和全局梯度聚集。网络初始化后,数据持有者根据公共损失函数和当前预测模型计算局部梯度。 然后,它们向网络中的所有计算节点广播局部梯度,该梯度受为一般学习模型设计的差分隐私方案所保护。 一旦计算节点达成共识,区块的权限持有者将使用一个高效容忍拜占庭式攻击的聚合方案来聚合局部梯度。 经过若干次迭代后,网络中的参与者可以在不暴露自己数据的情况下协作地训练一个学习模型。 为了更充分地解决数据的隐私和安全问题,文献 [32] 提出一种差分隐私 SGD 算法和一种基于误差的聚合规则,可以更有效地防止敌对终端设备试图降低模型准确性的攻击。
1.2 面向边缘学习的高效无线通信技术
在传统“云学习”场景中,移动设备与网络接入点 (Access Point,AP) 的通信信道被看做一条简单的数据 “管道”。 这是因为以云为中心的架构下,系统时延主要在核心网和大规模的云中心产生,系统设计也主要关注在后端的有线网络部分。 与此不同的是,边缘学习以边缘端作为系统架构的中心,大量终端与边缘端之间的数据和信令交互依托的是无线通信网络 (例如 WiFi、蓝牙、LTE 等)。 此时,无线网络的复杂性就成为限制系统性能的主要瓶颈。 与有线网络相比,无线通信网络需要面对更复杂的问题,主要包括:
① 信号在传输过程中会经历复杂的衰减、反射和折射等物理过程,由此造成信道的时变性、多径衰落和码间串扰等问题,因此需要信道估计和均衡等技术来实现更可靠的传输。
② 多个无线终端在同一空中接口下利用相同或相近的时间、频率和空间等系统资源进行相互通信,容易引起信号间的相互干扰,甚至造成在接收端不能正确恢复发送信号。 因此,多址访问和干扰管理等技术是抑制无线信号间相互干扰的必要手段。
③ 为充分利用宝贵的频谱资源,必须对无线终端进行严格的频率资源复用、分配和调度,以最大化系统的频谱效率,同时权衡系统的吞吐量和终端之间的公平性。
在移动通信、物联网等无线应用的边缘学习场景中,必须针对上述无线通信系统的复杂性,相应地设计面向边缘学习的多址访问、资源分配和编码等无线通信技术和策略。 事实上,通过对边缘学习系统中的无线通信子系统进行优化,能够显著降低终端与不同 AP 之间的通信时延,提高传输的可靠性。
另一方面,无线通信系统设计的首要目标是提高系统的可靠性和传输速率,但在边缘学习的场景中,实现快速的模型收敛才是最终目标。 因此,以提高训练速度为目的,结合机器学习的特点来设计无线通信系统可以更直接地提升系统整体性能[33-34]。同时,随着无线通信技术的快速发展,新兴的通信技术如多输入多输出 (Multiple-Input Multiple-Output,MIMO)、非正交多址和毫米波通信等技术也有望在未来应用于边缘学习系统中。 因此,通信与计算的有机结合将是边缘学习领域最重要的研究内容之一。 表 2 总结了面向边缘学习的通信子系统设计的3 个重要研究方向,以及其对应的基本思路和关键技术。

表2 面向边缘学习的通信子系统设计Tab.2 Communication subsystem design for edge learning
1.2.1 空中计算
空中计算 (Over-the-Air Computation,Air-Comp) 是一种利用无线信道的叠加特性实现在空中接口直接计算目标函数的通信-计算一体化架构[50]。 在传统的多址通信系统中,为了避免传输节点间的相互干扰,每个节点都需要通过某种多址方式来实现在不同信道的同时传输,如时分多址和正交频分多址 (Orthogonal Frequency Division Multiple Access,OFDMA) 等。 当通信系统容量受限时,系统的传输时延将随着传输节点数的增加而显著增加。事实上,当通信的目的仅仅是为了完成目标函数的计算时,将各点数据独立传输、解析后再计算目标函数的传统方法并不是最高效的。 与此相反,AirComp将空中信道作为一个天然的“聚合器”,通过它来自然叠加各节点的数据;然后通过在发送节点的预处理 (pre-processing) 和在聚合节点的后处理(postprocessing)实现目标函数的计算。 因此,AirComp 能够将计算和通信有机结合,也契合了上述联邦学习的主从式拓扑结构应用场景。 图 5(a) 表示传统的 OFDMA 传输,其中不同的线型表示相互正交的频率信道。 图5(b)表示AirComp 架构示意图,与OFDMA 相比,在 AirComp 架构中的边缘节点无需遵循正交传输准则,而是占用系统全部带宽资源,从而极大提高了传输速率和系统的可扩展性(边缘节点的数量不再受限于带宽)。
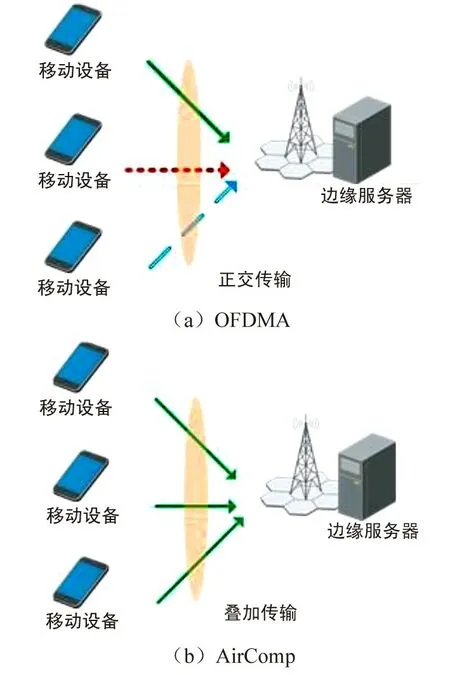
图5 OFDMA 和 AirComp 传输示意图Fig.5 Principles of OFDMA and AirComp transmissions
为了利用多址信道的叠加特性,AirComp 采用模拟调制的传输方式,同时要求各节点的同步传输和接收功率一致。 因此,AirComp 系统的实现除了需要对传输方式本身的设计,还需要研究发射功率控制和同步传输等关键技术。 通过对这些关键技术的研究和突破,AirComp 也开始被广泛应用于联邦学习的相关研究中:在模型训练的聚合阶段,所有终端节点同时使用全部的带宽资源传输各自的本地模型参数,从而显著降低聚合阶段的传输时延[35-37]。
文献 [35] 分别设计了基于数字调制的分布式随机梯度下降算法 (Digital Distributed SGD,D-DSGD) 和基于模拟调制的分布式随机梯度下降算法 (Analog Distributed SGD,A-DSGD)。 与 D-DSGD 相比,A-DSGD 能够采用更为灵活的功率控制策略,从而在终端平均发射功率受限的情况下实现较优的训练性能。 同时,A-DSGD 也为系统提供更好的扩展性,能够支持更多终端同时进行联邦学习,实现更准确的模型训练。 A-DSGD 与 D-DSGD 的比较说明了基于空中计算的联邦学习更适用于低功耗和带宽受限的边缘学习场景。 类似的,文献 [36] 设计了基于宽带模拟聚合技术 (Broadband Analog Aggregation,BAA) 的联邦学习系统。 利用模拟 OFDM 调制方式,BAA 实现了终端同时占用全部带宽的传输。 与此同时,BAA 考虑了衰落信道模型,通过信道翻转对终端发射功率进行控制,同时限制了信道质量差的终端的传输,一定程度上减少了传输的数据量。 虽然对终端传输的限制会造成训练参数的损失,但参数的损失也有助于降低模型过拟合的程度。 除此之外,文献 [36] 还研究了该场景下通信测度 (接收信噪比) 和训练测度 (训练参数的数量和多样性) 之间的折衷关系,为网络规划与优化提供参考。
作为对 A-DSGD 和 BBA 的改进,文献 [37] 在 A-DSGD 的基础上提出了 CWSA-DSGD 算法 (Compressed Worker-wise Scheduled Analog-DSGD)。除了采用模拟调制传输,CWSA-DSGD 还通过梯度稀疏化和差错累积的方法,减少聚合过程中的数据传输量,从而进一步加快训练速度。 与 BAA 只考虑信道状况的终端选择方式不同,CWSA-DSGD 在梯度稀疏化过程中衡量梯度信息的重要性,能够避免重要的梯度信息由于信道的衰落而丢失。 实验证明,在相同条件下,CWSA-DSGD 的模型训练准确度比 BAA 更高。
另一方面,各终端间的同步传输对于空中计算的实现也是至关重要的。 为了解决分布式相干传输 (Distributed Coherent Transmission) 中的同步问题,文献 [38] 在发送信号中携带与发射功率成比例的冗余信息,接收端通过解析冗余信息获得同步信息,系统只需保证简单的帧同步。 文献 [39] 提出一种 AirShare 策略,通过广播时钟消息作为节点的参考时钟,实现了各节点传输的严格同步。
1.2.2 通信资源分配
在传统的无线通信系统中,传输的所有数据都被认为是同等重要的。 因此,在保证传输可靠性的基础上,无线通信系统中资源分配的目的是通过对频谱等物理资源的分配实现最大化系统吞吐量等性能指标。 然而在面向应用和服务的 AI 场景中,单纯地通过资源分配策略的设计来提升上述指标不一定能直接换来服务质量 (Quality of Services,QoS) 的提升[51]。 在这种情况下,数据的“重要性”能够为资源分配策略的设计提供一个新的测度,通过保证“更重要”的数据优先和可靠地传输来保障服务质量。 基于这个思路,文献 [51] 设计了基于数据流重要性的传输控制协议。 协议首先将用户与服务器间交互的数据按照数据的重要性和服务时延要求划分为多个子集,然后优先传输更重要和时延敏感的数据。 实验证明,该协议能够在通信资源受限情况下保证用户及时获得所需的数据,从而保证服务质量。
对于边缘学习系统而言,设计基于数据重要性的通信资源分配策略也显得尤为重要。 这是因为在机器学习过程中,某些样本数据对模型的校正程度要优于其他数据。 因此,为了提高模型参数学习性能,更“重要”的数据应该受到特别重视。 换句话说,在使能边缘学习的通信过程中,除了通信的“可靠性”,数据的“重要性”也需要考虑。 对于这个问题,一个研究方向是基于数据重要性设计通信系统中的资源分配策略。 图 6 显示了一个基于数据重要性进行通信资源分配的机器学习模型训练过程,它根据实时模型对数据进行重要性评估,再根据评估结果,结合当前信道状态信息来执行通信资源分配。
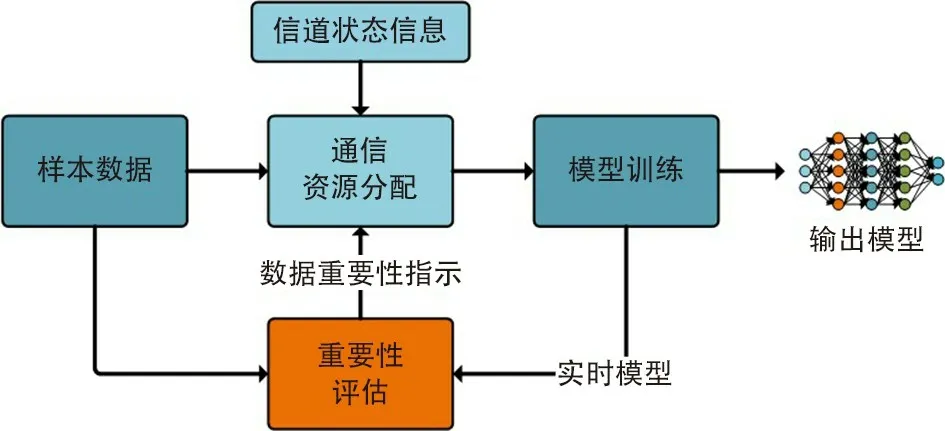
图6 基于数据重要性的通信资源分配Fig.6 Importance-aware communication resource allocation
在模型训练的过程中,不确定性越大的数据通常更有利于模型收敛[52]。 因此,数据的不确定性可以用于衡量数据的重要性。 基于此思路,文献 [40] 设计了一种基于数据重要性的自动重传请求策略 (Importance-Aware Automatic Repeat Request,Importance-ARQ)。 Importance-ARQ 考虑了集中式的边缘学习模型,终端设备将采集到的数据上传到边缘服务器用于模型训练。 在传输过程中,噪声等因素会造成数据与标签的错误匹配,因此需要通过重传保证样本的正确性。 在通信资源受限的情况下,Importance-ARQ 优先重传更重要的数据,直到达到期望的接收信噪比。 通过保证重要数据的传输,Importance-ARQ 能够尽可能提高模型训练的准确性。类似的,文献 [41] 提出了考虑数据重要性的终端调度策略,它能够优先调度需要传输更“重要”数据的终端设备,从而加速模型的收敛。 值得注意的是,文献 [41] 还引入了熵的概念来衡量CNN 训练过程中数据的重要性。 针对上述联邦学习场景,文献[42]提出以优化终端功耗为目标的通信资源分配策略,将更多的频带分配给计算能力较弱、信道条件较差的终端设备,并优先调度这些设备。 这样进行资源分配的目的是保持每个终端都可以尽可能地同步上传本地的训练参数,从而保证模型训练的准确性。 实验结果证明,随着训练时间的延长,采用上述策略的联邦学习系统在保证模型准确性的基础上,还能显著降低终端设备的整体功耗。 事实上,这样的资源分配策略与传统无线通信系统中追求最大化数据传输率和系统吞吐量的资源分配原则恰恰相反。 这也再次说明,为了提高边缘学习性能,必须对传统的无线通信系统和通信资源分配策略进行重新设计。
1.2.3 信号编码
在通信和计算中,编码被认为是一种有效抵抗“噪声”或实现数据压缩的方法。 在无线通信系统中,信源编码和信道编码通常用于对传输数据的预处理。 前者主要是通过压缩待传输数据量来提高传输的有效性,后者则是通过增加冗余数据来提高传输的可靠性。 而分布式计算作为通信和计算的交叉领域,也常常利用编码技术改善系统的性能。 例如,文献 [44] 提出基于编码的分布式计算 (Coded Distributed Computing),通过编码技术和充分利用终端上的存储资源减小分布式系统中的通信开销,实现计算和通信之间的折中;在此基础上,文献 [45] 考虑终端存储和计算资源受限的情况,研究了存储、计算和通信之间三者的折中,最小化系统的通信开销。 借鉴这种通过增加系统冗余 (计算量和存储量) 降低通信开销的思路,编码技术也能够被更广泛地运用到边缘学习的研究中。
在上述分布式训练中,分布式梯度下降(Distributed Gradient Descent,DGD)和分布式随机梯度下降(Distributed Stochastic Gradient Descent,DSGD)都是常用的模型训练算法。 这种将梯度计算任务分配到多个终端设备上的做法能够充分利用终端的计算资源,通过并行计算加快计算速度。 这种计算模式要求服务器在每次迭代中接收和聚合各个终端的梯度信息。 然而,由于终端性能不同,系统整体训练速度会受限于个别性能较差的终端。 为解决这个问题,一种方法是对梯度信息进行编码,即梯度编码。文献 [46] 给出梯度编码的一种基本方式。 其中,每个终端会计算多个样本数据子集的梯度信息,相应得到多个梯度向量;然后,再将这些梯度向量的线性组合上传到服务器,这就是梯度的“编码”过程。服务器通过解析每个终端上传的梯度向量来恢复出用于更新模型参数的梯度信息,即梯度的“解码”过程。 显然,由于每个终端上传的数据都能携带多个梯度向量,因此服务器只需接收部分终端的数据就能完整恢复所需的所有梯度信息。 从而避免个别终端“拖后腿”的情况,加快模型的收敛速度。 对于终端而言,这种编码方式增加了冗余的计算量。 因此,梯度编码也是一种通过增加冗余来换取系统整体性能提升的方法。
虽然文献 [46] 给出的梯度编码方式能够有效避免服务器等待终端上传梯度信息的情况,但这种方式对部分终端的“舍弃”也会造成计算资源的浪费。 考虑到这种情况,文献 [47] 提出部分梯度编码,在终端计算梯度的同时,将已经计算好的部分梯度信息上传给服务器,即梯度信息的计算和上传是同时进行的。 因此,即便是计算速度较慢的终端也能够尽量向服务器提供梯度信息,从而充分利用终端上的计算资源。 显然,部分梯度编码方式会增加系统的通信开销。 为克服这个问题,考虑到终端性能不同是造成计算速度差别的直接原因。 文献[48]提出基于终端异构性的梯度编码策略。 与文献 [46-47] 不同,该策略在划分数据子集时会对终端的计算能力进行评估,并根据终端数据处理能力不同来分配数据子集,对应不同计算量的计算任务。 从而减小了终端之间完成梯度计算的时间差别,同样能够避免训练速度受限于个别终端。
虽然梯度编码引入了编码的概念,但并未将编码与信号的传输过程结合。 事实上,为了避免模型的过拟合以及减少训练的数据量,深度学习中通常采用主成分分析和线性判别分析等方法对样本数据进行预处理,从而对样本数据进行降维。 既然在深度学习和无线通信2 个领域中都有数据预处理的必要性,一种提高边缘学习系统的学习效率和通信效率的方法就是将二者有机结合。 换句话说,可以将训练模型中的数据预处理过程与数据传输中的信号编码过程相结合,实现联合优化。
例如,文献 [49] 提出的快速模拟传输策略(Fast Analog Transmission,FAT)将信号编码和数据预处理更紧密地结合在一起:FAT 首先将终端设备上的样本数据通过格拉斯曼模拟编码 (Grassmann Analog Encoding,GAE) 映射到格拉斯曼流形空间上。 使用 GAE 的目的既是为了在边缘服务器使用格拉斯曼分类算法训练分类的 DNN 模型[53],也是为了下一步使用非相关的 MIMO 传输,从而减少信道估计造成的时延和信令开销;其次,FAT 通过线性模拟调制实现编码信号的模拟传输,相应地,在接收端做模拟检测和接收;最后,在接收端上将接收数据用于格拉斯曼分类训练。 应用了模拟 MIMO 传输的 FAT 能够在保证较优学习效率的同时,减小传输过程中的通信开销和时延。 虽然 GAE 会造成样本数据的类间距离减小而不利于分类,在文中称为自由度 (Degrees of Freedom,DoF) 的损失,但是 DoF 的损失能够换取信号对抗快衰落信道的鲁棒性。 这也说明,数据预处理和信号编码的联合设计能够提升边缘学习系统的整体性能。
1.3 边缘学习中的卸载技术
如上所述,深度学习相关的计算任务对计算、存储等资源的要求造成部署深度学习计算的困境:一方面,基于云计算的计算模型由于传输距离、网络带宽等限制,会不可避免地引入时延;另一方面,由于终端设备的电量和计算能力等资源的限制,终端无法承载更复杂的深度学习网络和密集计算。 随着边缘计算的发展,一种解决方法是在终端和云端之间引入边缘端,利用边缘服务器的计算资源卸载终端或云端的计算任务。 将计算任务卸载到边缘服务器上能够突破终端设备的资源限制和对云计算的依赖,以更快的速度处理更复杂的计算,从而显著降低服务时延。
近年来,边缘计算系统中的计算卸载策略也是学术界关注的热点,相关研究主要集中在卸载决策、资源分配和卸载面临的安全问题等方面。 本节将主要分析通过卸载 DNN 计算任务来实现边缘学习的方法。 与此同时,除了对计算任务的卸载,另一种卸载模式是将 DNN 模型划分成不同的层次并将部分层次卸载到边缘服务器上,实现“终端-边缘-云端”三层协作的边缘学习系统,将这种模式称为模型卸载。 表3 总结了与计算卸载和模型卸载相关的关键技术。

表3 边缘学习中的卸载策略Tab.3 Offloading strategy in edge learning
1.3.1 计算卸载
如图 7 所示,实现计算卸载主要有2 种模式。图 7(a) 表示完全基于边缘服务器的计算卸载。 在这种模式下,终端对数据的预处理和边缘服务器在多用户场景下对资源的高效分配是提高系统性能的关键;而在图 7(b) 中的“终端-边缘”卸载模式下,由于边缘服务器和终端相互协同运作,如何制定卸载策略是主要研究的问题。
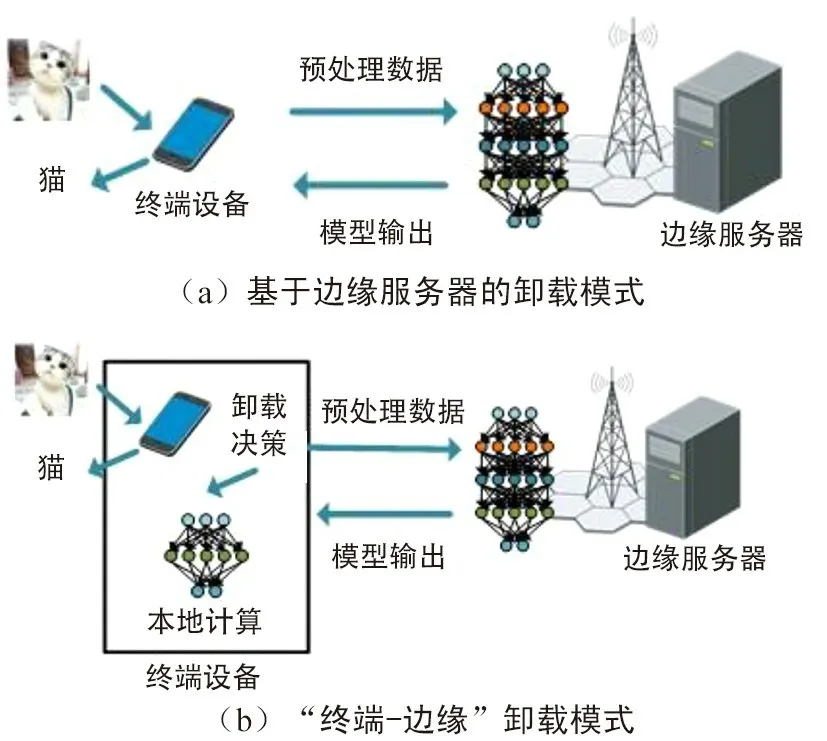
图7 计算卸载模式Fig.7 Computation offloading modes
(1) 基于边缘服务器的卸载模式
基于图 7(a) 的模式,文献 [54] 提出一种能够部署在移动终端上的实时、连续物体检测与识别系统:Glimpse。 Glimpse 将图像检测、特征提取和识别等深度学习计算的过程都卸载到临近的边缘服务器上执行;而系统中的移动终端仅负责图像采集和上传以及对识别对象进行跟踪。 同时,该文还引入了“驱动帧”筛选的过程,能够过滤掉不需要上传到边缘服务器的视频帧,降低系统的通信开销和时延。另外,Glimpse 的“动态缓存”功能实现了在终端设备上保持对识别对象的跟踪。 实验结果表明,系统在实现高识别准确率的同时还能节省传输带宽和终端功耗。 文献 [55] 设计了一个基于深度学习和边缘计算的物体识别系统。 与 Glimpse 相似,该系统也是通过移动终端采集实物的图像,并在终端上进行预处理,然后将预处理后的图像上传到边缘服务器上进行识别,最后向终端返回识别结果。 实现系统性能的关键除了需要高效的识别算法,还在于系统中的预处理过程,即对采集图像的裁剪、模糊化和分块。 预处理过程强调低计算复杂度,以便在移动终端上进行,同时降低数据传输的时延,提高识别的响应速度。
(2) “终端-边缘”卸载模式
上述基于边缘服务器的计算卸载模式主要应用在终端设备缺乏计算能力的场景下。 当终端具备一定的计算能力时,也可以自行完成一定的计算任务,而只在超出其自身计算能力时将相关计算任务卸载到边缘服务器进行。 这种模式下,做出卸载决策(是否将计算任务卸载到边缘服务器上)是待研究的关键问题。 针对这个问题,文献 [59] 设计的 Precog 系统利用终端具备位置感知的特点和存储资源,通过马尔科夫链预测系统可能需要识别的类别,并将相应的输入和结果从边缘服务器缓存到终端设备上。 发生识别请求时,终端首先在缓存中寻找相似的输入和结果,如果无法做出识别,再将请求上传到边缘服务器进行处理,通过充分利用终端上的计算和存储资源,降低系统响应时延。
事实上,在“终端-边缘”卸载模式下,做出卸载决策的过程往往也是一个联合优化系统时延、带宽和终端功耗的过程。 例如,在文献 [60] 提出的 DeepDecision 架构中,系统运行的时间被划分成连续的时隙,在每个时隙开始时求解一个时延、带宽、功耗受限条件下最大化视频帧率的优化问题,最终得出该时隙内的卸载策略,同时决定视频帧的采样率和分辨率。 事实上,相对于终端设备,边缘服务器具有更强大的计算资源,可以在它上面部署更复杂的 DNN 模型,从而提高识别的准确性。 因此,卸载决策的过程就是在资源受限条件下确定使用何种模型执行 DNN 计算的过程。
1.3.2 模型卸载
模型卸载是指将原来仅仅部署在云端的深度学习模型划分为层次大小不同的部分,并分别卸载到边缘服务器上或者终端设备上进行部署,最终形成“终端-边缘-云端”三层协作模式。 通常,DNN 模型由多层的神经网络组成,输入网络的数据经过每一层计算后都会减少数据量,直到经过整个模型运算后输出最终的结果。 因此,将一个深度学习模型的不同层次部署到不同位置后,终端、边缘服务器和云端之间只需传输有限的中间数据,从而在降低传输时延的同时也节省了传输带宽。 根据系统拓扑的不同,模型卸载可以分为“终端-边缘-云端”卸载模式和终端分布式卸载模式。 前者主要包括终端与边缘服务器之间的卸载,以及边缘服务器与云端之间的卸载;后者则将模型卸载到相互连接的终端设备之间。
(1) “终端-边缘-云端”卸载模式
如图8 所示,模型卸载一般在终端和边缘服务器之间进行,或者在边缘服务器与云端之间进行。例如,文献[61] 将 DNN 模型分为2 个部分:终端设备的数据首先上传到边缘服务器,经过较浅层的处理之后得到中间数据;中间数据再上传到云端由后续的网络层处理,得到最终的模型输出并返回给终端。 边缘服务器和云端的协同工作能够减少网络中传输的数据量。 在这种模式下,需要解决的关键问题是如何对模型进行划分,从而在带宽和计算资源受限的情况下最大化系统的性能。 因此,文献 [61] 也提出了根据资源状况和计算任务的复杂程度对神经网络模型进行动态划分和部署的方法。
另一方面,终端和边缘服务器之间的卸载也是模型卸载的常见方式。 例如,文献[62] 设计的Edgent 系统通过在线优化找出预训练模型的最佳划分点,然后将模型进行划分并分别部署到终端设备和边缘服务器上。 与此同时,为进一步降低时延,Edgent 系统还采用了“提前跳出机制”,即通过提前退出模型的计算来满足时延要求,实现时延和准确性之间的性能折中。
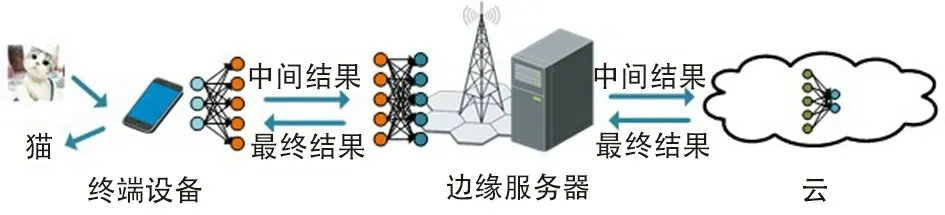
图8 “终端-边缘-云端”卸载模式Fig.8 “Terminal-Edge-Cloud” offloading mode
(2) 终端分布式卸载模式
图9 显示的是基于分布式计算的卸载模式,即将 DNN 模型进行层次划分,并将模型中不同的神经网络层别卸载到临近的终端设备上。 这样做的优点是能够充分利用终端设备的计算资源,提升系统的可扩展性。 基于这种模式,文献 [63] 设计的 DeepX 系统能够将 DNN 网络划分成多个子模型,并卸载到不同的终端设备上联合执行。 同时,以延长终端的使用寿命为目标,DeepX 系统还能充分利用异构设备的资源协作来完成 DNN 的计算。 除了用于优化资源利用率的模型分割算法,文献 [63] 还提出层压缩算法,通过压缩 DNN 模型进一步缩短终端时延并优化内存空间。 类似的,文献 [64] 设计的 MoDNN 系统利用 WiFi 将分割后的模型卸载到无线局域网内的终端设备上。 与 DeepX 系统不同的是,MoDNN 系统对 DNN 的划分颗粒度更细,它对每个层次内的神经元进行划分。 通过将神经元卸载到不同终端设备上,MoDNN 系统能够实现终端设备之间并行的 DNN 计算,从而减少响应时延。 实验结果证明,通过分布式计算,MoDNN 系统能够显著加速 DNN 计算。
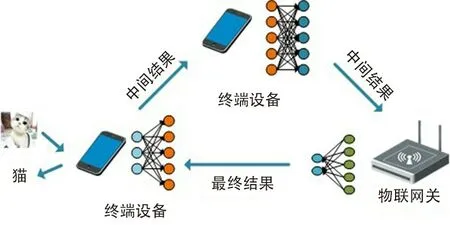
图9 分布式模型卸载模式Fig.9 Distributed model offloading mode
2 应用案例
基于上述关键技术的发展和演进,边缘学习特有的低时延、扩展灵活和隐私安全等特点将助力不同人工智能应用的实现。 本节将分析2 个边缘学习的具体应用案例:超可靠低时延车辆通信和以学习为中心的边缘图像分类系统,来展现边缘学习在不同场景中的实用价值。
2.1 基于联邦学习的超可靠低时延车辆通信
提供高效的车对车(Vehicle-to-Vehicle,V2V)通信是实现自主和智能交通系统的必要步骤。 V2V 通信可以扩展驾驶员的感知能力与可视范围,从而增强交通安全和驾驶体验,同时实现新的交通功能,如自动化列队行驶、实时导航、防碰撞和自动驾驶。一方面,新兴交通应用的性能严重依赖于超可靠低时延通信(UltraReliable Low-Latency Communication,URLLC);另一方面,为提高能量效率,必须实现高效的无线资源管理(Radio Resource Management,RRM)。
文献 [65] 提出一种基于联邦学习的分布式联合发射功率和资源分配框架,以实现超可靠和低时延的 V2V 通信。 为了对可靠性进行建模,可以使用广义帕累托分布的极值理论来获得超过高阈值队列长度的统计信息。 通常,广义帕累托分布的2 个特征参数(比例和形状)通过使用最大似然估计获得。经典的最大似然估计要求中央控制器(例如路边单元)从网络中的所有车辆收集超过阈值的队列长度样本,这将引入极大的数据传输量和较高的时延。为解决这个问题,文献 [65] 对每辆车都使用联邦学习构建本地模型并与路边单元共享该模型。 路边单元在汇聚不同车辆的本地模型之后,对这些模型进行平均得到全局模型,最后将全局模型反馈给车辆。 通过将广义帕累托分布的极值理论对应的参数模型与联邦学习结合使用,各个车辆无需交换本地队列长度样本就可以学习队列长度的拖尾分布。 相对于交换训练样本的集中式学习,联邦学习的主要优势在于减少了模型训练期间的通信负荷,从而减少训练中的通信延迟对 V2V 通信的影响。
具体而言,系统设计目的是要最大程度地减少车辆集合 U 的功耗,同时确保具有高可靠性的低排队等待时间。 但是,总会有低概率经历高延迟这种最坏情况的车辆出现,因此,考虑与车辆队列长度超过预定义阈值且概率不可忽略的极端事件来捕获最坏情况下车辆的性能损失。 首先利用极值理论,将排队长度超过预定义阈值的样本拖尾分布用广义帕累托分布 Gd(·) 来描述,其中,上标d= [δ,ξ] 表示广义帕累托的参数集合(δ 和ξ 分别代表比例和成形参数)。 然后利用队列拖尾分布来优化每个车辆的发送功率,以减少最坏情况下的排队延迟。
如果使用最大似然估计方法来计算在车辆 u 上观察到的队列长度样本{Qu}uϵU的队列拖尾分布,那么,总体代价函数定义为:
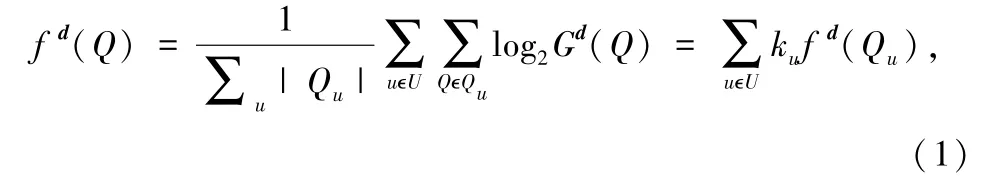
式中,|Qu| 表示车辆u 的校本数,ku= |Qu| /∑u|表示车辆 u 中样本数占总样本数的比例,fd(Qu) 表示车辆 u 的代价函数。 图 10 显示了具体的联邦学习过程,主要包括以下3 个步骤:
③ 每个车辆使用全局模型来建模队列长度的拖尾分布,并利用该分布来控制车辆的发射功率。
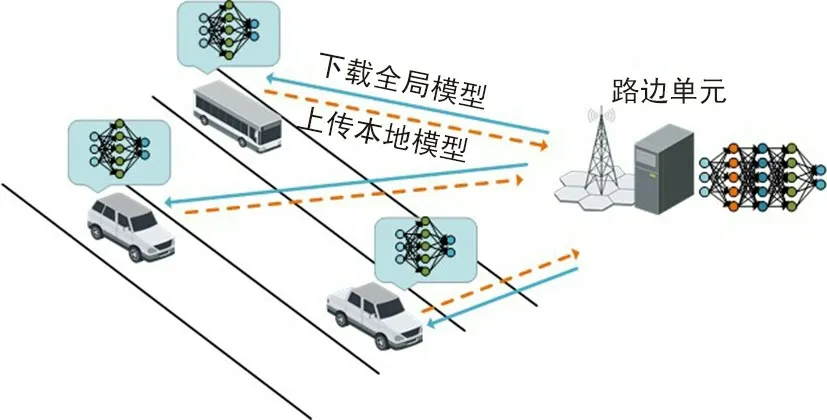
图10 基于联邦学习的车联网Fig.10 Federated learning for V2V networks
实验结果表明,与集中式学习相比,文献 [65] 提出的解决方案能够非常精确地估计广义帕累托分布参数,并且在减少具有大队列长度车辆数量的同时,能够最大程度地降低功耗。 对于具有 100 个车辆对的密集型车联网而言,与通过使用对平均队列长度的概率约束来控制可靠性的基准模型相比,文献[65] 提出的解决方案可以将功耗降低一半,并将大队列长度的车辆减少约60.9%。 此外,与上述基准相比,在建议的解决方案中可以看到,极端队列长度的平均值和波动分别减少了28.6%和33.2%。
2.2 以学习为中心的边缘图像分类系统
图像分类(如人脸识别、目标检测以及场景感知)是人工智能领域最重要的应用之一[66]。 由于功耗和算力的限制,图像捕获设备(如摄像头和相机)通常不具备分析图像的能力。 为了利用这些图像中的信息,边缘图像分类系统是一种行之有效的解决方案。 它将图像通过无线通信传输到边缘服务器进行深度分析,再将分析结果反馈到终端设备。如果分类器在云端已经完成了预训练,边缘服务器则对模型参数进行调整,以适应具体的应用环境。
边缘图像分类系统的目标是最大化分类准确度,而不是最大化吞吐率。 因此,边缘图像分类系统中的无线资源管理与传统无线通信系统有本质区别。 例如,当前主流的注水算法将更多的资源分配给信道质量更好的用户,比例公平算法将更多的资源分配给小区边缘的用户。 虽然这2 种算法在传统通信系统中十分有效,但它们在边缘图像分类系统中可能效率很低。 这是因为它们仅根据信道质量分配资源,并不理解AI 的特征(如学习类型和模型复杂度)。 如果在边缘服务器同时训练 CNN 与支持向量机(Supporting Vector Machine,SVM),服务器应该分配更多的资源给参与 CNN 训练的终端。
针对上述问题,文献 [67] 设计了一种以学习为中心的边缘图像分类系统,如图 11 所示。
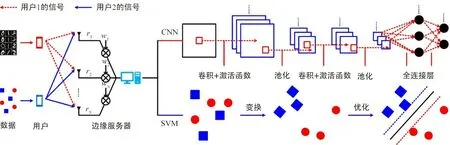
图11 边缘图像分类系统Fig.11 Image classification at the edge
为了建立分类准确率与无线资源管理之间的关系,文献 [67] 引入了样本大小作为中间变量,通过信息论建立样本与无线资源的关系,通过学习论建立准确率与样本的关系。 具体地,图11 包括一个N 根天线的边缘服务器和 K 个用户。 用户 k 向服务器发送功率为 pk的信号 sk。 边缘服务器接收到的信号表达式为rk=+ nk,其中 ,Gk,l=|2表示用户 l 对用户 k 的干扰信道,wk=hk/‖hk‖2表示最大比合并接收机,hk表示用户到服务器的信道,nk表示强度为 σ2的高斯噪声。 基于上述系统模型,边缘服务器的分类准确度与用户功率 p = [p1,…,pK]T之间的关系分析如下:
① 样本与功率的关系。 由信息论可知,用户 k 的传输速率为
因此,训练模型 k 的样本数量为:
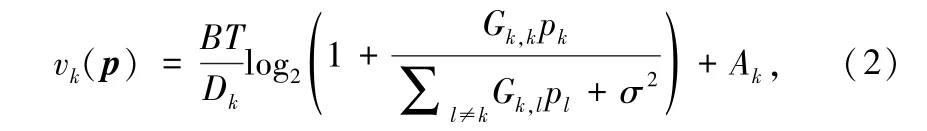
式中,B 表示系统的带宽(Hz),T 表示传输时间(s),Dk表示用户 k 单张图像的大小(bit),Ak表示服务器初始时储存的图像张数。
② 准确率与样本的关系。 由学习论可知,样本复杂度与 Vapnik-Chervonenkis(VC)维度有一定的相关性。 但是,VC 维度是一个标量,无法反应学习性能与算法及模型之间的关系。 为了更具体地刻画学习性能,统计力学理论证明了准确率与样本关系服从逆幂定律。 这个定律衍生出的准确率样本关系式如下:
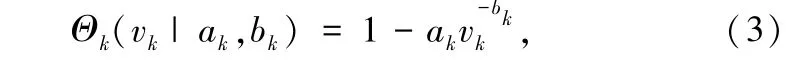
式中,ak和 bk为超参数,且 ak与模型复杂度相关, bk与数据集分布相关。 文献 [67] 用机器学习实验证明上述准确率模型可以很好地反映 SVM,CNN,ResNet-110,PointNet 的学习特性。
基于上述分析,可以得到最终准确率与功率之间的函数关系式为:
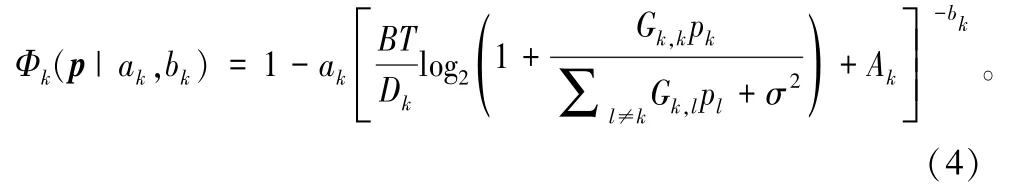
文献 [67] 采用文献 [68] 中的差分凸优化算法最大化 (Φ1,…,ΦK),设计了“以学习为中心”的功率分配算法。 相比注水算法与比例公平算法,图像的分类错误率能够降低 30% 以上。 文献 [67] 还揭示了在边缘图像分类系统中,最优的传输功率不但与信道质量成反比,而且与学习参数呈现指数关系。
3 机遇与挑战
尽管已经引起学术界和产业界的广泛重视,边缘学习还处在蹒跚踯躅的初级阶段,尚有大量问题值得深入研究。 首先,将通信和计算两大功能进行有机结合将是探索边缘学习技术进步和创新的重要途径。 其次,从云学习到边缘学习,保护个人隐私与数据安全也面临新的挑战。 最后,边缘学习从理论研究到系统实现的转化将依赖于系统架构设计、软件开发和硬件加速等研究的不断推进。 下面扼要讨论这3 个方面的研究机遇与面临的挑战。
3.1 通信与计算的联合优化
如第1.2 节所述,为实现通信与计算两大功能的有机结合,单纯地将边缘学习系统中的通信网络看成一条“数据管道”往往不是一个明智的选择。相反,通过对通信与计算过程的联合优化能够显著提高系统整体性能。 在此,联合优化一方面是指将通信技术用于优化机器学习的过程;另一方面,机器学习的方法也能够应用于系统中的通信设计。 除了面向边缘学习的通信设计,当前还有许多致力于将通信与计算联合优化的研究,例如:
① 绿色边缘计算:“绿色”是指节省能源。 研究绿色边缘计算一方面能够节约能源的消耗,有助于环保;另一方面,也有利于减少终端的功耗以延长终端的电池寿命。 因此,通信中能量收集[56]和无线能量传输技术[69]都有望应用于这个场景。 然而,在节省功耗的同时引入能量收集技术也会提高系统的复杂性,让计算卸载中的资源分配问题变得更加复杂。因此,需要设计考虑能量收集的计算卸载策略[56]。
② 协作计算与协作通信有机融合:协作计算 (cooperative computing)是指终端设备通过相互协作完成各自的计算任务,如1.3.2 节中的分布式模型卸载。 协作计算能够减少终端对于服务器的依赖性,并且提高空闲资源的利用率;协作通信 (cooperative communication)是指当某些设备无法直接与服务器通信时也能以相邻设备为桥梁,通过中继通信 (relay communication) 将计算任务转发卸载到服务器上。 二者的有机结合和联合优化能够提升移动边缘计算(Mobile Edge Computing,MEC)系统整体性能。 例如,文献 [70] 考虑了三节点的 MEC 系统 (终端、协作节点和边缘服务器)。 其中,终端既能将计算任务卸载到协作节点和边缘服务器上实现协作计算,又能以协作节点为中继将计算任务卸载到边缘服务器上,实现协作通信。 针对部分卸载和二元卸载2 种模式,文中研究了计算与通信资源分配的联合优化问题,为不同模式的计算任务提供低时延和低功耗的卸载策略。 然而,网络边缘端由各种设备组成,设备和网络的异构性给协作计算的系统设计带来极大的挑战。 因此,研究设备直通 (Device to Device,D2D) 通信和中继通信等协作通信技术与协作计算的有机融合将极具应用价值[71]。
③ 基于机器学习的计算卸载:除了前面讨论的通过优化通信子系统来提升边缘学习的性能之外,机器学习的方法也可以用来解决边缘计算系统设计的问题。 实际上,通过数学建模将计算卸载中的卸载决策、资源分配等问题映射成一个机器学习问题,就能够利用机器学习的高效性来解决相关问题。 例如,文献 [72] 将计算卸载映射成一个有监督学习的问题,而文献 [73] 则将计算卸载映射成一个强化学习的问题。
3.2 数据安全与隐私保护
虽然对隐私数据的保护是边缘计算的天然优势,但在边缘学习中同样存在新的数据安全与隐私泄漏问题。 首先,边缘学习系统通常由异构的网络和设备组成,不同网络或设备间的加密和保护机制难以兼容时,会导致用户的数据失去保护。 因此,需要设计新的安全协议或机制来保障边缘学习中的数据安全。 其次,边缘学习系统中设备资源的开放性和数据共享,都增加了边缘服务器和终端设备受到攻击的风险,如拒绝访问攻击 (Denial of Services,DoS)、欺骗攻击 (spoofing attacks) 和中间人攻击 (man-in-the-middle attacks) 等。 针对数据安全和隐私暴露问题,下面提出善用噪声和安全计算的2 个解决思路:
① 善用噪声:在经典香农通信理论中,噪声通常被认为会阻碍有用信息的检测,所以噪声是需要尽量被抑制的。 然而,在边缘学习系统中,在样本数据中添加适当噪声能够在一定程度上避免模型训练的过拟合现象[74]。 同时,这也依靠了深度学习所具备的抗噪声干扰的鲁棒性。 因此,可以通过人为在数据传输过程中添加噪声来对数据进行“加密”。基于这个思路,文献 [75] 设计了一个基于“边缘-云端”计算卸载模式的边缘学习系统,在边缘端利用 DNN 对输入数据进行特征提取,并在提取到的特征中加入适当噪声,带有噪声的特征再上传到云端做进一步的分析。 在这里,云端的 DNN 模型是利用带噪声的样本数据训练的,因此,它能够在计算时免受噪声的干扰,从而在利用噪声对原始数据加密的同时还能够保证 DNN 的效果。 值得注意的是,尽管噪声被证明在一定程度上有益于模型训练,过量的噪声仍然会影响通信子系统的有效性。 因此,如何折中考虑通信的有效性和模型训练的高效性,也是值得深入研究的课题。
② 安全计算:实现隐私安全更直接的方法是在系统中引入加密、鉴权等传统安全机制。 一种实现安全计算的思路是通过加密算法和验证过程保证设备间的数据交互过程是得到许可并且安全的。 例如,文献 [76]提出了一套基于强化学习(Reinforcement Learning,RL)的安全机制,该机制包括安全的计算卸载、认证和协作缓存。 利用强化学习中的Qlearning 和 DQN (Deep Q-learning Network)技术的灵活性和轻便性,该机制能够在不明显增加系统复杂度的情况下,保证系统安全性。
3.3 系统开发与部署
边缘学习系统的开发和部署是理论研究的最终目的,同时也是实现边缘学习技术价值的最后一环。下面从系统架构、软件平台以及硬件加速3 个方面说明实现边缘学习系统面临的机遇和挑战。
① 系统架构:边缘学习的实现和大规模部署将依赖于网络架构的高效设计。 欧洲电信标准研究院(European Telecommunications Standards Institute,ETSI)为了促进缘计算在 5G 通信系统中的应用,提出以网络功能虚拟化(Network Function Virtualization,NFV)为基础的网络架构[77]。 NFV 能将边缘的物理资源以网络功能的方式提供给上层的应用,为AI 应用的部署提供了平台。 通过网络运营商与服务提供商的紧密合作,可以实现网络能力的开放和针对特定垂直行业的应用服务。
② 软件平台:在软件平台方面,微软公司推出的 Azure IoT Edge 和 Google 公司推出的 Cloud IoT Edge,都成为实现边缘计算的应用平台。 二者都为开发者提供了在线训练AI 模型的平台,训练后的模型能够灵活地部署在网络边缘的 IoT 设备上。 但它们都依赖云平台,需要将模型训练的过程进一步向边缘化演进。 与此同时,当前也有许多用于开发 AI 应用的深度学习框架,如 TensorFlow,Torch ,Caffe 等。 这些框架一方面需要向边缘化发展,开发出更适合边缘服务器的软件框架如 TensorFlow Lite,Caffe2 ,CoreML 等;另一方面,也需要朝着彼此兼容的方向发展,从而适应由具有不同软硬件架构的设备形成的边缘网络环境。
③ 硬件加速:除了上述对软件的需求,硬件的加速对于在终端和边缘端部署以及实现机器学习算法也是至关重要。 为此,设备商也开始使用图像处理单元 (Graphic Processing Unit,GPU) 和 AI 芯片,如苹果公司的 A12 仿生芯片、中星微公司的嵌入式神经网络处理单元(Neural-network Processing Unit,NPU)——“星光智能一号”及华为公司的 NPU——“麒麟 970”等。 特别是,Google 公司还推出了专门用于嵌入终端设备的边缘张量处理单元 (Edge-Tensor Processing Unit,Edge-TPU) 及相关的开发套件。 TPU 是专门用于计算 AI 模型的专用集成电路(Application Specific Integrated Circuit,ASIC),它具有高性能、小体积、低功耗以及低成本等特点。 因此,TPU 能够灵活地部署在终端设备和边缘服务器中。 未来,边缘学习的实现和部署将有赖于算力更强、功耗和成本更低的 GPU,NPU,TPU 等AI 芯片的发展和应用。
4 结束语
随着移动通信和AI 技术的迅猛发展,通过更加靠近终端设备进行数据计算与处理,可以显著降低通信负荷并提高 AI 应用的响应速度。 因此,迫切需要将 AI 应用从云端下沉到网络边缘。 为了适应这个重要的技术发展趋势,边缘学习已被广泛认为是在资源受限环境中支持计算密集型 AI 应用的典型解决方案,本文对边缘学习的最新研究成果进行了全面综述。 具体来说,首先回顾了边缘学习的发展历程;然后,考虑到数据隐私及通信开销等问题,分析了如何在网络边缘进行模型训练以及如何进行高效通信子系统设计的关键技术;而且,为了减轻终端设备执行 AI 计算的压力,讨论了将计算密集型任务转移到边缘服务器或相邻终端上的计算和模型卸载技术;最后,展望了边缘学习面临的发展机遇与挑战,包括通信与计算的联合优化、数据安全与隐私保护,以及边缘学习的实现与部署等。 本文能够为边缘学习领域的初学者提供一个宏观的研究视野和快速入门指南,并启发后续理论研究和技术创新。
猜你喜欢
数学物理学报(2021年6期)2021-12-21 06:24:38
应用数学(2020年2期)2020-06-24 06:02:50
铁道通信信号(2019年4期)2019-10-10 03:42:54
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
通信产业报(2016年44期)2017-03-13 08:41:45
电子制作(2016年15期)2017-01-15 13:39:12
铁道通信信号(2016年3期)2016-06-01 12:10:18
河南科技(2014年3期)2014-02-27 14:05:45
河南科技(2014年1期)2014-02-27 14:04:05
雕塑(1999年2期)1999-06-28 05:01:42
