
一个选择最大似然互信息特征的网络关系预测通用模型
2020-01-14 06:03伍杰华熊云艳
计算机应用与软件 2020年1期
伍杰华 熊云艳
1(广东工贸职业技术学院计算机与信息工程学院 广东 广州 510510)2(华南理工大学计算机科学与工程学院 广东 广州 510641)
0 引 言
信息网络是一种基于实体和实体之间纷繁复杂互联关系组成的网络结构[1]。各实体通过信息网络实现信息的传递、传播和交互。比较常见的信息网络有科研学术合作网络[2]、社交媒体网络[3]、生物蛋白质功能网络[4]等。由于实体之间关系是信息传播之间的桥梁,因此对关系的分析与研究显得非常重要[5],其中一个主要的研究方向是关系预测与推断(又称链接预测或者关系分类与推断)[6]。该技术的核心思想是根据当前信息网络的结构信息预测尚未存在关系的实体之间产生关系的可能性。它首先能够从理论层面帮助深入理解信息网络的演化机制和信息传播机制[7],例如社交网络中的消息(信息)传播机制的本质是把人与人之间的互联关系引入到传播过程当中,因此该互联的社交关系直接影响信息传播效果及范围。例如,谣言、传闻、流言的传播是目前社交媒体或者社会网络领域中危害社会稳定和安全的垃圾信息,通过关系预测结合影响力节点分析等其他社交网络分析技术,我们能够进一步深入揭示谣言在用户之间的传播方式和整个网络的实体关系及其演化机制,从而有助于更好地找到谣言发起的源头、散步的规律,协助治理网络安全。此外,该技术在应用领域也有广泛的应用前景。例如知识图谱中实体之间的关系预测[8]。知识图谱是一种基于语义信息并描述实体与实体之间关系的异质结构。它能把不同知识领域的多维度的关系网络。关系预测技术有助于实现知识图谱实体之间关系的学习、融合以及推理,并为其实体关系进行标注,在新闻事件的关联分析、识别反欺诈潜在风险、失联客户管理和谣言识别等众多领域有重要的应用价值。
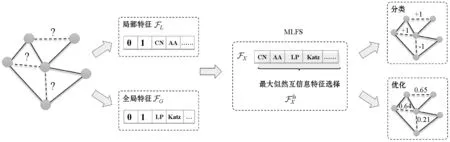
图1 算法模型
1 相关工作
预测,在一定程度上是个概率计算问题。即通过计算两潜在实体之间产生关系的概率来进行推断。由于该概率可通过挖掘网络结构信息直接计算或构建概率模型学习获得,因此关系预测与推断算法主要分为基于概率相似度和基于学习思想两大类[9]。第一类算法把概率视为两潜在实体之间的相似度,并通过信息网络节点、路径、社区、邻接矩阵等拓扑结构或网络表示结构计算该相似度,其原理简单,一直是研究的主流。但是本文主要介绍的是基于学习思想的算法,因此对于第一类算法的相关工作就不作详细叙述,可参考相关综述[9-10]。近几年来,随着机器学习理论的飞速发展,一些新技术、新方法不断提出,这些研究为第二类基于统计机器学习技术的关系预测奠定了基础。该类算法的主要思想是根据社交网络结构提取特征并建立一个适合的模型,采用统计方法估计模型的参数,然后通过参数进行类别判断和最优化推断等。其研究思路主要分为以下几个方面:基于特征学习的分类算法、基于概率图(层次图)模型的算法、基于矩阵分解和补全算法和基于网络表示学习与嵌入的算法等。(1) 基于特征学习的分类算法。该类算法假设潜在链接的形成与否受到与其相关联的特征空间的影响,并把链接形成与否视为一个二分类问题。文献[11]首先把链接预测变成给定特征下的两分类问题,并比较了多个监督学习算法的性能。文献[12]提出了一种高性能的基于流信息采用基于Bagging和Random Forest的分类模型,该模型有效地解决了分类中的不平衡问题。文献[13]提出了一个面向微博社交网络的预测算法。该算法从多个层面收集了网络中基于节点、拓扑结构、投票和社交信息等信息构建特征,采用SVM等多种方法有效地进行链接分类。(2) 基于概率图(层次图)模型的算法。该类算法的主要思想在于两个节点之间链接形成的概率取决于它们从属的层次、社区或者块信息。文献[14]认为链接可以看作社交网络内在的层次结构的反映,并提出了一种挖掘网络层次结构的最大似然估计的算法。文献[15]通过引入高斯过程,提出了一种基于随机关系模型(Stochastic Relational Models,SRM)的链接预测算法。该算法的关键思想在于通过多重高斯过程的张量相互作用对随机实体关系结构建模。文献[16]结合信息网络另外的一个热门研究领域-社区划分,把关系预测的问题从判断链接是否存在变成在一个社区划分网络下,已存在网络结构中不同类型的关系生成最大化推断问题,提出了一种平衡度模块度最大化的模型(Modularity Maximization Link Prediction Model, MMLP)。
但是上述算法依然存在通用的问题,因为它们仅仅考虑了如何建立模型提高对特征的学习,而忽略了特征之间存在的关联会影响学习与分类的性能。在分类问题中,特征是决定分类性能最重要的因素。但是由于获取的原始特征不一定能够准确反映待分类对象的本质特征,样本也可能比较稀疏,计算量大,不利于高效的分类;同时高维的原始特征存在冗余信息,不做分析直接用于分类会存在“维度灾难”,影响分类性能。
针对原始信息网络特征存在的不足,同时弥补上述算法在特征提取过程当中难以兼顾类型、数量及缺乏特征选择过程,本文提出一个结合最大似然互信息特征选择的信息网络关系预测算法。具体来说,算法首先基于相似度预测指标提取了局部和全局(半局部)两类特征,然后极大似然推断最大化特征之间互信息,对特征的重要性进行排序,根据排序选择最具影响力的特征进行分类。算法的主要贡献如下:
(1) 结合最大似然理论计算互信息,有效地筛选最具判别性特征,提高了学习和预测效率。
(2) 把提出的特征选择算法嵌入到基于特征学习的分类算法和新提出的基于概率图(层次图)模型中,在多个真实信息网络数据集的结果表明,分类性能得到提高,特性选择步骤是必要的。
2 特征提取
2.1 问题定义
基于分类理论的关系预测算法。该类方法把关系预测问题看成是一个标签预测问题(Label Prediction),其中存在的和不存在的关系分别被标记为正例和负例。或者把问题看成存在概率P(e∈G)的估计问题,然后建立一个预测模型M和获取影响链接生成的特征空间和参数空间θ,并通过分类、优化等理论与方法计算该概率。概率越高,关系生成的概率越大。具体的函数映射如下:
fM(GT,,θ)→{0,1}
(1)
式中:0表示潜在节点之间不存在链接,1则表示存在链接。M指预测模型,GT是训练集网络。
2.2 局部与全局特征提取
2.2.1局部特征
在信息网络关系分类领域,邻接节点指和指定和潜在节点i存在直接链接关系的节点集合,记为N(i)。节点i的d路径内邻居(或者指d条链接内可达到)是指i在d步路径之内能达到的节点j的集合,记为N(i,d)。如果V是一个节点集合,那么N(V,d)是指V中节点在d步路径之内能达到的节点集合。由于该节点集合的信息对于潜在节点对是否存在关系的影响是最直观的,因此局部结构或者局部性(locality)一般表示在1~3步路径内的节点集合。由于定义信息网络结构特征的指标有非常多,文中选择了5个典型具有代表性的指标构建局部特征集合L:
CommonNeighbors(CN)[6]:CN相似度指标(在文中指标也可称为方法、算法)是链接预测中最直观、最简单的相似度计算方法。假设两个潜在节点对拥有的共邻节点数目越多,它们之间产生链接的概率就越高。公式如下:
CN(i,j)=|N(i)∩N(j)|
(2)
式中:N(i)指所有与节点i相邻的节点的集合。
Adamic-Adar(AA)[17]:该指标通过对每个共邻节点的不同度的对数值差分化处理不同共邻节点的角色和贡献,度大的共邻节点贡献小于度小的共邻节点。其公式如下:
(3)
PreferentialAttachment(PA)[18]:该指标主要反映网络中的偏好性生成机制,即节点的度越大,其吸引其余节点产生关系的可能性越高。公式如下:
PA(i,j)=|N(i)|×|N(j)|
(4)
JaccardCoefficient(JC)[6]:JC指标不仅考虑了预测节点对的共邻节点数目,它还考虑了共邻节点在两个节点的邻居节点集合中所占的比率。公式如下:
(5)
ClusterCoefficient[18]:聚类系数表示节点邻接节点之间链接的密集程度,该指标取共邻节点聚类系数的和。公式如下:
(6)
式中:cω表示共邻节点ω的聚类系数。
2.2.2全局(半全局)特征
基于局部特征算法主要考虑局部拓扑结构属性,相应的指标所需的信息量少、算法简单、时间复杂度低,运行速度快,适用于小规模的网络关系预测任务。但是局部拓扑结构属性不能够深层次反映两节点之间的隐含属性,也不能反映整个网络结构对潜在预测节点的影响。基于上述两个原因,一部分相似度特征指标的构建工作基于路径或者基于随机游走展开(由于该过程取决于网络的结构,因此可能是全局的,也可能是半全局的,但后续均统称为全局特征)。因此,文中选择了5个典型的指标构建全局特征集合G:
LocalPath(LP)[19]:为了避免仅仅考虑共邻节点结构而导致的精确度以及区分度过低等问题,局部路径指标额外考虑了三阶路径的影响。公式如下:
LP(u,v)=(D2)u,v+α(D3)u,v
(7)
式中:α是权重参数,D是图矩阵,Du,v表示节点对u、v之间的一步路径,则是两步路径,(D2)u,v以此类推。当α=0时,LP(u,v)=(D2)u,v相似度指标变成只考虑共同邻居节点的影响,此时LP就是CN。
Katz[20]:根据局部路径指标可知,如果想要将网络结构的影响因素更全面地考虑进来,同时更进一步地提高计算精度,可以将四阶路径、五阶路径、乃至n阶路径考虑进来。当n→∞时,相似度计算将全局网络路径均考虑在内,此时的相似度指标就相当于Katz指标。公式如下:
Katz(u,v)=(I-αD)-1-I
(8)
式中:I是单位矩阵,该算法将所有对节点间产生影响的路径信息都考虑进来了。
RandomWalkwithRestart(RWR)[21]:该指标基于一个物理意义上的假设:随机游走的粒子会以一定的概率返回起始位置,其中元素πuv表示从节点u走到v的概率。公式如下:
RWR(u,v)=πuv+πvu
(9)
同时,基于随机游走还选取了SRW和LRW两个指标作为全局特征,由于版面关系,在此不再详细叙述。
3 算法框架
在基于信息网络结构的关系预测或者分类算法的相关工作中,所提取的相似度特征一般均基于节点、共邻节点或者相关路径等信息构建,因此特征之间会存在相似的信息,直接用作分类和推断优化会保留特征之间的噪音和冗余信息。因此,本文的核心思想在于考虑能否运用机器学习特征工程领域的特征选择技术筛选出具备最优判别性的特征帮助分类——即特征选择。特征选择技术指在未处理的特征空间中通过指定的标准筛选出一组具备最佳分类性能的特征子集的过程[22],该过程有助于删除特征间冗余信息和不相关的特征。
3.1 最大似然互信息特征选择
在面向特征选择的信息论中,两个随机变量的互信息(Mutual Information,MI)[23]定义变量间相互依赖性的量度。在分类问题中,特征和类别之间的相互信息体现了特征和类别的相关程度,即可以评价特征对于分类效果贡献。因此,估计特征和类别之间的MI在特征选择领域多年来一直备受关注,在度量特征之间的关系和辅助特征选择上有重要的意义。因此,使用互信息理论对特征进行选择和提取基于如下假设:特征在某个类别出现的频率高,但是其他出现的频率低,可以认为该特征和类别的互信息比较大。所以如何计算MI是其中的关键问题。MI可以定义为:
(10)
然而对上述公式中的密度进行估计是一个比较困难的问题。因为估计密度的划分涉及到MI的逼近,容易使估计误差放大。一部分工作例如用k近邻(KNN)方法估计熵算法尝试适当地确定k的值以使偏方差权衡得到最优,但是该步骤在MI估计的上下文中的实现并不简单。当目标密度接近正态分布时,计算边缘分布的方法效果较好;否则,它是有偏差的和不可靠的。针对计算互信息存在的问题,本文提出了一种称为最大似然互信息(Maximum Likelihood Mutual Information,MLMI)新的MI估计方法[24]。该方法的优点在于不涉及密度估计,直接对密度比建模:
(11)

(12)
然后用以下线性模型对密度比函数w(x,y)建模:
(13)
式中:α:=(α1,α2,…,αb)T是需要从样本中学习的参数。φ(x,y):=(φ1(x,y),φ2(x,y),…,φb(x,y)T则是偏差函数。
(14)
(15)
(16)
(17)
现在我们的优化准则总结如下:
在估计密度函数之后以互信息作为提取特征的评价选择互信息最大的N个特征进行分类。
3.2 基于MLMI的关系预测
整个算法框架如下所示:
Input:网络G=(V,E)
Output:Accuracy AUC Precision Recall F1
1: 对G划分为训练网络GT和预测网络GP
2:forGT和GP中的每一条存在或不存在关系do
4:endfor
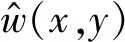
7: 采用优化准则公式推断参数
9: 采用NB,SVM和RF进行分类
4 实 验
4.1 实验设置
根据关系分类算法遵循图1的过程:按照比例r(默认设置为0.9)把网络划分为训练网络和预测网络,对两个网络分别提取特征空间T和P,然后根据图1的分类优化过程的每个步骤进行实验。每个算法划分10次,取10次结果的平均值。其中默认选择的特征是最具判别性(排序在前)的前8个特征作为特征子集。在该过程中把存在链接视为正类(Positive),不存在链接视为负类(Negative),True表示预测准确,False表示预测错误,TP则表示实际存在链接被成功分类的数目。实验结果采用信息检索领域分类模型标准评价指标准确率(Accuracy)、AUC(Area Under Curve)、精确率(Precision)、召回率(Recall)和F1-Measure对算法进行评价。其中:
(18)
(19)
(20)
(21)
4.2 数据集
(1) Dolphins[26]。这是宽吻海豚的定向社交网络。节点表示宽吻海豚社区的宽吻海豚,关系表示海豚间的频繁关联。
(2) Football[26]。2000年秋季常规赛期间IA大学之间的美式足球比赛网络。
(3) Enron[27]。邮件网络,网络中的节点是表示员工,关系表示节点之间的电子邮件。
(4) Yeast[28]。生物酵母数据集。
(5) Email[28]。Virgili大学成员之间的电子邮件交换网络。
(6) Openflights[29],航班网络。 每个节点表示一个机场,关系代表一个航空公司到另一个航空公司的航班。
数据集的拓扑结构属性显示在表1中。
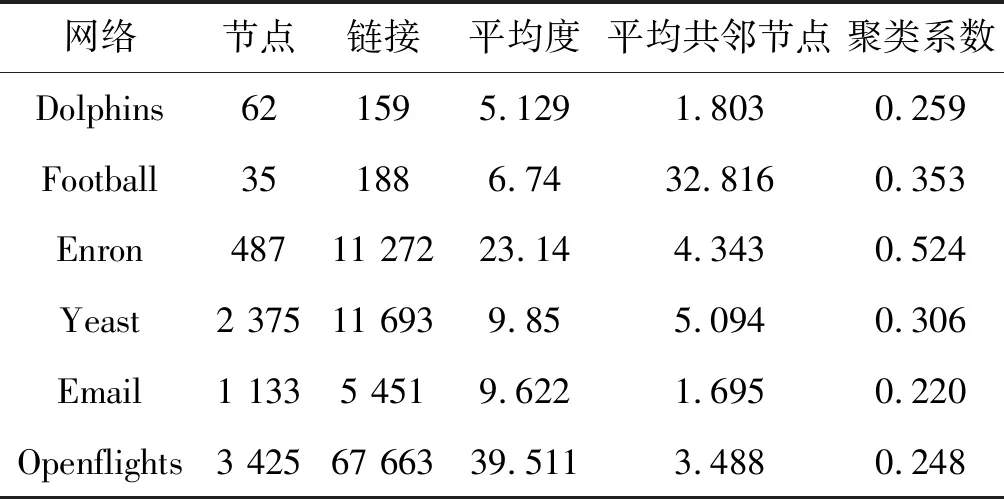
表1 多元网络结构属性
4.3 对比方法
实验中对网络中的潜在链接进行分类和推断,判断链接是否生成,验证提出模型的有效性。同时,实验采用多种有监督学习算法作为分类算法[30],这些分类算法包括朴素贝叶斯分类(Naïve Bayes,NB),支持向量机(Support Vector Machine,SVM)和随机森林(Radom Forest,RF)。本文提出方法简称为MLFS(Maximum Likelihood Mutual Information Feature Selection)。
4.4 实验结果与分析
为了充分验证提出特征分类算法对链接分类问题的有效性,本文使用不同分类算法在6个数据集中做了大量的实验。表2和表3给出了结果的平均值,其中No-FS表示没有经过特征选择步骤,直接采用原始特征进行分类的算法;MLFS表示经过特征选择过程的分类算法。根据表2的结果,有以下几点发现:(1) 实验使用了6个数据集、5个评价指标和3个分类器,因此共有90个对比案例。经过统计,与No-FS相比,MLFS在67.77%的案例中效果更好,在20%的案例中效果相等,在12.23%的案例中效果相对较差。该结果表明经过最大似然互信息特征选择步骤得到的分类性能要优于没有经过特征选择步骤基准方法,也反映本文提出的算法泛化性能很高,在多个数据集中均具备不错的性能。同时,对于每个数据集,最优的算法均出现在MLFS中,这是因为特征选择删除了一些不相关或冗余的特征,解决了维数过多带来的灾难,在一定程度上避免过拟合,也侧面反映特征选择过程是有效且必要的。需要指出的是,由于这5种评估指标各有侧重点,因此一个数据集上一个方法很难在所有评估指标上均优于对应基准算法。(2) 各数据集各指标在不同分类器下的分类结果有差别。在SVM分类器下,76.66%的案例中MLFS比No-FS要优,该百分比在NB和RF分类器分别下降为56.66%和53.33%,因此从整体上看,SVM和RF比NB要更适合信息网络关系分类这一任务,原因在于SVM的优点是处理高维特征数据,同时能更好地解决特征的非线性问题。(3) 无论是对于小规模的网络(例如Football数据集潜在关系有35×35),还是对于较大规模网络(Openflights数据集潜在关系有3 425×3 425),在对经过特征选择的特征分类的过程中均能够比原始特征取得更好的分类精度,这表明提出的算法能够适应不同规模的网络,在一定条件下具备拓展到超大规模网络应用的基础。
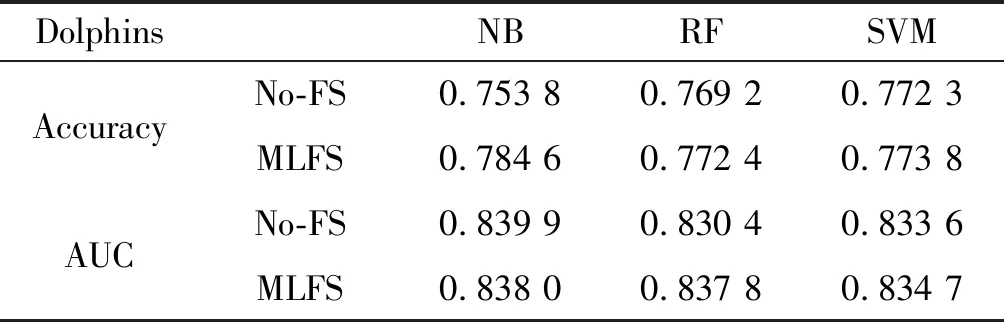
表2 各分类算法在Dolphins Football Enron下的分类效果

续表2
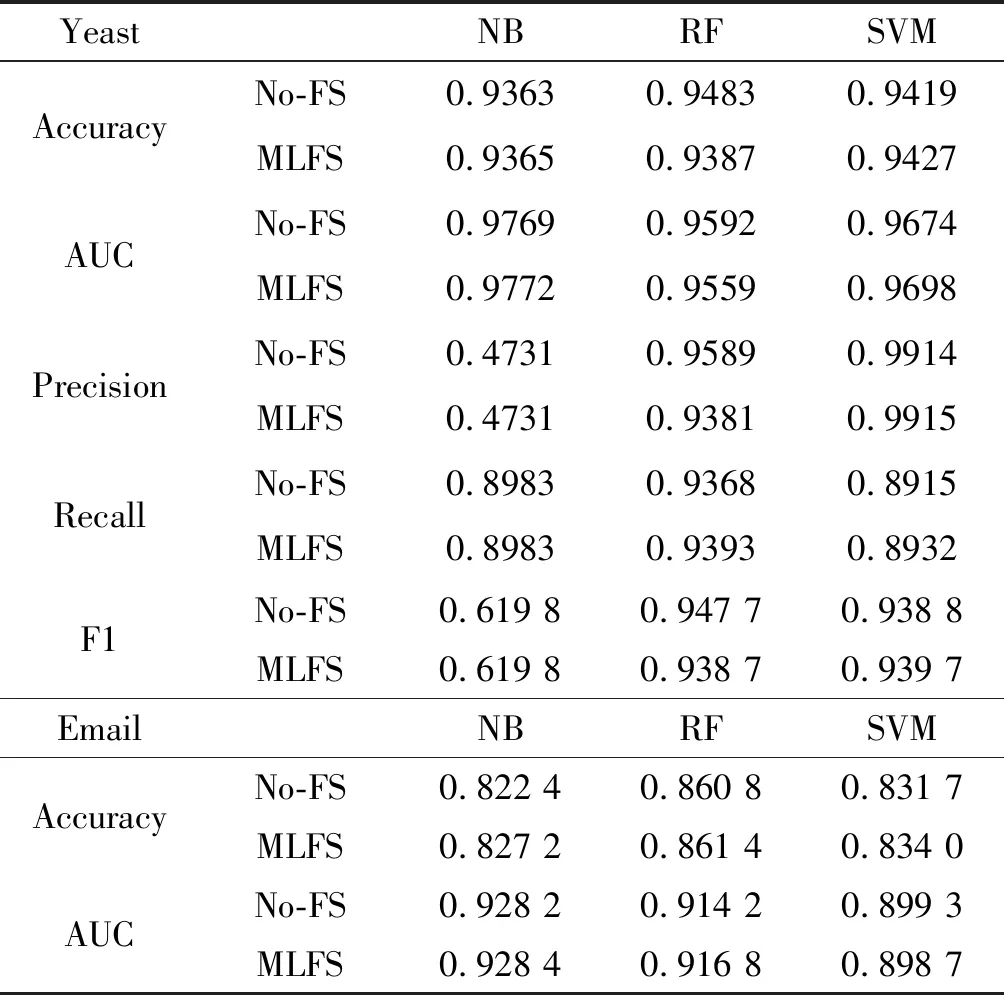
表3 各分类算法在Yeast Email Openflights下的分类效果
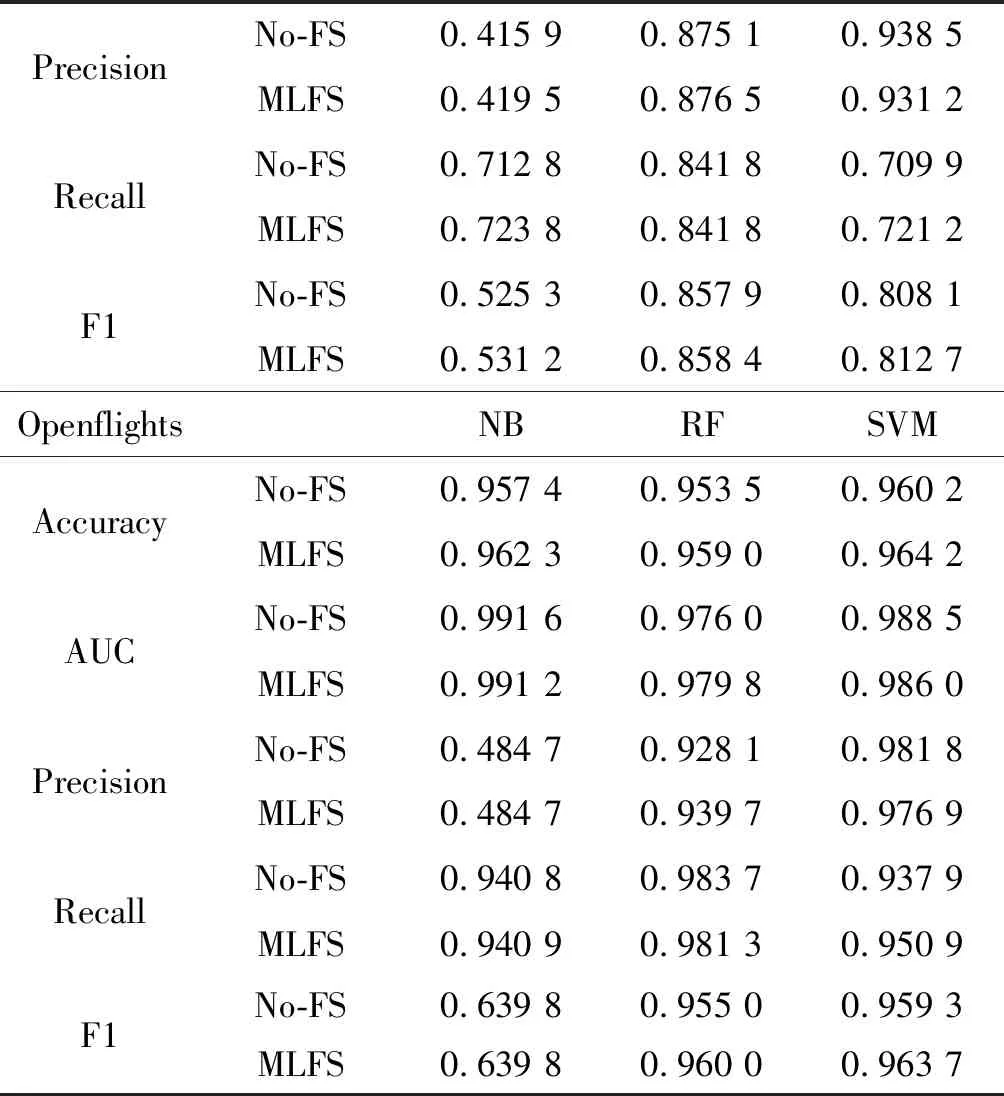
续表3
此外,为了更加细致地分析每个算法的效果,文中还进行了以下拓展实验:
(1) 为了验证提出算法的稳定性和解决稀疏网络学习的能力,表4给出了在不同规模划分网络下各分类算法的分类性能力,其中训练集比例r分别设置为0.5、0.6、0.7、0.8、0.9。我们在其他数据集也发现了类似的效果,由于版面的关系,仅仅给出Email数据集的分类结果。由表4可知,随着r值不断变大,对应No-FS和MLFS的分类效果基本上均呈上升趋势,在r=0.8或r=0.9时达到稳定状态。这是由于随着训练集规模的变大,更多的正例(存在链接)被加入到训练集中。更重要的是,基本在每一步r值上,MLFS均比对应的No-FS表现出更好的分类性能,这表明算法不受训练集大小的影响,表现出稳定的态势。值得一提的是,当r=0.5时,Email数据集99.96%共邻节点数目小于5,99.54%共邻节点数目小于2,网络变成一个非常稀疏的状态,这样的情况下MLFS在分类任务上仍然获得一个较为理想的结果,表明提出算法在稀疏网络上的灵活性和优越性。
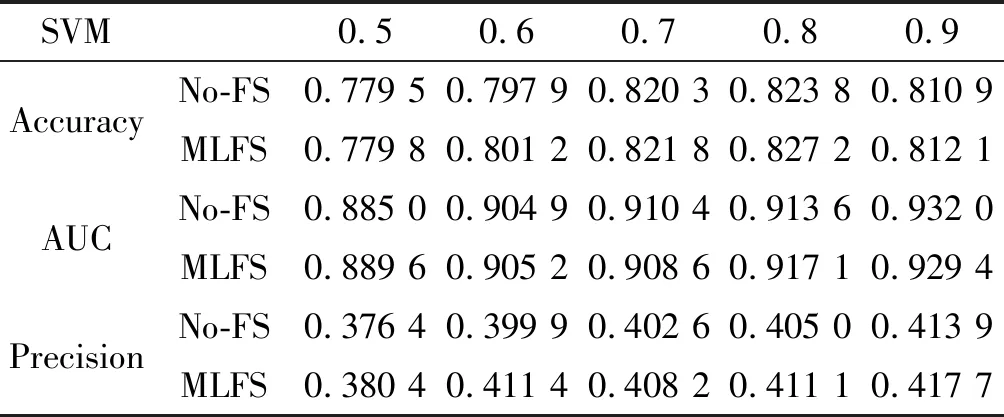
表4 Email数据集下的训练集规模变化下各指标的分类效果

续表4
(2) 第二部分在图2-图4输出了经过MLFS筛选不同特征数目下Openflight数据集各指标的分类效果。需要指出,由于把过多的指标绘制在同一个图表中会过于拥挤,同时F1指标综合了Precision和Recall的效果,因此该部分实验显示了Accuracy、AUC和F1对应曲线,其中SVM-MLFS表示在SVM算法下经过MLFS特征选择的分类效果,SVM-NoFS表示未经特征选择直接分类的效果。可以看出,当特征数目逐渐变大的时候(特征数目从5到8),对应的分类效果也呈现线性增长的趋势。这是因为特征数目过少(5或者6)会影响分类的性能,增加相似度指标的数目有利于提高特征判别性。同时在许多情况下(例如AUC指标的NB分类算法),当特征数目为9时分类性能并没有显著提升,甚至还有所降低,原因在于特征数目过多基本没有选择删除了不相关或冗余的特征,等于没有进行特征选择步骤。综上所述,默认特征选择数目设置为8 既保证了实验性能又提高了分类效率,因此是合理的。值得一提的是,在大部分的不同的特征数目设置中,经过MLFS的各指标性能优于NoFS,表明MLFS对特征数目不敏感,即无论特征数目如何变化,MLFS过程都是十分必要的。
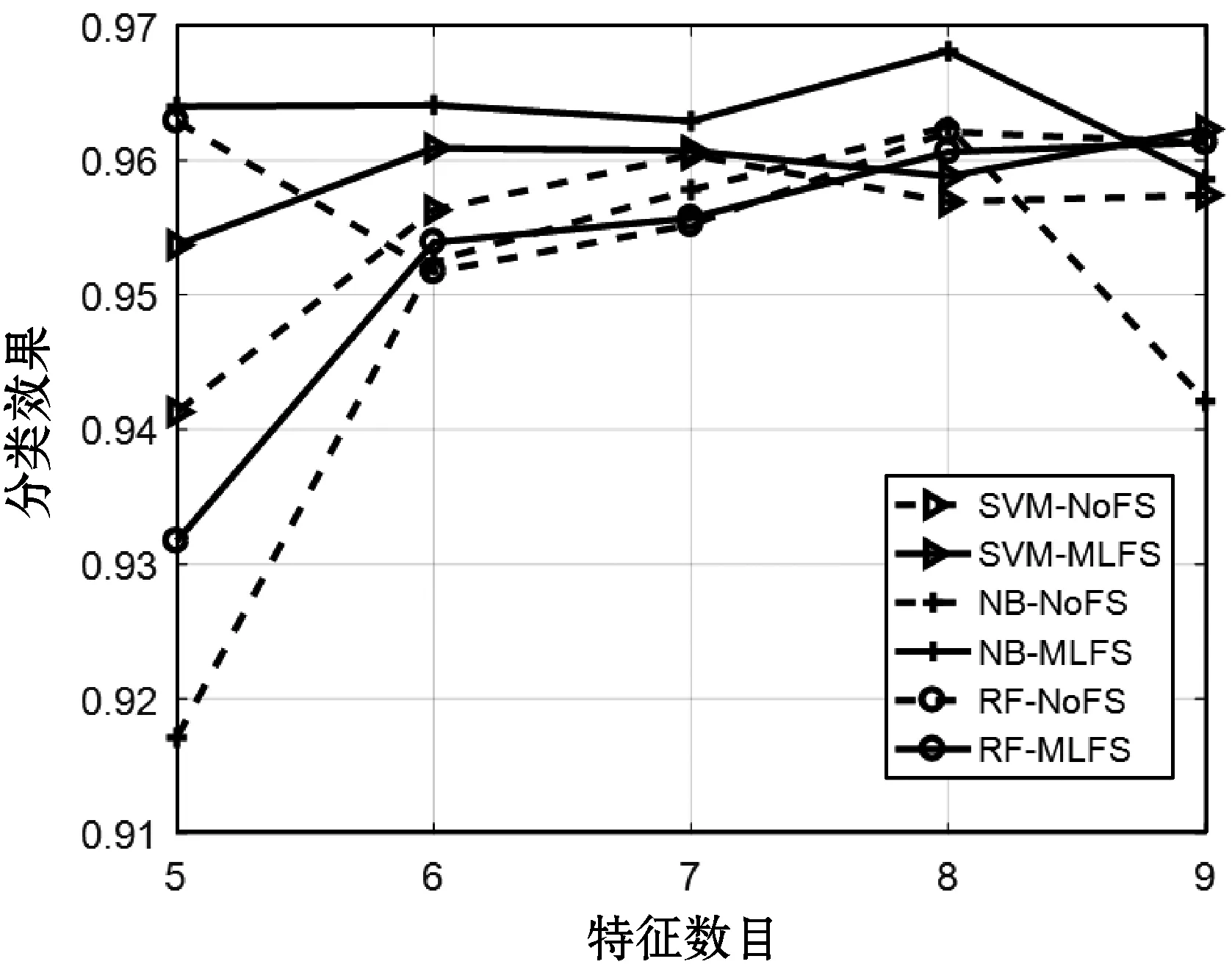
图2 不同特征数目下Openflight的Accuracy指标
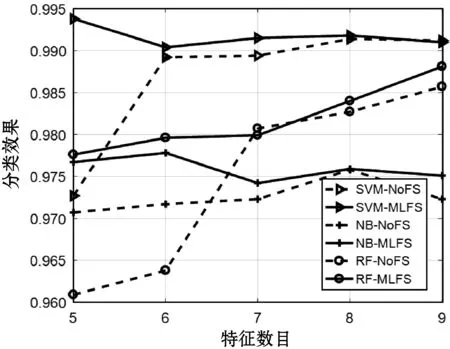
图3 不同特征数目下Openflight的 AUC指标

图4 不同特征数目下Openflight的F1指标
(3) 为了验证局部特征(Local)和全局特征(Global)对分类性能的差异化影响,本文在图5-图7输出了Yeast数据集在Accuracy、AUC和F1指标下各分类器的在局部特征和全局特征下的分类效果,其中Local-MLFS表示使用局部特征并经过MLFS特征选择的分类效果,其余表示则依次类推。从结果可以明显看出,无论是局部特征还是全局特征,在大部分情况下MLFS比NoFS的分类性能要好。以图7为例,可以看出MLFS表示的柱体(第二、四根柱体)比基准分类算法(第一、三根柱体)高,该结果进一步验证了特征选择步骤的必要性和有效性。此外,从结果也可以看出基于全局特征的分类算法和基于局部特征的分类算法各有优劣。结合在其他数据集中的统计结果可以发现,全局特征比局部特征判别性要更好,可能原因是在无监督学习链接预测任务中,全局特征指标比局部特征指标的整体预测性能更优。但是相关文献也指出,特征指标的优劣和具体的网络拓扑属性相关,因此一类特征无法全面优于另一类特征,结合两类特征分类是较好的方案。
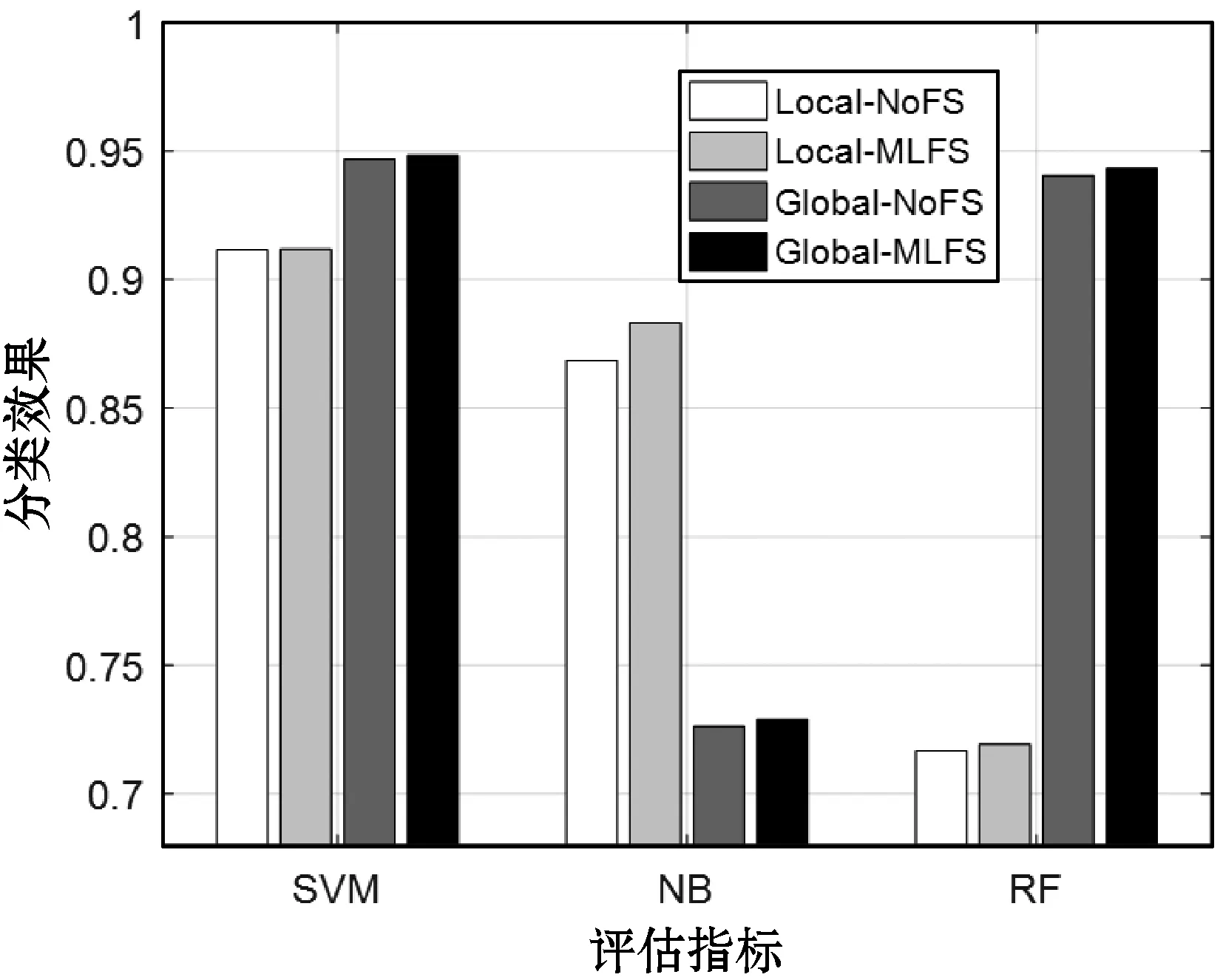
图5 Yeast数据集下局部和全局特征的Accuracy指标

图6 Yeast数据集下局部和全局特征的AUC指标

图7 Yeast数据集下局部和全局特征的F1指标
为了验证MLFS步骤的通用性和可推广性,在最后一部分实验中拟把特征选择到新近提出的模块度最大化链接预测算法(Modularity Maximization Link Prediction Model,MMLP)当中。在MMLP中,一个重要步骤是提取基于社区划分结构下社交网络的拓扑结构信息,使用的8个特征分别是中介性核心性、紧密中心性、PageRank、HITS、CN、AA、JC和CC。和前文采用同样的实验设置,抽取的特征数目设置为6,评估指标设置为AUC。从图8的实验结果可以看出,在绝大部分数据集上引入MLFS过程的MMLP算法获得了较好的性能提升,在各数据集中的预测值增长量分别是8.493%、2.369%、1.871%、-0.762%,1.891%和0.524%。这表明MLFS步骤对于引入特征进行链接预测或者链接分类的新近提出的算法均是有效的。

图8 MLFS在MMLP模型中的影响
5 结 语
本文对信息网络的关系分类与推断中的特征提取与处理过程进行分析与研究,主要工作包括以下几个部分:(1) 提取了反映信息网络局部和全局两类相似度特征,并提出一种基于密度估计的极大似然算法计算特征之间的互信息,该算法是一种不涉及密度估计的单步处理方法,能采用交叉验证的方法进行模型选择,可有效地计算出唯一的全局解。(2) 采用经典分类算法和新近提出的MMLP算法进行关系分类与推断。通过在真实数据集上的实验,有效验证了本文算法的优越性和互信息特征选择过程的必要性。
下一步将从以下几个方面继续深入探索:(1) 引入机器学习特征降维 、维度约减等相关算法进一步处理特征,提高算法的运行效率。(2) 由于网络结构的复杂性,进一步把模型推广到符号信息网络、多维度信息网络等场景的分类与推断任务上。
猜你喜欢
计算机应用与软件(2021年10期)2021-10-15
小型微型计算机系统(2020年5期)2020-05-14
计算机与生活(2020年5期)2020-05-13
火力与指挥控制(2020年1期)2020-03-27
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
