
基于网络爬虫的就业数据分析
2020-01-13 07:48项博良唐淳淳曹健东
智能计算机与应用 2020年1期
项博良, 唐淳淳, 钱 前, 曹健东
(上海工程技术大学 机械与汽车工程学院, 上海 201620)
0 引 言
随着人工智能的概念逐步的深入展开,人工智能因其高效性和实用性受到越来越多的重视。作为人工智能的重要组成部分,大数据也开始在社会生产中发挥巨大作用,同时还带动了社会生活质量的全面提升,并提供了以往不曾有过的便利性。在国内对高等教育改革正迈向更深层次的时候,各校的毕业生规模也逐年增加。临近毕业时,或多或少都会存在许多迷茫。而在招聘、应聘的过程中,互联网作为当下承载海量招聘信息的重要载体,则给毕业生的择业提供了一条便捷途径。只是互联网的信息检索中却会面临许多用户并不需要的信息,只有通过人工筛选、再经总结对比后,才能得到最终想要的信息。
为了帮助高校毕业生在择业时能够快速获取特定的需求信息,并且通过快速数据分析得到自身择业的准确定位,从而做出更好的选择,为此本文设计研发了一套针对于招聘就业的专用爬虫。这里即以BOSS直聘作为实例,对如何开发爬虫获取信息,及对获取的信息快速分析进行了深入探讨与研究。对此拟展开剖析论述如下。
1 爬虫的设计
1.1 系统需求及分析
网络爬虫系统的开发是否成功取决于确保系统能够实现用户定制功能,达到预期设计目的。因此,在网络爬虫系统开发之前,就需要对该系统需求加以详尽分析,从而对整体的设计有一个清晰的思路。时下,普遍适用的爬虫系统都是模块化的,模块化的程序设计有利于代码块的测试与维护,而且也进一步增加了代码的适用性。在此基础上,只要对各个模块进行组合,就能够构建出一个完整的爬虫系统。本次研究即以BOSS直聘为例,开展模块化的编程设计。因为研究旨在通过爬虫系统对当前就业做出科学分析,故而针对此需求就要从BOSS直聘网站中获取全部的岗位信息,以及从每个岗位中获得包括各岗位名称、工作地点、薪水、公司规模性质、工作要求在内的各种关键信息。至此,在接下来的功能、模块设计中,就具备了较强的针对性。
1.2 爬虫模块设计
1.2.1 爬虫整体设计思路
爬虫系统的设计思路为:首先,需要获得所有包括岗位信息网页的源码;其次,在每一页的网页源码中寻找出与需求相匹配的信息,此时就需要连接爬虫系统和数据库,将每次成功匹配到的信息均存入数据库中,直至所有网页检索完毕。在数据爬取的整个过程中,针对BOSS直聘的高度反爬,还要在各个模块中引入适当的反扒策略,以此保证数据爬取的连续性。研究可得整体设计框架如图1所示。

图1 整体设计框图
1.2.2 爬虫的网页抓取模块
网页抓取模块作为爬虫系统中最重要的部分,也是起始的模块。但是从实际爬取的情况来看,针对同一个IP在短时间内的多次爬取,会被网站屏蔽IP地址,因此在这里采用代理IP池的技术去访问。为了避免被对方发现,还需要加入User-Agent将自己伪装成代理服务器。通过构造代理IP池以及由众多用户代理组成的代理池,每次随机选择访问IP与用户代理的搭配,据此而将自己伪装成来自不同IP的用户访问,大大降低了被反爬虫的概率。接下来采用Requsets库的API去解析当前第一层的URL。如:
resp=requests.get(url,headers=headers,proxies=proxies,timeout=5)
1.2.3 网页源码分析模块
在提取好第一层URL的源码后,分析当前文本,寻找用户需要的关键信息,根据用户的需求,还需要了解每一类工作的名称与对应网页链接,通过对ELEMENTS的寻找,发现在标签a-href下存在着用户需要的信息,将所有的工作名称存入JOB列表,将所有的工作链接构造成完整的URL存入与JOB列表对应的JOBURL列表。
1.2.4 信息获取模块
由于BOSS直聘网站每一类工作的链接数最多不超过10页,在构造具体到每一页链接的时候,page的数不应超过10,且当链接无效,即已经检测超出最后一页的时候,便自动退出了。构造规则如下:
urlbase=link+ ’?page=’ +str(i) +’&ka=page-’ +str(i)
接下来便用requests库去实现当前网页解析,同样也可以运用代理IP池加上用户代理池随机选择与搭配的方法以便能够更加流畅地爬取信息。一个工作岗位对于求职人员最关心的应为岗位、薪水、公司信息,工作要求这些关键信息。用Beautifulsoup库去解析好的网页提取这些信息,此时将用到如下设计代码:
soupxbl=BeautifulSoup(resp1.text,’lxml’)
jobkinds=soupxb1.select(’div.info-primary>h3>a>div.job-title’)
salarys=soupxb1.find_all(’span’,class=’red’)
yaoqius=soupxb1.find_all(’div.info-primary>p’)
names=soupxb1.select(’div.company-text>h3>a’)
situations=soupxb1.select(’div.info-company>div>p’)
1.2.5 MySQL数据库的联合使用
研究遍历完BOSS直聘网站上每一个工作岗位获得的信息相对来说是一个比较大的数据,在这里选择MySQL数据库对爬取的数据进行存储,因为MySQL数据库开源,易操作、并且速度、可靠性以及适应性都适宜。使用MySQL Server8.0,并通过pymysql库去对数据库进行操作,在程序开端,利用API建立数据库的链接。设计研发代码参见如下:
conn=pymysql.connect(host=’127.0.0.1’,user=’root’,password=’xnxbl123@qq.com’,db=’bossapply’,charset=’utf8’)
接下来,将基于用户需要保存的信息建立数据表格。设计研发代码见如下:
cur.execute("DROP TABLE IF EXISTS bossapply")
sql_c="create table bossapply (jobchar(50),salarychar(50),requirementsvarchar (265),company_namechar(100),situationvarchar (265));"
此后,在网页的分析模块中提取信息后,将这些数据导入所创建的数据库中的表里面。设计研发代码见如下:
sql_insert="insert into bossapply(job,salary,requirements,company_name,situation) values (%s,%s,%s,%s,%s);"
cur.execute(sql_insert,(s1,s2,s3,s4,s5))
这样就能实现对数据库的操作,将研究中爬取到信息成功存入数据库,为下一步的就业数据分析奠定了基础。文中,利用数据库可视化工具MySQL WorkBench展示的部分爬取数据如图2所示。

图2 部分爬取数据
2 数据分析
2.1 数据处理
通过设计好的网络爬虫系统,从BOSS直聘网站上爬取了上海地区13万多的岗位招聘信息数据,从招聘岗位、工资待遇、工作地点、工作要求、公司性质这几方面的信息,对上海地区的就业数据做出研究与分析,对广大择业人员可起到一个初步指导的作用。
通过Navicat Premium将数据库导出成Excel文件,在Python中通过pandas库对数据进行处理,首先将所有的数据通过read_excel的API读取到处理环境下,将每一列的数据分别提取出来构造出job、salary、requirements、situation四个列表,通过遍历整个requirements,检索每一个元素的字段,可以统计出上海市每个地区大约能够提供多少个工作岗位;同理,用上述的方法,可以统计出上海地区提供的工作岗位对学历的要求,以及公司规模的情况。对于就业数据分析来说,至关重要的就是薪资分析,将提取出来的salary列表,对每一个元素采用正则表达式匹配前两个数字,也就是这份工作的薪水上下限,求一个平均值,遍历整个列表,对薪水分布进行统计。同时,通过定位以及包含字符段的方法,可以将每个地区的工作以及相对应的薪水提取出来,再通过前文对全上海各地区的工作岗位统计,对上海各地区的平均薪资做出分析。在此基础上,各行各业的薪资水平也能够根据各行业的岗位数以及对应的平均薪资计算得出。
2.2 数据分析结果
随着应届毕业生的人数每年不断上升,带给社会的就业压力也随即增大,在这种就业形势竞争激烈的就业市场里面如何做出最佳的选择即已成为研究的热点与焦点。
研究可得, 上海地区提供岗位图如图3所示。从图3可以看出上海每个地区提供的岗位数还是有很大差别的,其中以浦东地区提供的岗位数最多,且从图3可以看出金山、宝山、青浦、奉贤提供的就业岗位相对来说较少,大多数的就业岗位还是集中在市区。同时,也可得到,上海各教育程度提供岗位图如图4所示。从图4结果可以看出招聘当前的需求主要还是本科以上,大专以上,对于部分应届生,则可选择考研考博,凭此来提升在未来就业市场上的竞争实力。
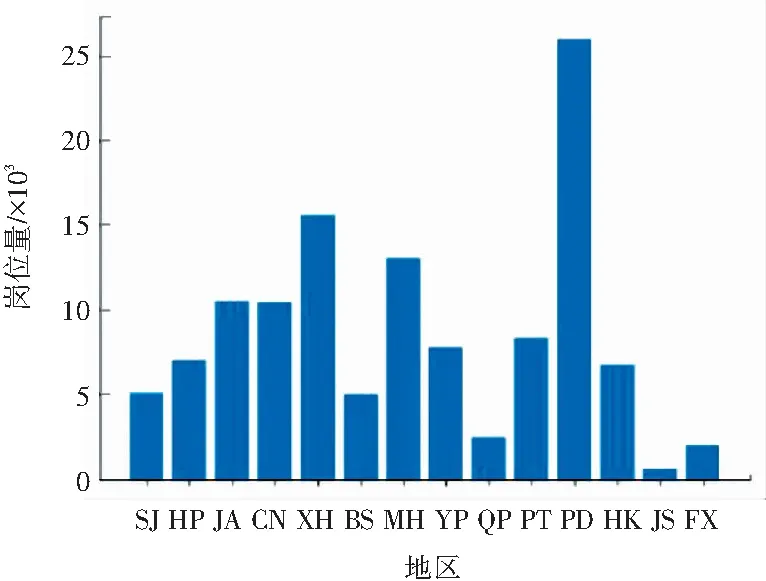
图3 上海地区提供岗位图

图4 上海各教育程度提供岗位图
就业市场对各职业的需求也是各有不同。上海各就业种类招聘情况如图5所示。由图5分析可知,对技术岗的需求甚至超过了其它众多行业的需求总和,伴随着人工智能时代的来临,对人工智能相关的技术岗位缺口还是很大的,是一个前景可期的就业方向。在未来职业规划还未具备清晰认知时,可以作为一个参考方向。另外,市场营销与生产制造行业也能提供不错的岗位数。在薪资水平方面,总体还是令人满意的,主要集中在月薪6~10 K,以及10~20 K之间,月薪在10 K以上和以下的各占大约50%,整体的收入水平保持在一个比较高的水准。

图5 上海各就业种类招聘情况

图6 上海招聘收入情况
在前文对上海市总体的收入水平进行了直观判断基础上,继而得到上海各地区招聘收入情况如图7所示,上海各就业种类招聘收入如图8所示,以便能够对就业选择以及未来职业规划进行准确及有效判断。从图7中可以看出,上海各地区的收入情况差距不大,但是整体上来看,徐汇区还是略高一筹,这样在选择就业时可以根据地区消费的不同,以及未来规划选择工作区域。从图8中可以看出,薪资水平处于前三位的行业分别是产品行业、管理行业以及技术行业。而在数据分析后得出,在提供岗位数量最多的技术岗上,工资并不是最高,有些岗位虽然需求量不大,但是薪水很高。而且,从薪资分布来看,80%以上的行业的月收入都已经达到10 K或者10 K以上了,这样人们在选择就业的时候,可以更少地受到薪资影响,从而做出更适合自己的选择。
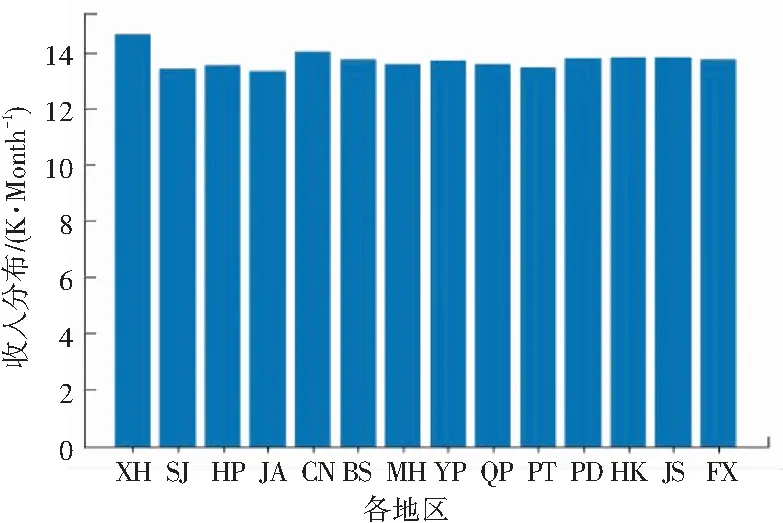
图7 上海各地区招聘收入情况

图8 上海各就业种类招聘收入
3 结束语
本文通过Python加上MySQL Server的配置,创建了一个基于BOSS直聘网站的网络爬虫数据收集分析系统,该系统能够登录到BOSS直聘,并获取页面信息,分析页面中的URL,同时对筛选构造后的URL再一次进行数据筛选,将用户获取到的数据存储到数据库,在此基础上将对数据进行深层次的挖掘,也就是运用一系列的数据分析手段,获得关于上海各地区、各岗位的薪资待遇、招聘需求等一系列重要信息,为广大的就业人员提供有益的借鉴与参考。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
当代陕西(2022年6期)2022-04-19
现代信息科技(2021年21期)2021-05-07
智能计算机与应用(2018年5期)2018-10-20
魅力中国(2018年5期)2018-07-30
电脑知识与技术·经验技巧(2018年1期)2018-05-30
中学科技(2016年7期)2017-05-16
智能计算机与应用(2007年4期)2007-08-25
