
基于SDAE深度学习框架的现代学徒制课程教学质量评价研究
2020-01-13 07:48左国才苏秀芝王海东韩东初
智能计算机与应用 2020年1期
左国才, 张 珏, 苏秀芝, 王海东, 韩东初
(1 湖南软件职业学院, 湖南 湘潭 411100; 2 湖南大学, 长沙 410082)
0 引 言
《国务院关于印发国家职业教育改革实施方案的通知(国发〔2019〕4号)》中指出:“总结现代学徒制试点经验,推进校企融合、教学管理等改革与创新,对全国职业院校的教育管理、教学质量、学生职业技能提升等方面进行考核评估,促进职业院校深化课程改革,提高师资水平,全面提升教育教学质量。”
堆栈式去噪自编码器(SDAE)深度学习框架已经成功应用于人脸识别、单目标跟踪、多目标跟踪、生物医学图像检索等方面[1],本文设计基于堆栈式去噪自编码器(SDAE)深度学习框架的课堂行为分析模型,用于研究现代学徒制班的教师、学生课堂行为与教学效果的关系,为课堂教学质量评价提供依据,实现更有针对性的教学。并且,研究学生课堂专注度分布情况,掌握一堂课中学生的专注度分布情况,有利于教师将重点内容放在学生专注度相对较高的时间段进行讲解,合理地设计教学方案,改进教学效果,切实提高教学质量。
1 堆栈式去噪自编码器
Bengio等人[2]提出通过增加噪音的方式来获得更加鲁棒特征的去噪自编码器算法(DAE)。此后研发的堆栈式去噪自编码器(SDAE)是基于DAE算法提出的,在网络层次逐渐加深和完善。去噪自编码器可以将一个带有噪音干扰的图像恢复到没有噪音的原始图像,具有较少特征单元的隐藏层特征可以用于表示原始的图像输入层,去噪自编码器可以获得更少而且更加鲁棒的图像特征表示,成功实现了图像的降维。去噪自编码器可以编码带有噪音干扰的输入数据X'到隐藏层数据Y,再将隐藏层数据Y解码回近似于原始输入数据Y'。为了使解码后的数据Y'和原始输入数据X尽可能相等,去噪自编码器通过下面的优化函数来调整编码层和解码层的参数,这里用到的数学公式可顺次表示为:
假设:
Y=f(WX+b),
(1)
Y'=f(W'Y+b'),
(2)
那么:
(3)
相比于堆栈原始的自编码器所建立的网络模型,堆栈式去噪自编码器将取得更好的表现,并能获得更加鲁棒的图像特征。这种去噪策略和堆栈式多层结构将有助于指导网络模型去学习更加有用和高级的图像特征表示,而且采用了无监督方式来获得较为抽象和精致的图像特征。其网络结构设计和训练过程中使用无监督的训练方式均将用来逐层训练参数权重,再将上一层的输出作为下一层的输入继续训练,从而产生越来越高级别的特征表示。堆栈式去噪自编码器网络模型[3]如图1所示。
基于堆栈式去噪自编码器(SDAE)的更加鲁棒、更加高级的图像特征表示优势,本文利用堆栈式去噪自编码器(SDAE)模型实现人脸识别与人的姿态检测识别,对现代学徒制班教师、学生的课堂行为进行客观量化的分析,为课程教学质量提供客观评价依据。
2 教师与学生课堂行为分析算法
2.1 基于SDAE的人脸识别算法
无监督训练的堆栈式去噪自编码器模型学习一般图像的深度特征表示,使用有监督的微调网络模型学习和调整人脸识别任务中部分微小的且不同于一般化图像的特征。关于在线进行人脸识别的深度网络模型如图2所示。
算法步骤可分述如下:
(1)利用大规模图像数据集Tiny[4],离线训练堆栈式去噪自编码器深度学习模型,学习图像的一般化特征。
(2)使用带标签的人脸数据库进行深度特征的微调和训练新的特征提取网络模型,并在顶层输出层后添加分类层,构建深度特征提取模型。
(3)通过分类层和人脸训练数据,有监督在线微调特征模型,利用新的深度在线人脸识别模型完成判别和识别人脸目标的任务。
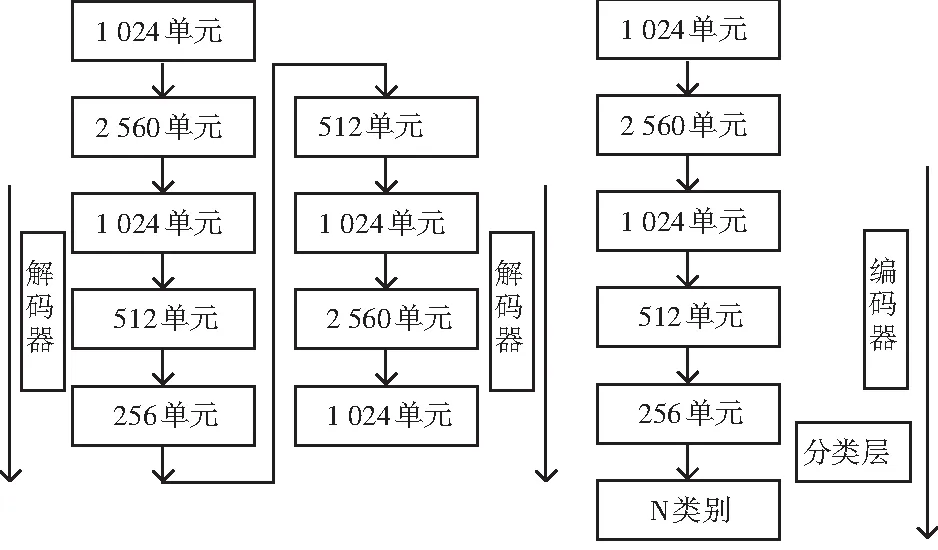
图1 堆栈式去噪自编码器网络模型 图2 人脸识别的深度网络模型
Fig. 1Network model of stack denoising self-encoder Fig. 2 Depth network model for face recognition
2.2 学生课堂行为分析算法实现
设计基于SDAE人脸识别技术的教师与学生课堂行为分析算法。通过检测识别教师、学生在教室中表现出的姿态、神情、动作等特征[5],判断教师授课状态及学生上课专注度的高低。研究可得阐释解析如下。
(1)算法思想。本次研究拟设计基于SDAE人脸识别技术的课堂行为分析算法,提取到目标人脸,对人脸面部特征进行检测,同时检测目标人物的姿态。
通过检测目标(教师、学生)所在教室表现出的姿态、神情、动作等,判断教师授课状态及学生听课专注度的状况,用于研究现代学徒制班的课堂专注行为与学习效果的关系,为现代学徒制班课堂教学质量评价提供客观依据,实现更真实有效的课程教学质量评价。
(2)专注度判定流程。首先在课堂教学视频中间隔5 s随机采集一帧图片,通过SDAE人脸识别模型,判断其身份(教师或者学生)并标识出来,然后分别根据教师或者学生的姿态、神情、动作检测识别,判断被测目标是否专注课堂。教师与学生上课专注度判断流程如图3所示。
(3)专注度判定算法实现步骤
① 利用海量图片集对堆栈式去噪自编码器深度学习模型进行离线训练,无监督地学习图像的一般化特征。
② 将拍摄的教师、学生所在教室表现出的姿态、神情、动作图片数据用于实验训练和测试。从中随机选择80%的课堂行为图片作为训练数据集,其余的20%图片作为测试数据集。

图3 课堂行为判断流程
③ 使用离线训练好的堆栈式去噪自编码器模型进行在线深度学习,并更新目标人脸与目标姿态、神情、动作检测识别模型,再通过误差反馈,进行权重参数微调。
④ 使用微调后的权重参数和教师或学生的课堂行为测试数据集,来测试目标的人脸及姿态、神情、动作识别算法,利用sigmoid分类层来判别和输出教师或者学生课堂专注度识别结果。
3 测试序列及实验结果分析
基于SDAE深度学习模型的教师、学生上课专注度判断实验环境主要包括:视频采集,采用了分辨率较高的网络视频监控摄像机;软件环境方面,操作系统为Windows7,64位,CPU为2.6 G,内存为4 GB。深度学习实验环境为:CPU为i7-5830K,内存为128 G,GPU为GTX1080,深度学习框架使用TensorFlow1.4 ,开发语言选用Python3.6。
实验中采用教室任意采集的50组时长为200 s的视频序列。采集任意一张教师或学生上课中的课堂图像,进行专注度判断,检测结果如图4、图5所示。在课堂上,根据教师、学生的姿态、神情、动作进行检测识别。坐姿端正,双手摆放桌上,眼睛注视讲台或者教师的行为被检测为课堂专注行为,否则被检测为不专注行为。
由于课堂行为训练数据量不够大,容易导致过拟合;训练数据标识不精确、学生在课堂上表现的姿态、神情、动作等比较随意和多样化,这均会影响最终的识别效果;由于教师与学生是面对面的情况,教师与学生同时拍摄到的图像只能识别一类,不能同时识别教师与学生,识别一张图像需要用到2个模型,增加了算法复杂度,影响识别速度和效率。

图4 教师与学生专注行为检测结果

图5 学生专注行为检测结果
4 结束语
SDAE深度学习框架能够提取更鲁棒更高级的深度特征,提高了人脸及学生的姿态、神情、动作的识别效率与准确率。本文设计研发了基于SDAE深度学习框架的教师与学生的课堂行为分析算法,对教师、学生课堂专注行为进行研究,实现对人脸及学生的姿态、神情、动作的识别,判断教师授课的状态与学生听课的专注度情况,为教学质量评价提供客观量化的分析评测基础。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
传感器世界(2022年4期)2022-08-05
传感器世界(2022年3期)2022-05-24
作文中学版(2022年1期)2022-04-14
文萃报·周五版(2021年17期)2021-05-31
数字技术与应用(2021年1期)2021-03-24
卷宗(2019年36期)2019-02-18
通信产业报(2018年10期)2018-04-13
软件工程(2017年9期)2017-10-28
电脑知识与技术(2017年14期)2017-07-10
