
基于卷积神经网络的候选区域优化算法
2020-01-10 01:49王春哲安军社姜秀杰邢笑雪
中国光学 2019年6期
王春哲,安军社,姜秀杰,邢笑雪
(1.中国科学院国家空间科学中心 复杂航天系统电子信息技术重点实验室,北京 100190;2.中国科学院大学,北京 100049;3.长春大学,吉林 长春 130022)
1 引 言
在计算机视觉中,目标检测在人脸识别与目标跟踪等方面有着广泛的应用[1-2]。目标检测是确定图像中是否含有目标及目标所在图像中的位置。在过去几十年中,解决该问题的主要方法是采用滑动窗口范式,具体为:在该范式下,使用一个高效的分类器判断密集采样的滑动窗口中是否存在目标。然而,该类方法计算量巨大,仅在单尺度下,每张图像就需处理104~105个滑动窗口,而且现在的数据集还要求预测目标的宽高比,极大地增加了检测算法的复杂度。最近,学者们提出基于候选区域(Region Proposals,RP)的检测框架,该检测框架可有效提高目标的检测效率,其主要思想是在图像上生成少量更可能包含目标的候选区域,并对该候选区域进行后续的识别与定位[3]。
生成候选区域的主要准则有[3]:分组提案(Grouping Proposals,GP)准则及窗口评分(Window Scoring Proposals,WSP)准则。GP准则试图生成可能包含目标的分割段,并利用颜色、形状等线索合并分割段来生成候选区域,其代表性算法是选择性搜索算法(Selective Search,SS)[4]。WSP准则是对滑动窗口中出现目标的可能性进行评分,并根据评分高低筛选候选区域,该准则主要有Object-ness[5],BING[6]以及Edge Boxes(EB)[7]。
EB通过统计滑动窗口中出现目标边缘信息的多少来生成目标的候选区域。但由于EB方法使用传统边缘检测算子生成边缘特征,不能准确地描述目标,因此具有一定局限性。近几年,卷积神经网络(Convolutional Neural Network,CNN)在目标分割、识别与检测等领域中表现出色[8-11]。由于目标边界通常含有较多的语义信息[12],使用CNN可以生成更富有语义信息的边缘特征,有助于提高目标候选区域的质量。
目标显著性是在图像的多尺度及不同宽高比下统计图像的颜色、纹理及形状信息,从而将目标从背景中区分出来[13-14]。目标的空间位置信息是衡量目标属性的重要指标,自然图像中,目标多出现在图像的中间或邻近中间位置,若将目标显著性及位置信息引入到候选区域算法中,可有效提高目标候选区域的召回率。
本文从卷积边缘特征、目标显著性及目标的空间位置,3个方面来研究目标的候选区域算法。使用深度神经网络生成更能表达目标边界的卷积边缘特征,并统计每个滑动窗口中含有的目标边缘信息量、显著性特征及目标的空间位置信息,筛选滑动窗口。
2 卷积边缘特征与目标显著性
本文所述候选区域算法主要包括:(1)边缘信息得分;(2)目标的显著性得分;(3)位置信息得分;(4)筛选滑动窗口。首先,使用RCF(Richer Convolutional Features)网络生成富有语义信息的卷积边缘特征图;然后,在整张图像上无重叠采样若干图像块,并使用周边延拓像素、颜色直方图的卡方距离(Chi-square distance)等策略,统计每个滑动窗口的平均显著性得分;第三,为每个滑动窗口构建位置信息得分模型;最后,根据每个滑动窗口的边缘信息得分、显著性得分及位置信息得分,筛选滑动窗口,算法结构如图1所示。
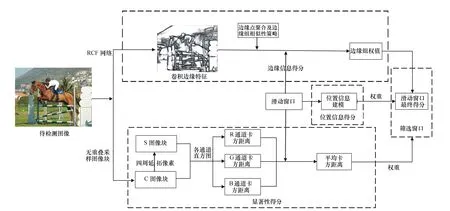
图1 所提算法实现框图 Fig.1 Block diagram of the proposed algorithm

图2 RCF结构 Fig.2 The structure of RCF
2.1 卷积边缘特征
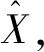

图3 给定一张图像X Fig.3 An given image X

图4 X的边缘特征图 Fig.4 Edge feature maps of X

表1 边缘组算法描述
对于一个边缘组s中的任意边缘点p,其边缘强度为mp、边缘方向角为θp及边缘点位置为(xp,yp),则边缘组s的位置(xs,ys)可定义为:
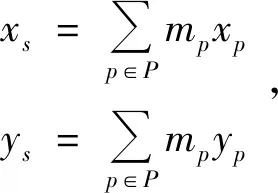
(3)
其中,P为边缘组s中所有边缘点集合。边缘组s的方向角θs可表示为:
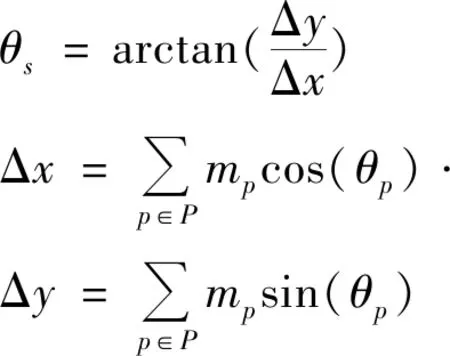
(4)
在边缘组集合T中任意取两个边缘组ti及tj,则两边缘组之间的相似度为:
a(ti,tj)=|cos(θi-θij)cos(θj-θij)|γ.
(5)
其中,θi、θj分别为ti及tj的方向角;θij为ti及tj重心连线间的方向角;γ用于调整方向角变化对相似度的敏感性[7],根据EB算法取值策略,取γ=2。

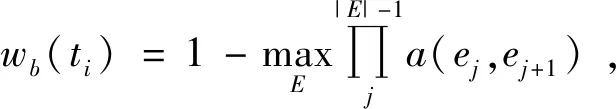
(6)
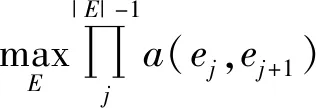
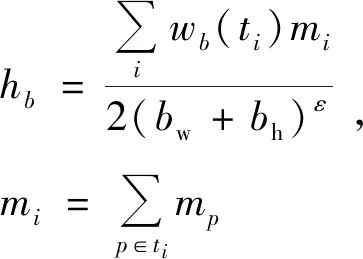
(7)
其中,mi表示第i个边缘组强度;bh与bw为滑动窗口b的高和长;ε为调节hb对滑动窗口大小的敏感度[7],鉴于EB算法,本文取ε=1.5。
2.2 显著性得分
在文献[14]中,作者认为目标的颜色变化比背景的颜色变化丰富,因此作者将图像无重叠地分成若干图像块,并将图像块的6个通道R、G、B、L、a、b作为颜色向量,使用随机森林等训练策略确定滑动窗口的显著性得分。这种处理对算法性能有所改善,但有两点不足:第一,众所周知,语义信息对后续的目标检测很重要,但作者在文献[14]中使用传统的边缘检测算子生成边缘特征,不能很好地描述图像的语义信息,这就要求采用更复杂的分类器对后续目标进行识别,从而增加了检测阶段算法的复杂度;第二,需要对若干图像块的颜色特征进行单独的预先训练,而训练后的参数可能受不同数据库内容的影响,从而增加了算法的运算时间。
针对上述两点不足,本文使用目标颜色的局部特征改进算法。目标显著性指出,目标与周围背景之间的颜色差异较大[13]。对于紧紧包含目标的矩形框bxc,通过将矩形框bxc向周边扩展像素,获得背景矩形框bxs(bxc⊂bxs);对于不包含目标的矩形框bxr,按照相同策略获取相应的背景矩形框bxm(bxr⊂bxm),则颜色直方图的卡方距离关系有:ds{bxc,bxs}>ds{bxr,bxm},如图5所示。将矩形框bxc、bxr称为中心图像块,简记为C图像块;背景矩形框bxs、bxm称为背景图像块,简记为S图像块。

图5 图像块的卡方距离 Fig.5 The chi-square distance of image patches
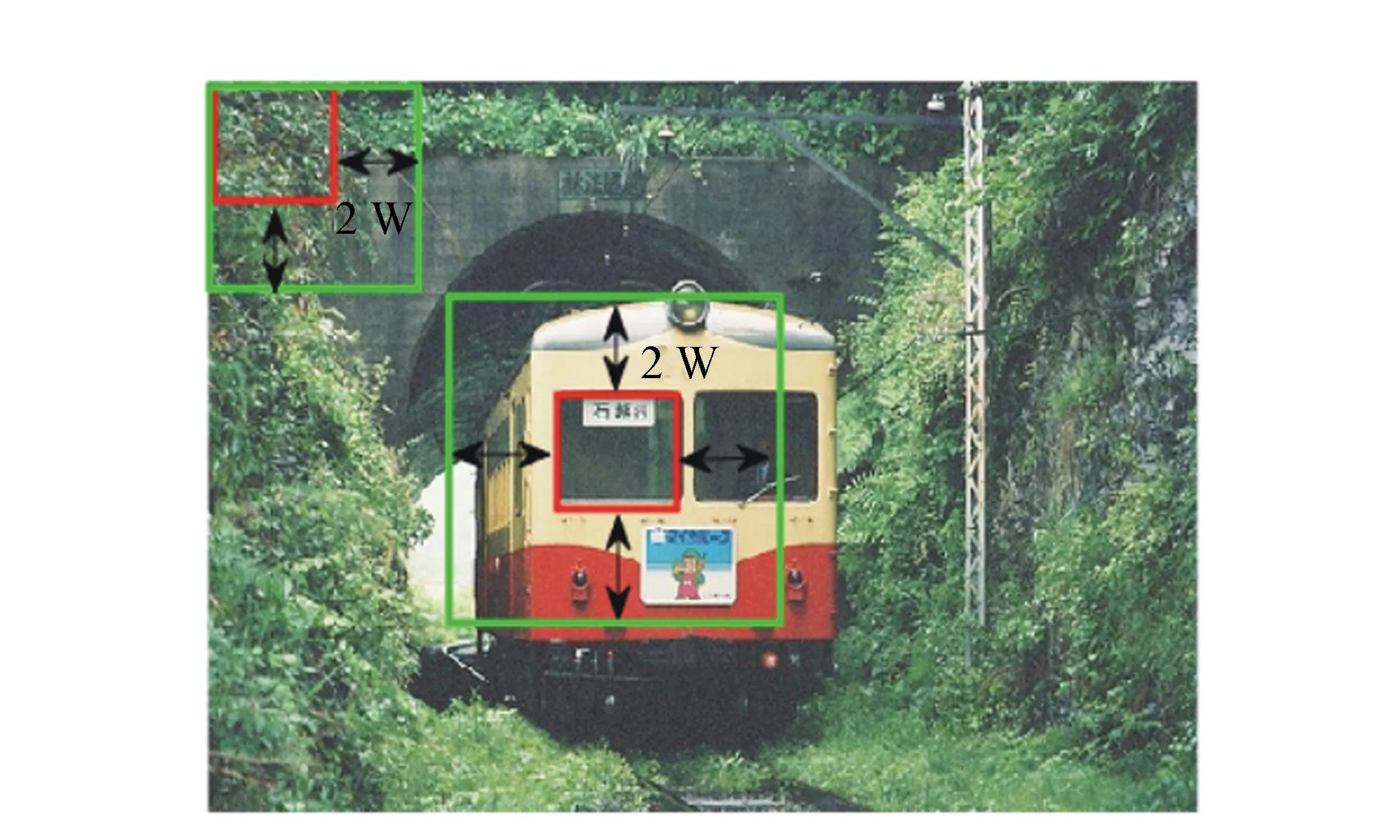
图6 选取S图像块的策略 Fig.6 Selection strategy of S image patch
在尺寸为M×N的彩色图像X上无重叠采样,采样窗口为w×w,因此,共采样Ng=(M/w)×(N/w)个彩色图像块。每个彩色图像块Xci(i=1,…,Ng)有3个通道,分别记作Xci(R)、Xci(G)、Xci(B)。
为计算显著性得分,需将每个图像块Xci按照一定的策略向四周延拓像素,形成S图像块,记作Xsi(i=1,…,Ng)。S图像块的选取策略如图6所示。对位于X边缘上的图像块Xci,仅向含有像素的方向延拓2×w个像素;对位于非边缘上的图像块Xci,则向四周分别延拓2×w个像素。为衡量图像块Xci及Xsi间的颜色差异,分别计算Xci三通道的颜色直方图为hr,hg,hb以及Xsi三通道的颜色直方图为sr,sg,sb。每个通道颜色直方图的卡方距离分别为:
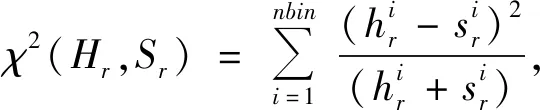
(8)
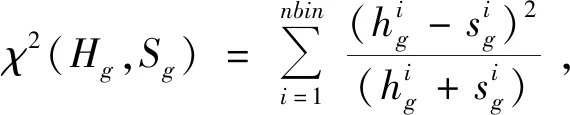
(9)
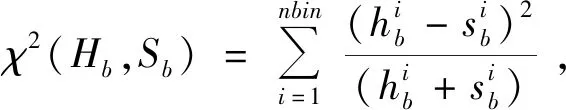
(10)
其中,nbin为一常数,取值为256。图像块Xci及Xsi的颜色直方图的卡方距离定义为:

(11)
使用b中所有图像块的卡方距离的平均值,作为滑动窗口b的显著性得分:
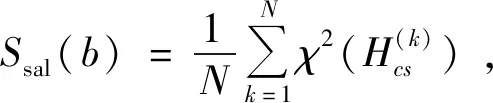
(12)

2.3 位置信息得分
为描述图像中目标的位置信息,图7分别列出了PASCAL VOC 2007、VOC 2012数据集中目标位置与目标数目的关系。其中:横坐标为已标注目标的中心与图像中心归一化后的欧氏距离,纵坐标为目标数目。可以看到,目标主要分布在距图像中心[0,0.5)范围内,此区域的目标约占70%,随着距离的增加,目标数逐渐减少。根据这一特性,将目标位置信息融入到候选区域算法中。
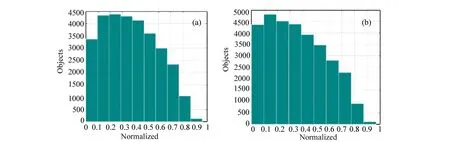
图7 目标位置与目标数目关系。(a)VOC 2007数据集;(b)VOC 2012数据集 Fig.7 Relationship between the object′s location and object′s number. (a) VOC 2007 dataset; (b) VOC 2012 dataset
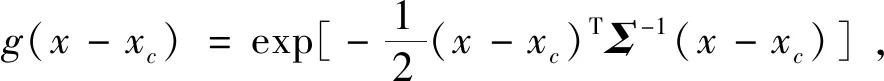
首先对每个滑动窗口进行位置信息建模,计算彩色图像X的中心位置坐标(Xmx,Xmy):
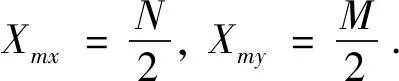
(13)
对于滑动窗口b,用四维向量(bx,by,bw,bh)表示,因此b的中心位置坐标(bmx,bmy):
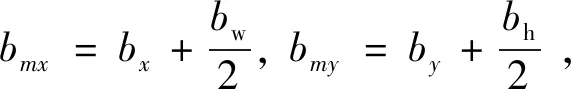
(14)
其中,bx,by表示滑动窗口b左上角的位置坐标,bw及bh分别为滑动窗口的宽和高。则滑动窗口b的中心与彩色图像中心的欧氏距离为:
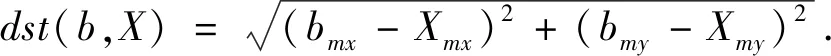
(15)
由于滑动窗口b的中心与图像X中心距离越大,则含有目标的概率越小。因此,本文选取一个单调递减函数作为该距离的权重,来表达该候选区域的位置信息得分:
L(b)=(η)dst(b,X)·dst(b,X) ,
(16)
其中,0<η<1,η值的大小(取0.5),表明L(b)对距离dst(b,X)的敏感程度。
2.4 筛选候选框
将计算的边缘信息得分、显著性得分及位置信息得分,分别赋予合适权重,作为滑动窗口b的最终得分:
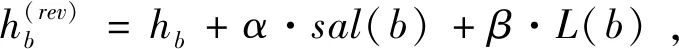
(17)

表2 精调滑动窗口策略
3 数据分析与性能比较
3.1 数据库选取及性能评价指标
本文选取在候选区域算法中使用较广泛的数据集PASCAL VOC 2007进行实验。该数据集有训练集、验证集及测试集,共9 963张图像、24 640个目标。数据集的基本情况如表3所示。
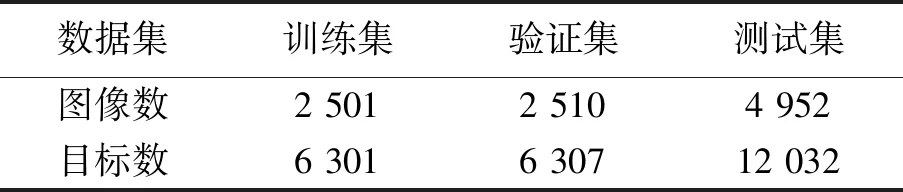
表3 VOC 2007数据集特性
本文采用召回率(recall)、AUC(Area Under Curve,AUC)值及达到某召回率时所需候选框数目作为评价算法性能的标准,具体见3.4节。
召回率是描述候选区域为正样本的概率指标,公式为:

(18)
其中,nmb(·)表示含有·的数目;tp表示正样本,fn表示虚假负样本。为确定候选区域是否为正样本,需通过候选区域与标注区域的交并比(Intersection over Union,IoU)实现。在给定候选区域pbx及对应的标注框gbx情况下,其交并比可定义为:
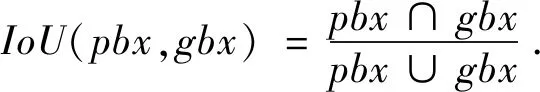
(19)
若交并比IoU(pbx,gbx)大于设置的阈值thr(通常为0.5),则候选区域pbx为正样本。召回率越大,说明候选区域算法越好。AUC值是衡量候选区域算法性能的重要指标,其值越大,候选区域算法性能越好。
3.2 RCF网络训练
为得到更加富有语义信息的边缘特征,本文选取ImageNet数据集VGG16的预先训练模型,并在BSD500的边缘检测数据集上训练RCF。在训练RCF网络时,选择均值为零、标准差为0.01的高斯分布的权重值,在偏置为零时进行参数初始化。每次选取10张图像,并使用随机梯度SGD算法优化参数。参数设置为:学习率为1×10-6、动量值为0.9、权重衰减为0.000 2,NVIDIA GeForce GTX 1080上共运行SGD 40k次。
3.3 参数确定

图8 参数α、β与召回率的关系 Fig.8 Relationship of the parameters α, β and recall
为确定合适的窗口尺寸w,固定参数α及β的最优值α=0.000 1和β=0.1,选取w分别为8,16,24,32,40,48,w与召回率之间的关系如图9所示。可见,当窗口尺寸w=16时,召回率为最大值。因此,本文最终选取的参数为α=0.000 1、β=0.1、w=16。
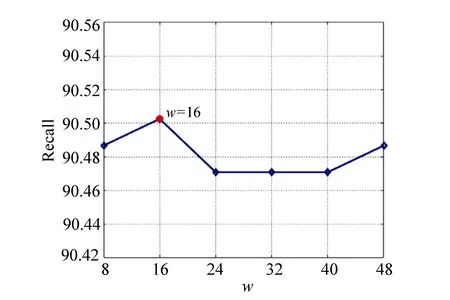
图9 参数w与召回率的关系 Fig.9 Relationship of the parameter w and recall
3.4 数据分析与性能比较
为验证本文方法的有效性,选取SS[4]、Object-ness[5]、BING[6]、CPMC[15]、EB[7,16]、Randomized Prim′s[17]、Rantalankila[18]、MCG[19]、Endres[20]、Geodesic[21]、Rigor[22-23]、Improved EdgeBoxes[14]共12种近年来主流算法,在PASCAL VOC2007测试集上进行对比实验。首先固定候选框的数目,研究13种算法在不同交并比IoU下的召回率,如图10所示(彩图见期刊电子版)。
从图10可知,实验中的算法可分为两类:一类是定位较好的算法,此类算法随着IoU的升高,召回率缓慢下降,如SS和EB算法;另一类是定位较差的算法,随着IoU的升高,召回率急速下降,如BING,Rantalankila算法。当候选框个数为100时,Improved EdgeBoxes性能略高于所提算法,但弱于CPMC、endres等算法,这表明在候选框较少的情况下,可优先考虑CPMC及endres算法;当候选区域数目为1 000时,MCG性能表现最好;当候选区域数目大于1 000,且IoU为0.5~0.7时,本文算法的召回率最高,这表明本文算法有效提高了候选区域的质量。
评价候选区域算法性能的另一种方法是固定交并比IoU,研究不同候选区域数目下算法的召回率。图11(彩图见期刊电子版)为指定交并比IoU,13种算法召回率随候选区域数目的变化示意图。从图11可知,交并比IoU取为0.5及0.7时,随着候选框数目的增加,本文算法性能趋于最佳,有最高的召回率。图11(c)展示了13种算法
在不同交并比下的平均召回率。从图11(c)可知,MCG、SS和本文算法的整体性能表现优越。
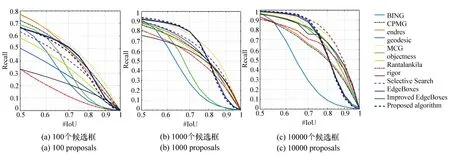
图10 不同候选框数下召回率与交并比之间的关系 Fig.10 Relationship between recall and IoU at different number of proposals
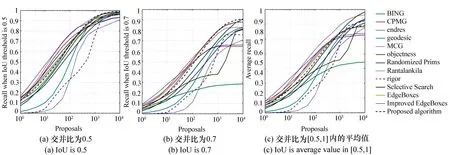
图11 不同交并比的候选框数与召回率的关系 Fig.11 Recall versus number of proposals at different IoUs
平均召回率AR表示在不同交并比IoU下召回率的平均值,定义为:
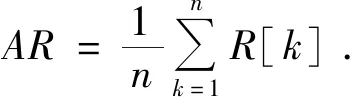
(20)
为全面衡量所提算法性能,表4列出了在PASCAL VOC 2007验证集下,当交并比IoU=0.7时,AUC值、运算时间及召回率分别达到45%、60%、75%时,所需候选框的数目。其中,除本文算法外,其他算法的结果来自参考文献[7][24]。
若在指定召回率下,所需候选框数目越少,表明该算法定位性能越好;另外,由于处理的候选框相对较少,也可为后续检测节约时间,从而极大地提高了检测效率。
达到指定召回率时,所需最少候选框数目的确定规则如下:
(1)预先选取候选框的个数为cnts={1,2,5,10,100,200,500,1 000,2 000,5 000,10 000},然后计算各候选框数目下的召回率,为区分不同交并比下的召回率,此处,记作Rj(j=1,2,…11);
(2)对给定的数据集合cnts中每个数据取对数ms=log(cnts),ms中共有11个值,每个值分别记为ms[i];
(3)当召回率Rj>Rs时,候选区域最小数目的索引为:e=min{index{Rj>Rs}},并令f=e-1;
(4)召回率达到Rs时,所需候选框的最小数目,即为:
(ms[e]-ms[f])+ms[f]) .
(21)
根据上述的召回率值Rj及ms确定AUC值,其策略如下:
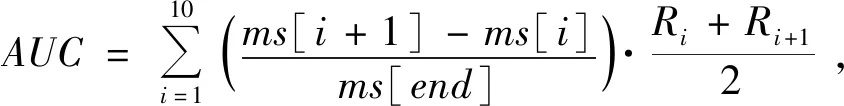
(22)
式(22)中,ms[end]表示集合ms的最后一个值。
表4中“--”表示无穷大。由表4知,本文算法的AUC值达到了0.47,与MCG算法性能相当;性能达到75%时,仅需799个候选框,相比于MCG的1 116个、SS的1 812个候选区域,明显降低了候选框个数。
表4中,Rρ代表候选框数为ρ(1 000,2 000,10 000)时,各算法的召回率。可以知道,在不同候选框数目下,本文算法均有很好性能;当候选框数为10 000时,本文算法的召回率达到了90.50%,明显高于其他算法,同时较Improved EdgeBoxes提高了1.25%。

表4 交并比为0.7时13种算法的实验结果
本文在NVIDIA GeForce GTX 1080、CPU@4.20 GHz,32G RAM下,本文算法所用时间为0.764 9 s,以牺牲微小计算资源,提高了算法的召回率。精度mAP值是选取1 000个候选框,在Fast R-CNN(model M)的测试结果。由表4可知,本文算法的精度较高。
3.5 图像中不同位置目标的召回率
为证明所提算法对出现在图像中不同位置目标的性能,本文在PASCAL VOC 2007测试集中,选取已标注目标的中心与图像中心的归一化距离分别为[0,0.5)、[0.5,0.8)及[0.8,1.0]的图像进行实验。归一化距离越大,则目标越靠近图像边缘;距离越小,目标越靠近图像中心。图12(彩图见期刊电子版)列出了图像中不同区域的目标、候选框数目取10 000时,13种算法在不同交并比IoU下的召回率。可以看出,所提算法在距离图像中心为[0,0.5)及[0.5,0.8)上的目标性能优越,Improved EdgeBoxes与EB算法性能相当,低于所提算法的性能,在靠近边缘的目标,所提算法的性能接近SS算法。这表明,无论是在图像中心或图像边缘的目标,所提算法均有良好性能。
为进一步说明所提算法对图像边缘目标检测的性能,选取测试集中与图像中心的归一化距离为[0.8,1.0]的图像,在不同交并比IoU下进行测试,其候选框数目与召回率之间的关系如图13(彩图见期刊电子版)所示。由图13(a)、13(b)可知,所提算法仅用较少的候选框,就能达到较高的召回率;由图13(c)可见,随着候选框数目的增加,所提算法的平均召回率逐渐上升,算法性能与SS相当,这说明所提算法能够获取定位较好的候选框。

图12 13种算法不同位置目标的召回率与交并比的关系 Fig.12 Recall vs IoU curves of objects at different locations by 13 kinds of algorithms
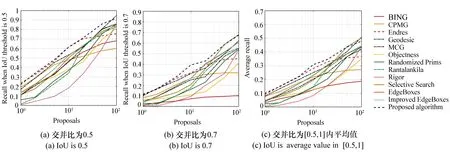
图13 不同交并比下候选框数与召回率的关系 Fig.13 Recall versus number of proposals at different IoUs
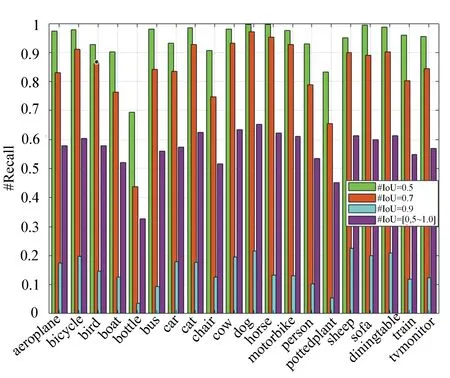
图14 本文算法在PASCAL VOC 2007测试集的召回率 Fig.14 Recall on the PASCAL VOC 2007 test set for proposed algorithm in this paper
为确定每一类目标候选区域的召回率,本文利用PASCAL VOC 2007测试集中单目标图像的标注信息,以及Hosang在文献[24]中对VOC 2007各类目标候选框的统计标注信息,计算各类目标的召回率。
图14(彩图见期刊电子版)从PASCAL VOC 2007测试集选取20类目标,本文算法在候选框数目为500时的各类召回率。可以看出,所提算法在“cow”、“dog”及“sheep”目标在各交并比IoU下均能获得较高的召回率;但对于“bottle”及“pottedplant”目标,召回率相对较低,这是由于此类目标尺寸较小,含有目标的信息不多,使得召回率下降。
3.6 图像窗口的宽高比对实验结果的影响
本文测试了C图像块窗口的宽高比对实验结果的影响。所谓宽高比是指窗口的宽与高的比值。本文选取宽高比分别为0.5,1.2、窗口宽度分别为8,16,24共8个窗口,在测试集及验证集上进行实验,不同宽高比的召回率如图15(彩色见期刊电子版)所示。可知,宽高比对召回率的影响小,这表明本文算法对宽高比的鲁棒性较好。

图15 不同宽高比时测试集及验证集上的召回率 Fig.15 The recalls at different aspect ratios of test set and validation set
3.7 所提算法的目标检测结果
图16(彩图见期刊电子版)列出了本文算法的部分目标的检测结果。其中,实线代表真实的标注框;虚线为本文算法预测的候选区域。可以看到,所提算法的目标检测性能较好,但对于尺寸相对较小的目标,出现了漏检。

图16 所提算法对部分目标的检测结果 Fig.16 Object detection results of some objects detected by proposed algorithm
为证实漏检目标的分布情况,图17绘制了测试集中漏检目标的尺寸与漏检目标数目间的关系示意图。可见,漏检目标主要集中在行数为(0~50)、列数为(0~50)范围内,这一区域内所提算法的性能下降。

图17 漏检目标的尺寸与漏检目标数目间的关系 Fig.17 The relation of the size of undetected objects and the number of undetected objects
由于小目标分辨率低及对噪声敏感等原因,小目标检测是目标检测领域的一项挑战。针对这一问题,现有方法多借用多尺度手段,使用插值算法对小目标区域进行插值放大后检测。但这增加了算法的复杂度,且检测精度受插值算法影响较大。本课题组将继续从深度卷积神经网络方面研究小目标的敏感特征,使得算法有更高的检测精度。
4 结 论
本文从卷积边缘特征、目标显著性及目标空间位置信息三方面研究了目标候选区域算法。从实验结果中得知,由于使用语义信息更丰富的卷积边缘特征,提高了目标候选区域的质量,这说明卷积神经网络能够很好地描述目标边界;另外,将目标显著性的局部特征及目标空间位置引入到候选区域中,也使得目标候选区域的召回率有所提高,这表明目标显著性特征及目标的空间位置信息有助于生成定位更准确的候选区域。当选取10 000个候选框、交并比为0.7时,所提算法在PASCAL VOC 2007验证集上的召回率达到了90.50%,较EB和SS算法分别提高了3.31%、1.38%。本文算法的不足之处在于对小目标的检测效果不好。这是由于小目标的像素较少,产生的边缘信息不多,容易出现目标漏检。针对这种情况,下一步将继续利用深度神经网络探究小目标含有的特征,以提高候选区域算法的召回率。
猜你喜欢
计算机工程与应用(2022年1期)2022-01-22
小猕猴智力画刊(2021年6期)2021-08-05
计算机技术与发展(2020年2期)2020-04-15
制造技术与机床(2019年8期)2019-09-03
电子技术与软件工程(2019年4期)2019-04-26
意林(绘英语)(2018年1期)2018-04-28
火力与指挥控制(2018年3期)2018-04-19
作文大王·低年级(2016年3期)2016-03-11
汽车与新动力(2015年1期)2015-02-27
雷达学报(2014年4期)2014-04-23
