
基于无线体域网的在线人体活动识别
2020-01-08 01:37范长军
小型微型计算机系统 2020年1期
范长军,高 飞
(浙江工业大学 计算机科学与技术学院,杭州 310013)
1 引 言
据2018年5月GSMA公布的“移动经济”报告统计[1],2017年全球手机用户人数已突破50亿人大关,其中智能手机用户人数占比57%,预计到2025年这两个数字将分别攀升至59亿和77%.随着智能手机的普及,以及计算能力的提升,普适感知应用与服务得以迅速发展.一方面,手机中被嵌入越来越多的传感器件,使其成为集感知、计算与通讯为一体的智能终端[2];另一方面,用户往往随身携带手机,随时随地通过手机来实时检测人的日常行为,能为人机交互提供不可或缺的及时反馈,为医疗保健或健康管理提供场景丰富的海量信息.基于智能手机的在线人体活动感知和识别成为近年来国内外的研究热点[3,4].
现有相关工作大多仅采用手机上的加速度、陀螺仪等惯性传感器进行人体活动识别[5].文献[6]采用手机加速度和陀螺仪传感器,通过特征提取、特征选择以及数据融合来提高坐、站、躺、走、上楼、下楼六类活动的分类准确率和在线推理效率;文献[7]开发了一套手机应用,用于在线进行传感数据的收集、训练和识别,静止、走、骑摩托车三类活动的识别准确率达90%以上.上述两类方法均取得了不错的效果,但感知范围有限,在一定程度上限制了可识别的活动种类.比如,当把手机放在裤袋中时,将很难捕捉喝茶、打字、吸烟等活动涉及的手部运动.
随着MEMS技术的发展,智能手表、智能手环等可穿戴设备得以普遍使用,它们具有体积小、重量轻、非侵入、便于佩戴等特点,内置的加速度、陀螺仪、心率等传感器,能有效辅助日常活动识别.文献[8]用手腕处的加速度、角速度和磁场信息来检测手部姿态和识别吸烟行为,文献[9]通过腕部的加速度和角速度来识别吃饭动作,此两者都仅采用腕部惯性传感数据专门识别特定类型的活动;文献[10]研究了智能手机和智能手表在人体活动识别中分别所起的作用,识别了9类活动,但是两类设备是独立工作的;文献[11]同时利用裤袋和手腕处的惯性传感器来进行日常活动的识别,识别了更多种类的活动(13类).上述工作均采用了传统的机器学习算法,需要人工提取特征,并且没有对在线识别的性能进行评估.
针对以上问题,设计了由智能手机和智能手环组成的体域网,并在此基础上实现了一套普适化的人体活动在线识别系统.首先,在Android智能手机上设计和开发了通用的传感数据采集系统,以方便采集体域网内各节点的传感数据;其次,设计了深度神经网络—DeepCIL,在传感数据经过预处理后,通过构造带有Inception结构的卷积神经网络和长短时记忆递归神经网络来提取其时空域特征,并结合两类网络结构来进行数据融合,离线训练神经网络模型;最后,对训练好的神经网络模型进行优化,并部署到智能手机上,在线实时识别人体活动.
2 人体活动识别系统设计
2.1 系统总体设计
本文设计了一种适用于人体活动识别的可扩展的体域网系统框架,组成包括:可穿戴感知设备、智能移动计算终端以及大数据分析云平台,系统的整体架构如图1所示.
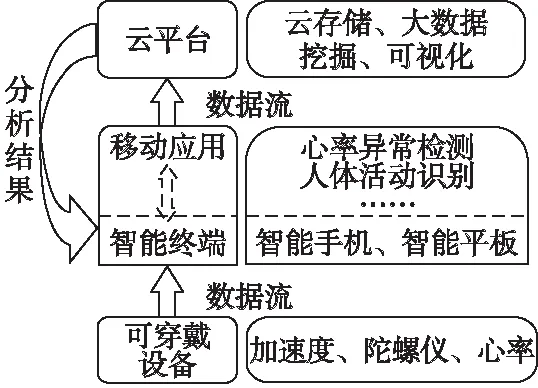
图1 系统框架图Fig.1 Framework of the system
在体域网中,各类可穿戴设备作为感知节点,负责实时地采集用户的体感信号,如加速度、角速度等惯性数据以及心率等生理数据.智能手机既是计算节点,又承担了感知节点和通信节点的角色:作为移动计算终端,它负责对各节点的传感信号进行收集、预处理与分析识别;作为感知节点,它可用于人体上下文运动感知,实现硬件资源的充分利用;在通信层面,手机既是体域网的汇聚节点,又是与云平台交互的接口.在网络拥堵或电量有限时,手机可以将收集的传感数据暂存到本地,只将识别的结果发送至远端云平台,由云平台作进一步的处理,并及时返回处理结果.当网络通畅或电量充足时,再将保存在本地的原始传感数据上传到云端,方便后续大数据平台进行历史数据的分析与挖掘.该方法在本地移动端即可得到识别的结果,及时准确,且不受限于网络.
为了减轻用户的负担及增加系统的普适性,本文中体域网主要由智能手机和智能手环两个节点组成.基于该系统框架,选用了谷歌Nexus 5x手机,并采用Arduino开源硬件开发了可穿戴感知设备iWristIMU,以模拟智能手环的功能.iWristIMU的硬件组成主要包括一个Arduino主控板,一个九轴惯性传感模块,一个无线蓝牙模块,以及一套电源组件.其中,惯性传感模块采用的CMPS11具有I2C总线接口和TTL串行接口,内置三轴加速度、三轴陀螺仪和三轴地磁仪,具有接口简单、感知精度高和支持多频率输出的优点,可以满足人体活动识别的要求.iWristIMU主要通过该传感模块捕捉人的手臂运动,并通过无线蓝牙模块发送到手机上.
2.2 数据采集软件及实验
基于以上系统框架,设计开发了相应的数据采集软件iSomaticLog,并通过该软件采集了一批数据,以验证本文提出方法的有效性.iSomaticLog支持Android 4.0及以上版本的平台,能从智能手机内置的各类传感器中采集数据,包括加速度、陀螺仪、磁力计等惯性传感器,以及GPS、光强、大气压等其他传感器,也可接收由蓝牙等无线网络发送来的体域网其他节点的感知数据.为了便于交互操作,为iSomaticLog设计了用户友好的图形化界面,当需要标记人体活动类型时,可直接点选下拉菜单中的对应项,方便又快捷.此外,界面中还可实时显示体域网各传感节点的感知数据.

图2 数据采集软件界面与采集实验设置Fig.2 UI of iSomaticLog and settings for the experiment
数据采集软件iSomaticLog系统界面如图2左图所示,由三部分构成:在第一部分中,当选取人体活动的类型,并点击开始按钮后,即开始数据的采集工作,并得到样本数据的标签;第二部分显示了智能手机内置传感器感知到的部分数据,如GPS、角速度、磁场等;第三部分显示了从智能手环传递来的惯性传感数据,包括角速度、加速度等,并且可通过点击开关按钮的方式选择是否连接智能手环.
为了验证本文方法的有效性,进行了模拟场景实验.将Nexus 5x手机竖直放入右侧裤子口袋中,顶端朝上,屏幕背对人体,iWristIMU戴在右手手腕处,各位穿戴者的佩戴方式保持一致,如图2右图所示.
表1 测试者的生理状况统计
Table 1 Summary of participant′s physiological profiles
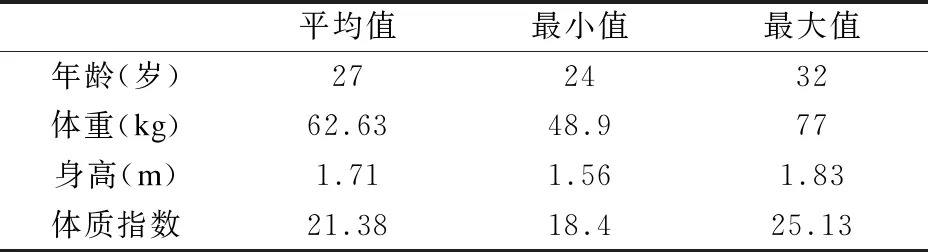
平均值最小值最大值年龄(岁)272432体重(kg)62.6348.977身高(m)1.711.561.83体质指数21.3818.425.13
本试验由4名男性和2名女性共6人参与测试,表1统计了他们的年龄、身高、体重等基本生理状况.这些测试者通过iSomaticLog采集并标注了十二类日常活动的传感数据,包括坐、站、上楼、下楼、走、跑、骑自行车、打字、写字、喝茶、吃饭、吸烟.其中,打字、写字、喝茶、吃饭,坐在桌前完成,吸烟在指定地点站着完成.在6名测试者中,仅有2人抽烟,有1人不喝茶,其他活动每人均参与实验.一次采集过程一个人一类活动至少持续1分钟,6名测试者总共采集得到22.5小时的数据,并且确保每类活动的数据不少于40分钟.在测试时,对数据进行乱序排列和随机抽取,以保证结果无偏.
3 人体活动识别系统实现
3.1 传感器数据预处理
采集的原始传感数据一般不会直接用来识别人体活动,这样难以保证识别的准确率,主要是因为很多因素都能导致信号质量下降,其中高频噪音和信号丢失最为常见.
在人们自然的日常活动中,身体各部位的加速度、角速度等惯性信号主要维持在较低的频率,但在这些信号从激励、发生到检测、传输等诸多环节中,它们都有可能受到环境中各类高频噪声的污染.常用的解决方案是通过低通滤波器来将这些噪声剔除,本文选用巴特沃斯(Butterworth)低通IIR数字滤波器来达到此目的.从图3中可以看到,滤波后加速度信号的波形变得平滑,但关键细节仍在,且总体波形特征没有受到影响.
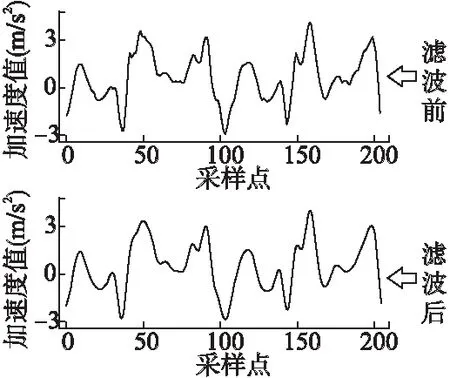
图3 Butterworth低通滤波Fig.3 Low pass Butterworth filter
此外,一方面,由于传感器件运行状态不稳定等各方面的原因,容易出现信号漂移与数据丢失问题;另一方面,当体域网扩展新的传感节点(比如心率)时,其可配置的采样频率与惯性传感器的未必一致,需要进行数据对齐.这里采用线性插值的方法补全上述缺失的数据,以保证感知数据的内在模式不被改变.另外,不同类型传感器的输出数值范围往往差别很大,在经过上述处理后,应对各通道数据进行归一化.
各类传感信号是随时间而持续产生的,以一定的频率离散采样可得到一个很长的数据序列.为方便提取特征和进行训练,需要把这些长数据序列分割成若干具有相同长度的重叠的窗口,也即加窗操作.此处,设置手机和手腕上惯性传感器的采样频率为50Hz,并将滑动窗口的长度设为6s时长的传感序列样本数——300,同时设置滑动窗口的步进时长为1s(对应50个样本).
3.2 人体活动识别算法分析
人体活动识别主要通过监督式学习算法实现,更具体地,通过多元分类算法实现,故其关键在于设计与实现高效且准确的分类算法.
当前的人体活动识别研究常常采用朴素贝叶斯、决策树、支持向量机等简单易用的分类算法,算法的准确性和效率极大地依赖于训练数据的特征工程.相关工作通常采用启发式的方法,手动提取用来表示活动的各类时域、频域和时频域等特征,并进行特征选择.目前常用的特征包括均值、方差、平均交叉率、FFT变换、能量(Energy)、轴间相关系数等.将一个滑动窗口内X轴的加速度值表示为X={x1,…,xi,…,xN},这里N=300,则举例说明如下:
1)均值:
(1)
2)方差:
(2)
3)平均交叉率:数据越过均值的次数.
(3)
4)能量:Ak(k=1,2,…,N)代表数据序列的快速傅里叶变换系数,则:
(4)
5)轴间相关系数:xi,yi分别代表X,Y两轴的加速度值,则:
corr(X,Y)=
(5)
特征工程因不同应用领域要解决不同的问题,或要使用不同的传感器类型,而各不相同,需要对应领域的专家知识具体问题具体分析.在现有人体活动识别研究中,经常存在多模态传感数据,比如加速度、角速度、磁场、心率等,不同类型的数据往往需要提取不同的特征.与过去要从人工设计的特征开始学习的传统方法不同,近年来迅速发展的深度学习技术可从原始数据直接开始学习,实现了“端到端”的效果,又被称为表示学习[12].卷积神经网络(Convolutional Neural Network,CNN)在特征提取的全面性和表示能力方面都表现不俗,可用于提取多模态传感数据的局部空间特征,并能通过叠加多个卷积层来提取更加抽象的活动语义,以充分表示不同的活动.相较于CNN,长短时记忆网络(Long Short-Term Memory Network,LSTM)能有效提取数据内在的时序关系,更善于建模喝茶、吸烟等具有长时语义的活动.
为此,本文提出了一种新的深度神经网络DeepCIL,将CNN和LSTM整合到一个网络框架内.先分别对不同模态传感数据通过带有Inception结构的多个卷积层提取短时局部特征,再通过一个全连接层实现这些特征的整合,最后通过LSTM层来建模长期时序关系,并进行人体活动的分类.
3.3 人体活动识别算法设计
3.3.1 卷积神经网络设计
卷积神经网络主要有卷积层和池化层两类基本结构,它们一般交替出现,形成一个多层的深度网络.
在CNN中,每层的神经元都仅与前一层中的部分数据相连,通过与卷积核的卷积操作,局部感受野中的空间特征被提取出来.不同的卷积核可以提取不同类型的特征,对每一层数据通常会使用多个卷积核进行卷积操作.卷积之后得到的数据称之为特征映射(feature map),多个卷积核对应多个特征映射.由于加速度等惯性传感信号都是一维的数据,因此采用一维的卷积核,对应的卷积操作为:
(6)
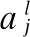
ReLU:σ(x)=max(0,x)
(7)
在卷积层之后往往紧跟着池化层,以对得到的特征进行二次提取,减少特征数量的同时保持特征的局部不变性.池化层计算式为:
(8)
式中:β表示池化权重系数,fdown()表示采用的池化函数,常用的池化函数有最大池化函数(如式(9))和平均池化函数(如式(10)),其中,k为池化核的大小.
fdown(a)=max(ai,j)i,j∈[0,k]
(9)
(10)
传统CNN方法主要强调通过加深网络层数来提高网络特征处理能力,本文为其引入了结合Network in Network思想的Inception结构[13].Inception结构通过并联不同尺度的卷积核来增加网络宽度,获取多模态传感数据中的多种尺度特征,能有效地表征喝茶、吸烟等复杂活动.
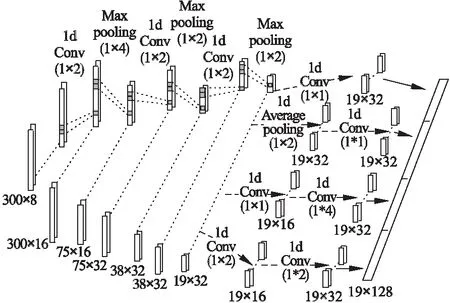
图4 CNN-Inception网络层结构Fig.4 Structure of CNN with Inception
以手机作感知节点为例,设计卷积神经网络层CNN-Inception的结构.选用其三轴加速度和三轴角速度作为训练样本,并且为了避免传感器朝向的变动影响识别的效果,计算三轴加速度向量和三轴角速度向量的长度作为辅助数据通道,因此共有3+3+2=8通道的训练数据.传感序列窗口长度为300,则对应输入CNN的一个样本的维度为(300×8).经过“卷积—>池化”的三次交替迭代,将8通道数据进行融合得到大小为(19×32)的特征映射.其中,选用的卷积核大小一律为2,池化窗口大小分别采用4、2、2,提取的滤波器数依次为16、32和32,具体如图4所示.然后,在此基础上分四路进行数据的缩放,以实现Inception的功能,分别是:①卷积核大小为(1×1)的一维卷积操作;②先进行窗口大小为(1×2)的平均池化,再做(1×1)的一维卷积;③先做(1×1)的卷积,再做(1×4)的卷积,均为一维;④先做(1×1)的卷积,再做(1×2)的卷积,均为一维.上述每一路均得到了大小为(19×32)的数据,将这四路数据并联起来即为CNN-Inception的输出—大小为(19×128)的特征映射.可以看到,在③和④中数据维度经过(19×32)->(19×16)->(19×32),实现了多尺度的特征提取.
在训练时,采用了反向传播的梯度下降算法对参数进行调整,CNN特有的局部感受野和权值共享机制,将需训练的参数数量限制在一定范围内,提高了训练性能.
3.3.2 长短时记忆网络层设计
惯性传感数据经过CNN-Inception网络层处理后得到的特征映射被输入LSTM网络层,以学习内在的动态时序特征.
在LSTM中,每个神经单元的前一个时间点的激活值与权重系数相乘后又被加回到本时间点上,这为它施加了过去激活函数的影响,相当于具有了记忆.LSTM的各个隐藏层由一系列存储块递归相连而成,一个存储块对应一个记忆单元,每个记忆单元内部包含三个门:输入门、输出门和遗忘门,分别具有对记忆单元进行读、写和复位的功能,以灵活控制不同记忆单元之间的信息传递.
一个LSTM记忆单元的状态通过以下公式进行更新:
it=σ(WiXt+Viht-1+bi)
(11)
ft=σ(WfXt+Vfht-1+bf)
(12)
ot=σ(WoXt+Voht-1+bo)
(13)
ct=ft⊗ct-1+it⊗tanh(WcXt+Vcht-1+bc)
(14)
ht=ot⊗tanh(ct)
(15)
其中,it,ft,ot,ct和ht分别代表输入门、遗忘门、输出门、控制单元和记忆单元在t时刻的输出.bi,bf,bo,bc分别为对应的偏置向量.Wi,Wf,Wo,Wc,Vi,Vf,Vo,Vc为权重矩阵.
设计LSTM网络为两个隐藏层的结构,每个隐藏层分别对应一个LSTM单元,依次表示为LSTM-Cell1和LSTM-Cell2.输入层传入的数据和上一个时刻LSTM-Cell1的状态输出构成了第一层LSTM-Cell1的输入;同理,第二层LSTM-Cell2的输入由LSTM-Cell1的计算输出和上一时刻LSTM-Cell2的状态输出组成.具体参见图5.
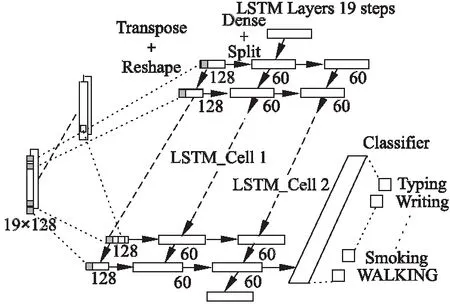
图5 LSTM网络层结构Fig.5 Structure of the LSTM
CNN-Inception网络结构的批量输出经过转置与形变后,通过一个全连接层进行拟合,再被分割,转换成LSTM容易处理的形式.针对上一小节的例子,设置LSTM隐藏层的节点数为60,序列长度为19.在DeepCIL网络中,两个LSTM隐藏层之后紧跟一个全连接层,对提取的时空域特征进行分类,得到各类人体活动的识别结果.
在训练模型时,为达到训练效率和效果折中的目的,将传感数据分批次进行输入.批大小作为超参数,可多次赋值并测试效果来选定,本系统一律置为100.一次训练迭代包含前向及反向传播两个过程,每迭代一次参数随之更新一次,直至准确率及损失趋向于收敛.通过设置训练迭代的次数或终止的条件,最终可获得稳定的DeepCIL网络模型.
3.4 人体活动识别移动端部署
由于智能手机的计算能力有限,并且可携带的电池容量有限,运行在其上的软件需要充分考虑性能因素.此外,为了增加用户的体验,以及满足某些在线应用的需求,实时性也是题中应有之义.因此,在服务器端训练DeepCIL网络模型,并将训练好的模型进行转换、优化,部署到手机端,以实现算法对移动终端硬件的支持.
本文基于Tensorflow[14]框架和Android系统来进行人体活动识别系统的移动端部署.TensorFlow是谷歌研发的第二代人工智能开源学习系统,具有灵活性高、可移植性好等优点,能够运行在单个或多个CPU或GPU上.Tensorflow将神经网络的输入、输出和中间层以及各层节点间的运算关系定义在内部的一个静态图(Graph)上,并通过一个动态会话(Session)执行图中的具体运算.在服务器端,训练时可通过GPU来加速模型的训练过程,训练完成后Tensorflow自带的工具可以将设计好的DeepCIL图结构以及训练得到的参数固化到一个二进制文件中,并进行前向推理的优化,比如,删除模型中输入和输出之间的非必要节点,将批处理标准化运算跟卷积权重进行合并等,以节省计算时间;在移动端,Android系统可方便地通过Gradle导入Tensorflow对应的库,调用库的API接口对实时感知的手机和手环上的惯性数据进行推理,即可得到识别的结果.
为了便于与传统机器学习方法进行对比,在Android移动端同时引用了Weka[15]的Maven库,以方便调用常用的机器学习算法.Weka是基于Java环境的开源机器学习及数据挖掘软件,集成了大量分类、回归、聚类等机器学习算法,并可方便地部署于Android平台.
基于以上设计,在Android平台上开发了在线人体活动识别软件.该软件可实时地收集体域网各节点的感知数据,并进行推理得到准确的识别结果,目前可有效识别前文所述的十二类人体活动.
4 实验分析
基于DeepCIL的人体活动识别模型是在Ubuntu 16.04平台上,由TensorFlow框架通过NVIDIA GTX 1080显卡硬件加速训练得到的,而后被部署到谷歌Nexus 5x手机上.在训练过程中经过多次赋值测试并筛选得到了相应的学习速率、序列长度和训练迭代次数等超参数,分别为0.0001,300,100.
表2 传感器类别与佩戴位置对准确率的影响
Table 2 Effect of number and position of sensors to accuracy
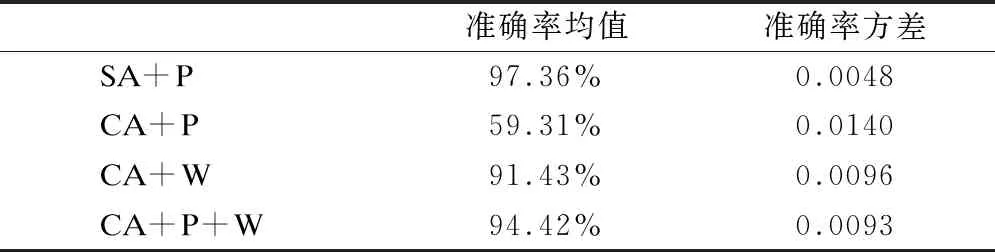
准确率均值准确率方差SA+P97.36%0.0048CA+P59.31%0.0140CA+W91.43%0.0096CA+P+W94.42%0.0093
首先,考虑传感器数量与佩戴位置对人体活动识别准确率的影响.将十二类活动分为简单活动(以SA表示):坐、站、走、跑、骑自行车、上楼、下楼,共七类;和复杂活动(以CA表示):打字、写字、喝茶、吃饭、吸烟,共五类.分别采用手机(以P表示)和手环(以W表示)的三轴加速度和三轴角速度两类传感数据,并提取其均值、方差作为基本统计特征,通过Weka的朴素贝叶斯来进行分类.每次实验随机选取80%的数据作为训练数据,10%作为验证数据,剩下10%的数据作为测试数据,重复上述过程10次,并计算各次分类准确率的均值和方差,如表2所示.
从实验结果可以看出,在仅采用手机上的惯性传感数据的条件下,七类简单活动能够被朴素贝叶斯算法准确的区分,且分类效果相对稳定,而五类复杂活动的分类准确率并不理想,仅为59.31%;在仅采用手腕上的惯性传感数据时,五类复杂活动的分类效果得到了很大程度的改善,可见对于这些人体活动而言,手部的动作更有区分度;当同时采用手机和手腕上的惯性传感数据时,五类复杂活动的分类效果进一步提升,准确率和稳定性都维持在较好的水平.这说明增加体域网传感节点,能够有效的扩展可识别的人体活动种类;手环设备作为一个感知节点,在某些类别的活动分类中是必要的.
表3 特征组名与类别
Table 3 Three group of extracted features

特征组名特征类型简单特征(SF)均值,方差常用特征(MF)均值,方差,绝对偏差,平均交叉率,峰值间隔,能量,桶分布,轴间相关系数通用特征(CF)tsfresh[16]时序特征工具提取794个特征,并从中平均选择得到423个特征
为了考察特征工程对人体活动识别准确率和效率的影响,进行如下实验.在五类复杂活动的基础上,增加与之运动模式类似的坐、走两类活动,针对这七类活动,同时采用手机和手环上的三轴加速度和三轴角速度,并为这些数据各通道的每一窗口分别提取三组特征,如表3所示.
表4 特征工程对识别准确率和效率的影响
Table 4 Effect of feature engineering to accuracy and efficience

准确率/%特征耗时/ms推理耗时/msSF+NB86.970.550.13MF+NB88.4528.543.29CF+NB77.38(1,048)-DeepCIL-199.8708.41DeepCIL-298.4606.17
在移动端,在线提取SF和MF特征,并通过训练好的朴素贝叶斯(以NB表示)模型在线分类,分别得到对应的耗时和准确率.CF仅在服务器端(CPU配置为Intel(R)Core(TM)i7-7740x)提取并计算耗时.此外,在服务器端分别训练两个DeepCIL模型,一个遵照前文设计的网络参数(DeepCIL-1),另一个将所有隐藏层的节点数减半(DeepCIL-2),然后将两个模型部署到移动端,并计算推理耗时和准确率.结果如表4所示.
从表4中可以看出,在仅有简单特征的情况下,移动端特征提取和分类预测的平均耗时分别为0.55ms和0.13ms,基本可以忽略,但分类准确率较低,仅为86.97%;采用启发式的方法优选得到MF特征后,分类准确率有了一定程度的提升,但耗时分别增加至28.54ms和3.29ms.由于启发式的方法无法明确需要提取的特征种类,尝试采用tsfresh提取并选择得到的CA特征进行分类,效果却并不理想.一方面,准确率仅为77.38%,明显偏低;另一方面,特征提取在服务器平台上的耗时已为1.048s,即便部署至移动端也无法做到实时识别,而且特征数量的庞大也造成了移动端的部署困难.采用本文设计的DeepCIL进行端到端的人体活动识别,无需人为设计特征工程,识别准确率高达99.87%,移动端平均耗时仅为8.41ms,能够满足在线日常活动识别的实时性要求.对DeepCIL进行压缩,将网络各隐层的节点数减半,耗时降至6.17ms,识别准确率仍达98.46%.
表5 相关工作的分类效果对比
Table 5 Results of activity recognition with different methods
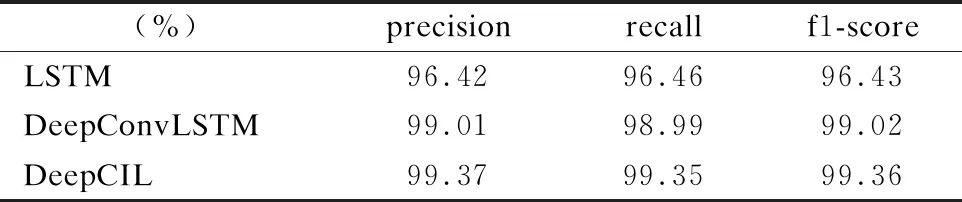
(%)precisionrecallf1-scoreLSTM96.4296.4696.43DeepConvLSTM99.0198.9999.02DeepCIL99.3799.3599.36
目前,已有一些基于深度卷积神经网络或LSTM进行人体活动识别的研究,包括笔者前期基于LSTM的工作[17],以及DeepConvLSTM[18]等,分别采用上述方法对十二类人体活动传感数据通过十折交叉验证进行分类,并与本文方法进行比较,结果如表5所示.从表中可以看出,在准确率、召回率和f1-score三个指标方面,本文方法均具有一定的优势.究其原因,Inception优化了CNN特征提取的性能和效果,LSTM进一步挖掘出数据间的时序依赖,DeepCIL在时域和空域对人体活动均有较好的表征.
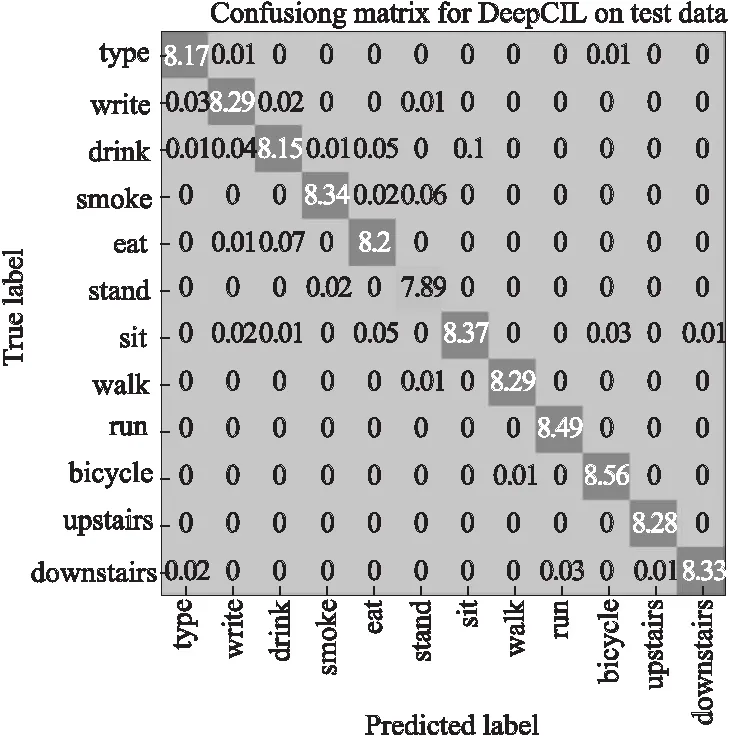
图6 DeepCIL测试数据混淆矩阵Fig.6 Confusion matrix for DeepCIL on test data
图6为训练好的DeepCIL模型下测试数据集的混淆矩阵,从图中可以看出,有0.06%的“吸烟”活动对应的传感数据被误分类成“站着”,有0.07%的“吃饭”被误分类为“喝茶”.直观上理解,吸烟是站着进行的,而吃饭和喝茶都是坐着进行的,并均伴有手部的动作,因此较易出现混淆.
5 结束语
本文设计了由智能手环和智能手机组成的体域网,并在此基础上实现了一套普适化的人体活动在线识别系统.先在智能手机上基于Android平台设计和开发了一套通用的传感数据采集系统,并采集了实验所需的数据;然后,设计了DeepCIL深度神经网络,对预处理后的传感数据进行离线训练;最后,对训练好的神经网络模型进行了优化,并部署到智能手机上,实现了在线人体活动的识别.
猜你喜欢
传感技术学报(2022年7期)2022-10-19
今日农业(2022年15期)2022-09-20
当代水产(2022年6期)2022-06-29
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
金桥(2018年4期)2018-09-26
劳动保护(2018年8期)2018-09-12
分析化学(2017年12期)2017-12-25
